hadoop2-MapReduce详解
本文是对Hadoop2.2.0版本的MapReduce进行详细讲解。请大家要注意版本,因为Hadoop的不同版本,源码可能是不同的。
以下是本文的大纲:
1.获取源码
2.WordCount案例分析
3.客户端源码分析
4.小结
5.Mapper详解
5.1.map输入
5.2.map输出
5.3.map小结
6.Reduce详解
7.总结
若有不正之处,还请多多谅解,并希望批评指正。
请尊重作者劳动成果,转发请标明blog地址
https://www.cnblogs.com/hongten/p/hongten_hadoop_mapreduce.html
1.获取源码
大家可以下载Hbase
Hbase: hbase-0.98.9-hadoop2-bin.tar.gz
在里面就包含了Hadoop2.2.0版本的jar文件和源码。
2.WordCount案例分析
在做详解之前,我们先来看一个例子,就是在一个文件中有一下的内容
hello hongten 1 hello hongten 2 hello hongten 3 hello hongten 4 hello hongten 5 ...... ......
文件中每一行包含一个hello,一个hongten,然后在每一行最后有一个数字,这个数字是递增的。
我们要统计这个文件里面的单词出现的次数(这个可以在网上找到很多相同的例子)
首先,我们要产生这个文件,大家可以使用以下的java代码生成这个文件
1 import java.io.BufferedWriter; 2 import java.io.File; 3 import java.io.FileWriter; 4 5 /** 6 * @author Hongten 7 * @created 11 Nov 2018 8 */ 9 public class GenerateWord { 10 11 public static void main(String[] args) throws Exception { 12 13 double num = 12000000; 14 15 StringBuilder sb = new StringBuilder(); 16 for(int i=1;i<num;i++){ 17 sb.append("hello").append(" ").append("hongten").append(" ").append(i).append("\n"); 18 } 19 20 File writename = new File("/root/word.txt"); 21 writename.createNewFile(); 22 BufferedWriter out = new BufferedWriter(new FileWriter(writename)); 23 out.write(sb.toString()); 24 out.flush(); 25 out.close(); 26 System.out.println("done."); 27 } 28 }
进入Linux系统,编译GenerateWord.java文件
javac GenerateWord.java
编译好了以后,会生成GenerateWord.class文件,然后执行
java GenerateWord
等待一段时间....就会生成这个文件了(大概252MB左右)。
接下来,我们来写统计单词的map,reduce,以及客户端的实现。
项目结构

这里总共有三个java文件
客户端
首先,我们需要定义Configuration和job,然后就是job的set操作,最后到job.waitForCompletion()方法,才触发了动作的提交。
这里可以理解为在客户端,包含了一个配置分布式运行的相关配置信息,最后提交动作。
1 package com.b510.hongten.hadoop; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.Path; 5 import org.apache.hadoop.io.IntWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Job; 8 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 9 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 10 11 /** 12 * @author Hongten 13 * @created 11 Nov 2018 14 */ 15 public class WordCount { 16 17 public static void main(String[] args) throws Exception { 18 //读取配置文件 19 Configuration conf = new Configuration(); 20 //创建job 21 Job job = Job.getInstance(conf); 22 23 // Create a new Job 24 job.setJarByClass(WordCount.class); 25 26 // Specify various job-specific parameters 27 job.setJobName("wordcount"); 28 29 job.setMapperClass(MyMapper.class); 30 job.setMapOutputKeyClass(Text.class); 31 job.setMapOutputValueClass(IntWritable.class); 32 33 job.setReducerClass(MyReducer.class); 34 job.setOutputKeyClass(Text.class); 35 job.setOutputValueClass(IntWritable.class); 36 37 // job.setInputPath(new Path("/usr/input/wordcount")); 38 // job.setOutputPath(new Path("/usr/output/wordcount")); 39 40 FileInputFormat.addInputPath(job, new Path("/usr/input/wordcount1")); 41 42 Path output = new Path("/usr/output/wordcount"); 43 if (output.getFileSystem(conf).exists(output)) { 44 output.getFileSystem(conf).delete(output, true); 45 } 46 47 FileOutputFormat.setOutputPath(job, output); 48 49 // Submit the job, then poll for progress until the job is complete 50 job.waitForCompletion(true); 51 52 } 53 }
自定义的Mapper
1 package com.b510.hongten.hadoop; 2 3 import java.io.IOException; 4 import java.util.StringTokenizer; 5 6 import org.apache.hadoop.io.IntWritable; 7 import org.apache.hadoop.io.Text; 8 import org.apache.hadoop.mapreduce.Mapper; 9 10 /** 11 * @author Hongten 12 * @created 11 Nov 2018 13 */ 14 public class MyMapper extends Mapper<Object, Text, Text, IntWritable> { 15 16 private final static IntWritable one = new IntWritable(1); 17 private Text word = new Text(); 18 19 public void map(Object key, Text value, Context context) throws IOException, InterruptedException { 20 StringTokenizer itr = new StringTokenizer(value.toString()); 21 while (itr.hasMoreTokens()) { 22 word.set(itr.nextToken()); 23 context.write(word, one); 24 } 25 } 26 27 }
自定义的Reduce
1 package com.b510.hongten.hadoop; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.io.IntWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Reducer; 8 9 /** 10 * @author Hongten 11 * @created 11 Nov 2018 12 */ 13 public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> { 14 15 private IntWritable result = new IntWritable(); 16 17 public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { 18 int sum = 0; 19 for (IntWritable val : values) { 20 sum += val.get(); 21 } 22 result.set(sum); 23 context.write(key, result); 24 } 25 26 }
运行并查看结果
cd /home/hadoop-2.5/bin/ --创建测试文件夹 ./hdfs dfs -mkdir -p /usr/input/wordcount1 --把测试文件放入测试文件夹 ./hdfs dfs -put /root/word.txt /usr/input/wordcount1 --运行测试 ./hadoop jar /root/wordcount.jar com.b510.hongten.hadoop.WordCount --下载hdfs上面的文件 ./hdfs dfs -get /usr/output/wordcount/* ~/ --查看文件最后5行 tail -n5 /root/part-r-00000
运行结果
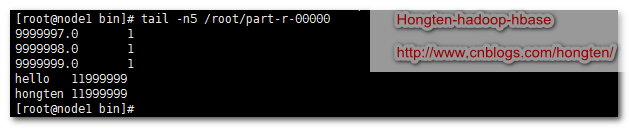
从yarn客户端可以看到程序运行的时间长度
从11:47:46开始,到11:56:48结束,总共9min2s.(这是在我机器上面的虚拟机里面跑的结果,如果在真正的集群里面跑的话,应该要快很多)
数据条数:12000000-1条

3.客户端源码分析
当我们在客户端进行了分布式作业的配置后,最后执行
// Submit the job, then poll for progress until the job is complete job.waitForCompletion(true);
那么在waiteForCompletion()方法里面都做了些什么事情呢?
//我们传递的verbose=true public boolean waitForCompletion(boolean verbose ) throws IOException, InterruptedException, ClassNotFoundException { if (state == JobState.DEFINE) { //提交动作 submit(); } //verbose=true if (verbose) { //监控并且打印job的相关信息 //在客户端执行分布式作业的时候,我们能够看到很多输出 //如果verbose=false,我们则看不到作业输出信息 monitorAndPrintJob(); } else { // get the completion poll interval from the client. int completionPollIntervalMillis = Job.getCompletionPollInterval(cluster.getConf()); while (!isComplete()) { try { Thread.sleep(completionPollIntervalMillis); } catch (InterruptedException ie) { } } } //返回作业的状态 return isSuccessful(); }
这个方法里面最重要的就是submit()方法,提交分布式作业。所以,我们需要进入submit()方法。
public void submit() throws IOException, InterruptedException, ClassNotFoundException { ensureState(JobState.DEFINE); //设置新的API,我使用的2.2.0的HadoopAPI,区别于之前的API setUseNewAPI(); //和集群做连接,集群里面做出相应,分配作业ID connect(); final JobSubmitter submitter = getJobSubmitter(cluster.getFileSystem(), cluster.getClient()); status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() { public JobStatus run() throws IOException, InterruptedException, ClassNotFoundException { //提交作业 /* Internal method for submitting jobs to the system. The job submission process involves: 1. Checking the input and output specifications of the job. 2. Computing the InputSplits for the job. 3. Setup the requisite accounting information for the DistributedCache of the job, if necessary. 4. Copying the job's jar and configuration to the map-reduce system directory on the distributed file-system. 5. Submitting the job to the JobTracker and optionally monitoring it's status. */ //在这个方法里面包含5件事情。 //1.检查输入和输出 //2.为每个job计算输入切片的数量 //3.4.提交资源文件 //5.提交作业,监控状态 //这里要注意的是,在2.x里面,已经没有JobTracker了。 //JobTracker is no longer used since M/R 2.x. //This is a dummy JobTracker class, which is used to be compatible with M/R 1.x applications. return submitter.submitJobInternal(Job.this, cluster); } }); state = JobState.RUNNING; LOG.info("The url to track the job: " + getTrackingURL()); }
所以我们需要进入submitter.submitJObInternal()方法去看看里面的实现。
//在这个方法里面包含5件事情。 //1.检查输入和输出 //2.为每个job计算输入切片的数量 //3.4.提交资源文件 //5.提交作业,监控状态 //这里要注意的是,在2.x里面,已经没有JobTracker了。 JobStatus submitJobInternal(Job job, Cluster cluster) throws ClassNotFoundException, InterruptedException, IOException { //validate the jobs output specs checkSpecs(job); Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, job.getConfiguration()); //configure the command line options correctly on the submitting dfs Configuration conf = job.getConfiguration(); InetAddress ip = InetAddress.getLocalHost(); if (ip != null) { submitHostAddress = ip.getHostAddress(); submitHostName = ip.getHostName(); conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName); conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress); } JobID jobId = submitClient.getNewJobID(); //设置Job的ID job.setJobID(jobId); Path submitJobDir = new Path(jobStagingArea, jobId.toString()); JobStatus status = null; try { conf.set(MRJobConfig.USER_NAME, UserGroupInformation.getCurrentUser().getShortUserName()); conf.set("hadoop.http.filter.initializers", "org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer"); conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString()); LOG.debug("Configuring job " + jobId + " with " + submitJobDir + " as the submit dir"); // get delegation token for the dir TokenCache.obtainTokensForNamenodes(job.getCredentials(), new Path[] { submitJobDir }, conf); populateTokenCache(conf, job.getCredentials()); // generate a secret to authenticate shuffle transfers if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) { KeyGenerator keyGen; try { keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM); keyGen.init(SHUFFLE_KEY_LENGTH); } catch (NoSuchAlgorithmException e) { throw new IOException("Error generating shuffle secret key", e); } SecretKey shuffleKey = keyGen.generateKey(); TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(), job.getCredentials()); } copyAndConfigureFiles(job, submitJobDir); Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir); // Create the splits for the job LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir)); //写切片信息,我们主要关系这个方法 :)) int maps = writeSplits(job, submitJobDir); conf.setInt(MRJobConfig.NUM_MAPS, maps); LOG.info("number of splits:" + maps); // write "queue admins of the queue to which job is being submitted" // to job file. String queue = conf.get(MRJobConfig.QUEUE_NAME, JobConf.DEFAULT_QUEUE_NAME); AccessControlList acl = submitClient.getQueueAdmins(queue); conf.set(toFullPropertyName(queue, QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString()); // removing jobtoken referrals before copying the jobconf to HDFS // as the tasks don't need this setting, actually they may break // because of it if present as the referral will point to a // different job. TokenCache.cleanUpTokenReferral(conf); if (conf.getBoolean( MRJobConfig.JOB_TOKEN_TRACKING_IDS_ENABLED, MRJobConfig.DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED)) { // Add HDFS tracking ids ArrayList<String> trackingIds = new ArrayList<String>(); for (Token<? extends TokenIdentifier> t : job.getCredentials().getAllTokens()) { trackingIds.add(t.decodeIdentifier().getTrackingId()); } conf.setStrings(MRJobConfig.JOB_TOKEN_TRACKING_IDS, trackingIds.toArray(new String[trackingIds.size()])); } // Write job file to submit dir writeConf(conf, submitJobFile); // // Now, actually submit the job (using the submit name) // //到这里才真正提交job printTokens(jobId, job.getCredentials()); status = submitClient.submitJob( jobId, submitJobDir.toString(), job.getCredentials()); if (status != null) { return status; } else { throw new IOException("Could not launch job"); } } finally { if (status == null) { LOG.info("Cleaning up the staging area " + submitJobDir); if (jtFs != null && submitJobDir != null) jtFs.delete(submitJobDir, true); } } }
在这里我们关心的是
int maps = writeSplits(job, submitJobDir);
进入writeSplites()方法
private int writeSplits(org.apache.hadoop.mapreduce.JobContext job, Path jobSubmitDir) throws IOException, InterruptedException, ClassNotFoundException { //可以从job里面获取configuration信息 JobConf jConf = (JobConf)job.getConfiguration(); int maps; if (jConf.getUseNewMapper()) { //调用新的切片方法,我们使用的2.x的hadoop,因此 //使用的是新的切片方法 maps = writeNewSplits(job, jobSubmitDir); } else { //旧的切片方法 maps = writeOldSplits(jConf, jobSubmitDir); } return maps; }
我们使用的版本是2.x,所以,我们使用writeNewSplites()方法。
@SuppressWarnings("unchecked")
private <T extends InputSplit>
int writeNewSplits(JobContext job, Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
//可以从job里面获取configuration信息
Configuration conf = job.getConfiguration();
//通过反射获取一个输入格式化
//这里面返回的是TextInputFormat,即默认值
InputFormat<?, ?> input =
ReflectionUtils.newInstance(job.getInputFormatClass(), conf); // == 1 ==
//输入格式化进行切片计算
List<InputSplit> splits = input.getSplits(job); // == 2 ==
T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]);
// sort the splits into order based on size, so that the biggest
// go first
Arrays.sort(array, new SplitComparator());
JobSplitWriter.createSplitFiles(jobSubmitDir, conf,
jobSubmitDir.getFileSystem(conf), array);
return array.length;
}
我们看到‘== 1 ==’,这里是获取输入格式化,进入job.getInputFormatClass()方法
@SuppressWarnings("unchecked")
public Class<? extends InputFormat<?,?>> getInputFormatClass()
throws ClassNotFoundException {
//如果配置信息里面INPUT_FORMAT_CLASS_ATTR(mapreduce.job.inputformat.class)没有配置
//则返回TextInputFormat
//如果有配置,则返回我们配置的信息
//意思是:默认值为TextInputFormat
return (Class<? extends InputFormat<?,?>>)
conf.getClass(INPUT_FORMAT_CLASS_ATTR, TextInputFormat.class);
}
我们看到,系统默认的输入格式化为TextInputFormat。
我们看到‘== 2 ==’,这里从输入格式化里面进行切片计算。那么我们进入getSplites()方法
public List<InputSplit> getSplits(JobContext job) throws IOException { //minSize = Math.max(1, 1L)=1 long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job)); // == A == //maxSize = Long.MAX_VALUE long maxSize = getMaxSplitSize(job); // == B == // generate splits List<InputSplit> splits = new ArrayList<InputSplit>(); //获取输入文件列表 List<FileStatus> files = listStatus(job); //遍历文件列表 for (FileStatus file: files) { //一个文件一个文件的处理 //然后计算文件的切片 Path path = file.getPath(); //文件大小 long length = file.getLen(); if (length != 0) { BlockLocation[] blkLocations; if (file instanceof LocatedFileStatus) { blkLocations = ((LocatedFileStatus) file).getBlockLocations(); } else { //通过路径获取FileSystem FileSystem fs = path.getFileSystem(job.getConfiguration()); //获取文件所有块信息 blkLocations = fs.getFileBlockLocations(file, 0, length); } //判断文件是否可以切片 if (isSplitable(job, path)) { //可以切片 //获取文件块大小 long blockSize = file.getBlockSize(); //切片大小 splitSize = blockSize //默认情况下,切片大小等于块的大小 long splitSize = computeSplitSize(blockSize, minSize, maxSize); // == C == long bytesRemaining = length; while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { //块的索引 int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); // == D == //切片详细信息 splits.add(makeSplit(path, length-bytesRemaining, splitSize, blkLocations[blkIndex].getHosts())); bytesRemaining -= splitSize; } if (bytesRemaining != 0) { int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining, blkLocations[blkIndex].getHosts())); } } else { // not splitable //不可切片 splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts())); } } else { //Create empty hosts array for zero length files splits.add(makeSplit(path, 0, length, new String[0])); } } // Save the number of input files for metrics/loadgen job.getConfiguration().setLong(NUM_INPUT_FILES, files.size()); LOG.debug("Total # of splits: " + splits.size()); return splits; }
我们看‘== A ==’, getFormatMinSplitSize()方法返回1,getMinSplitSize()方法返回1L。
protected long getFormatMinSplitSize() { return 1; } public static long getMinSplitSize(JobContext job) { //如果我们在配置文件中有配置SPLIT_MINSIZE(mapreduce.input.fileinputformat.split.minsize),则取配置文件里面的 //否则返回默认值1L //这里我们,没有配置,所以返回1L return job.getConfiguration().getLong(SPLIT_MINSIZE, 1L); }
我们看‘== B ==’,getMaxSplitSize()方法返回Long.MAX_VALUE(我们没有进行对SPLIT_MAXSIZE进行配置)
public static long getMaxSplitSize(JobContext context) { //如果我们在配置文件中有配置SPLIT_MAXSIZE(mapreduce.input.fileinputformat.split.maxsize),则取配置文件里面的 //否则返回默认值Long.MAX_VALUE //这里我们,没有配置,所以返回Long.MAX_VALUE return context.getConfiguration().getLong(SPLIT_MAXSIZE, Long.MAX_VALUE); }
我们看‘== C ==’,在我们没有进行配置的情况下,切片大小等于块大小。
//minSize=1 //maxSize=Long.MAX_VALUE protected long computeSplitSize(long blockSize, long minSize, long maxSize) { //Math.min(maxSize, blockSize) -> Math.min(Long.MAX_VALUE, blockSize) -> blockSize //Math.max(minSize, blockSize) -> Math.max(1, blockSize) -> blockSize return Math.max(minSize, Math.min(maxSize, blockSize)); }
我们看‘== D ==’,通过偏移量获取块的索引信息。
protected int getBlockIndex(BlockLocation[] blkLocations, long offset) { //通过偏移量获取块的索引 for (int i = 0 ; i < blkLocations.length; i++) { // is the offset inside this block? if ((blkLocations[i].getOffset() <= offset) && (offset < blkLocations[i].getOffset() + blkLocations[i].getLength())){ return i; } } BlockLocation last = blkLocations[blkLocations.length -1]; long fileLength = last.getOffset() + last.getLength() -1; throw new IllegalArgumentException("Offset " + offset + " is outside of file (0.." + fileLength + ")"); }
4.小结
用通俗的语言来描述上面的事情,可以用下面的图来说明:
系统默认的块大小为128MB,在我们没有进行其他配置的时候,块大小等于切片大小。
Type1:块大小为45MB,小于系统默认大小128MB,
切片信息:path, 0, 45, [3, 8, 10]
切片信息:文件的位置path, 偏移量0, 切片大小45, 块的位置信息[3, 8, 10]=该文件(块)存在HDFS文件系统的datanode3,datanode8,datanode10上面。
Type2:块大小为128MB,即等于系统默认大小128MB,不会分成两个快,和Type1一样。
Type3:块大小为414MB,即大于系统默认128MB,那么在我们上传该文件到HDFS的时候,系统就会把该文件分成很多块,每一块128MB,每一块128MB,直到分完为止,最后剩下30MB单独为一块。那么,每一个切片信息由文件位置path, 偏移量,切片大小, 块的位置信息构成。我们把这一串信息称为文件的切片清单。
当系统拿到了文件的切片清单了以后,那么就会把这些清单提交给分布式系统,再由分布式系统去处理各个切片。

5.Mapper详解
5.1.map输入
map从HDFS获取输入流,然后定位到切片的位置,除了第一个切片,其他切片都是从第二行开始读取数据进行处理。
在org.apache.hadoop.mapred.MapTask里面,包含了run()方法
//org.apache.hadoop.mapred.MapTask public void run(final JobConf job, final TaskUmbilicalProtocol umbilical) throws IOException, ClassNotFoundException, InterruptedException { this.umbilical = umbilical; if (isMapTask()) { // If there are no reducers then there won't be any sort. Hence the map // phase will govern the entire attempt's progress. //我们在客户端可以设置reduce的个数 // job.setNumReduceTasks(10); //如果没有Reduce,只有map阶段, if (conf.getNumReduceTasks() == 0) { //那么就执行这行 mapPhase = getProgress().addPhase("map", 1.0f); } else { // If there are reducers then the entire attempt's progress will be // split between the map phase (67%) and the sort phase (33%). //只要有Reduce阶段, mapPhase = getProgress().addPhase("map", 0.667f); //就要加入排序 sortPhase = getProgress().addPhase("sort", 0.333f); } } TaskReporter reporter = startReporter(umbilical); boolean useNewApi = job.getUseNewMapper(); initialize(job, getJobID(), reporter, useNewApi); // check if it is a cleanupJobTask if (jobCleanup) { runJobCleanupTask(umbilical, reporter); return; } if (jobSetup) { runJobSetupTask(umbilical, reporter); return; } if (taskCleanup) { runTaskCleanupTask(umbilical, reporter); return; } //是否使用新的API if (useNewApi) { //我们使用的是new mapper runNewMapper(job, splitMetaInfo, umbilical, reporter); } else { runOldMapper(job, splitMetaInfo, umbilical, reporter); } done(umbilical, reporter); }
我们进入到runNewMapper()方法,我们可以看到整个map的宏观动作
1.输入初始化
2.调用org.apache.hadoop.mapreduce.Mapper.run()方法
3.更新状态
4.关闭输入
5.关闭输出
@SuppressWarnings("unchecked")
private <INKEY,INVALUE,OUTKEY,OUTVALUE>
void runNewMapper(final JobConf job,
final TaskSplitIndex splitIndex,
final TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException,
InterruptedException {
// make a task context so we can get the classes
//获取任务上下文
org.apache.hadoop.mapreduce.TaskAttemptContext taskContext =
new org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl(job,
getTaskID(),
reporter);
// make a mapper
// 通过反射构造mapper
// 得到我们写的mapper类
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE> mapper =
(org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getMapperClass(), job); // == AA ==
// make the input format
// 通过反射获取输入格式化
// 通过输入格式化,在这里,就可以获取到文件的切片清单
org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE> inputFormat =
(org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE>)
ReflectionUtils.newInstance(taskContext.getInputFormatClass(), job); // == BB ==
// rebuild the input split
//一个map对应的是一个切片,即一个切片对应一个map
org.apache.hadoop.mapreduce.InputSplit split = null;
split = getSplitDetails(new Path(splitIndex.getSplitLocation()),
splitIndex.getStartOffset());
LOG.info("Processing split: " + split);
//这里new了一个NewTrackingRecordReader()
org.apache.hadoop.mapreduce.RecordReader<INKEY,INVALUE> input =
new NewTrackingRecordReader<INKEY,INVALUE>
(split, inputFormat, reporter, taskContext); // == CC ==
job.setBoolean(JobContext.SKIP_RECORDS, isSkipping());
org.apache.hadoop.mapreduce.RecordWriter output = null;
// get an output object
if (job.getNumReduceTasks() == 0) {
output =
new NewDirectOutputCollector(taskContext, job, umbilical, reporter);
} else {
output = new NewOutputCollector(taskContext, job, umbilical, reporter);
}
//创建一个map上下文对象
//这里传入input对象
//这里MapContext,NewTrackingRecordReader,LineRecordReader他们之间的关系是什么呢?
//在MapContext,NewTrackingRecordReader,LineRecordReader类里面都包含了nextKeyValue(),getCurrentKey(), getCurrentValue()方法
//当我们调用MapContext里面的nextKeyValue()的时候,会去掉用NewTrackingRecordReader里面的nextKeyValue()方法,这个方法最终会去调用LineRecordReader里面的nextKeyValue()方法
//即LineRecordReader才是最终做事情的
org.apache.hadoop.mapreduce.MapContext<INKEY, INVALUE, OUTKEY, OUTVALUE>
mapContext =
new MapContextImpl<INKEY, INVALUE, OUTKEY, OUTVALUE>(job, getTaskID(),
input, output,
committer,
reporter, split); // == EE ==
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>.Context
mapperContext =
new WrappedMapper<INKEY, INVALUE, OUTKEY, OUTVALUE>().getMapContext(
mapContext);
try {
//=============================
// 这里列出了mapper的宏观动作
// 1. 输入初始化
// 2. 调用org.apache.hadoop.mapreduce.Mapper.run()方法
// 3. 更新状态
// 4. 关闭输入
// 5. 关闭输出
//=============================
//输入初始化
input.initialize(split, mapperContext); // == FF ==
//然后调用mapper里面的run()方法,即org.apache.hadoop.mapreduce.Mapper里面的run()方法
mapper.run(mapperContext); // == GG ==
//map结束
mapPhase.complete();
setPhase(TaskStatus.Phase.SORT);
statusUpdate(umbilical);
//关闭输入
input.close();
input = null;
//关闭输出
output.close(mapperContext);
output = null;
} finally {
closeQuietly(input);
closeQuietly(output, mapperContext);
}
}
我们看'== AA ==',由于我们在客户端已经设置了我们自定义的mapper,所以系统会返回我们定义的mapper类
//在客户端,我们通过job.setMapperClass(MyMapper.class); //设置了我们自定义的mapper类,因此这里返回我们写的mapper @SuppressWarnings("unchecked") public Class<? extends Mapper<?,?,?,?>> getMapperClass() throws ClassNotFoundException { return (Class<? extends Mapper<?,?,?,?>>) conf.getClass(MAP_CLASS_ATTR, Mapper.class); }
我们看'== BB ==',在上面我们已经提到,系统默认为TextInputFormat输入格式化
//系统默认为TextInputFormat @SuppressWarnings("unchecked") public Class<? extends InputFormat<?,?>> getInputFormatClass() throws ClassNotFoundException { return (Class<? extends InputFormat<?,?>>) conf.getClass(INPUT_FORMAT_CLASS_ATTR, TextInputFormat.class); }
我们看'== CC ==',这里返回一个RecordReader对象
NewTrackingRecordReader(org.apache.hadoop.mapreduce.InputSplit split, org.apache.hadoop.mapreduce.InputFormat<K, V> inputFormat, TaskReporter reporter, org.apache.hadoop.mapreduce.TaskAttemptContext taskContext) throws InterruptedException, IOException { this.reporter = reporter; this.inputRecordCounter = reporter .getCounter(TaskCounter.MAP_INPUT_RECORDS); this.fileInputByteCounter = reporter .getCounter(FileInputFormatCounter.BYTES_READ); List <Statistics> matchedStats = null; if (split instanceof org.apache.hadoop.mapreduce.lib.input.FileSplit) { matchedStats = getFsStatistics(((org.apache.hadoop.mapreduce.lib.input.FileSplit) split) .getPath(), taskContext.getConfiguration()); } fsStats = matchedStats; long bytesInPrev = getInputBytes(fsStats); //客户端输入格式化计算切片 //而在map阶段,输入格式化会创建一个 //org.apache.hadoop.mapreduce.RecordReader<KEYIN, VALUEIN> this.real = inputFormat.createRecordReader(split, taskContext); // == DD == long bytesInCurr = getInputBytes(fsStats); fileInputByteCounter.increment(bytesInCurr - bytesInPrev); }
我们看'== DD ==', 这里直接new一个LineRecordReader行读取器。这个在后面还会提到。因为真正做事情的就是这个行读取器。
//org.apache.hadoop.mapreduce.lib.input.TextInputFormat @Override public RecordReader<LongWritable, Text> createRecordReader(InputSplit split, TaskAttemptContext context) { String delimiter = context.getConfiguration().get( "textinputformat.record.delimiter"); byte[] recordDelimiterBytes = null; if (null != delimiter) recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8); //这里创建了一个行读取器 return new LineRecordReader(recordDelimiterBytes); }
我们看'== EE =='创建map上下文
//这里的reader就是org.apache.hadoop.mapreduce.RecordReader public MapContextImpl(Configuration conf, TaskAttemptID taskid, RecordReader<KEYIN,VALUEIN> reader, RecordWriter<KEYOUT,VALUEOUT> writer, OutputCommitter committer, StatusReporter reporter, InputSplit split) { super(conf, taskid, writer, committer, reporter); this.reader = reader; this.split = split; }
看到这里以后,这里MapContext,NewTrackingRecordReader,LineRecordReader他们之间的关系是什么呢?
这要看这三个类里面的一些共同的方法:
nextKeyValue()
getCurrentKey()
getCurrentValue()
当我们调用MapContext里面的nextKeyValue()的时候,会去掉用NewTrackingRecordReader里面的nextKeyValue()方法,这个方法最终会去调用LineRecordReader里面的nextKeyValue()方法。
即LineRecordReader才是最终做事情的
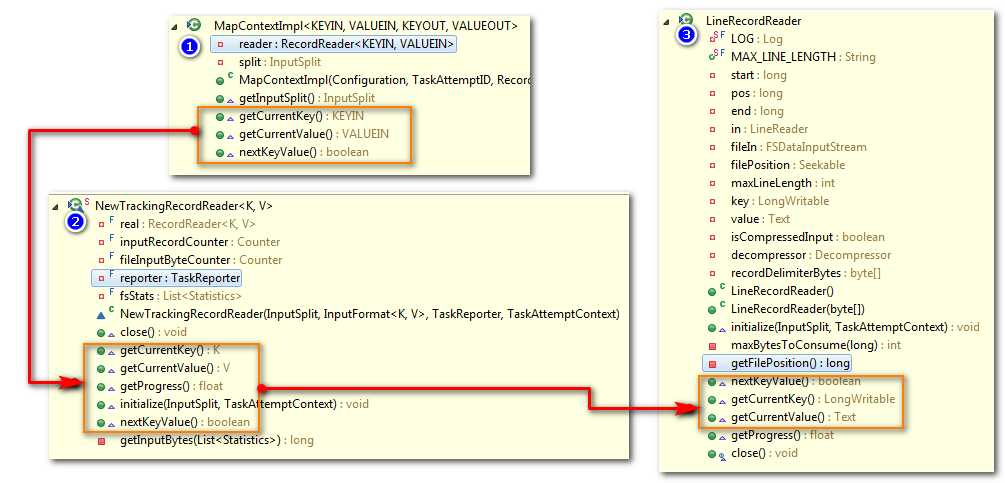
我们看'== FF ==',输入初始化
//输入初始化 public void initialize(InputSplit genericSplit, TaskAttemptContext context) throws IOException { FileSplit split = (FileSplit) genericSplit; Configuration job = context.getConfiguration(); this.maxLineLength = job.getInt(MAX_LINE_LENGTH, Integer.MAX_VALUE); //起始偏移量 start = split.getStart(); //结束偏移量 end = start + split.getLength(); //位置信息 final Path file = split.getPath(); // open the file and seek to the start of the split //打开HDFS文件 final FileSystem fs = file.getFileSystem(job); fileIn = fs.open(file); CompressionCodec codec = new CompressionCodecFactory(job).getCodec(file); if (null!=codec) { isCompressedInput = true; decompressor = CodecPool.getDecompressor(codec); if (codec instanceof SplittableCompressionCodec) { final SplitCompressionInputStream cIn = ((SplittableCompressionCodec)codec).createInputStream( fileIn, decompressor, start, end, SplittableCompressionCodec.READ_MODE.BYBLOCK); if (null == this.recordDelimiterBytes){ in = new LineReader(cIn, job); } else { in = new LineReader(cIn, job, this.recordDelimiterBytes); } start = cIn.getAdjustedStart(); end = cIn.getAdjustedEnd(); filePosition = cIn; } else { if (null == this.recordDelimiterBytes) { in = new LineReader(codec.createInputStream(fileIn, decompressor), job); } else { in = new LineReader(codec.createInputStream(fileIn, decompressor), job, this.recordDelimiterBytes); } filePosition = fileIn; } } else { fileIn.seek(start); if (null == this.recordDelimiterBytes){ in = new LineReader(fileIn, job); } else { in = new LineReader(fileIn, job, this.recordDelimiterBytes); } filePosition = fileIn; } // If this is not the first split, we always throw away first record // because we always (except the last split) read one extra line in // next() method. //如果不是第一个切片,即从第二个切片开始,通常情况下,不会去读取第一行 //而是从第二行开始读取 if (start != 0) { start += in.readLine(new Text(), 0, maxBytesToConsume(start)); } this.pos = start; }
怎样理解下面代码呢?
if (start != 0) { start += in.readLine(new Text(), 0, maxBytesToConsume(start)); }
我们可以通过下图可以知道
一个文件上传到HDFS后,被分成很多block,然而每个block有一定的size,那么在切分这些文件的时候,就可能产生一个block的最后一行被放在两个block里面
e.g.Block1里面的最后一行,原本应该是'hello hongten 5'
但是由于block的size的大小限制,该文本被分成两部分'hello hong' 和 'ten 5'
现在切片个数大于1,那么Block2在读取内容的时候,从第二行开始读取,即从'hello hongten 6'开始读取。而对于Block1在读取内容的时候,则会读取Block2的第一行,即'ten 5'。
这样就保证了数据的完整性了。

我们看'== GG ==',调用org.apache.hadoop.mapreduce.Mapper.run()方法
public void run(Context context) throws IOException, InterruptedException { setup(context); try { //最终调用LineRecordReader.nextKeyValue(), // 这里是一行一行读取数据 // 即读一行数据,调用map()方法 while (context.nextKeyValue()) { //最终调用LineRecordReader.getCurrentKey(), LineRecordReader.getCurrentValue() map(context.getCurrentKey(), context.getCurrentValue(), context); } } finally { cleanup(context); } }
那么LineRecordReader里面的nextKeyValue()做了什么呢?
public boolean nextKeyValue() throws IOException { if (key == null) { //key为偏移量,默认为LongWritable key = new LongWritable(); } //给key赋值 key.set(pos); if (value == null) { //value默认为Text value = new Text(); } int newSize = 0; // We always read one extra line, which lies outside the upper // split limit i.e. (end - 1) //这里总是读取多一行,为什么要读取多一行呢?现在知道了吧 while (getFilePosition() <= end) { //给value赋值 newSize = in.readLine(value, maxLineLength, Math.max(maxBytesToConsume(pos), maxLineLength)); pos += newSize; if (newSize < maxLineLength) { break; } // line too long. try again LOG.info("Skipped line of size " + newSize + " at pos " + (pos - newSize)); } if (newSize == 0) { key = null; value = null; return false; } else { return true; } } @Override public LongWritable getCurrentKey() { //因为在nextKeyValue()已经赋值,直接返回 return key; } @Override public Text getCurrentValue() { //因为在nextKeyValue()已经赋值,直接返回 return value; }
5.2.map输出
@SuppressWarnings("unchecked")
private <INKEY,INVALUE,OUTKEY,OUTVALUE>
void runNewMapper(final JobConf job,
final TaskSplitIndex splitIndex,
final TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException,
InterruptedException {
//.....其他代码省略
org.apache.hadoop.mapreduce.RecordWriter output = null;
// get an output object
//如果没有Reduce
if (job.getNumReduceTasks() == 0) {
output =
new NewDirectOutputCollector(taskContext, job, umbilical, reporter);
} else {
//在我们客户端定义了一个reduce
output = new NewOutputCollector(taskContext, job, umbilical, reporter);
}
//.....其他代码省略
}
在NewOutputCollector里面做了什么呢?
@SuppressWarnings("unchecked")
NewOutputCollector(org.apache.hadoop.mapreduce.JobContext jobContext,
JobConf job,
TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException {
//创建一个collecter容器
collector = createSortingCollector(job, reporter); // == OO1 ==
//分区数量 = Reduce Task的数量
partitions = jobContext.getNumReduceTasks();
if (partitions > 1) {
//多个分区
partitioner = (org.apache.hadoop.mapreduce.Partitioner<K,V>)
ReflectionUtils.newInstance(jobContext.getPartitionerClass(), job); // == OO2 ==
} else {
//第1个分区器,获取0号分区器
partitioner = new org.apache.hadoop.mapreduce.Partitioner<K,V>() {
@Override
public int getPartition(K key, V value, int numPartitions) {
return partitions - 1;
}
};
}
}
我们看看'== OO1 ==',调用createSortingCollector()创建一个collector容器
@SuppressWarnings("unchecked")
private <KEY, VALUE> MapOutputCollector<KEY, VALUE>
createSortingCollector(JobConf job, TaskReporter reporter)
throws IOException, ClassNotFoundException {
MapOutputCollector<KEY, VALUE> collector
= (MapOutputCollector<KEY, VALUE>)
ReflectionUtils.newInstance(
job.getClass(JobContext.MAP_OUTPUT_COLLECTOR_CLASS_ATTR,
MapOutputBuffer.class, MapOutputCollector.class), job);
LOG.info("Map output collector class = " + collector.getClass().getName());
MapOutputCollector.Context context =
new MapOutputCollector.Context(this, job, reporter);
//容器初始化
collector.init(context);
//返回容器
return collector;
}
调用init()方法,在该方法里面主要做了以下几件事情:
1.设置内存缓冲区
2.设置排序器
3.设置比较器
4.设置合并器
5.设置溢写线程
public void init(MapOutputCollector.Context context ) throws IOException, ClassNotFoundException { job = context.getJobConf(); reporter = context.getReporter(); mapTask = context.getMapTask(); mapOutputFile = mapTask.getMapOutputFile(); sortPhase = mapTask.getSortPhase(); spilledRecordsCounter = reporter.getCounter(TaskCounter.SPILLED_RECORDS); partitions = job.getNumReduceTasks(); rfs = ((LocalFileSystem)FileSystem.getLocal(job)).getRaw(); //sanity checks //map处理数据的时候,需要放入内存缓冲区 //那么这里的100就是系统默认的缓冲区大小,即100MB。 //我们可以通过配置IO_SORT_MB(mapreduce.task.io.sort.mb)对缓冲区大小进行调节。 //0.8的是内存缓冲区阈值的意思,就是当这个缓冲区使用了80%,那么这个时候, //缓冲区里面的80%的数据就可以溢写到磁盘。 // 我们可以通过配置MAP_SORT_SPILL_PERCENT(mapreduce.map.sort.spill.percent)对缓冲区阈值进行调节。 final float spillper = job.getFloat(JobContext.MAP_SORT_SPILL_PERCENT, (float)0.8); final int sortmb = job.getInt(JobContext.IO_SORT_MB, 100); indexCacheMemoryLimit = job.getInt(JobContext.INDEX_CACHE_MEMORY_LIMIT, INDEX_CACHE_MEMORY_LIMIT_DEFAULT); if (spillper > (float)1.0 || spillper <= (float)0.0) { throw new IOException("Invalid \"" + JobContext.MAP_SORT_SPILL_PERCENT + "\": " + spillper); } if ((sortmb & 0x7FF) != sortmb) { throw new IOException( "Invalid \"" + JobContext.IO_SORT_MB + "\": " + sortmb); } //排序器,默认为快速排序算法(QuickSort) //把map里面的乱序的数据,使用快速排序算法进行排序 //使得内存中乱序的数据进行排序,然后把排序好的数据,溢写到磁盘 sorter = ReflectionUtils.newInstance(job.getClass("map.sort.class", QuickSort.class, IndexedSorter.class), job); // buffers and accounting int maxMemUsage = sortmb << 20; maxMemUsage -= maxMemUsage % METASIZE; kvbuffer = new byte[maxMemUsage]; bufvoid = kvbuffer.length; kvmeta = ByteBuffer.wrap(kvbuffer) .order(ByteOrder.nativeOrder()) .asIntBuffer(); setEquator(0); bufstart = bufend = bufindex = equator; kvstart = kvend = kvindex; maxRec = kvmeta.capacity() / NMETA; softLimit = (int)(kvbuffer.length * spillper); bufferRemaining = softLimit; if (LOG.isInfoEnabled()) { LOG.info(JobContext.IO_SORT_MB + ": " + sortmb); LOG.info("soft limit at " + softLimit); LOG.info("bufstart = " + bufstart + "; bufvoid = " + bufvoid); LOG.info("kvstart = " + kvstart + "; length = " + maxRec); } // k/v serialization //比较器 comparator = job.getOutputKeyComparator(); // == OO3 == keyClass = (Class<K>)job.getMapOutputKeyClass(); valClass = (Class<V>)job.getMapOutputValueClass(); serializationFactory = new SerializationFactory(job); keySerializer = serializationFactory.getSerializer(keyClass); keySerializer.open(bb); valSerializer = serializationFactory.getSerializer(valClass); valSerializer.open(bb); // output counters mapOutputByteCounter = reporter.getCounter(TaskCounter.MAP_OUTPUT_BYTES); mapOutputRecordCounter = reporter.getCounter(TaskCounter.MAP_OUTPUT_RECORDS); fileOutputByteCounter = reporter .getCounter(TaskCounter.MAP_OUTPUT_MATERIALIZED_BYTES); // compression if (job.getCompressMapOutput()) { Class<? extends CompressionCodec> codecClass = job.getMapOutputCompressorClass(DefaultCodec.class); codec = ReflectionUtils.newInstance(codecClass, job); } else { codec = null; } // combiner //合并器 final Counters.Counter combineInputCounter = reporter.getCounter(TaskCounter.COMBINE_INPUT_RECORDS); combinerRunner = CombinerRunner.create(job, getTaskID(), combineInputCounter, reporter, null); if (combinerRunner != null) { final Counters.Counter combineOutputCounter = reporter.getCounter(TaskCounter.COMBINE_OUTPUT_RECORDS); combineCollector= new CombineOutputCollector<K,V>(combineOutputCounter, reporter, job); } else { combineCollector = null; } spillInProgress = false; //最小溢写值,默认为3 //即在默认情况下,我们在定义了合并器, // 1. 在内存溢写到磁盘的过程中,在溢写之前,数据会在内存中进行合并。 // 2. 在溢写的文件的过程中,文件数量>3,那么此时就会触发合并器进行合并文件。 minSpillsForCombine = job.getInt(JobContext.MAP_COMBINE_MIN_SPILLS, 3); //溢写线程 spillThread.setDaemon(true); spillThread.setName("SpillThread"); spillLock.lock(); try { spillThread.start(); while (!spillThreadRunning) { spillDone.await(); } } catch (InterruptedException e) { throw new IOException("Spill thread failed to initialize", e); } finally { spillLock.unlock(); } if (sortSpillException != null) { throw new IOException("Spill thread failed to initialize", sortSpillException); } }
这里涉及到环形缓冲区:
我们看看'== OO3 ==', 获取比较器
public RawComparator getOutputKeyComparator() { // 1. 用户配置了取用户配置的 // 2. 用户没有配置,则取key自身的比较器 Class<? extends RawComparator> theClass = getClass( JobContext.KEY_COMPARATOR, null, RawComparator.class); if (theClass != null) return ReflectionUtils.newInstance(theClass, this); return WritableComparator.get(getMapOutputKeyClass().asSubclass(WritableComparable.class)); }
我们看看'== OO2 ==',获取分区器
@SuppressWarnings("unchecked")
public Class<? extends Partitioner<?,?>> getPartitionerClass()
throws ClassNotFoundException {
//默认为HashPartitioner
return (Class<? extends Partitioner<?,?>>)
conf.getClass(PARTITIONER_CLASS_ATTR, HashPartitioner.class);
}
//在HashPartitioner中包含getPartition()方法
public int getPartition(K key, V value,
int numReduceTasks) {
//分区
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
当我们客户端的map调用write(key, value)方法时,系统会在内部调用collector.collect()方法,获取key, value, partitions,即k,v,p
public void write(K key, V value) throws IOException, InterruptedException { collector.collect(key, value, partitioner.getPartition(key, value, partitions)); }
最后会调用close()方法,关闭输出
@Override public void close(TaskAttemptContext context ) throws IOException,InterruptedException { try { collector.flush(); } catch (ClassNotFoundException cnf) { throw new IOException("can't find class ", cnf); } collector.close(); }
5.3.map小结
在map输入阶段:每个map处理一个切片的数据量,需要seek(),让出第一行,从第二行开始读取数据(切片数量大于1)。
在map输出阶段:map输出的是Key, value;但是map计算完成以后,会得到key, value, partition.也就是说,每个数据从map输出只有,就知道归属于哪一个reduce task去处理了,归属于那个分区
之后,在内存中有一个内存缓冲区buffer in memory,这个内存缓冲区是环形缓冲区。
内存大小默认是100MB,为了是内存溢写不阻塞,默认的阈值是80%,即只要大于等于80MB的时候,就会触发溢写,溢写会把内存中的数据写入到磁盘。在写入磁盘之前要对数据进行快速排序,这是整个框架当中仅有的一次,把数据从乱序到有序。后面的排序都是把有序的数据进行归并排序了。
在排序的时候,有一个判定。有可能我们定义了combiner,需要压缩一下数据。
现在大数据,最大的瓶颈就是I/O,磁盘I/O,网络I/O,都是慢I/O。
所以在I/O之前,能在内存里面排序就排序,能压缩就尽量压缩。那么在调用I/O的时候,写的数据越少越好,速度就越快。
在溢写的时候(partion, sort and spill to disk),先按分区排序,在分区内再按key排序。这是因为map计算的结果是key, value, partition.这样的文件才能是内部有序。最后,溢写很多的小文件要归并成一个大文件。那么大文件也是按分区排序,文件里面再按key排序。
- 如果我们做了combiner,在归并成大文件的时候,框架默认的小文件数量是3个
- 只要我们设置的值大于等于3(mapreduce.map.combine.minspills)
就会触发combiner压缩数据,这是为了减少在shuffer阶段拉取网络I/O,以及在拉完数据以后,让Reduce处理数据量变少,加快计算速度。所以map的工作的核心目的,就是让reduce跑的越来越快。
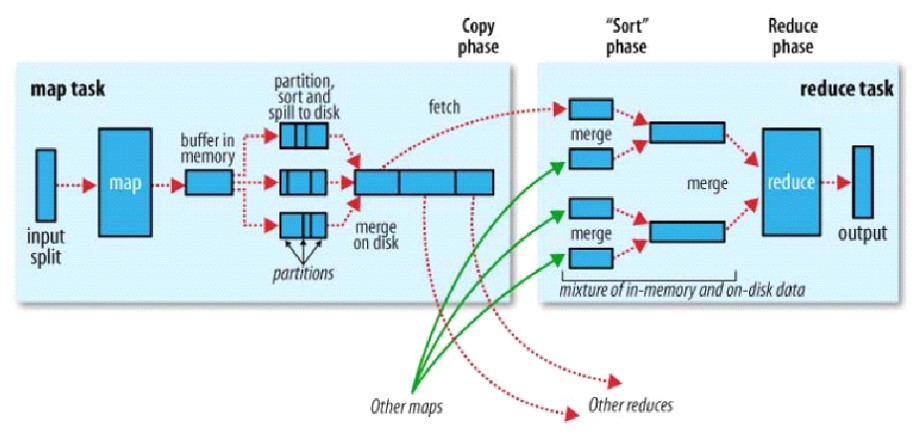
6.Reduce详解
Reduce需要从Map那边获取Map的输出,作为Reduce的输入。
@Override @SuppressWarnings("unchecked") public void run(JobConf job, final TaskUmbilicalProtocol umbilical) throws IOException, InterruptedException, ClassNotFoundException { job.setBoolean(JobContext.SKIP_RECORDS, isSkipping()); //================= Shuffer阶段从Map端拉取数据 开始 ============ if (isMapOrReduce()) { copyPhase = getProgress().addPhase("copy"); sortPhase = getProgress().addPhase("sort"); reducePhase = getProgress().addPhase("reduce"); } // start thread that will handle communication with parent TaskReporter reporter = startReporter(umbilical); boolean useNewApi = job.getUseNewReducer(); initialize(job, getJobID(), reporter, useNewApi); // check if it is a cleanupJobTask if (jobCleanup) { runJobCleanupTask(umbilical, reporter); return; } if (jobSetup) { runJobSetupTask(umbilical, reporter); return; } if (taskCleanup) { runTaskCleanupTask(umbilical, reporter); return; } // Initialize the codec codec = initCodec(); RawKeyValueIterator rIter = null; ShuffleConsumerPlugin shuffleConsumerPlugin = null; boolean isLocal = false; // local if // 1) framework == local or // 2) framework == null and job tracker address == local String framework = job.get(MRConfig.FRAMEWORK_NAME); String masterAddr = job.get(MRConfig.MASTER_ADDRESS, "local"); if ((framework == null && masterAddr.equals("local")) || (framework != null && framework.equals(MRConfig.LOCAL_FRAMEWORK_NAME))) { isLocal = true; } if (!isLocal) { Class combinerClass = conf.getCombinerClass(); CombineOutputCollector combineCollector = (null != combinerClass) ? new CombineOutputCollector(reduceCombineOutputCounter, reporter, conf) : null; Class<? extends ShuffleConsumerPlugin> clazz = job.getClass(MRConfig.SHUFFLE_CONSUMER_PLUGIN, Shuffle.class, ShuffleConsumerPlugin.class); shuffleConsumerPlugin = ReflectionUtils.newInstance(clazz, job); LOG.info("Using ShuffleConsumerPlugin: " + shuffleConsumerPlugin); ShuffleConsumerPlugin.Context shuffleContext = new ShuffleConsumerPlugin.Context(getTaskID(), job, FileSystem.getLocal(job), umbilical, super.lDirAlloc, reporter, codec, combinerClass, combineCollector, spilledRecordsCounter, reduceCombineInputCounter, shuffledMapsCounter, reduceShuffleBytes, failedShuffleCounter, mergedMapOutputsCounter, taskStatus, copyPhase, sortPhase, this, mapOutputFile); shuffleConsumerPlugin.init(shuffleContext); //rIter这个迭代器里面的数据就是从Map端拉取的数据集 //即接下来Reduce的数据输入源 rIter = shuffleConsumerPlugin.run(); } else { // local job runner doesn't have a copy phase copyPhase.complete(); final FileSystem rfs = FileSystem.getLocal(job).getRaw(); rIter = Merger.merge(job, rfs, job.getMapOutputKeyClass(), job.getMapOutputValueClass(), codec, getMapFiles(rfs, true), !conf.getKeepFailedTaskFiles(), job.getInt(JobContext.IO_SORT_FACTOR, 100), new Path(getTaskID().toString()), job.getOutputKeyComparator(), reporter, spilledRecordsCounter, null, null); } // free up the data structures mapOutputFilesOnDisk.clear(); //================= Shuffer阶段从Map端拉取数据 结束 ============ sortPhase.complete(); // sort is complete setPhase(TaskStatus.Phase.REDUCE); statusUpdate(umbilical); Class keyClass = job.getMapOutputKeyClass(); Class valueClass = job.getMapOutputValueClass(); //分组比较器 RawComparator comparator = job.getOutputValueGroupingComparator(); // === RR0 == if (useNewApi) { //使用新API runNewReducer(job, umbilical, reporter, rIter, comparator, keyClass, valueClass); // === RR1 == } else { runOldReducer(job, umbilical, reporter, rIter, comparator, keyClass, valueClass); } if (shuffleConsumerPlugin != null) { shuffleConsumerPlugin.close(); } done(umbilical, reporter); }
我们看'=== RR0 ==',分组比较器
我们通过代码可以看出里面的逻辑:
1.如果用户设置了分组比较器,系统则使用
2.如果用户没有设置分组比较器,系统会查看用户是否设置了排序比较器,如果有设置,则使用
3.如果用户没有设置分组比较器,排序比较器,那么系统会使用自身的key比较器
//1.用户是否设置分组比较器GROUP_COMPARATOR_CLASS //2.用户是否设置排序比较器KEY_COMPARATOR //3.如果用户都没有设置,则使用自身key比较器 public RawComparator getOutputValueGroupingComparator() { //通过反射获取分组比较器 //用户可以通过配置GROUP_COMPARATOR_CLASS(mapreduce.job.output.group.comparator.class)来定义比较器 Class<? extends RawComparator> theClass = getClass( JobContext.GROUP_COMPARATOR_CLASS, null, RawComparator.class); if (theClass == null) { return getOutputKeyComparator(); } return ReflectionUtils.newInstance(theClass, this); } public RawComparator getOutputKeyComparator() { //用户是否设置排序比较器KEY_COMPARATOR //如果用户都没有设置,则使用自身key比较器 Class<? extends RawComparator> theClass = getClass( JobContext.KEY_COMPARATOR, null, RawComparator.class); if (theClass != null) return ReflectionUtils.newInstance(theClass, this); return WritableComparator.get(getMapOutputKeyClass().asSubclass(WritableComparable.class)); } //自身key比较器 public Class<?> getMapOutputKeyClass() { Class<?> retv = getClass(JobContext.MAP_OUTPUT_KEY_CLASS, null, Object.class); if (retv == null) { retv = getOutputKeyClass(); } return retv; }
我们看看‘=== RR1 ==’,
private <INKEY,INVALUE,OUTKEY,OUTVALUE> void runNewReducer(JobConf job, final TaskUmbilicalProtocol umbilical, final TaskReporter reporter, RawKeyValueIterator rIter, RawComparator<INKEY> comparator, Class<INKEY> keyClass, Class<INVALUE> valueClass ) throws IOException,InterruptedException, ClassNotFoundException { // wrap value iterator to report progress. final RawKeyValueIterator rawIter = rIter; rIter = new RawKeyValueIterator() { public void close() throws IOException { rawIter.close(); } public DataInputBuffer getKey() throws IOException { return rawIter.getKey(); } public Progress getProgress() { return rawIter.getProgress(); } public DataInputBuffer getValue() throws IOException { return rawIter.getValue(); } public boolean next() throws IOException { boolean ret = rawIter.next(); reporter.setProgress(rawIter.getProgress().getProgress()); return ret; } }; // make a task context so we can get the classes org.apache.hadoop.mapreduce.TaskAttemptContext taskContext = new org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl(job, getTaskID(), reporter); // make a reducer org.apache.hadoop.mapreduce.Reducer<INKEY,INVALUE,OUTKEY,OUTVALUE> reducer = (org.apache.hadoop.mapreduce.Reducer<INKEY,INVALUE,OUTKEY,OUTVALUE>) ReflectionUtils.newInstance(taskContext.getReducerClass(), job); org.apache.hadoop.mapreduce.RecordWriter<OUTKEY,OUTVALUE> trackedRW = new NewTrackingRecordWriter<OUTKEY, OUTVALUE>(this, taskContext); job.setBoolean("mapred.skip.on", isSkipping()); job.setBoolean(JobContext.SKIP_RECORDS, isSkipping()); //创建Reduce上下文 org.apache.hadoop.mapreduce.Reducer.Context reducerContext = createReduceContext(reducer, job, getTaskID(), rIter, reduceInputKeyCounter, reduceInputValueCounter, trackedRW, committer, reporter, comparator, keyClass, valueClass); try { //调用org.apache.hadoop.mapreduce.Reducer.run()方法 reducer.run(reducerContext); } finally { trackedRW.close(reducerContext); } }
进入createReduceContext()方法
protected static <INKEY,INVALUE,OUTKEY,OUTVALUE> org.apache.hadoop.mapreduce.Reducer<INKEY,INVALUE,OUTKEY,OUTVALUE>.Context createReduceContext(org.apache.hadoop.mapreduce.Reducer <INKEY,INVALUE,OUTKEY,OUTVALUE> reducer, Configuration job, org.apache.hadoop.mapreduce.TaskAttemptID taskId, RawKeyValueIterator rIter, org.apache.hadoop.mapreduce.Counter inputKeyCounter, org.apache.hadoop.mapreduce.Counter inputValueCounter, org.apache.hadoop.mapreduce.RecordWriter<OUTKEY,OUTVALUE> output, org.apache.hadoop.mapreduce.OutputCommitter committer, org.apache.hadoop.mapreduce.StatusReporter reporter, RawComparator<INKEY> comparator, Class<INKEY> keyClass, Class<INVALUE> valueClass ) throws IOException, InterruptedException { org.apache.hadoop.mapreduce.ReduceContext<INKEY, INVALUE, OUTKEY, OUTVALUE> reduceContext = //创建ReduceContextImpl实例对象 new ReduceContextImpl<INKEY, INVALUE, OUTKEY, OUTVALUE>(job, taskId, rIter, inputKeyCounter, inputValueCounter, output, committer, reporter, comparator, keyClass, valueClass); org.apache.hadoop.mapreduce.Reducer<INKEY,INVALUE,OUTKEY,OUTVALUE>.Context reducerContext = new WrappedReducer<INKEY, INVALUE, OUTKEY, OUTVALUE>().getReducerContext( reduceContext); return reducerContext; }
进入ReduceContextImpl()方法
public ReduceContextImpl(Configuration conf, TaskAttemptID taskid, RawKeyValueIterator input, Counter inputKeyCounter, Counter inputValueCounter, RecordWriter<KEYOUT,VALUEOUT> output, OutputCommitter committer, StatusReporter reporter, RawComparator<KEYIN> comparator, Class<KEYIN> keyClass, Class<VALUEIN> valueClass ) throws InterruptedException, IOException{ super(conf, taskid, output, committer, reporter); this.input = input; this.inputKeyCounter = inputKeyCounter; this.inputValueCounter = inputValueCounter; this.comparator = comparator; this.serializationFactory = new SerializationFactory(conf); this.keyDeserializer = serializationFactory.getDeserializer(keyClass); this.keyDeserializer.open(buffer); this.valueDeserializer = serializationFactory.getDeserializer(valueClass); this.valueDeserializer.open(buffer); hasMore = input.next(); this.keyClass = keyClass; this.valueClass = valueClass; this.conf = conf; this.taskid = taskid; }
最后会把map端的输出,作为Reduce端的输入传递到这里。
public void run(Context context) throws IOException, InterruptedException { setup(context); try { //循环每一个key while (context.nextKey()) { //调用reduce方法,这个方法我们已经重写,所以每次调用的时候,会调用我们自己的reduce方法 reduce(context.getCurrentKey(), context.getValues(), context); // If a back up store is used, reset it Iterator<VALUEIN> iter = context.getValues().iterator(); if(iter instanceof ReduceContext.ValueIterator) { ((ReduceContext.ValueIterator<VALUEIN>)iter).resetBackupStore(); } } } finally { cleanup(context); } }
7.总结
========================================================
More reading,and english is important.
I'm Hongten
大哥哥大姐姐,觉得有用打赏点哦!你的支持是我最大的动力。谢谢。
Hongten博客排名在100名以内。粉丝过千。
Hongten出品,必是精品。
E | hongtenzone@foxmail.com B | http://www.cnblogs.com/hongten
========================================================

 浙公网安备 33010602011771号
浙公网安备 33010602011771号