8.6 高速缓存的设计要点
计算机组成
8 存储层次结构
8.6 高速缓存的设计要点

高速缓存是一个非常精细的部件,想让它高效地工作,就得在设计时,进行仔细地权衡。想要设计出一个优秀的高速缓存部件,我们就得从几个基本概念开始入手。
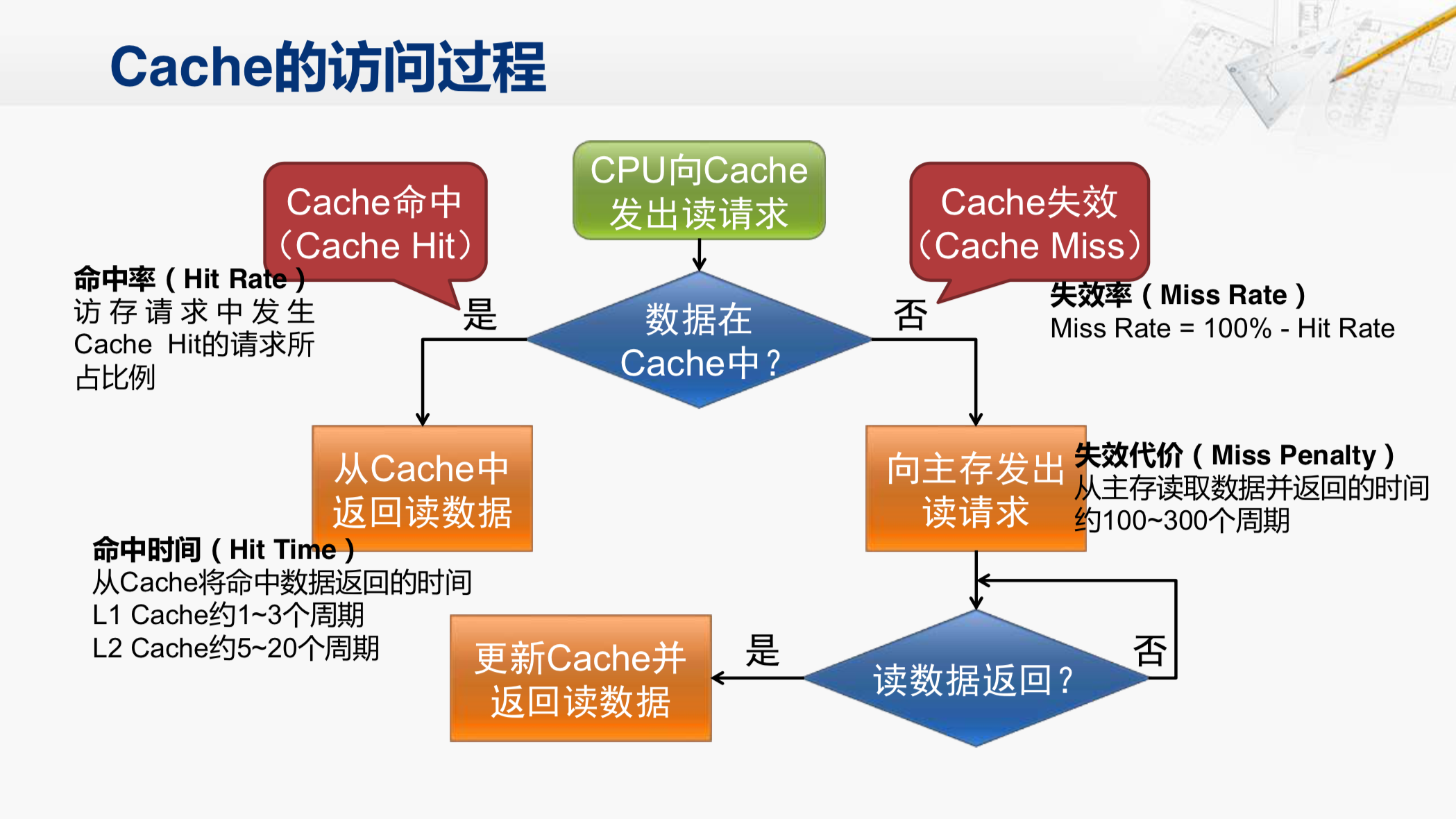
我们再来看一看Cache的访问过程。如果CPU向Cache发出了读请求,Cache就会检查对应的数据是否在自己内部。
如果在,我们就称为Cache命中。有项性能指标就叫做命中率,这说的是CPU所有访存请求中发生了Cache命中的请求所占的比例。如果命中就从Cache内部向CPU返回数据。从Cache中将命中的数据返回的时间,就称为命中时间,这也是一个重要的性能参数。现在的CPU当中,一级开始的命中时间大约是1到3个周期,二级Cache的命中时间大约是5到20个周期。
如果数据不在Cache里,我们就称为Cache失效,对应的就是失效率。失效率和命中率加在一起肯定是百分之一百。在失效之后,Cache会向主存发起读请求,那么等待从主存中返回读数据的这个时间,我们就称为失效代价。现在通常需要在100到300个时钟周期之后,才能得到读的数据。

那要评价访存的性能,我们经常会用到平均访存时间这个指标,这个指标就是用刚才介绍的那几个参数推算出来的。平均访存时间就等于命中时间,加上失效代价乘以失效率。想要提高访存的性能,我们就得降低平均访存时间,要做的就是分别降低这三个参数,这就是提高访存性能的主要途径。
其中想要降低命中时间,就要尽量将Cache的容量做得小一些,Cache的结构也不要做得太复杂。但是小容量的结构简单的Cache,又很容易发生失效,这样就会增加平均访存时间。其中如果要减少失效代价, 要么是提升主存的性能,要么是在当前的高速缓存和主存之间再增加一级高速缓存。那在新增的那级高速缓存当中,也需要面临这些问题。所以,这三个途径并不是独立的,它们是交织在一起相互影响。那我们先重点来看一看命中率这个因素。
如果有一个Cache的命中率是97%,我们假设命中时间是3个周期,失效代价是300个周期。那么平均访存时间就是12个周期。那如果我们有一个方法可以在不影响命中时间和失效代价的情况下,将命中率提高到99%,这时候的平均访存时间就降低到了6个周期。所以,虽然命中率只提高了2%,看起来并不起眼,但是访存性能却提高了一倍,这是非常大幅度的提升。所以,对于现在的Cache来说,能够提高一点点命中率,都可以带来很好的性能提升。
那哪些因素会影响命中率呢?

或者我们反过来看,Cache失效会由哪些原因造成?
有一种叫做义务失效。从来没有访问过的数据块,肯定就不在Cache里。所以,第一次访问这个数据块所发生的失效,就称为义务失效。义务失效是很难避免的。
第二种失效原因称为容量失效。如果这个程序现在所需的数据块已经超过了这个Cache容量的总和,这样不管我们怎么去精巧地设计这个Cache,总会发生失效。当然容量失效可以通过扩大Cache来缓解,但是增加了Cache容量之后,一方面会增加成本,另一方面可能也会影响到命中时间。所以,也需要综合地考虑。
第三种失效称为冲突失效。也就是在Cache并没有满的情况下,因为我们将多个存储器的位置映射到了同一个Cache行,导致位置上的冲突而带来的失效。我们重点就来看一看如何解决这个问题。这个问题就称为Cache的映射策略。
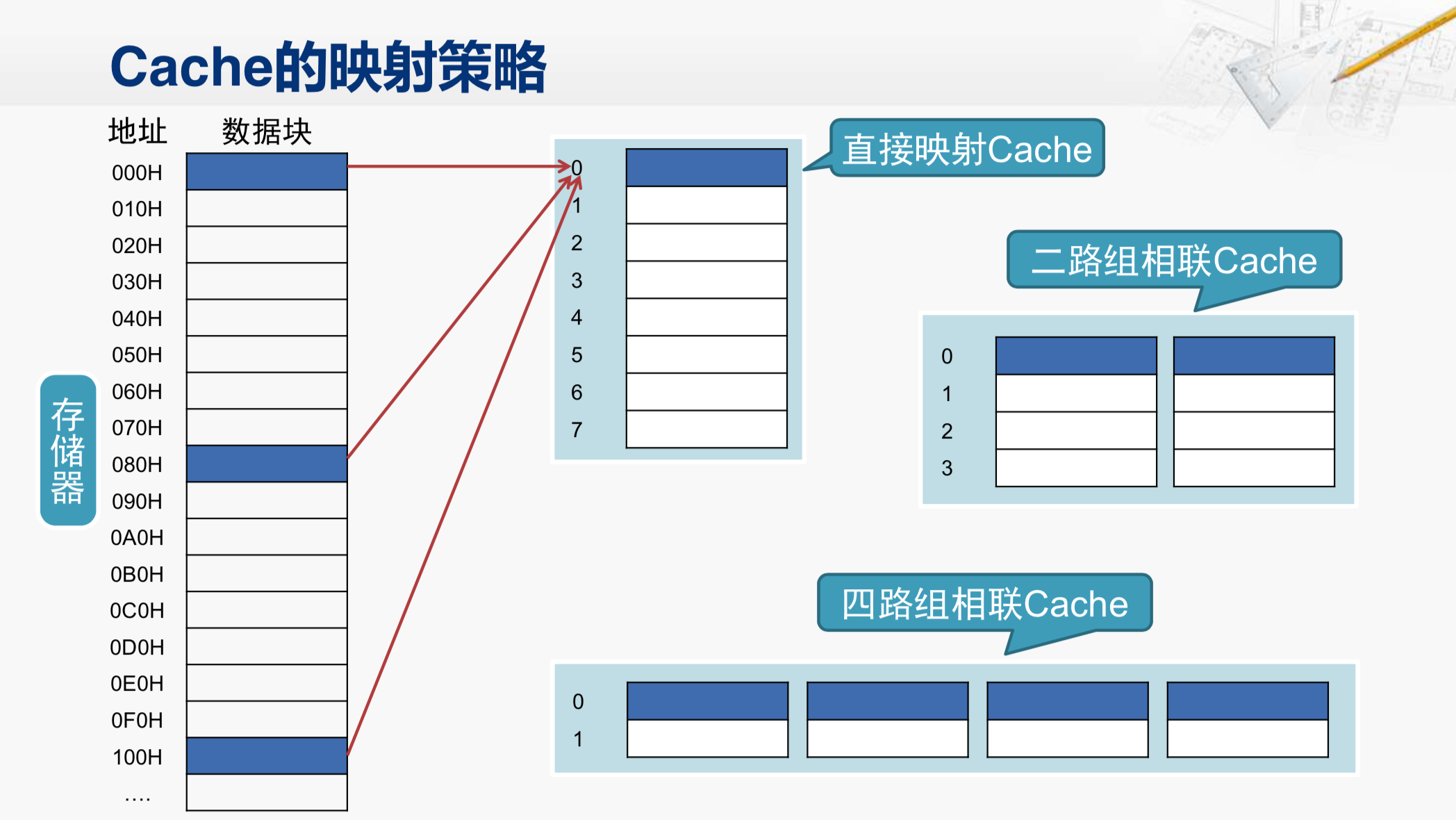
那这是一块存储器的区域,我们还是按照每16个字节一个数据块(十六进制地址最低位为0)的形式把这块存储器的区域画出来。所以,地址这一列标记的是各个数据块的起始地址,每个地址之间正好相差16。那如果我们有一个8表项的Cache,那么就采用我们之前介绍过的那种存放方法。地址为0的数据块是要放在表项0当中;而地址为080的数据块,也得放在表项0当中;同样地址为100的数据块,也要存放在这个表项中。这其实就是把内存分成每8个数据块为一组,任何一组当中的第0个数据块,都会被放在表项0,第一个数据块都会被放在表项1,这样的Cache的映射策略就叫做直接映射。它的优点在于硬件结构非常简单,我们只要根据地址就可以知道对应的数据块应该放在哪个表项,但是,它的问题也很明显。如果我们在程序当中正好要交替地不断访问两个数据,不妨称为数据A和数据B。如果数据A在地址为0的这个数据块当中,而数据B在地址080的这个数据块当中,那在访问到数据A时,会把地址0的这个数据块调到Cache当中来,然后把对应的数据A交给CPU;然后CPU又需要访问数据B,其后开始发现,数据B不在Cache当中,所以又要把080对应的这个数据块调进来,替换掉原有的表项0当中的数据,然后再将数据B交给CPU。然后,接下来CPU又访问到数据A,那Cache又要把地址为000H的这个数据块调进来,再次覆盖表项0。那如果CPU不断地在交替访问数据A和数据B,这段时间的Cache访问每一次都是不命中的,这样的访存性能还不如没有Cache,而这时Cache当中其他的行都还是空着的,根本没有发挥作用。所以,这就是这个映射策略上的问题。
为了解决这个问题,我们可以做一些改进,在不增加Cache总的容量情况下,我们可以将这8个Cache行分为两组,这就是二路组相联的Cache。这样刚才那种交替地访问数据A和数据B的情况,就不会有问题了,因为CPU访问数据A时,就会把地址0对应的数据块放在这里,而接下来在访问数据B时,就会把地址080对应的数据块放在这里。然后,再反复地访问数据A和数据B,都会在Cache中命中,这样访存的性能就会非常好。当然如果CPU在交替地访问这三个数据(000H,080H,100H)块当中的数据,那么二路组相联的Cache又会出现连续不命中的情况。所以,我们还可以对它进一步切分。这就是一个四路组相联的Cache。
我们是不是可以无限制地切分下去呢?这倒是可以的。如果这个Cache总共只有8行,而我们把它分成八路组相联,那也就是说,内存当中任一个数据块都可以放到这个Cache当中的任何一个行中,而不用通过地址的特征来约定固定放在哪一个行,这样结构的Cache就叫做全相联的Cache。这样的设计灵活性显然是最高的,但是它的控制逻辑也会变得非常的复杂。我们假设CPU发了一个地址,Cache要判断这个地址是否在自己内部,它就需要把可能包含这个地址的Cache行当中的标签取出来进行比较。对于直接映射的Cache,只需要取一个标签来比较就行;二路组相联的时候,就需要取两个标签同时进行比较;四路组相联的时候就需要取出四个标签来比较;而在全相联的情况下,那就需要把所有行当中的标签都取出来比较。
这样的比较需要选用大量的硬件电路,既增加了延迟,又增加了功耗。如果划分的路数太多,虽然有可能降低了失效率,但是却增加了命中时间,这样就得不偿失了。而且话又说回来,增加了路数,还不一定能够降低失效率。

因为在多路组相联的Cache当中,同一个数据块可以放在不同的地方。如果这些地方都已经被占用了,就需要去选择一行替换出去,这个替换算法设计得好不好,就对性能有很大的影响。如果这个Cache选择替换出去的行,恰恰总是过一会就要使用到的那个数据块,那这样性能的表现就会很差。
现在常见的Cache替换算法有这几种。最简单的是随机替换,这个性能显然不会很好。然后还有轮转替换,也就是按照事先设定好的顺序依次地进行替换,如果是四路组相联,上一次替换了第0路,这一次就替换第1路,下一次就替换第2路,再下一次就替换第3路。这个从硬件设计设计上来说比较简单,但是性能也一般。性能比较好的替换算法,是最近最少使用的替换算法,简称为LRU,它需要额外的硬件来记录访问的历史信息,在替换的时候,选择距离现在最长时间没有被访问的那个Cache行进行替换。在使用中,这种方法的性能表现比较好,但是其硬件的设计也相当的复杂。所以,映射策略和替换算法都需要在性能和实现代价之间进行权衡。
那我们再来看看一些Cache设计的实例。

在X86系列CPU当中,486是最早在CPU芯片内部集成了Cache的,但它使用的是一个指令和数据共用的Cache。这个Cache有一个很明显的缺点,那就是指令和数据的局部性会互相影响。因为指令和数据一般是存放在内存中的不同区域,所以它们各自具有局部性。利用在执行一个要操作大量数据的程序,这些数据就会很快地占满Cache,把其中的指令都挤出去了,在这个时候,执行一条指令,取指的阶段很可能是Cache不命中,需要等待访问存储器,那就需要花很长的时间。而在执行阶段,去取操作数时,却往往会命中Cache,虽然这段时间比较短,但是整个指令执行的时间还是很长。
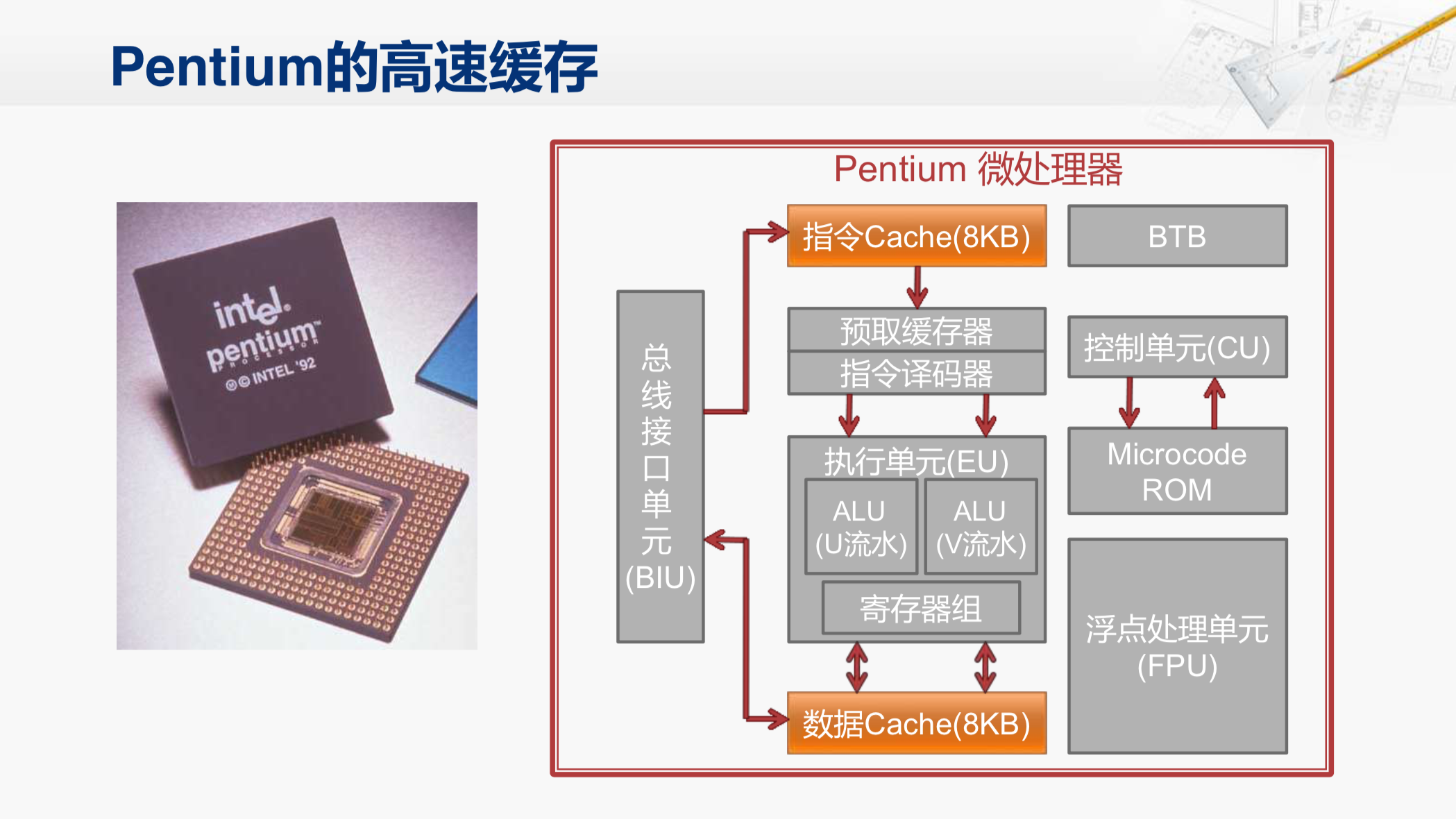
所以到了后来的奔腾,就把指令和数据分成了两个独立的Cache,这样它们各自的局部性就不会相互影响了。
现在大多数CPU的一级Cache都会采用这样的形式。

这个是现在比较先进的Core i7。它内部采用了多级Cache的结构,其中一级Cache是指令和数据分离的各32K个Byte,采用了8路组相联的形式,命中时间是4个周期。所以,在CPU的流水线当中,访问Cache也需要占多个流水级。
那么在这个4核的i7当中,每个处理器核还有自己独享的二级Cache。二级Cache就不再分成指令和数据两个部分了,因为它的容量比较大,指令和数据之间的相互影响就不那么明显。但是二级Cache的命中时间也比较长,需要11个周期,Core i7 CPU的流水线总共也就16级左右,肯定是没有办法和二级Cache直接协同工作的。这也是为什么一级Cache不能做得很大的一个重要原因(做大了需要花费多个流水级)。
在二级Cache之下,还有一个三级Cache。这是由四个核共享的,总共8兆个字节。三级Cache采用了16路组相联的结构,而且容量也很大,达到了8兆个字节,这又导致它的命中时间很长,需要30到40个周期,但它这样的结构命中率会很高,这样就很少需要去访问主存了。
我们可以看到这三级的Cache,它的命中时间从4个周期、11个周期到40个周期,我们再考虑到主存的100到300个周期,就可以看出这个多级Cache + 主存的结构就拉开了明显的层次,在各自的设计时就可以有不同的侧重,相互配合来提升整个系统的性能。

高速缓存的研究已经持续了很长时间,直到今天仍然是一个研究的热点。只不过之前的研究对象是CPU和主存之间的这一级高速缓存,而现在的研究对象则是由多级高速缓存组成的这么一个多层次的结构。不管怎么样,高速缓存技术的研究给我们带来了在可控成本之下,尽可能高的系统性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号