
随机森林不需要交叉验证!
随机森林属于bagging集成算法,采用Bootstrap,理论和实践可以发现Bootstrap每次约有1/3的样本不会出现在Bootstrap所采集的样本集合中。故没有参加决策树的建立,这些数据称为袋外数据oob,歪点子来了,这些袋外数据可以用于取代测试集误差估计方法,可用于模型的验证。
袋外数据(oob)误差的计算方法如下:
- 对于已经生成的随机森林,用袋外数据测试其性能,假设袋外数据总数为O,用这O个袋外数据作为输入,带进之前已经生成的随机森林分类器,分类器会给出O个数据相应的分类
- 因为这O条数据的类型是已知的,则用正确的分类与随机森林分类器的结果进行比较,统计随机森林分类器分类错误的数目,设为X,则袋外数据误差大小=X/O
随机森林树模型的特征重要性排序常见有两种方法
1、基于OOB的评估指标
先用训练好的模型对OOB数据进行打分,计算出AUC或其他业务定义的评估指标;接着对OOB数据中的每个特征:(1) 随机shuffle当前特征的取值(即依次对每个特征赋予一个随机数,观察算法性能的变化);(2) 重新对当前数据进行打分,计算评估指标;(3)计算指标变化率。按照上面方式,对每个特征都会得到一个变化率,最后按照变化率排序来量化特征重要性。
2、基于gini指数
就是看看每个特征在随机森林中的每颗树上做了多大的贡献,然后取个平均值,最后比一比特征之间的贡献大小。对于生成的每棵树,计算每个分裂节点的Gini指数,计算公式如下:

其中,K表示K个类别, 表示第
个分裂点中k类别所占的比例。特征
在节点m的重要性可以通过分裂前后的特征
的差值来表示,可以表示为
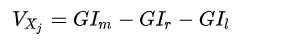
最后,把所有求得的重要性评分做一个归一化处理即可
具体计算例子可以参考【3】
Reference:
【1】https://zhuanlan.zhihu.com/p/77473961
【2】https://zhuanlan.zhihu.com/p/77480254
【3】https://www.jianshu.com/p/cfd7e2d385da
