
声明:本文为原创文章,转载请注明出处。
经常处理文本文件的小伙伴,有个很头疼的事情,就是如何准确识别一个文本文件到底是什么编码方式,ANSI(也就是GBK)还是UTF8。
文本文件,是指以特定的文本编码将每个字符逐个字节存储的一种文件格式,文本文件的常见的扩展名是.txt ,但又不一定是.txt,例如常见的CSV文件,其实就是文本文件。
既然是文本文件,在使用特定的程序去读取时,就需要知道文本文件的编码,解码和编码只有一致,才能完整还原文件中存储的文字信息。
那么GBK、GB2312、GB18030、Unicode、UTF8、UTF16、UTF32都是些什么意思呢?相信小伙伴们已经提前对这些有所了解!
长话短说,GBK、GB2312、GB18030、Unicode 这个四个是字符的编码集,其中,GB18030兼容GBK、GB2312,GBK兼容GB2323。
而Unicode 和GBK、GB2312、GB18030 互不兼容。
而UTF8、UTF16、UTF32并不是字符集,而是三种存储Unicode字符的存储方式。
以下问题是一些常见问题
1、GB18030、GBK、GB2312三者什么关系
比如汉字“𬌗” 这个字,只属于GB18030,而不属于GBK,自然更不属于GB2312
比如汉字“〇” 这个字,属于GBK,自然也就属于GB18030,但是其不属于GB2312
比如汉字“啊” 这个字,属于GBK2312,自然也就属于GB18030,并且其还属于GB2312,并且三个字符集编码是相同的,是一个2字节的16进制数
如果一个汉字,在GB18030、GBK、GB2312 三个字符集中都有,那么该汉字在这三个字符集中的编码都是一致的。
2、为什么弄这么多字符集,既然Unicode已经包含了GB18030的所有字符了,那么还弄GB18030有什么用?
这是因为在unicode字符集中,用4个字节表示一个字符,而GB18030用2个字节表示一个字符,在只存储汉字,不存储俄文、西班牙文等外文的情况下,使用GB18030可以节省一半存储空间。
虽然随着存储器价格降低,占用空间不需要考虑太多,但是国内的GB18030、GBK依然还是有用武之地的,但会越来越少。
3、既然GB18030兼容GBK、GB2312,只用GB18030行不行?
答:绝大多数情况下,是没问题的,但是当对方程序没有GB18030字库时,属于GB18030但不属于GBK、GB2312字符集的特殊字符,就会变成乱码,
非特殊字符的情况下,GB18030和GBK的编码是一样的,可以理解为GB18030就是GBK的演进升级版,并且向下兼容
4、什么是字符的存储方式
所谓字符的存储方式,就是怎么把按照某种编码集(GBK\GB18030\UNICODE)编码后的字符,以文件形式存储在电脑上。
5、直接将编码后的字符按顺序存储在文件上不行吗,为什么还要再弄出个存储方式,是不是多此一举
还真不是,如果某段汉字字符使用GBK编码的,然后以ANSI方式保存为文本文件,那么其内部确实存储的就是GBK编码,每个字符2个字节,8个字符16个字节。
但是如果汉字和英文混排的一段,就不然,英文GBK编码中,刻意兼容了ASICII编码集, 比如英文字符“Z”,其ASICII的16进制编码是5A,二进制是1011010 ,而GBK的编码的是00000000 01011010,
如果直接以00000000 1011010存在一个字符Z,那就太浪费空间了,所以在GBK编码的文本文件中,英文和数字等ASICII表中的字符,只占用1个字节存储,而汉字用2个字节存储。
在Unicode编码中,字幕Z的编码是00000000 00000000 00000000 01011010,如果将这一串存在电脑上,是不是很浪费?
于是为了存储Unicode字符,衍生出了UTF8、UTF16LE、UTF16BE、UTE32 这四种不同的存储编码。其中UTF8是存储unicode编码效率最高,最节省存储空间的方式,而UTF32是最占用存储空间的的方式,几乎没有什么地方使用。
UTF8实际是一种可变长度的字符存储方法,当存储一个属于ASICII表的字符时,直接存储该字符的ASICII编码,当存储一个汉字时,大多数情况以3个字节存储,只有极个别生僻字会以四个字节来存储。
6、什么是BOM
BOM是英文ByteOrderMark的缩写,翻译成中文,就是字节顺序标记,这个东西的作用就是在一个文本文件头2-4个字节,存储一些特殊字符,这些字符在任何的字符集中都没有使用,
通过这些特殊字节,可以很容易的确定文本文件的编码方式,而不是靠猜的方式确定。具体不同的存储编码方式用什么样的BOM头,小伙伴们可以自行搜索,网上解释的很详细。
现在引出本文主要内容:
当一个文本文件没有BOM头的时候,能不能准确的识别出,存储方式到底是GBK还是什么其他字符集还是UTF8?
也许小伙伴们已经从网上找了不少代码片段,实现了在五BOM头的情况下自动识别,但我今天想说,这些方法都是有瑕疵的,不可能百分百识别正确。
没错,就算是微软这种顶级软件公司,也不可能开发出一个程序,在无BMOM的情况下,准确识别文本文件是GBK还是UTF8。
一、GBK存储编码特点
当文本文件存储为GBK方式,当存储一个汉字时,直接存储两个字节的汉字GBK编码,而GBK编码的特点,两个字节都是1XXXXXXX类似的二进制存储,最高两个字节的最高位均为1,在存储ASCII码表中的字符时,例如子母Z的GBK的编码的是00000000 01011010,两个字节,但是只存储01011010一个字节。
二、UTF8的存储编码特点
UTF编码的文件中,可以每个字符可能有1-4个字节,特点如下
单字节字符:0XXXXXXX
双字节字符:110XXXXX 10XXXXXX
三字节字符:1110XXXX 10XXXXXX 10XXXXXX
四字节字符:11110XXX 10XXXXXX 10XXXXXX10XXXXXX
三、如果我能找出一种情况,同时满足GBK编码和UTF8编码,那么岂不是那些能自动识别编码方式的软件就识别不对了呗?
还真让我找着了。
请打开记事本,只粘贴这三个汉字“浒颁耽”,然后保存为ANSI,WIN11可能在保存时有提示,确定就行。
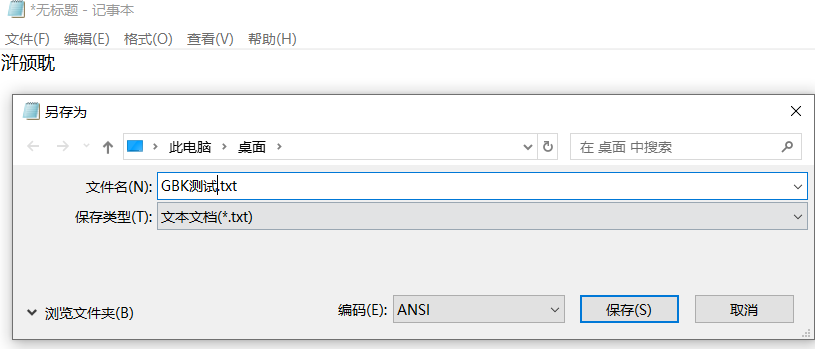
当保存完成后,双击打开该文件,你会惊奇的发现,字符变成了“䰰䵢”,而右下角显示的编码方式为UTF8
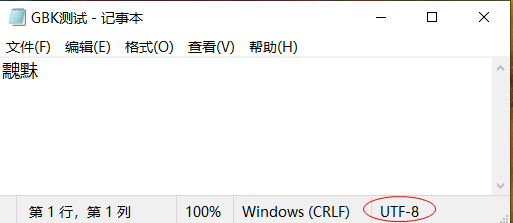
使用NotePad++打开该文件,依然显示的是䰰䵢,而不是你之前粘贴的“浒颁耽”。
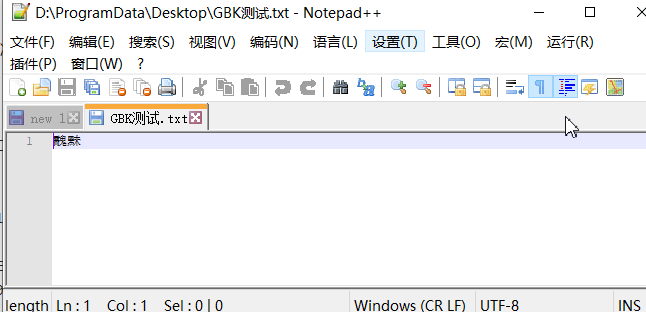
但是NotePad++可以手工选择编码方式,在菜单选择 编码-使用ANSI编码后,你会惊喜的发现,显示的字符变成了“浒颁耽”。
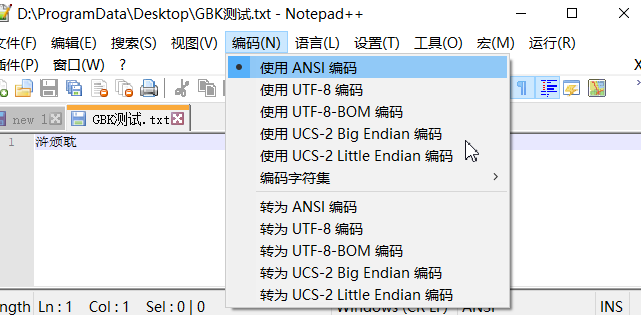
为什么呢?这是因为二者的以UTF8无BOM方式存储的“䰰䵢”和使用GBK(或者GB18030、GB2312,编码是相同的)存储的“浒颁耽”文本文件,总共6个字节,二进制数完全相同。
除了文件保存者,否则谁都不能知道他当初到底是存了个啥,因为两个文件中存储的二进制数是完全相同的。
为什么会出现这种情况呢?
首先来看
当使用GBK编码存储“浒颁耽”时,存储的编码是11100100 10110000 10110000 11100100 10110101 10100010 ,换算成16进制就是E4B0B0E4B5A2
如下16进制方式查看该文件
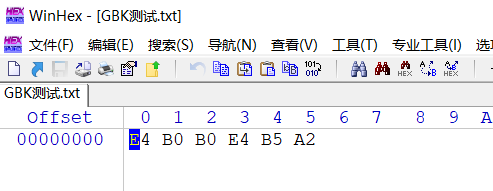
问题来了,按照GBK的解码方式,每2个二进制数,也就是2个字节,存储为1个汉字,E4B0 代表 浒 ,B0E4 代表 颁 ,B5A2代表耽。
但是按照UTF8的编码方式,前三个字节E4B0B0 也就是11100100 10110000 10110000 恰好满足3字节字符存储的标准1110XXXX 10XXXXXX 10XXXXXX,并且11100100 10110000 10110000这个编码是有效的,是个“䰰”字
后三个字节E4B5A2,也就是11100100 10110101 10100010,也恰好满足3字节字符存储的标准1110XXXX 10XXXXXX 10XXXXXX,并且11100100 10110101 10100010这个编码有效的,是个“䵢”字
于是存储了6个字节E4B0B0E4B5A2 的文本文件,就根本不可能识别出作者最初到底是存储了什么。
这也是为什么,我明明保存成ANSI编码,但是打开文件后变成了UTF8,并且字变成了“䰰䵢”。

而上述,是可以按照编码规则找的几个汉字,这样的组合还大量存在,自然而然,在没有BOM头的情况下,没有程序能准确识别GBK和ANSI编码的文本文件,因为这是不可能的,
即使是微软的记事本,也是无法准确识别刚才文本文件的编码,那么,谁能准确识别,我的答案是谁都不能准确识别当初存的到底是“䰰䵢”还是“浒颁耽”,换成钢铁侠马斯克也是不行的。
所以,如果小伙伴们在用一些网上的自动识别字符编码的代码段,或者想自己写一些自动识别字符编码的方法时,没必要过于执拗,绝大多数情况下,能识别就可以,不能自动识别的,那就手工指定编码。
在某些特殊情况下,程序确实是无法区分存储的这个文本文件到底当时什么编码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号