并查集详解
1.1 并查集概念
并查集是一种非常精巧而实用的数据结构,主要用于处理一些不相交集合的合并问题。一些常见的用途有连通子图、最小生成树的Kruskal算法和求最近公共祖先等。
1.2 操作
并查集的基本操作有两个
Union:把两个元素所在的集合合并,要求两个元素所在集合不相交,如果相交则不合并。
Find:找到指定元素所在集合的根;该操作也可以用于判断两个元素是否位于同一个集合,只要将它们各自的根比较一下即可。
1.3 实现
并查集的实现原理也比较简单,就是使用树来表示集合,树的每个结点就表示集合中的一个元素,如图:

图中有两棵树,分别对应两个集合,其中第一个集合为 {a, b, c, d},代表元素是 a;第二个集合为 {e, f, g},代表元素是 e。树的节点表示集合中的元素,指针表示指向父节点的指针,根节点的指针指向自己,表示其没有父节点。沿着每个节点的父节点不断向上查找,最终就可以找到该树的根节点,即该集合的代表元素。 假设使用一个足够长的数组来存储树节点(很类似静态链表),即父节点是其自身:

接下来,就是find 操作了,如果每次都沿着父节点向上查找,那时间复杂度就是树的高度,完全不可能达到常数级。这里需要应用一种非常简单而有效的策略——路径压缩。
最后是合并操作Union,并查集的合并也非常简单,就是将一个集合的树根指向另一个集合的树根,如图所示。

1.3.1 路径压缩
路径压缩,就是在每次查找时,令查找路径上的每个节点都直接指向根节点,如图所示。

2、并查集模板
#include <iostream> #define VERTICES 3 // INIT void initialise(int *parent) { for(int i = 0; i < VERTICES; i++) parent[i] = i; } // FIND int find_root(int x, int *parent) { if(parent[x] != x) parent[x] = find_root(parent[x], parent); return parent[x]; } // UNION void union_vertices(int x, int y, int *parent) { parent[find_root(x, parent)] = find_root(y, parent); } int main() { int parent[VERTICES] = {0}; int connect[3][3] = { {1, 1, 0}, {1, 1, 0}, {0, 0, 1} }; initialise(parent); for(int i = 0; i < VERTICES; i++) for(int j = i + 1; j < VERTICES; j++) if(connect[i][j] == 1) union_vertices(i, j, parent); int r = 0; for(int i = 0; i < VERTICES; i++) if(parent[i] == i) r++; std::cout << "连通分量个数: " << r << std::endl; return 0; }
3、并查集例题
3.1 Leetcode-547 省份数量
题目:
有 n 个城市,其中一些彼此相连,另一些没有相连。如果城市 a 与城市 b 直接相连,且城市 b 与城市 c 直接相连,那么城市 a 与城市 c 间接相连。
省份 是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个 n × n 的矩阵 isConnected ,其中 isConnected[i, j] = 1 表示第 i 个城市和第 j 个城市直接相连,而 isConnected[i, j] = 0 表示二者不直接相连。
返回矩阵中 省份 的数量。
示例:
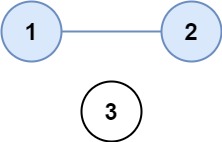
输入:isConnected = [[1, 1, 0], [1, 1, 0], [0, 0, 1]]
输出:2
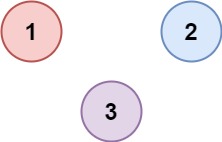
输入:isConnected = [[1, 0, 0], [0, 1, 0], [0, 0, 1]]
输出:3
方法一(DFS):
/** * 解题思路: * 深度优先搜索思路:遍历所有城市,对每个城市来说如果该城市尚未被访问过, * 则从城市开始深度优先搜索,通过举证isConnected得到与该城市直接相连的 * 城市有哪些,这些城市和该城市属于同一个连通分量,然后对这些城市继续深 * 度优先搜索,知道同一个连通分量的所有城市都被访问到,即可得到一个省份。 * 遍历完全部城市以后得到连通分量总数,即为所求。 */ #include <iostream> #include <vector> class Solution { public: /** * 深度优先搜索 * isConnected - 二维矩阵,表明城市连通关系 * vistited - 一维数组,记录城市是否被访问,1表示被访问,0表示未被访问 * provinces - int类型,存储城市个数 * i - int类型,城市编号 * return: void */ void dfs( std::vector<std::vector<int>> &isConnected, std::vector<int> &visited, int provinces, int i) { for(int j = 0; j < provinces; j++) { if(isConnected[i][j] == 1 && !visited[j]) { visited[j] = 1; dfs(isConnected, visited, provinces, j); } } } /** * 寻找符合条件的省份数量(图的连通分量) * isConnected - 二维矩阵,表明城市连通关系 * return: int类型,连通分量个数 */ int findCircleNum(std::vector<std::vector<int>> &isConnected) { int provinces = isConnected.size(); std::vector<int> visited(provinces); int circleNum = 0; for(int i = 0; i < provinces; i++) { if(!visited[i]) { dfs(isConnected, visited, provinces, i); circleNum++; } } return circleNum; } }; int main() { std::vector<std::vector<int>> isConnected = { {1, 1, 0}, {1, 1, 0}, {0, 0, 1} }; Solution findCircles; int result = findCircles.findCircleNum(isConnected); std::cout << result << std::endl; return 0; }
方法二(并查集):
/** * 解题思路: * 初始时,每个城市都属于不同的连通分量,遍历矩阵isConnected, * 如果两个城市间有相连关系,则它们属于同一个连通分量,对它们 * 进行合并。遍历完isConnected的全部元素后,计算连通分量的总数, * 即为省份的总数。 */ class Solution { public: /** * 寻找输入结点的根节点 * index - 当前结点索引 * parent - 一维数组,存储各结点的父节点 * return: int类型,根节点索引 */ int find_root(int index, std::vector<int> &parent) { if(parent[index] != index) parent[index] = find_root(parent[index], parent); return parent[index]; } /** * 合并两个连通分量 * index_1 - 第一个城市结点索引 * index_2 - 第二个城市结点索引 * parent - 一维数组,存储各结点父节点 * return: void */ void union_vertices(int index_1, int index_2, std::vector<int> &parent) { parent[find_root(index_1, parent)] = find_root(index_2, parent); } // 寻找符合条件的省份数量 int findCircleNum(std::vector<std::vector<int>> &isConnected) { int provinces = isConnected.size(); std::vector<int> parent(provinces); for(int i = 0; i < provinces; i++) parent[i] = i; for(int i = 0; i < provinces; i++) for(int j = i + 1; j < provinces; j++) if(isConnected[i][j] == 1) union_vertices(i, j, parent); int result = 0; for(int i = 0; i < provinces; i++) { if(parent[i] == i) result++; } return result; } }; int main() { std::vector<std::vector<int>> isConnected = { {1, 0, 0}, {0, 1, 0}, {0, 0, 1} }; Solution findCircles; int result = findCircles.findCircleNum(isConnected); std::cout << result << std::endl; return 0; }
3.2 Leetcode-990 等式方程的可满足性
题目:
给定一个由表示变量之间关系的字符串方程组成的数组,每个字符串方程 equations[i] 的长度为 4,并采用两种不同的形式之一:"a==b" 或 "a!=b"。在这里,a 和 b 是小写字母(不一定不同),表示单字母变量名。
只有当可以将整数分配给变量名,以便满足所有给定的方程时才返回 true,否则返回 false。
示例 :
1、
输入:["a==b", "b!=a"]
输出:false
解释:如果我们指定,a = 1 且 b = 1,那么可以满足第一个方程,但无法满足第二个方程。没有办法分配变量同时满足这两个方程。
2、
输入:["b==a", "a==b"]
输出:true
解释:我们可以指定 a = 1 且 b = 1 以满足满足这两个方程。
3、
输入:["a==b", "b!=c", "c==a"] 输出:false
解题思路(并查集):
我们可以将每一个变量看作图中的一个节点,把相等的关系 == 看作是连接两个节点的边,那么由于表示相等关系的等式方程具有传递性,即如果 a==b 和 b==c 成立,则 a==c 也成立。也就是说,所有相等的变量属于同一个连通分量。因此,我们可以使用并查集来维护这种连通分量的关系。
首先遍历所有的等式,构造并查集。同一个等式中的两个变量属于同一个连通分量,因此将两个变量进行合并。
然后遍历所有的不等式。同一个不等式中的两个变量不能属于同一个连通分量,因此对两个变量分别查找其所在的连通分量,如果两个变量在同一个连通分量中,则产生矛盾,返回 false。
如果遍历完所有的不等式没有发现矛盾,则返回 true。
具体实现方面,使用一个数组 parent 存储每个变量的连通分量信息,其中的每个元素表示当前变量所在的连通分量的父节点信息,如果父节点是自身,说明该变量为所在的连通分量的根节点。一开始所有变量的父节点都是它们自身。对于合并操作,我们将第一个变量的根节点的父节点指向第二个变量的根节点;对于查找操作,我们沿着当前变量的父节点一路向上查找,直到找到根节点。
代码:
#include <iostream> #include <vector> #include <string> class Solution { public: // FIND int find(int index, std::vector<int> &parent) { if(parent[index] != index) parent[index] = find(parent[index], parent); return parent[index]; } // UNION void union_vertices(int index_1, int index_2, std::vector<int> &parent) { parent[find(index_1, parent)] = find(index_2, parent); } /** * 获取等值方程的可满足性 * equations - 等式方程集合 * return: true表示给定方程全部满足,false表示存在不满足条件的方程 */ bool equationsPossible(std::vector<std::string> &equations) { std::vector<int> parent(equations.size(), 0); for(const std::string &str : equations) { if(str[1] == '=') { int index1 = str[0] - 'a'; int index2 = str[3] - 'a'; union_vertices(index1, index2, parent); } } for(const std::string &str : equations) { if(str[1] == '!') { int index1 = str[0] - 'a'; int index2 = str[3] - 'a'; if(find(index1, parent) == find(index2, parent)) return false; } } return true; } }; int main() { std::vector<std::string> input = { "c==c", "b==d", "x!=z" }; Solution sol; bool result = sol.equationsPossible(input); std::cout << result << std::endl; return 0; }
3.3 Leetcode-面试题-17.07 婴儿名字
题目:
每年,政府都会公布一万个最常见的婴儿名字和它们出现的频率,也就是同名婴儿的数量。有些名字有多种拼法,例如,John 和 Jon 本质上是相同的名字,但被当成了两个名字公布出来。给定两个列表,一个是名字及对应的频率,另一个是本质相同的名字对。设计一个算法打印出每个真实名字的实际频率。注意,如果 John 和 Jon 是相同的,并且 Jon 和 Johnny 相同,则 John 与 Johnny 也相同,即它们有传递和对称性。
在结果列表中,选择 字典序最小 的名字作为真实名字。
示例:
输入:names = ["John(15)", "Jon(12)", "Chris(13)", "Kris(4)", "Christopher(19)"], synonyms = ["(Jon,John)", "(John,Johnny)", "(Chris,Kris)", "(Chris,Christopher)"]
输出:["John(27)", "Chris(36)"]
解题思路:
这是一道并查集的题,如果多个假名是同一个集合,则将他们对应出现的频率进行合并。否则,等价于原样输出。返回的array<string>不必根据输入顺序原样输出,只要保证集合结果相同即可。使用哈希表建立名字和索引,用map来替代模板算法中的parent集合,详情请看下面展示的代码。
#include <iostream> #include <map> #include <string> #include <vector> #include <unordered_map> #include <algorithm> class Solution { public: /** * 寻找指定字符串的根(FIND) * f - 等价并查集的parent,键原字符串,值表示父结点的字符串 * str - 指定将要查找根的结点字符串 * root - 用于存储返回值 * return: void */ void find_root( std::map<std::string, std::string> &f, std::string str, std::string &root) { if(!f.count(str)) // 如果str父结点为空,则根为其本身 { f[str] = str; root = str; return; } root = str; // root初始化为str while (root != f[root]) root = f[root]; while (f[str] != root) { std::string temp = f[str]; f[str] = root; str = temp; } } /** * 合并连通分量(UNION) * a - 连通分量1中的a字符串 * b - 连通分量2中的b字符串 * f - 等同并查集parent数组 * return: void */ void union_vertices( const std::string &a, const std::string &b, std::map<std::string, std::string> &f) { if(!f.count(a)) f[a] = a; if(!f.count(b)) f[b] = b; std::string fa, fb; find_root(f, a, fa); find_root(f, b, fb); if(fa != fb) { if(fa > fb) std::swap(fa, fb); f[fb] = fa; } } /** * 获取婴儿真实姓名 * names - 频率列表 * synonyms - 本质相同的名字对 * return: 一个存储婴儿真实姓名的vector */ std::vector<std::string> trulyMostPopular( std::vector<std::string> &names, std::vector<std::string> &synonyms) { std::vector<std::string> v; std::map<std::string, std::string> f; std::unordered_map<std::string, int> fre; for(auto &sy : synonyms) { int split = sy.find(','); std::string a = sy.substr(1, split - 1); std::string b = sy.substr(split + 1, sy.length() - 2 - split); union_vertices(a, b, f); } for(auto &str : names) { int split = str.find('('); std::string name = str.substr(0, split); std::string freq = str.substr(split + 1, str.length() - 2 - split); int times = 0; for(int i = 0; i < freq.length(); i++) times = times * 10 + freq[i] - '0'; std::string father; find_root(f, name, father); if(fre.count(father)) fre[father] += times; else fre[father] = times; } for(auto &i : fre) { std::string freq = ""; while (i.second > 0) { freq += i.second % 10 + '0'; i.second /= 10; } std::reverse(freq.begin(), freq.end()); // 字符串顺序反转 std::string ans = i.first + "(" + freq + ")"; v.push_back(ans); } return v; } }; int main() { std::vector<std::string> names = { "John(15)", "Jon(12)", "Chris(13)", "Kris(4)", "Christopher(19)" }; std::vector<std::string> synonyms = { "(Jon,John)", "(John,Johnny)", "(Chris,Kris)", "(Chris,Christopher)" }; Solution sol; std::vector<std::string> result = sol.trulyMostPopular(names, synonyms); for(auto str : result) std::cout << str << " "; std::cout << std::endl; return 0; }
3.4 Leetcode-684 冗余连接
题目:
在本问题中, 树指的是一个连通且无环的无向图。
输入一个图,该图由一个有着N个节点 (节点值不重复1, 2, ..., N) 的树及一条附加的边构成。附加的边的两个顶点包含在1到N中间,这条附加的边不属于树中已存在的边。
结果图是一个以边组成的二维数组。每一个边的元素是一对[u, v] ,满足 u < v,表示连接顶点u 和v的无向图的边。
返回一条可以删去的边,使得结果图是一个有着N个节点的树。如果有多个答案,则返回二维数组中最后出现的边。答案边 [u, v] 应满足相同的格式 u < v。
示例:
1、
输入: [[1, 2], [1, 3], [2, 3]]
输出: [2, 3]
解释: 给定的无向图为:
1 / \ 2 - 3
2、
输入: [[1, 2], [2, 3], [3, 4], [1, 4], [1, 5]]
输出: [1, 4]
解释: 给定的无向图为:
5 - 1 - 2 | | 4 - 3
解题思路:
在一棵树中,边的数量比节点的数量少 1。如果一棵树有 N 个节点,则这棵树有 N-1 条边。这道题中的图在树的基础上多了一条附加的边,因此边的数量也是 N。
树是一个连通且无环的无向图,在树中多了一条附加的边之后就会出现环,因此附加的边即为导致环出现的边。
可以通过并查集寻找附加的边。初始时,每个节点都属于不同的连通分量。遍历每一条边,判断这条边连接的两个顶点是否属于相同的连通分量。
- 如果两个顶点属于不同的连通分量,则说明在遍历到当前的边之前,这两个顶点之间不连通,因此当前的边不会导致环出现,合并这两个顶点的连通分量。
- 如果两个顶点属于相同的连通分量,则说明在遍历到当前的边之前,这两个顶点之间已经连通,因此当前的边导致环出现,为附加的边,将当前的边作为答案返回。
代码:
#include <iostream> #include <vector> class Solution { public: int find_root(std::vector<int> &parent, int index) { if(parent[index] != index) parent[index] = find_root(parent, parent[index]); return parent[index]; } void union_vertices(int index_1, int index_2, std::vector<int> &parent) { parent[find_root(parent, index_1)] = find_root(parent, index_2); } std::vector<int> findRedundantConnection(std::vector<std::vector<int>> &edges) { int edgeNums = edges.size(); std::vector<int> parent(edgeNums + 1); for(int i = 1; i <= edgeNums; i++) parent[i] = i; for(auto &edge : edges) { int node_1 = edge[0]; int node_2 = edge[1]; if(find_root(parent, node_1) != find_root(parent, node_2)) union_vertices(node_1, node_2, parent); else return edge; } return std::vector<int>{}; } }; int main() { std::vector<std::vector<int>> edges_1 = { {1, 2}, {1, 3}, {2, 3} }; std::vector<std::vector<int>> edges_2 = { {1, 2}, {2, 3}, {3, 4}, {1, 4}, {1, 5} }; Solution sl; std::vector<int> r1 = sl.findRedundantConnection(edges_1); std::vector<int> r2 = sl.findRedundantConnection(edges_2); for(auto i : r1) std::cout << i << " "; std::cout << std::endl; for(auto i : r2) std::cout << i << " "; std::cout << std::endl; return 0; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号