JVM类加载机制、双亲委派模型
jvm类加载机制、双亲委派模型
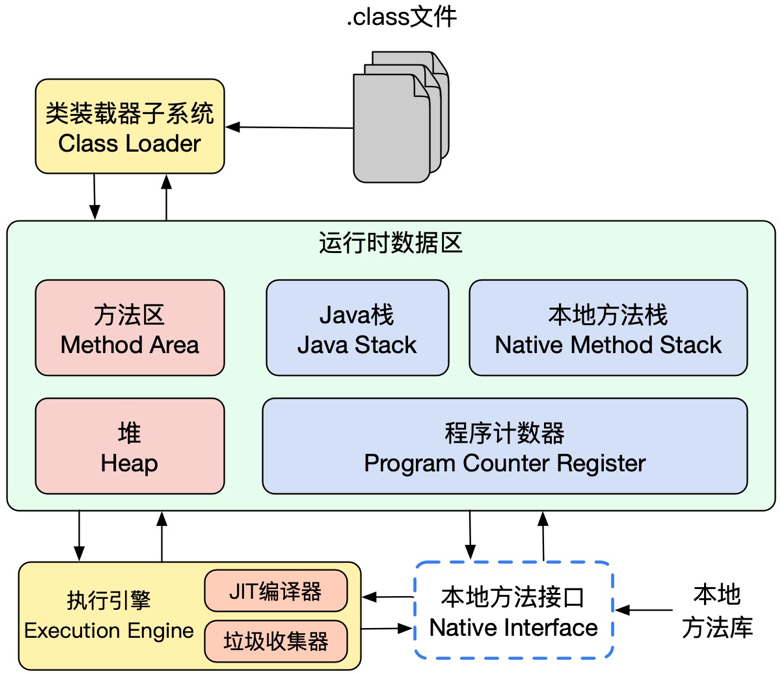
什么是类加载:
虚拟机把描述类的数据从.Class文件加载到内存中,并对数据进行校验、转换解析和初始化,最终形成可被虚拟机直接使用的java类型。
谁来加载:
加载描述类的Class文件的二进制流是由类加载器完成的,已有的三种类加载和自定义类加载器组成了类加载器的子系统。
怎么加载:
类的生命周期 :一共七个阶段
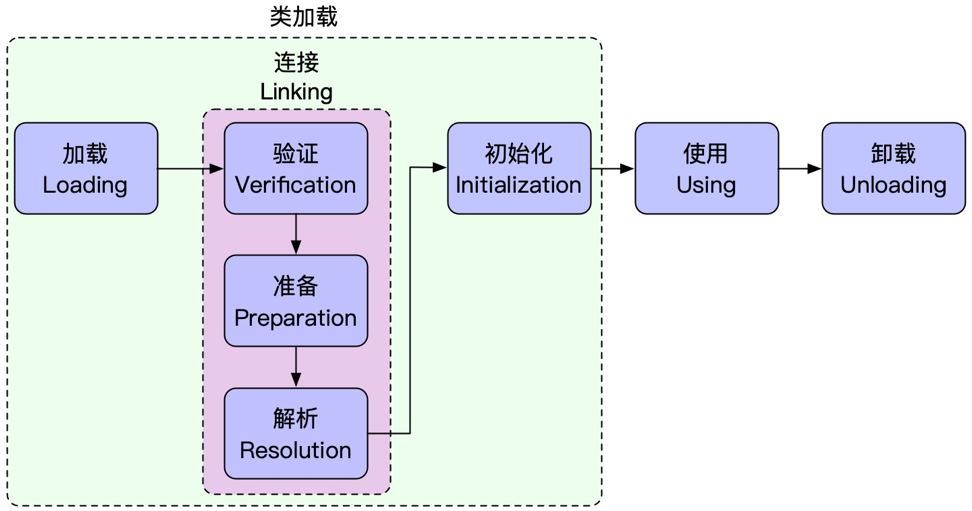
前五个阶段属于类加载流程的范围,其中验证、准备、解析又被成为连接,类加载的5个阶段并不是按照顺序依次完成的,除了解析可能会在初始化之后开始,其他的几个阶段的开始顺序是确定的,但结束的顺序不一定,可能会交叉进行,加载还没完成,连接可能已经开始。
类加载的流程
类加载分为5个过程,分别是加载、验证、准备、解析、初始化
一、加载
加载阶段主要干的3件事:
1.通过一个类的全限定名获取定义此类的二进制字节流。
2.将这个字节流解析所代表的静态存储结构转化为方法区的运行时数据结构
3.在内存中生成一个代表这个类的java.lang.Class实例,作为访问入口。
在这三件事中,开发人员只能干预的是第一件事,我们可以使用系统的三个类加载器去加载我们想要的类文件,也可以自定义类加载器去获取二进制流文件。
定义类的二进制字节流不一定是经过编译后存储在磁盘上的.class文件,也有可能是来自以下来源:
1.从ZIP包中读取,如:JAR、WAR、EAR
2.从网络中获取,如:Applet
3.运行时计算生成:动态代理技术
4.从其他文件生成,如JSP生成的.class文件
5.从数据库读取,中间件服务器,如:ASP Netweaver
Hotspot虚拟机中,Class实例不是在堆上分配空间,而是存在方法区中,这个实例在代码中可以轻松获取,并通过它可以获取代表某个类的各种数据结构。
二、验证:
验证是对输入的字节流进行检查的过程
加载的二进制字节流,来源广泛,不得不防止被小人利用,损害虚拟机的正常运行,导致崩溃,所以总共有四个验证过程
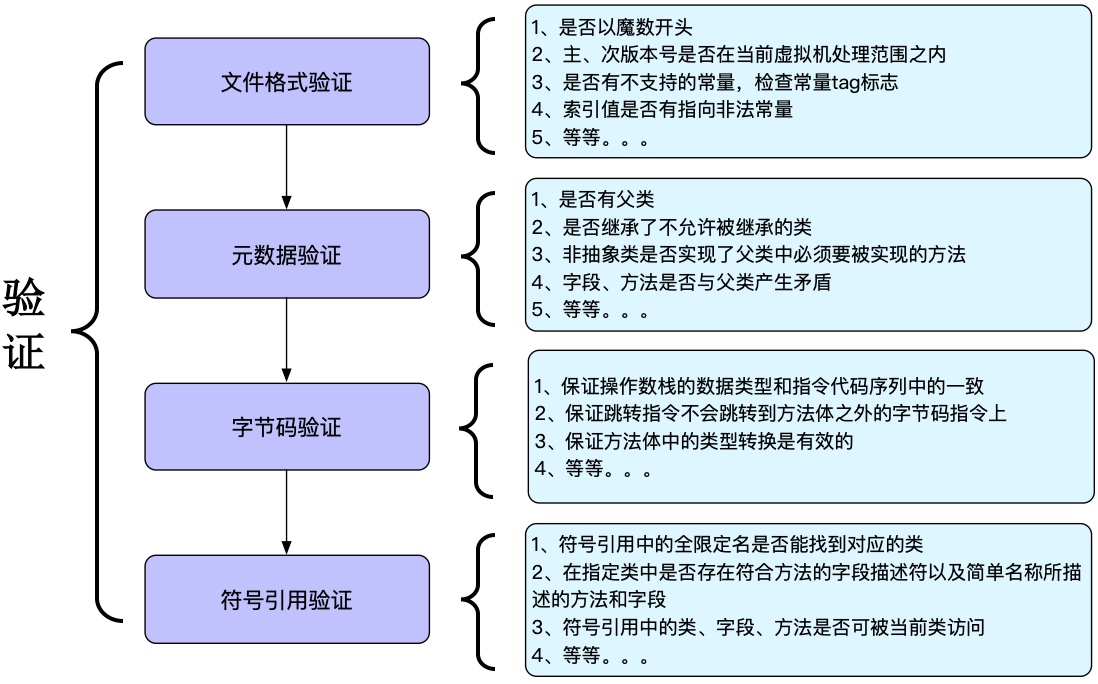
1.文件格式验证
这个阶段直接操作字节流,后面的三个阶段是基于方法区的存储结构,这个阶段主要是验证文件本身的字节码是不是符合规范,目的确保字节流可以被正确的存储在方法区上。
2.元数据验证
这个阶段主要是验证类的元数据信息是否符合Java语言规范,比如检查是否有父类,除了Object,其他类应该要有父类,否者就不符合规范了;被final修饰的不允许被继承
3.字节码验证
这个阶段主要是对类的方法体验证,保证类的方法运行时不会对虚拟机造成危害。这是4个验证里面最复杂的一个,因为要通过数据流和控制流分析,确定程序的语义是合法的、符合逻辑的。
4.符号引用验证
上面的三个阶段是对类本身进行验证,而符号引用验证主要是对类以外的信息进行验证,保证符号引用是正确的,因为解析是将符号引用替换成直接引用,确保后面的解析过程顺利进行。
三、准备
准备阶段是为类变量分配内存并设置类变量初始值的阶段。
注意这里是为类变量分配内存,而且是分配在方法区中,实例变量是随后面的实例一起分配在堆上的。
设置初始值也不是代码里赋的值,而是各个数据类型规定的,比如基础类型是相应类型不同字节长度的0,引用类型是null。
不是每个类变量都是设置为0值,被final修饰的常量,因为在编译期带有一个ConstantValue,属性值则是该常量代码里赋的值,这个值在准备阶段前就已经确定了,所以再准备阶段赋值的时候,直接取的ConstantValue给常量。
public class Test {
public static int a;
public static int b = 1;
public static final int c = 2;
public void say(){
System.out.println("Hello");
}
}
答案揭晓:0, 0, 2 原因上文里写的很明白
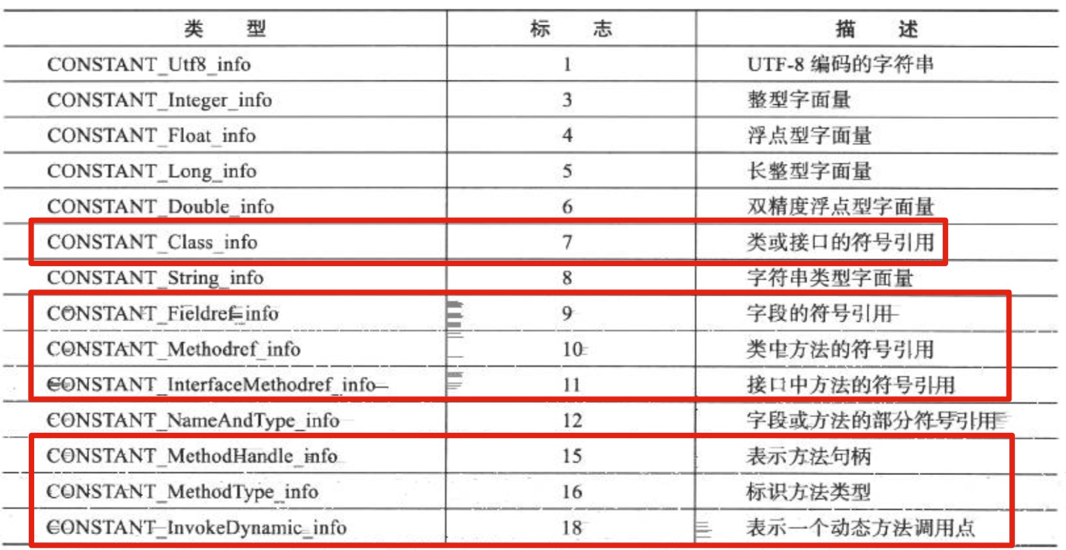
四、解析
解析是将常量池内的符号引用替换成直接引用的过程
那什么是符号引用和常量引用呢?
符号引用:以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时无歧义的定位到目标即可
直接引用:直接引用可以是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的域
符号引用与虚拟机实现的内存布局无关,引用的目标并不一定已经加载到内存中,各种虚拟机实现的内存布局可以各不相同,但是他们能接受的符号引用必须是一致的,因为符号引用的字面量形式明确定义在Java虚拟机规范的Class文件格式中。
直接引用是和虚拟机实现内存布局相关的,同一个符号引用在不同的虚拟机实例上翻译出来的结果一般不会相同,如果有了直接引用,那引用的目标必定已存在内存中。
解析的时机根据虚拟机实现不同而不同,可以是类加载器加载时解析,也可以是符号引用使用前解析
解析主要是对7类符号引用进行:类或接口、字段、类方法、接口方法、方法句柄、调用点限定符
五、初始化
初始化是执行类构造器clinit()方法的过程
类初始化阶段是类加载流程的最后一个阶段,是执行clinit()方法的阶段,这个阶段才真正开始执行开发人员的代码。
clinit()方法是编译器按照源文件中定义的顺序收集类变量和静态语句块形成的方法。它的一些特点和细节如下:
1.编译器自动收集静态变量和静态代码块合并产生的
2.不需要显式的调用父类的clinit()方法,虚拟机保证父类先执行
3.父类定义的静态语句块优先于子类的变量赋值操作
4.没有静态变量和静态语句块,可以不生成clinit()方法
5.接口也会有这个方法,但是不需要先执父类的clinit()方法
6.虚拟机保证该方法在多线程环境下被正确的加锁和同步
什么时候发生初始化
对一个类进行主动引用的时候必须初始化,主动引用的场景如下:
1.遇到 new、getstatic、putstatic、invokestatic这四条指令时
2.使用java.lang.reflect反射包的方法对类进行反射调用时
3.初始化一个其父类还没被初始化的类时
4.虚拟机启动时,包含main()方法的主类还没被初始化时
5.当使用动态语言支持时,如果一个java.lang.invoke.MethodHandle实例最后解析结果REF_getStatic、REF_putStatic、REF_invokeStatic的方法句柄,并且这个方法对应的类没进行初始化时
什么时候不发生初始化?
对一个类进行被动引用的时候不初始化,被动引用的场景有下面一些:
1.通过子类引用父类的静态字段,不会导致子类初始化
2.通过数组定义来引用类,不会触发此类的初始化
3.引用类的常量时,不会触发此类的初始化
类加载器
什么是类加载器
实现“通过一个类的全限定名来获取此类的二进制字节流”这个动作的代码块就叫做类加载器
类加载器不仅仅是加载二进制流字节码的作用,还起着独立类名称空间的作用,确定一个类的唯一性由三个因素决定:
1.同一java虚拟机
2.同一个类加载器
3.同一个全限定类名
双亲委派模型
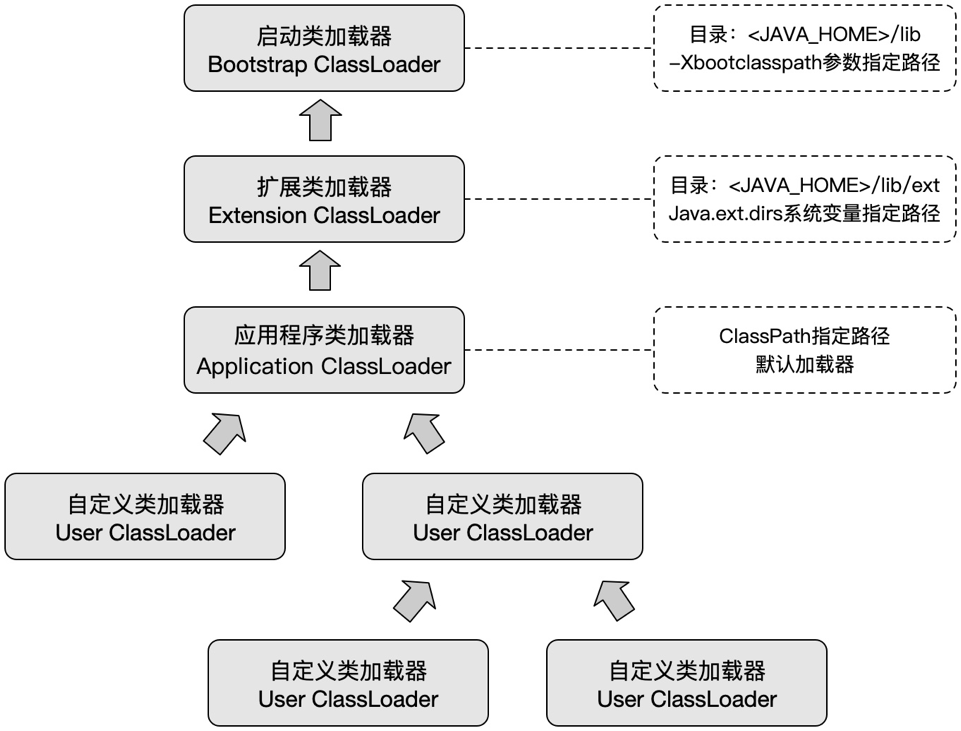
图中可以看到,系统提供了三个类加载器:启动类加载器、扩展类加载器和应用程序类加载器,java程序启动的时候,三个类加载器分别从各自指定的路径中加载所需的类。最下面的是开发人员自定义的类加载器,继承自ClassLoader,重写了findClass()方法。
一般我们自己写的类是默认由应用程序加载器加载的,自定义的类加载器的父类加载器默认是应用程序加载器,应用程序加载器的父类是扩展类加载器,扩展类加载器的父类是启动类加载器,这种父子关系不是一般的继承或者实现关系,而是子加载器持有父加载器的引用,是一种组合关系。自定义类加载器时,可在构造函数中传入指定的父类加载器。
双亲委派模型的主要代码:
//ClassLoader.java
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
//加锁,整个类加载期间都持有锁
synchronized (getClassLoadingLock(name)) {
// 首先,检查此类是否已被加载过,是的话直接返回
Class<?> c = findLoadedClass(name);
if (c == null) { //如果没有加载过,则继续
long t0 = System.nanoTime();
try {
if (parent != null) { //有父类加载器,则交给父类加载器加载,递归执行loadClass方法
c = parent.loadClass(name, false);
} else { //没有父类加载器,交给启动类加载器加载,执行一个本地方法
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// 除了启动类加载器之外的类加载器加载类失败抛异常,此处不进行任何处理
}
if (c == null) {
// 父类加载器未成功加载到类,则调用本加载器的findClass方法
long t1 = System.nanoTime();
c = findClass(name);
// 记录一些状态
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
//验证解析
if (resolve) {
resolveClass(c);
}
return c;
}
}
双亲委派模型流程图:
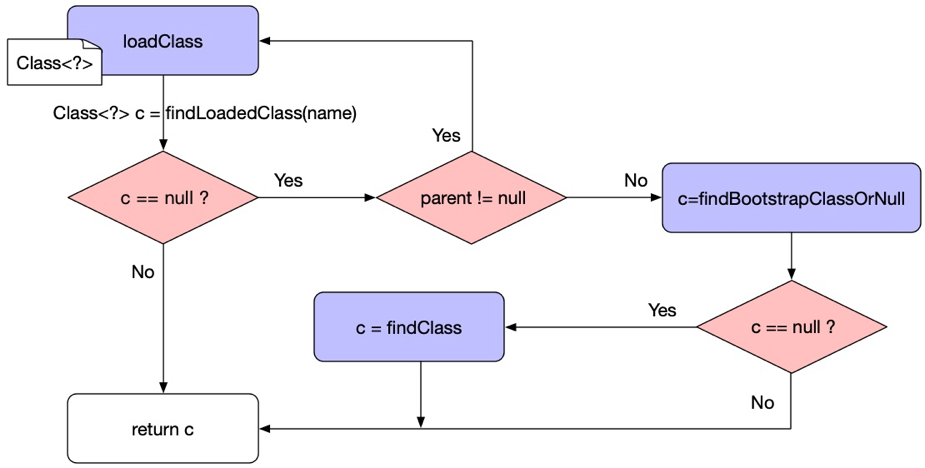
假设自定义的类加载器调用了loadClass()方法,触发了类的加载过程,按照双亲委派模型分析,依次会执行:
1.自定义的类加载器首先会调用findLoadedClass(name)方法查看有没有被加载这个类,如果有直接返回,否者执行以下步骤
2.检查是否存在父类,如果有则递归调用父类的loadClass()方法,否则说明父类加载器是启动类加载器,本类加载器是扩展类加载器,调用findBootstrapClassOrNull(name)使用启动类加载器加载。
3.启动类加载器加载成功则返回,失败则调用扩展类的findClass(name)方法来加载,成功则返回,失败则继续调用应用程序类加载器的findClass(name)方法,同样成功返回,失败则调用自定义类加载器的findClass(name) 方法
4.我们定义的类加载器一般会重写findClass()方法,在此方法中,使用自定义的类加载器加载一个父类加载器加载不了的时候,就会执行自定义的findClass()方法,在此方法中,会指定二进制字节码文件的路径读入字节数组中,最后调用defineClass返回加载成功的类
总而言之:双亲委派模型就是当一个类收到了加载请求时,不会先自己去加载这个类,而是一直将其委派给父类,让父类来加载,如果此时父类加载器不能加载,反馈给子类,由子类去完成加载。若最后子类也无法加载,则抛出ClassNotFoundException
自定义类加载器示例代码:
public class MyClassLoader extends ClassLoader{
private String classpath;
//指定父类加载器的构造函数
public MyClassLoader(String classpath,ClassLoader classLoader) {
super(classLoader);
this.classpath = classpath;
}
//默认父类加载器为应用程序加载器的构造函数
public MyClassLoader(String classpath) {
this.classpath = classpath;
}
//重写findClass,加载类文件,返回类
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
String classFilePath = null;
String finalName = name.replace(".", "/");
classFilePath = classpath + "/" + finalName + ".class";
Path path = Paths.get(classFilePath);
if (!Files.exists(path)) {
return null;
}
try {
byte[] classData = Files.readAllBytes(path);
return defineClass(name, classData, 0, classData.length);
} catch (IOException e) {
throw new RuntimeException("Can not read class file into byte array");
}
}
}
为什么要用双亲委派模型?用这个模型的好处
采用双亲委派模型的好处之一就是类和它对应的类加载器一起具备了一种带有优先级的层次关系通过这种层次关系可以避免类重复加载,当父类加载器已经加载了该类时,子类加载器就没必要再加载一次。
其次是考虑安全因素,保证java核心API中心定义的类型不会被随意替换,假设通过网络传递一个名为java.lang.Integer类,通过双亲委派模型传递到启动类加载器,而启动类加载器在和兴Java API发现这个名字的类,发现该类已被加载,并不会重新加载网络传递过来的java.lang.Integer,而直接返回已加载的Integer.class,这样便可以放在核心的API库被随意篡改。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号