仿射变换与投影变换
介绍基本的图形变换,仿射变换和投影变换的内容和关系,最后再简单讲解下RANSAC算法。这套内容常用于图片和图片的特征点匹配、图片融合等场景。
仿射变换和单应矩阵
首先明确:二者的应用场景相同,都是针对二维图片的变换。仿射变换affine是透视变换的子集,透视变换是通过homography单应矩阵实现的。
从数学的角度,homography即H阵,是一个秩为3的可逆矩阵:

仿射矩阵是:

由于第三行没有未知数,仿射矩阵最常用的是两行三列的形式。计算H阵需要4对不共线点,计算仿射阵只需要3对不共线的点。
通常会才用RANSAC方法从多对匹配点中计算得到精确、鲁棒的结果。affine一般比homography更稳定一些,所以可以先计算affine,然后再用affine作为homography的初始值,进行非线性优化。
仿射变换的实际意义
仿射变换在图形中的变换包括:平移、缩放、旋转、斜切及它们的组合形式。这些变换的特点是:平行关系和线段的长度比例保持不变。

平移变换

数学形式:

矩阵形式:

尺度变换

矩阵形式:

旋转变换

矩阵形式:

刚体运动:旋转缩放平移

矩阵形式:

斜切变换

矩阵表示:

这个也是更为一般的仿射变换的形式,xy轴的旋转是两个自由度。
透视投影变换的实际意义
首先,继续上面的示例,透视变换的矩阵形式:

这个变换看似是很随意的,变化的可能性也是非常多。但投影变化具有其明确的意义:共面点成像。
先回顾下摄像机模型:
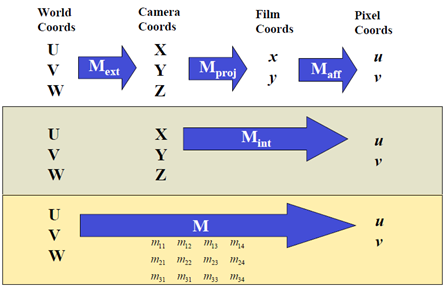
世界坐标系映射到摄像机坐标系:Pc即上图的Mext
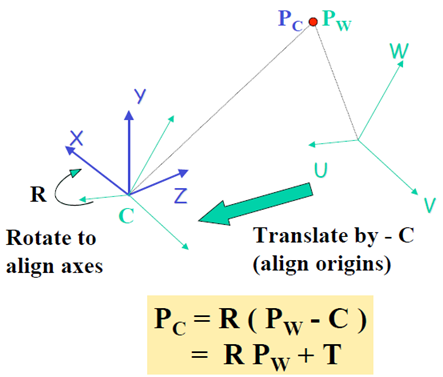

其中Maff表示像素坐标系和单位距离坐标系之间的转化,与硬件设备相关。不考虑像素坐标系,在以米等单位距离为尺度的笛卡尔坐标系中,有:

对于共面点,我们可以另其一个坐标为0(肯定存在一个适当的世界坐标系满足的),不妨设为第三维度,上述矩阵可以得到简化:

最终得到的3*3的矩阵,称之为“Homography矩阵”,该矩阵是可逆的。
研究共面点成像有什么意义呢?两个不同位置的相机,共面点对应有两个单应矩阵H1和H2。
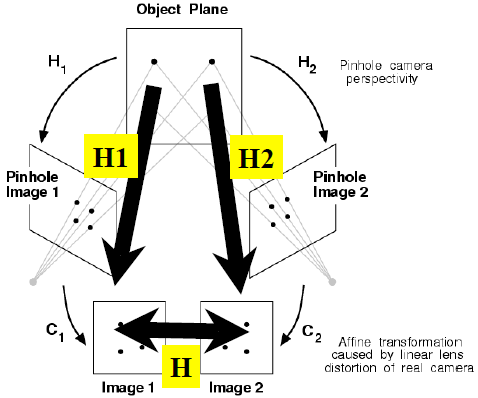
两个角度拍摄的一堆共面点,可以通过H1和H2以及C阵(上面的Mext)得到变换矩阵H。矩阵的形式:

求解上述方程,有两种方式,一种是设:![]() ;两一种是添加约束:
;两一种是添加约束:![]() 。
。
选择第一种约束:

得到:

写成矩阵的形式:

线性最小二乘为题:
1997年,Hartley发表“In Defense of the Eight Point Algorithm”对原始8点算法进行改进,在构造解的方程之前对输入的数据进行适当的归一化。即在形成8点算法的线性方程组之前,图像点的一个简单变换(平移或变尺度)将使这个问题的条件极大地改善,从而提高结果的稳定性。而且进行这种变换所增加的计算复杂性并不显著。算法具体过程具体如下:
a.对原始图象坐标做一个平移变换,使原来以左上角为原点的图象坐标变成以所有图像点的重心为原点的图像坐标;
b.再对图象坐标做一个尺度变换,使得点到原点的平均距离为![]() 。
。
分别对两幅图像进行以上两步变换,然后将变换后的图像坐标作为输入数据计算基础矩阵。计算过程如下:
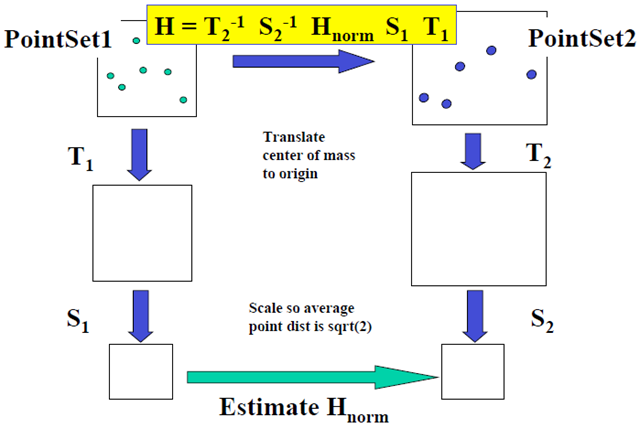
第二种求解方式:这里可以使用SVD分解

得到:

矩阵的形式:
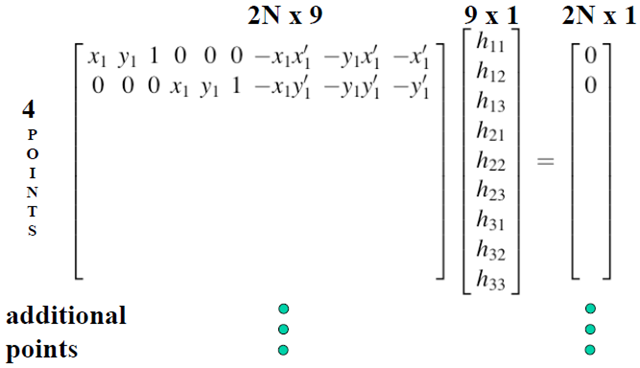
齐次最小二乘法:Ah=0,h的解是A的SVD分解V的最后一列向量,右奇异向量还是单位向量,正好满足条件。
透视变换的应用主要有两个:消除透视投影导致的失真,校正图像;图像拼接。


RANSCK算法剔除误匹配
相比,上面的矩阵求解,Ransck的优势是:消除歧义点,速度更快。
采样次数设定
如果想要得到好的结果而又使计算量不至于很大,就需要确定一个合适的采样次数。采样次数N足够大,令由s个点组成的随机样本中至少有一次没有外点的概率为p,通常p取0.99。假定![]() 是任意选择的数据点为内点的概率,那么
是任意选择的数据点为内点的概率,那么![]() 是其为外点的概率。那么,至少需要N次选择(每次s个点),其中
是其为外点的概率。那么,至少需要N次选择(每次s个点),其中![]() ,从而得到采样次数N为:
,从而得到采样次数N为:
![]()
但是,通常数据中的错误率![]() 是未知的,在开始抽样时对数据错误率
是未知的,在开始抽样时对数据错误率![]() 给出一个最坏的估计,然后根据上式计算出在此最坏估计情况下所需要的抽样次数N,在抽样过程中,不断修正
给出一个最坏的估计,然后根据上式计算出在此最坏估计情况下所需要的抽样次数N,在抽样过程中,不断修正![]() 和N的值,一直到当前抽样次数大于N的值,则终止抽样。在一开始时,由于对数据错误率
和N的值,一直到当前抽样次数大于N的值,则终止抽样。在一开始时,由于对数据错误率![]() 给出一个最坏的估计,所以估计出来的N值会非常大,但由于在抽样过程中大量外点被剔除,
给出一个最坏的估计,所以估计出来的N值会非常大,但由于在抽样过程中大量外点被剔除,![]() 值不断减小,则N的值也会急剧减小,向真值不断逼近。确定RANSAC采样次数的自适应算法如下所示:
值不断减小,则N的值也会急剧减小,向真值不断逼近。确定RANSAC采样次数的自适应算法如下所示:

RANSAC算法剔除误匹配
把RANSAC算法应用于假设对应集,以求得单应估计和与此估计相一致的(内点)对应。样本大小是4,因为四组对应确定一个单应。采样次数由每个一致集中数据错误率自适应地设置。这里有两个问题需要继续进行讨论:此时的“距离”是什么;以及怎样去选择样本。
距离测量:通过单应矩阵![]() 估计一组对应的误差最简单的方法是采用对称转移误差
估计一组对应的误差最简单的方法是采用对称转移误差![]() ,其中
,其中![]() 是点对应。一个更好但是开销更大的距离测量方法是重投影误差
是点对应。一个更好但是开销更大的距离测量方法是重投影误差![]() ,其中
,其中![]() 是完全对应。这种测量开销大的原因是必须计算
是完全对应。这种测量开销大的原因是必须计算![]() 。另一种方法是采用Sampson误差。
。另一种方法是采用Sampson误差。
样本选择:这里存在两个问题:第一,退化的样本应该丢弃。例如,如果四点中有三个点共线则单应无法得到;第二,组成样本的点应该在整个图像中有合理的空间分布。空间的分布采样可以这样来实施:划分图像并通过随机采样的适当加权来保证属于不同小区的点比同属于一个区的点有更大可能性进入样本。
在RANSAC算法估计内点结束之后,可以得到获得最大的一致集。为了使得匹配结果更加精确,用得到的所有内点(而不是仅仅用样本的四点)来改进单应估计;然后在通过最小化ML(极大似然)代价函数从内点中计算进一步改进单应估计。最后一步首先在内点上执行一个ML估计,然后用新估计的![]() 重新计算内点,并重复这一循环直到内点数目收敛。
重新计算内点,并重复这一循环直到内点数目收敛。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号