Redis学习总结
Redis (Remote Dictionary Server ),即远程字典服务
Rredis是什么?
高性能的非关系型的键值对数据库,Redis支持五种键值对数据类型,键的类型只能是字符串类型,值有五种基本类型,分别是String、List、Hash、Set、Zset。它的数据存在内存中,所以读写速度非常快,因此,Redis已办用作缓存数据库方向。另外还支持数据的持久化、集群和事务等。

string——适合最简单的k-v存储,类似于memcached的存储结构,短信验证码,配置信息等,就用这种类型来存储。最大可存储512M数据。
hash——一般key为ID或者唯一标示,value对应的就是详情了。如商品详情,个人信息详情,新闻详情等。
list——因为list是有序的,比较适合存储一些有序且数据相对固定的数据。如省市区表、字典表等。因为list是有序的,适合根据写入的时间来排序。
set——可以简单的理解为ID-List的模式,如微博中一个人有哪些好友,set最牛的地方在于,可以对两个set提供交集、并集、差集操作。例如:查找两个人共同的好友等。
Zset-set的增强版本,增加了一个score参数,自动会根据score的值进行排序。比较适合类似于top 10等不根据插入的时间来排序的数据。
GeoSpatial-地理位置 经纬度 底层是zset
Bitmap 位图,统计打卡,带有状态位 1或0
hyperLoglog:统计每日访问量,活跃量,在线用户数
Redis的优缺点:
Redis的优点:读写快,且支持数据持久化。支持事务,redis的每一个操作都是原子性的。数据结构丰富String、List、Hash、Set、Zset。支持集群,保证数据可靠性。
缺点:因为数据是存在内存中,所以数据容量很容易受到限制,所以redis一般用在小数据量的高性能操作和运算,而且,redis很难实现线上扩容。Redis是基于内存的,一旦主机宕机,宕机前没有完成数据持久化和同步到从机,就会造成数据丢失。
为什么要用到缓存:
实现高性能:假如用户第一次访问数据库,这个时候会比较耗时,因为从磁盘读数据是比较慢的,引入了缓存后,把第一次读的数据存到缓存中,下一次访问这些数据的时候就可以直接去缓存中取数据,也就是直接读内存,这样速度相对更快,如果数据库中的数据发生改变,则相应的将缓存中的数据同步即可。
实现高并发:如果很多个请求直接请求数据库,数据库的压力会很大,导致访问速度慢,所以我们可以把部分不经常修改而经常查询的数据放到缓存中,这样就能实现多个请求访问缓存也不会造成速度下降。
Redis 6.0引入多线程
Redis6之前的版本是单线程的,是因为redis并不太会受到cpu的瓶颈,而是会收到内存本身性能和网络I/O的影响,采用多线程的话反而会导致一些数据操作会受到cpu上下文切换带来的性能影响。
Redis6,加入了多线程是为了优化网络I/O,核心的读写操作还是单线程的,redis会把网络I/O请求分发给多线程处理,处理完毕后在提交给主线程处理,这样就提升了网络I/O的速度,从而提高整体性能。
Redis的数据持久化
数据持久化就是将内存中的数据写到磁盘中去。避免由于宕机导致内存中的数据丢失。Redis提供了两种持久化机制,分别是RDB和AOF机制。配置文件默认是RDB。
RDB:Redis DataBase的缩写,说白了就是使用快照的方式保存数据。RDB是Redis的默认持久化方式,当Redis要做持久化时,会fork出一个子进程,子进程会将内存中的数据以快照的方式将内容写入到临时的RDB文件中,最后持久化保存到磁盘文件中,对应地产生dump.rdb文件,将原来rdb文件替换,然后子进程再退出,就完成了一次持久化。
AOF:Append Only File,要开启AOF方式要去配置文件修改配置。开启AOF后,Redis就开启了全程持久化,默认是每秒一次,可以通过配置文件设置。Redis会fork出子进程,子进程全程会将每一个收到的写请求(只记录写操作,不记录读操作)都通过write函数以追加的方式写到appendonly.aof文件末尾。这样最大程度的保证了数据的完整性。如果文件超过配置文件配置的最大文件大小(默认64MB),他又会fork出一个子进程开始写另一个aof文件。
RDB持久化触发机制
1.根据配置文件save的规则,自动触发rbd持久化
2.执行flushall会触发
3.退出redis,会生成rdb文件
如何恢复rdb文件数据:
只要将rdb文件放在redis的启动目录中,当redis启动时会自动检索dump.rdb文件,恢复里面的数据
AOF文件损坏如何恢复
当appendonly.aof文件里面的命令被损坏后,无法启动redis,
使用redis-check-aof 文件对appendonly.aof进行自动修复,删除文件里面错误的命令。
两种持久化机制对比:
RDB方式,它保存的是某一个时间点的数据,非常适合数据备份和大规模数据恢复,而且数据恢复的速度也比AOF速度快。但是由于它是按时间点来保存数据,如果在保存时间点之前宕机,容易造成数据丢失,而且fork子进程的时候会消耗一定的资源,这是他的缺点。
AOF方式,它是一直保存数据的操作指令,所以会消耗一定的资源,AOF的文件会比较大,数据恢复的速度也会比RDB更慢,这是他的缺点。他的优点在于实时保存数据操作指令,这样能够最大程度上维护数据的完整性。
Redis的事务:
事务就是一个单独个隔离操作,不会被程序的其他请求打断,事务中的所有指令都会序列化、按顺序执行,事务是一个原子操作,要么全做完,要么全不做。
Redis的事务是支持一致性和隔离性的,其他的特性是不支持的,当redis开启了AOF持久化机制时,redis事务也具有持久性。
Redis的事务不能保证原子性,虽然redis的命令是单条执行的,是原子操作,但事务不保证原子性,且没有数据回滚操作,事务中的某条命令执行失败,其他命令还是会继续执行。
Redis的集群:
主从模式:主从复制,读写分离,主机负责写,从机负责读(80%的业务是读),主机和从机的数据保证同步一致。最少一主二从。
作用:
1.数据冗余,实现数据热备份
2.故障恢复,当主节点出现故障时,从节点提供服务,实现快速的故障恢复
3.负载均衡,读写分离,从机负责大部分的写操作,减轻主机压力
4.实现高可用,避免一台服务器挂掉后,系统崩溃。
主从同步(主从复制):当主机有写入操作时,主机会触发增量复制,把所有收到的修改命令传给salve,完成同步。当启动一个从机加入到主机后,主机就会触发一次数据的全量复制,此时,主机会开启一个子线程在后台进行一次快照,生成一个RDB文件,然后在将RDB文件分发给从机,从机收到文件后,立即存储到磁盘中,然后再将RDB文件数据加载进内存。之后主机会发送写命令给从机,从机也会同步这些数据,保持数据的一致性。
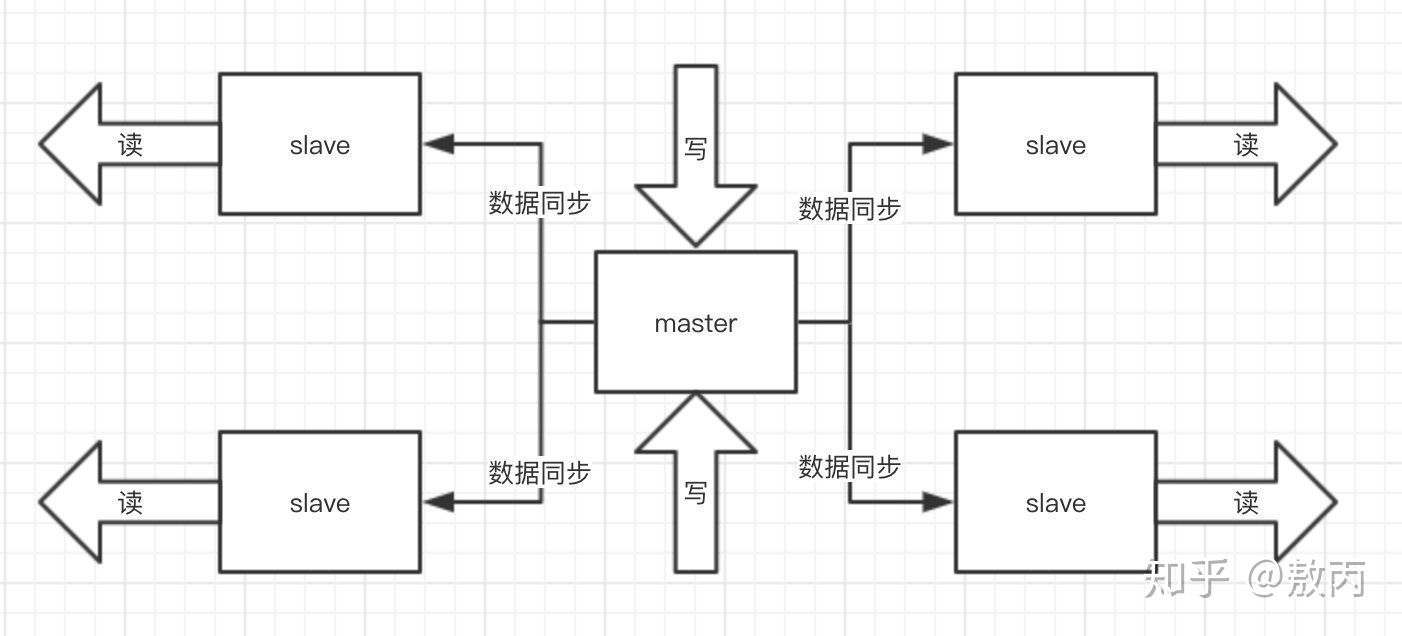
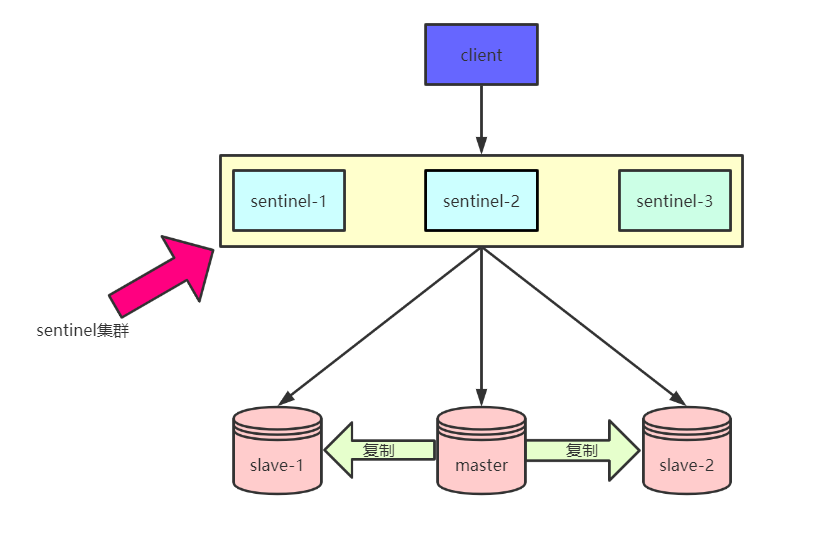
主从+哨兵模式:
哨兵至少需要3个以上的实例,才能保证自己的健壮性。
当主机挂了,哨兵会通过选举来确定下一个主机,如果从机挂了,还是能够保证高的用性。但并不能保证数据的完整性。
官方Redis Clister集群模式(服务器路由查询):
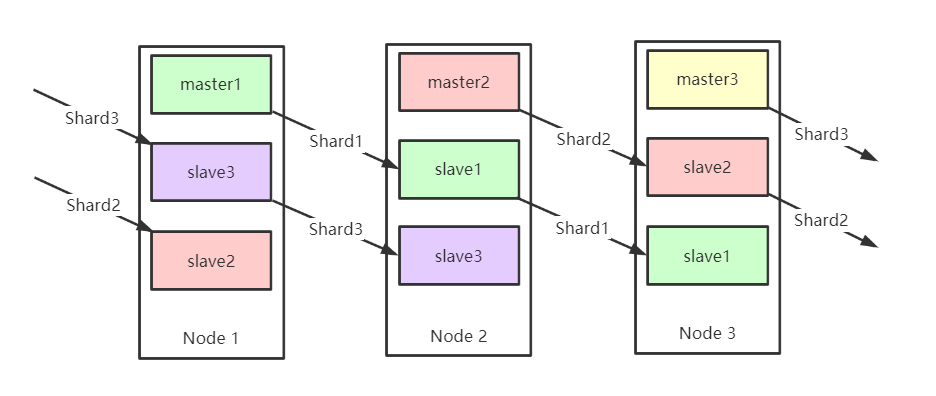
方案说明
通过哈希的方式,将数据分片,每个节点均分存储一定哈希槽(哈希值)区间的数据,默认分配了16384 个槽位
每份数据分片会存储在多个互为主从的多节点上
数据写入先写主节点,再同步到从节点(支持配置为阻塞同步)
同一分片多个节点间的数据不保持一致性
读取数据时,当客户端操作的key没有分配在该节点上时,redis会返回转向指令,指向正确的节点
扩容时时需要需要把旧节点的数据迁移一部分到新节点
优点
无中心架构,支持动态扩容,对业务透明
具备Sentinel的监控和自动Failover(故障转移)能力
客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
高性能,客户端直连redis服务,免去了proxy代理的损耗
缺点
运维也很复杂,数据迁移需要人工干预
只能使用0号数据库
不支持批量操作(pipeline管道操作)
分布式逻辑和存储模块耦合等
Redis LRU淘汰策略
常用 LRU:淘汰最近最久未使用的。
- noeviction: 不删除策略, 达到最大内存限制时, 如果需要更多内存, 直接返回错误信息。 大多数写命令都会导致占用更多的内存(有极少数会例外, 如 DEL )。
- allkeys-lru: 所有key通用; 优先删除最近最少使用(less recently used ,LRU) 的 key。
- volatile-lru: 只限于设置了 expire 的部分; 优先删除最近最少使用(less recently used ,LRU) 的 key。
- allkeys-random: 所有key通用; 随机删除一部分 key。
- volatile-random: 只限于设置了 expire 的部分; 随机删除一部分 key。
- volatile-ttl: 只限于设置了 expire 的部分; 优先删除剩余时间(time to live,TTL) 短的key。
java可以用hashMap和双链表来实现LRU算法,hashmap的key-value,通过key把value存储在LRU链表的槽中
-
save(key),首先通过 hash 算法,在key space 找到 key,并且尝试把数据存储到LRU空间,如果LRU空间足够,则不需要淘汰旧的内容;如果缓存空间不足,会淘汰掉 tail 指向的内容,并更新队头,存储后返回使用槽下标,更新key space 的value。
-
get(key),通过 hash 找到 key,然后通过 value 找到 LRU空间对应的槽,更新LRU指向关系。
Redis 的LRU实现
如果按照HashMap和双向链表实现,需要额外的存储存放 next 和 prev 指针,牺牲比较大的存储空间,显然是不划算的。所以Redis采用了一个近似的做法,就是随机取出若干个key,然后按照访问时间排序后,淘汰掉最不经常使用的。
SpringBoot集成redis:
SpringBoot底层集成redis使用的是SpringData redis,SpringData redis底层使用的是Lettuce,而不是Jedis
Lettuce和Jedis的区别:
Lettuce和Jedis都是redis的client,都可以用来连接Redis Server
Jedis在实现上是直接连接的Redis Server,如果在多线程环境下是非线程安全的。每个线程都去拿自己的Jedis实例,当连接数量增多时,资源消耗梯式增大,连接成本高。
Lettuce的连接是基于Netty的,Netty是一个多线程、时间驱动I/O的框架,连接实例可以在多个线程间共享,当多线程使用同一连接实例时,是线程安全的。所以一个多线程应用可以使用同一个连接实例,而不用担心并发线程的数量。如果一个连接实例不够,还可以按情况增加连接实例的数量。
通过异步的方式,可以让我们充分的利用系统资源,而不用浪费线程等待网络或者I/O。所以SpringData底层集成的是Lettuce。
Redis发布订阅
subscribe whq
publish whq "hahahaha"
订阅者:subcribe [channel]
发布者:publish [channel] [message]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号