Java集合
1. 集合
1.1 集合概念
集合为对象的容器,存储对象的对象,可代替数组
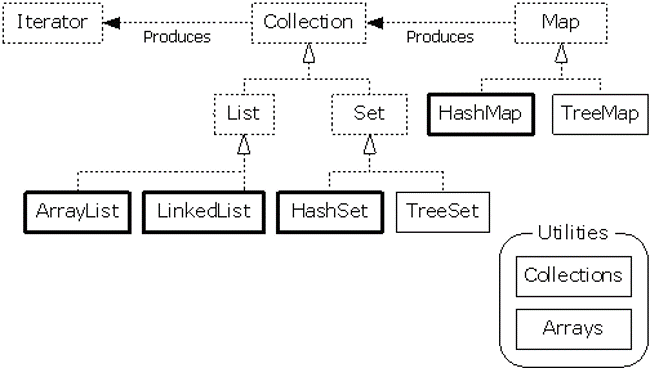
虚线表示接口,实线为实例类,其中 Map 没有继承 Collection
1.2 集合和数组的区别
| 集合 | 数组 | |
|---|---|---|
| 长度 | 可变长度 | 固定长度 |
| 内容 | 只能是引用类型 | 可以是基本类型,也可以是引用类型 |
| 元素内容 | 可以存储不同类型(一般都是存储同一种类型) | 只能存储同一种类型 |
1.3 集合的方法
| 方法名 | 作用 |
|---|---|
| add(E e) | 在集合末尾添加元素 |
| remove(Object o) | 删除集合中的元素 |
| clear( ) | 清除本类集合中的所有元素 |
| contain(Object o) | 判断该集合是否包含某元素 |
| isEmpty | 判断集合是否为空 |
| size( ) | 集合中的元素个数 |
| addAll(Collection c) | 将一个集合中的全部元素添加到另一个集合中 |
| toArray | 返回一个集合中包含本类集合中的所有元素的数组,数组类型为:Object[] |
| iterator | 迭代器,集合专用的遍历方式 |
2.List接口
2.1 ArrayList
ArrayList集合底层实现是一个Object数组,有下标,有序,可以为null,可以重复,线程不安全
特点:
- 查询修改快,因为有下标
- 增加删除慢,因为需要移动元素
ArrayList源代码解读:
- 当我们调用无参构造时,会初始化一个初始为空的数组
- 当我们第一次添加元素的时候,会将数组容量该为10
- 如果集合长度不够,将扩容为原来的1.5倍
public static void main(String[] args) {
ArrayList<Integer> list1 = new ArrayList<Integer>();
list1.add(20);
list1.add(35);
list1.add(30);
list1.add(55);
list1.add(60);
System.out.println(list1.size());
System.out.println(list1.remove(0));
System.out.println(list1.size());
list1.set(0, 666);
System.out.println(list1.get(0));
System.out.println(list1.isEmpty());
list1.clear();
System.out.println(list1.isEmpty());
}
ArrayList遍历
1.普通for循环遍历
for(int i = 0; i < list.size();i++) {
System.out.println(list.get(i));
}
2.迭代器遍历
Iterator<Integer> it = list.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
3.增强for循环遍历(底层实现依然是迭代器)
for(Integer i :list) {
System.out.println(i);
}
以上三种循环所用时间都差不多
2.2 LinkedList
LinkedList 底层结构是双向链表,每个元素只能访问上一个元素和下一个元素,可以存储重复元素,线程不安全
特点:
- 增加删除速度快
- 查询修改速度慢
LinkedList 集合常用方法
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<String>();
list.add("a");
list.addFirst("hello");
list.addLast("world");
System.out.println(list.remove(0));
System.out.println(list.size());
System.out.println(list.removeFirst());
System.out.println(list.removeLast());
System.out.println(list.size());
list.add("ABC");
list.add("DEF");
list.set(0, "abc");
System.out.println(list.get(0));
System.out.println(list.getLast());
System.out.println(list.isEmpty());
list.clear();
System.out.println(list.isEmpty());
}
LinkedList遍历方式
1.普通for循环遍历
for(int i = 0; i < list.size();i++) {
System.out.println(list.get(i));
}
2.迭代器遍历
Iterator<Integer> it = list.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
3.增强for循环遍历(底层实现依然是迭代器)
for(Integer i :list) {
System.out.println(i);
}
以上三种循环中普通for循环所用时间最长,并且会随着数据的增多遍历时间而成指数倍增加,迭代器遍历和增强for循环遍历时间差不多
2.3 Vector
ArrayList与Vector的区别?
| ArrayList | Vector |
|---|---|
| 线程不安全 | 线程安全 |
| 初始为0 | 初始为10 |
| 当空间不足时扩容为1.5倍 | 空间不足时扩容为2倍 |
public class TestVector {
public static void main(String[] args) {
Vector<String> v = new Vector<String>();
v.add("a");
v.add("b");
v.add("c");
v.add("d");
v.remove(1);
v.set(0, "hello");
System.out.println(v.get(0));
System.out.println(v.size());
v.clear();
System.out.println(v.isEmpty());
// 遍历的方式三种 普通for 迭代器 增强for
}
}
3. Set接口
Set接口存储一组唯一,无序的对象,不允许有重复内容,即不允许两个对象equals方法比较为true,hashCode也相同
3.1 HashSet
HashSet 特点 :无序 不能重复 去除重复的原理 两个对象equals比较为true 并且hashCode相同
底层是有一个HashMap维护的
public class TestHashSet {
public static void main(String[] args) {
HashSet<String> set = new HashSet<String>();
set.add("a");
set.add("a");
set.add("A");
set.remove("a");
for (String v : set) {
System.out.println(v);
}
Iterator<String> iterator = set.iterator();
while(iterator.hasNext()) {
System.out.println(iterator.next());
}
set.clear();
System.out.println(set.isEmpty());
System.out.println(set.size());
HashSet<Student> stuSet = new HashSet<Student>();
Student stu1 = new Student("赵四", 25);
Student stu2 = new Student("赵四", 25);
Student stu3 = new Student("赵四", 25);
stuSet.add(stu1);
stuSet.add(stu2);
stuSet.add(stu3);
System.out.println(stuSet.size());
}
}
public class Student implements Comparable<Student>{
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
@Override
public int compareTo(Student stu) {
if(this.getAge() > stu.getAge()) {
return 1;
}else if(this.getAge() < stu.getAge() ) {
return -1;
}
return 0;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
}
3.2 TreeSet
TreeSet底层维护的是一个TreeMap
有序的Set集合 比较的顺序 元素必须实现Comparable接口,重写compareTo方法
public class TestTreeSet {
public static void main(String[] args) {
TreeSet<String> set = new TreeSet<String>();
set.add("a");
set.add("d");
set.add("f");
set.add("c");
for (String v : set) {
System.out.println(v);
}
Iterator<String> iterator = set.iterator();
while(iterator.hasNext()) {
System.out.println(iterator.next());
}
TreeSet<Student> stuSet = new TreeSet<Student>();
Student stu1 = new Student("赵四1", 26);
Student stu2 = new Student("赵四2", 23);
Student stu3 = new Student("赵四3", 25);
stuSet.add(stu1);
stuSet.add(stu2);
stuSet.add(stu3);
for (Student stu : stuSet) {
System.out.println(stu);
}
}
}
3.3 LinkedHashSet
一个基于双向链表的Set集合 有序的 按插入顺序排序
public class TestLinkedHashSet {
public static void main(String[] args) {
LinkedHashSet<Integer> set = new LinkedHashSet<Integer>();
set.add(110);
set.add(11);
set.add(12);
set.add(3);
set.remove(11);
System.out.println(set.size());
// set.clear();
System.out.println(set.isEmpty());
for (Integer i : set) {
System.out.println(i);
}
Iterator<Integer> it = set.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
}
}
4. Map接口
Map用于保存具有映射关系的数据,里边保存两组数据,key和value
Map的主要方法
| 方法名 | 作用 |
|---|---|
| clear( ) | 清空Map中的所有元素 |
| size( ) | 返回Map中的元素个数 |
| containsKey(Object key) | 判断Map中是否包含某个键值 |
| containsValue(Object value) | 判断Map中是否包含某个值 |
| get(Object key) | 根据键值获取Map中的值 |
| isEmpty( ) | 判断Map是否为空 |
| KeySet( ) | 返回Map中所有key组成的Set集合 |
| put(Object key,Object value) | 添加一对键值对,如果键值相同,则会覆盖原来的键值对 |
| putAll(Map m) | 将指定Map中的键值对复制到Map中 |
| remove(Object key) | 根据键值移除指定键值对 |
| entrySet( ) | 返回Map中所包含的键值对组成的Set集合,每个集合元素都是Map |
内部类Entry的方法
| 方法名 | 作用 |
|---|---|
| getKey( ) | 返回该Entry里包含的key值 |
| getValue( ) | 返回该Entry里包含的value值 |
| setValue(V value) | 设置该Entry里包含的value值,并返回新设置的value值 |
4.1 HashMap
HashMap常用方法
public static void main(String[] args) {
HashMap<String,String> map = new HashMap<String,String>();
map.put("CN", "中国");
map.put("US", "美国");
map.put("JP", "日本");
map.put("KR", "韩国");
System.out.println(map.size());
System.out.println(map.remove("JP")); // 删除
System.out.println(map.size()); // 长度
map.put("CN", "中华人民共和国"); // 存放
System.out.println(map.get("CN")); // 获取
map.replace("US", "美国佬");
System.out.println(map.get("US"));
map.clear();
System.out.println(map.isEmpty());
}
HashMap遍历方式:
1.获取所有的键
Set<String> keySet = map.keySet();
for(String key : keySet) {
System.out.println(key + "\t" + map.get(key) );
}
2.获取所有的值
Collection<String> values = map.values();
for(String v : values) {
System.out.println(v);
}
3.获取所有键的迭代器
Iterator<String> iterator = map.keySet().iterator();
while(iterator.hasNext()) {
String key = iterator.next();
System.out.println(key + "\t" + map.get(key));
}
4.获取所有值的迭代器
Iterator<String> iterator2 = map.values().iterator();
while(iterator2.hasNext()) {
System.out.println(iterator2.next());
}
5.获取所有键值对组成
Set<Entry<String, String>> entrySet = map.entrySet();
for(Entry<String,String> entry : entrySet) {
System.out.println(entry.getKey() + entry.getValue());
}
6.获取所有键值对的迭代器
Iterator<Entry<String, String>> iterator3 = map.entrySet().iterator();
while(iterator3.hasNext()) {
Entry<String, String> next = iterator3.next();
System.out.println(next.getKey() + next.getValue());
}
HashMap在JDK8以后的数据结构为:数组+单向链表+红黑树
HashMap中的元素是Node(节点),每个节点包含四个部分:key值、value值、根据key计算出来的hash值和下一个元素的引用next
HashMap数据的存放过程:
当我们调用put方法往HashMap中存储数据,会先根据key的hash值找到当前元素应该存放在数组中的位置,
如果此位置没有元素,则直接存放,
如果此位置有元素,那么向下延伸为单向链表
如果链表的长度大于8并且元素的总个数超过64 那么单向链表转换为红黑树
在我们使用过程中,我们会删除元素,如果红黑树节点数小于6,将红黑树再次转换为链表
HashMap中的两个重要的数据
16 表示数组的长度为初始长度16
0.75 表示数组的使用率达到75% 就扩容 扩容两倍 使用resize() 方法
4.2 Hashtable
Hashtable (JDK1.0) 提供与HashMap相同的API 并且不允许null作为键或者值 线程安全
初始长度为11 负载因子0.75 扩容 rehash() 两倍+1
HashMap与Hashtable的区别?
| HashMap | Hashtable |
|---|---|
| 线程不安全 | 线程安全 |
| 允许null键和值 | 不允许null键和值 |
| JDK1.2 | JDK1.0 |
public class TestHashtable {
public static void main(String[] args) {
Hashtable<Integer,String> table = new Hashtable<Integer,String>();
table.put(1, "a");
table.put(2, "b");
table.put(3, "c");
table.put(4, "d");
// table.put(null, null);
System.out.println(table.remove(1));
System.out.println(table.size());
table.replace(2, "hello");
System.out.println(table.get(2));
//table.clear();
System.out.println(table.isEmpty());
// 遍历方式与HashMap一致
Set<Integer> keySet = table.keySet();
for (Integer key : keySet) {
System.out.println(table.get(key) + "\t" + key);
}
Collection<String> values = table.values();
for (String v : values) {
System.out.println(v);
}
Set<Entry<Integer, String>> entrySet = table.entrySet();
for (Entry<Integer, String> entry : entrySet) {
System.out.println(entry.getKey() + entry.getValue());
}
}
}
4.3 LinkedHashMap
LinkedHashMap是基于双向链表的有序的Map集合 顺序为插入顺序
public class TestLinkedHashMap {
public static void main(String[] args) {
LinkedHashMap<String,String> map = new LinkedHashMap<String,String>();
map.put("a", "A");
map.put("b", "B");
map.put("c", "C");
map.put("d", "D");
System.out.println(map.remove("a"));
map.replace("b", "hello");
System.out.println(map.get("b"));
System.out.println(map.size());
// map.clear();
System.out.println(map.isEmpty());
// 遍历方式与之前Map集合一致
Set<String> keySet = map.keySet();
for (String key : keySet) {
System.out.println(key + "---" + map.get(key));
}
Collection<String> values = map.values();
for (String v : values) {
System.out.println(v);
}
Set<Entry<String, String>> entrySet = map.entrySet();
for (Entry<String, String> entry : entrySet) {
System.out.println(entry.getKey() + "===" + entry.getValue());
}
}
}
4.4 TreeMap
基于树的Map集合,有序,是按照键的比较顺序
如果使用自定义的类型作为TreeMap键,必须实现Comparable接口,重写compareTo方法来指定比较规则,否则运行报错
public class TestTreeMap {
public static void main(String[] args) {
TreeMap<Integer,String> map = new TreeMap<Integer,String>();
map.put(1, "abc");
map.put(20, "hello");
map.put(17, "hhh");
map.put(5, "666");
// 其他方法 增删改查 是否为空 与之前map集合一致
// 遍历方式与之前也一致
Set<Integer> keySet = map.keySet();
for (Integer key : keySet) {
System.out.println(map.get(key) + "===" + key);
}
System.out.println("============================================");
TreeMap<Student,String> map1 = new TreeMap<Student,String>();
Student stu1 = new Student("赵四", 25);
Student stu2 = new Student("广坤", 21);
Student stu3 = new Student("大拿", 22);
map1.put(stu1, "abc");
map1.put(stu2, "abc");
map1.put(stu3, "abc");
Set<Entry<Student, String>> entrySet = map1.entrySet();
for (Entry<Student, String> entry : entrySet) {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
}
}
public class Student implements Comparable<Student>{
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
@Override
public int compareTo(Student stu) {
if(this.getAge() > stu.getAge()) {
return 1;
}else if(this.getAge() < stu.getAge() ) {
return -1;
}
return 0;
}
}
4.5 Properties
Properties类用于存放成对的字符串数据,实际开发中用于读取配置文件,所以此类不要使用从父类Hashtable继承来的put或者putAll方法,而应使用setProperty
public class TestProperties {
public static void main(String[] args) {
System.out.println(System.getProperty("java.version"));
System.getProperties().list(System.out);
Properties p = new Properties();
// p.put(1, "abc");
p.setProperty("a", "A");
p.setProperty("b", "B");
System.out.println(p.get("a"));
p.list(System.out);
}
}
5. Collections
Collections和Collection的区别?
前者是工具类 后者是集合父接口
工具类提供的有操作集合一些方法 比如查找集合最大、最小元素,集合排序等
public class TestCollections {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<Integer>();
list.add(101);
list.add(202);
list.add(30);
list.add(55);
System.out.println(Collections.max(list));
System.out.println(Collections.min(list));
Collections.sort(list);
System.out.println("============================");
for (Integer i : list) {
System.out.println(i);
}
// 二分查找的前提必须先排序
System.out.println(Collections.binarySearch(list, 101));
}
}
6. 泛型
泛型 用于统一数据类型 并且扩展代码 相当于是一个占位符 表示未知的类型
泛型不能类型转换 不能多态
List<类型A> 表示此list只能存放A类型的数据
泛型应用场景:
类、方法、形参、接口
泛型字母表示的含义 通常是单词首字母
T type 类型
E Element 元素
P Parameter 参数
R Return 返回值
K Key 键
V Value 值
以上字母是业界公认有特定含义的简写 可以任意写字母 也可以小写 但是不要太随意
public class Test {
public static void main(String[] args) {
A<String> a = new A<String>();
a.m1("a");
a.m2();
A<Integer> a1 = new A<Integer>();
a1.m1(20);
a1.m2();
}
}
class A<T>{
void m1(T t) {
}
T m2() {
return null;
}
public static <P> List<P> m3() {
List<P> list = new ArrayList<P>();
return list;
}
}
interface B<P,R>{
R m1(P p);
}
class C implements B<String,Integer>{
@Override
public Integer m1(String p) {
return null;
}
}
class D implements B<Float,Character>{
@Override
public Character m1(Float p) {
return null;
}
}
class Animal{}
class Dog extends Animal{}
class Cat extends Animal{}
class E{
void m1(Set<Animal> set) { }
// <? extends Animal> 表示Animal或者Animal的子类
void m2(List<? extends Animal> list) {}
// <? super Dog> 泛型为 可以是Dog类 或者Dog类的父类
void m3(Map<Set<? super Dog>,String> map) {}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号