

红楼梦
import jieba
import re
from collections import Counter
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
设置中文字体(确保图表正确显示中文)
font = FontProperties(fname=r"C:\Windows\Fonts\simhei.ttf") # Windows系统黑体
Mac系统可用:font = FontProperties(fname="/System/Library/Fonts/PingFang.ttc")
《红楼梦》人物别称映射(将不同称呼合并为同一人物)
character_aliases = {
"贾宝玉": ["宝玉", "怡红公子", "宝二爷", "通灵宝玉"],
"林黛玉": ["黛玉", "林妹妹", "潇湘妃子", "颦儿"],
"薛宝钗": ["宝钗", "宝姐姐", "蘅芜君", "宝姑娘"],
"王熙凤": ["凤姐", "凤辣子", "熙凤", "琏二奶奶"],
"贾母": ["老太太", "史太君", "老祖宗", "贾母"],
"史湘云": ["湘云", "云妹妹", "枕霞旧友", "史大姑娘"],
"贾探春": ["探春", "三姑娘", "蕉下客", "探丫头"],
"贾元春": ["元春", "贵妃", "娘娘", "大小姐"],
"贾迎春": ["迎春", "二姑娘", "菱洲", "迎丫头"],
"贾惜春": ["惜春", "四姑娘", "藕榭", "惜丫头"],
"李纨": ["李纨", "宫裁", "稻香老农", "大奶奶"],
"妙玉": ["妙玉", "槛外人", "妙师父", "妙玉师父"],
"晴雯": ["晴雯", "晴姑娘", "晴丫头", "雯姐姐"],
"袭人": ["袭人", "花袭人", "珍珠", "袭姑娘"],
"贾政": ["贾政", "老爷", "政老爷", "二老爷"],
"贾赦": ["贾赦", "大老爷", "赦老爷", "贾大老爷"],
"贾琏": ["贾琏", "琏二爷", "琏爷", "琏二哥"],
"贾环": ["贾环", "环兄弟", "环儿", "环三爷"],
"贾兰": ["贾兰", "兰哥", "兰小子", "贾兰哥儿"],
"薛姨妈": ["薛姨妈", "姨妈", "薛氏", "薛姨妈太太"],
"王夫人": ["王夫人", "太太", "王夫人太太", "贾政夫人"],
"邢夫人": ["邢夫人", "大太太", "邢氏", "贾赦夫人"],
"刘姥姥": ["刘姥姥", "姥姥", "老亲家", "刘老老"]
}
反转映射表:别称 -> 标准名称
alias_to_standard = {}
for standard_name, aliases in character_aliases.items():
for alias in aliases:
alias_to_standard[alias] = standard_name
读取《红楼梦》文本
def read_novel(file_path):
try:
# 尝试UTF-8编码读取
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
return text
except UnicodeDecodeError:
# 尝试GBK编码读取(适用于旧版文本)
with open(file_path, 'r', encoding='gbk') as f:
text = f.read()
return text
except FileNotFoundError:
# 若文件不存在,使用示例文本(包含《红楼梦》经典段落)
print("未找到《红楼梦》文本,使用示例文本进行演示...")
sample_text = """
宝玉忙携手问:"妹妹几岁了?可也上过学?现吃什么药?在这里不要想家,想要什么吃的、什么玩的,只管告诉我;丫头老婆们不好了,也只管告诉我。"
一面又问婆子们:"林姑娘的行李东西可搬进来了?带了几个人来?你们赶早打扫两间下房,让他们去歇歇。"
黛玉道:"我自来是如此,从会吃饮食时便吃药,到今日未断,请了多少名医修方配药,皆不见效。那一年我才三岁时,听得说来了一个癞头和尚,说要化我去出家,我父母固是不从。
宝钗笑道:"宝兄弟,亏你每日家杂学旁收的,难道就不知道酒性最热,要热吃下去,发散的才快;若冷吃下去,便凝结在内,以五脏去暖他,岂不受害?从此还不快不要吃那冷的了。"
凤姐儿笑道:"亲戚们不大走动,都疏远了。知道的呢,说你们弃厌我们,不肯常来;不知道的那起小人,还只当我们眼里没人似的。"
"""
return sample_text
文本处理:分词并替换人物别称
def process_text(text):
# 去除标点符号和特殊字符(保留中文)
text = re.sub(r'[^\u4e00-\u9fa5]', ' ', text)
# 使用jieba分词
words = jieba.lcut(text)
processed_words = []
i = 0
while i < len(words):
word = words[i]
# 检查是否是人物别称(优先匹配2字以上的别称,避免短别称被提前匹配)
if len(word) >= 2 and word in alias_to_standard:
processed_words.append(alias_to_standard[word])
i += 1
else:
# 单字过滤 + 保留2字以上有意义词汇
if len(word) >= 2:
processed_words.append(word)
i += 1
return processed_words
统计词频并获取前20个高频词
def get_top_words(words, top_n=20):
# 定义停用词(无实际意义的高频词)
stop_words = {
"一个", "不是", "什么", "没有", "怎么", "知道", "起来", "这里", "那里",
"出来", "进去", "就是", "自己", "只见", "于是", "说道", "知道", "那里",
"这边", "那边", "时候", "回来", "姑娘", "奶奶", "太太", "老爷", "众人"
}
# 统计词频
word_count = Counter(words)
# 过滤停用词和单字
filtered_words = {word: count for word, count in word_count.items()
if word not in stop_words and len(word) >= 2}
return Counter(filtered_words).most_common(top_n)
可视化词频结果
def visualize_word_frequency(top_words):
words, counts = zip(*top_words)
plt.figure(figsize=(14, 8))
plt.barh(words, counts, color='skyblue')
plt.xlabel('出现次数', fontproperties=font, fontsize=12)
plt.ylabel('词语', fontproperties=font, fontsize=12)
plt.title('《红楼梦》中出现频率最高的20个词', fontproperties=font, fontsize=15)
plt.gca().invert_yaxis() # 使高频词显示在顶部
plt.tight_layout()
plt.show()
主函数
def main():
# 《红楼梦》文本路径(请替换为实际路径)
novel_path = "hongloumeng.txt"
# 读取文本
text = read_novel(novel_path)
# 处理文本
words = process_text(text)
# 获取高频词
top_words = get_top_words(words)
# 输出结果
print("《红楼梦》中出现频率最高的20个词:")
for i, (word, count) in enumerate(top_words, 1):
print(f"{i}. {word}: {count}次")
# 可视化结果
visualize_word_frequency(top_words)
if name == "main":
main()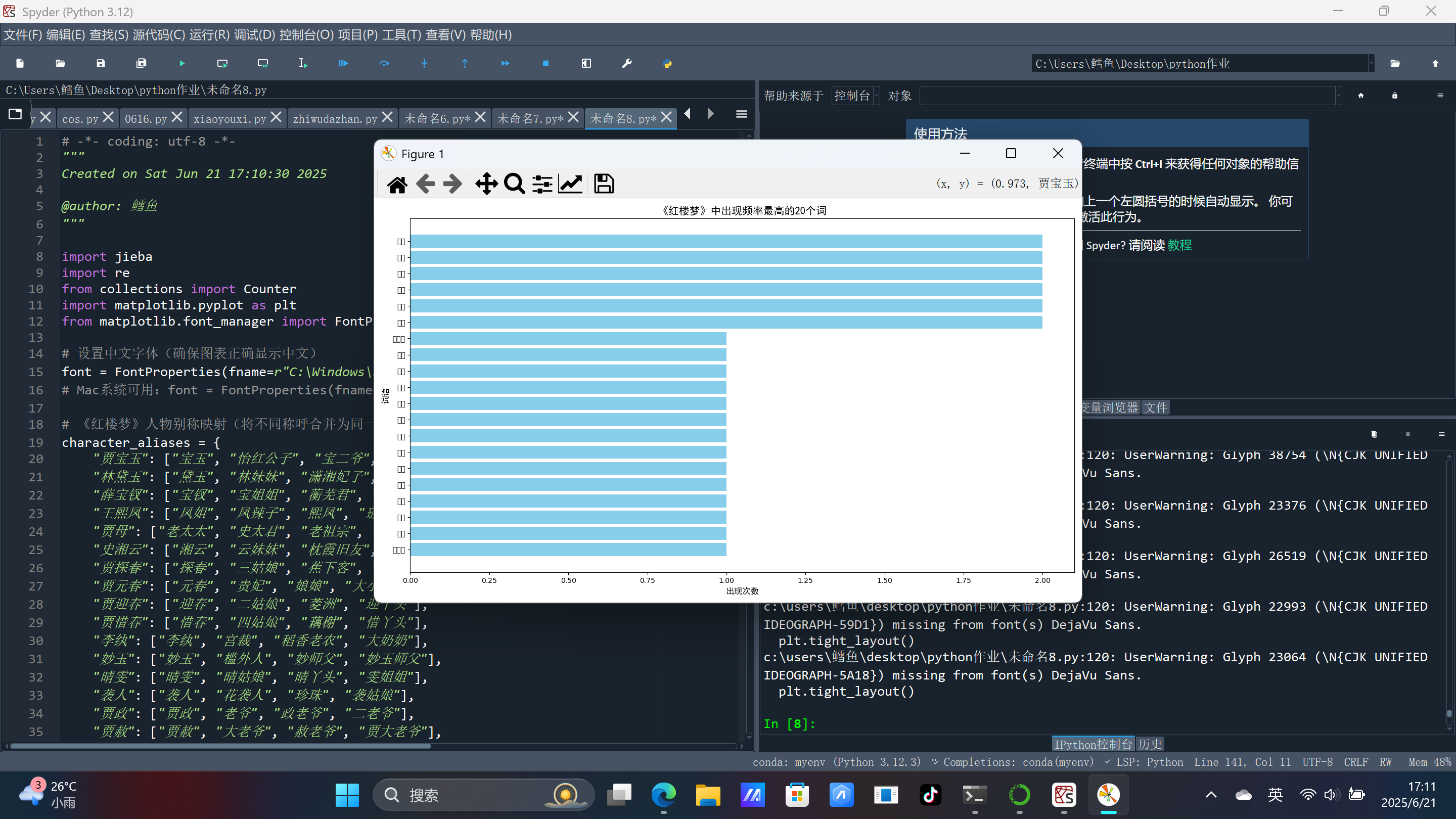

 浙公网安备 33010602011771号
浙公网安备 33010602011771号