lucene加权_模仿百度(Baidu)推广
我们在百度上面搜索一些东西的时候,会在最前面出现一些不是我们想要的信息
如:
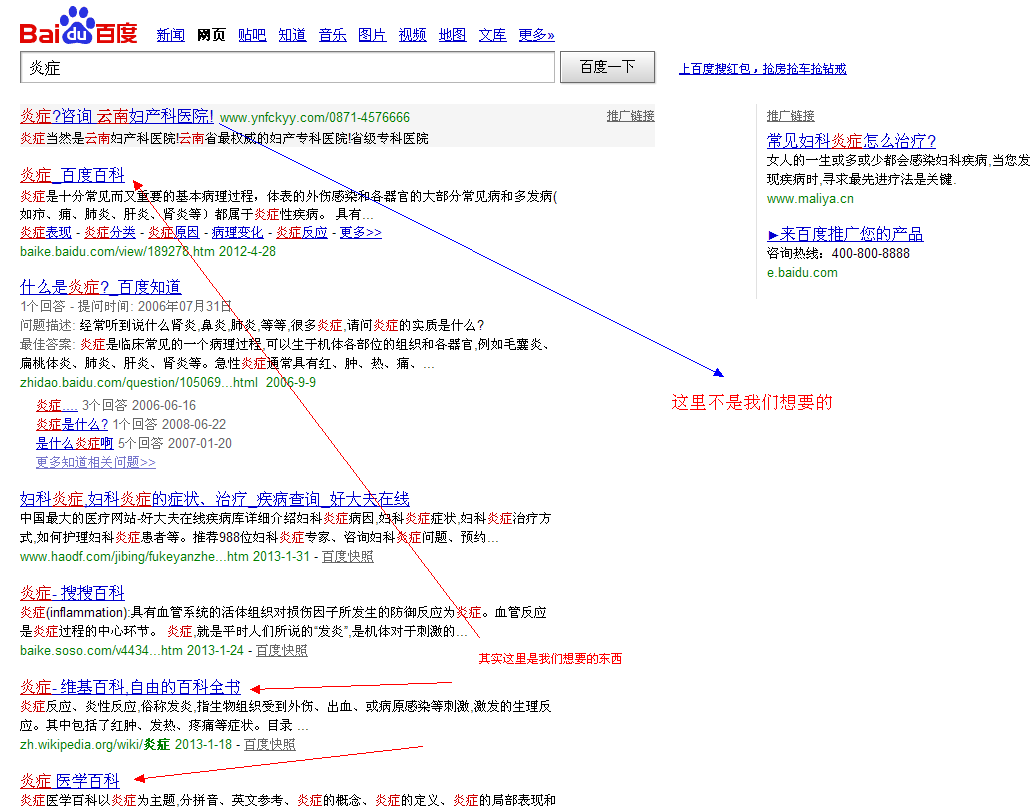
在百度这里,是做了加权操作的,也就是我们知道的百度推广
那么现在我们就模拟一下百度推广
===================================================================
项目结构:
运行代码:
1 TermQuery query = new TermQuery(new Term("content","hello"));
运行效果:

也就是说,当我们搜索"hello"关键字的时候,会把所有包含关键字"hello"的结果返回出来,再依据各自的得分大小
进行结果排序,所以就算最后一个包含两个关键字"hello",但是还是排在后面,权值高的会排在前面。
运行代码:
1 TermQuery query = new TermQuery(new Term("content","ee"));
运行效果:

当我们搜索包含关键字为"ee"的时候,会出现一条记录,为什么呢?其实很好理解,因为在所有的记录中,包含关键字"ee"的
结果只有一条记录,其他记录虽然权值要比上面的结果大,但是没有包含关键字"ee",所以显示的结果也是理所当然。
声明:如果有不正确的地方,还请大家多多指教,大家可以一起探讨
================================================================
代码部分:
================================================================
/lucene_0300_boost/src/com/b510/lucene/util/LuceneUtil.java
1 /** 2 * 3 */ 4 package com.b510.lucene.util; 5 6 import java.io.File; 7 import java.io.IOException; 8 import java.util.HashMap; 9 import java.util.Map; 10 11 import org.apache.lucene.analysis.standard.StandardAnalyzer; 12 import org.apache.lucene.document.Document; 13 import org.apache.lucene.document.Field; 14 import org.apache.lucene.index.CorruptIndexException; 15 import org.apache.lucene.index.IndexReader; 16 import org.apache.lucene.index.IndexWriter; 17 import org.apache.lucene.index.IndexWriterConfig; 18 import org.apache.lucene.index.Term; 19 import org.apache.lucene.search.IndexSearcher; 20 import org.apache.lucene.search.ScoreDoc; 21 import org.apache.lucene.search.TermQuery; 22 import org.apache.lucene.search.TopDocs; 23 import org.apache.lucene.store.Directory; 24 import org.apache.lucene.store.FSDirectory; 25 import org.apache.lucene.store.LockObtainFailedException; 26 import org.apache.lucene.util.Version; 27 28 /** 29 * @author Hongten <br /> 30 * @date 2013-1-31 31 */ 32 public class LuceneUtil { 33 34 /** 35 * 邮件id 36 */ 37 private String[] ids = { "1", "2", "3", "4", "5", "6" }; 38 /** 39 * 邮箱 40 */ 41 private String[] emails = { "aa@sina.com", "bb@foxmail.com", "cc@qq.com", 42 "dd@163.com", "ee@gmail.com", "ff@sina.com" }; 43 /** 44 * 邮件内容 45 */ 46 private String[] contents = { "hello,aa,hi,hell world!!", 47 "hello,bb,i'm a boy", 48 "hello,cc", 49 "hello,dd,welcome to my zone,this is a test hello", 50 "hello,ee,haha,xixi,hello world!!", 51 "hello,ff" }; 52 53 /** 54 * 收件人的名称 55 */ 56 private String[] names = { "hongten", "hanyuan", "Devide", "Tom", "Steven", 57 "Shala" }; 58 59 private Directory directory = null; 60 /** 61 * 评分 62 */ 63 private Map<String, Float> scores = new HashMap<String, Float>(); 64 65 public LuceneUtil() { 66 try { 67 scores.put("sina.com", 1.0f); 68 scores.put("foxmail.com", 1.1f); 69 directory = FSDirectory.open(new File( 70 "D:/WordPlace/lucene/lucene_0300_boost/lucene/index")); 71 } catch (IOException e) { 72 e.printStackTrace(); 73 } 74 } 75 76 /** 77 * 创建索引 78 */ 79 public void index() { 80 IndexWriter writer = null; 81 try { 82 writer = new IndexWriter(directory, new IndexWriterConfig( 83 Version.LUCENE_35, new StandardAnalyzer(Version.LUCENE_35))); 84 //删除之前所建立的全部索引 85 writer.deleteAll(); 86 // 创建文档 87 Document document = null; 88 for (int i = 0; i < ids.length; i++) { 89 // Field.Store.YES:将会存储域值,原始字符串的值会保存在索引,以此可以进行相应的回复操作,对于主键,标题可以是这种方式存储 90 // Field.Store.NO:不会存储域值,通常与Index.ANAYLIZED和起来使用,索引一些如文章正文等不需要恢复的文档 91 // ============================== 92 // Field.Index.ANALYZED:进行分词和索引,适用于标题,内容等 93 // Field.Index.NOT_ANALYZED:进行索引,但是不进行分词,如身份证号码,姓名,ID等,适用于精确搜索 94 // Field.Index.ANALYZED_NOT_NORMS:进行分词,但是不进行存储norms信息,这个norms中包括了创建索引的时间和权值等信息 95 // Field.Index.NOT_ANALYZED_NOT_NORMS:不进行分词也不进行存储norms信息(不推荐) 96 // Field.Index.NO:不进行分词 97 document = new Document(); 98 document.add(new Field("id", ids[i], Field.Store.YES, 99 Field.Index.NOT_ANALYZED_NO_NORMS)); 100 document.add(new Field("email", emails[i], Field.Store.YES, 101 Field.Index.NOT_ANALYZED)); 102 document.add(new Field("content", contents[i], Field.Store.YES, 103 Field.Index.ANALYZED)); 104 document.add(new Field("name", names[i], Field.Store.YES, 105 Field.Index.NOT_ANALYZED_NO_NORMS)); 106 //这里进行加权处理 107 String et = emails[i].substring(emails[i].lastIndexOf("@")+1); 108 System.out.println(et); 109 if(scores.containsKey(et)){ 110 document.setBoost(scores.get(et)); 111 }else{ 112 document.setBoost(0.6f); 113 } 114 writer.addDocument(document); 115 } 116 } catch (CorruptIndexException e) { 117 e.printStackTrace(); 118 } catch (LockObtainFailedException e) { 119 e.printStackTrace(); 120 } catch (IOException e) { 121 e.printStackTrace(); 122 } finally { 123 if (writer != null) { 124 try { 125 writer.close(); 126 } catch (CorruptIndexException e) { 127 e.printStackTrace(); 128 } catch (IOException e) { 129 e.printStackTrace(); 130 } 131 } 132 } 133 } 134 135 /** 136 * 搜索 137 */ 138 public void search(){ 139 try { 140 IndexReader reader = IndexReader.open(directory); 141 IndexSearcher searcher = new IndexSearcher(reader); 142 TermQuery query = new TermQuery(new Term("content","hello")); 143 TopDocs tds =searcher.search(query, 10); 144 for(ScoreDoc sd : tds.scoreDocs){ 145 Document doc = searcher.doc(sd.doc); 146 System.out.println("文档序号:["+sd.doc+"] 得分:["+sd.score+"] 邮件名称:["+doc.get("email")+"] 邮件人:["+doc.get("name")+"] 内容 : ["+doc.get("content")+"]"); 147 } 148 } catch (CorruptIndexException e) { 149 e.printStackTrace(); 150 } catch (IOException e) { 151 e.printStackTrace(); 152 } 153 } 154 }
/lucene_0300_boost/src/com/b510/lucene/test/IndexTest.java
1 /** 2 * 3 */ 4 package com.b510.lucene.test; 5 6 import org.junit.Test; 7 8 import com.b510.lucene.util.LuceneUtil; 9 10 /** 11 * @author Hongten <br /> 12 * @date 2013-1-31 13 */ 14 public class IndexTest { 15 16 @Test 17 public void testIndex(){ 18 LuceneUtil util = new LuceneUtil(); 19 util.index(); 20 } 21 22 @Test 23 public void testSearch(){ 24 LuceneUtil util = new LuceneUtil(); 25 util.search(); 26 } 27 28 }
I'm Hongten


 浙公网安备 33010602011771号
浙公网安备 33010602011771号