Group Normalization笔记
作者:Yuxin,Wu Kaiming He
机构:Facebook AI Research (FAIR)
摘要:BN是深度学习发展中的一个里程碑技术,它使得各种网络得以训练。然而,在batch维度上进行归一化引入如下问题——BN的错误会随着batch size的减小而急剧增加,这是由batch不正确的统计估计造成的。这就限制了BN用于训练由于显存消耗不足而导致batch size受限的大型网络和迁移特征到如检测、分割以及视频等计算机视觉任务。在此论文中,作者提出了Group Normalization(GN)作为BN的简单替代。GN将通道划分成组然后在每一个组中计算用于归一化的均值和方差。GN的计算不依赖于batch size,而且它的准确率在各种batch size下是稳定的。在ImageNet数据集上训练ResNet-50,当使用batch size 为2的时候,GN获得的错误比在相应位置上使用BN低10.6%;当使用典型的batch size,GN比BN相对好,同时相对于其它归一化变体好。此外,GN可以可以很自然地从预训练模型到微调。在COCO的检测、语义分割以及Kinetics数据集的视频分类任务中,在相应位置上使用GN可以比BN获得更出色的表现。这显示了GN可以在很多任务中有效地替换强大的BN。BN可以通过少量代码来实现。
简介:BN是深度学习中一个很有效的组件,极大的推动了计算机视觉的发展。BN是通过计算一个(mini-)batch内的均值和方差来归一化特征的。众多实践证明使用BN的网络易于优化以及使得很深的网络得以收敛。batch统计的随机不确定性也起到有利于泛化的正则化作用。BN已经成为含多先进算法的基石。
虽然BN非常成功,但是在batch维度上截然不同的归一化行为也展露它的不足。在实践中,BN需要足够大的batch size才能达到显著效果。小的batch size会引起batch统计上的错误估计,这会很大地增加模型错误。下图可以看出GN比BN优秀。
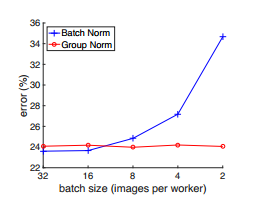
图中:是ResNet-50在ImageNet数据集上使用8个GPU进行训练,以及在验证集上验证。图中折线,蓝色BN,红色GN。可见随着batch size的减小,BN的错误率增加,而GN不依赖于BS,其错误率相对稳定。在batch size为2的同等条件下,GN获得比BN低10%的错误率。
因此,许多如今的模型由于显存的限制都使用了精心设计的batch size。严重地依赖于BN的效果,变成了限制人们取探索那些大容量但消耗资源的模型。batch size上的限制,会更加要求诸如检测、分割、视频识别的计算机视觉任务以及其它高层系统基于它而建立。比如,Fast/er 和Mask R-CNN框架因为使用了大的分辨率而只能使用batch size为1或者2,其中BN通过转变成线性层进行“冻结”。在使用3D卷积的视频分类任务中,时空特征的存在引入了关于时间长度(temporal length)和batch size的一个权衡。由于BN的使用通常需要系统在模型设计和batch size之间的妥协。
在这篇论文中提出GN,作为BN的一个简单替代。我们注意到许多的特征,类似SIFT和HOG组间特征以及涉及到组间归一化。例如,一个HOG向量是一些空间单元的输出。其中每一个单元由一个已归一化的有向直方图。类似地,我们提出GN作为一个将通道划分成组以及归一化组内的这些特征的层。GN并没有采用batch维度,因此它独立于batch sizes。
除了GN,BN之外,还有LN(Layer Normalization) 和IN(Instance Normalization),这两个也一样防止在batch维度上进行归一化,这个方法在训练序列模型(RNN/LSTM)或者生成模型(GANs).但是正如实验中给出,LN和IN在视觉识别任务中均未能很好表现。而对于GN则表现出较好的结果。换言之,GN可以用于代替LN和IN在序列模型和生成模型中的表现。
相关工作:
归一化层在BN出现之前已经在深度网络中得到广泛应用,Local Response Normalization(LRN)是AlexNet中的组件,它通过计算每一个像素的一个小的邻域的统计量。(待续)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号