
presto原理
presto:
https://blog.csdn.net/u011596455/article/details/86558218
部署:
https://blog.csdn.net/weixin_33701564/article/details/91894251
EMR:
https://help.aliyun.com/document_detail/64035.html?spm=a2c4g.11186623.6.827.424b2ae70yGokQ
Presto 是一款由FaceBook开源的一个分布式SQL-on—Hadoop分析引擎。Presto目前由开源社区和FaceBook内部工程师共同维护,并衍生出多个商业版本
使用的技术,如向量计算,动态编译执行计划,优化的ORC和Parquet Reader等
presto不太支持存储过程,支持部分标准sql
presto的查询速度比hive快5-10倍
上面讲述了presto是什么,查询速度,现在来看看presto适合干什么
适合:PB级海量数据复杂分析,交互式SQL查询,支持跨数据源查询
不适合:多个大表的join操作,因为presto是基于内存的,多张大表在内存里可能放不下
presto是一个交互式查询引擎,可以在很短的时间内返回查询结果,秒级,分钟级,能访问很多数据源
Presto支持的数据源和存储格式:
Hadoop/Hive connector与存储格式:
HDFS,ORC,RCFILE,Parquet,SequenceFile,Text
开源数据存储系统:
MySQL & PostgreSQL,Cassandra,Kafka,Redis
其他:
MongoDB,ElasticSearch,HBase
系统组件:
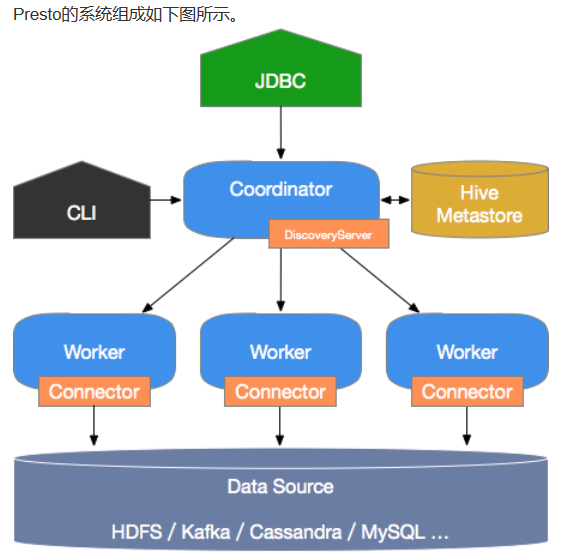
Presto是典型的M/S架构的系统,由一个Coordinator节点和多个Worker节点组成。 Coordinator负责如下工作:
1/ 接收用户查询请求,解析并生成执行计划,下发Worker节点执行。
2/ 监控Worker节点运行状态,各个Worker节点与Coordinator节点保持心跳连接,汇报节点状态。
3/ 维护MetaStore数据。
执行过程:
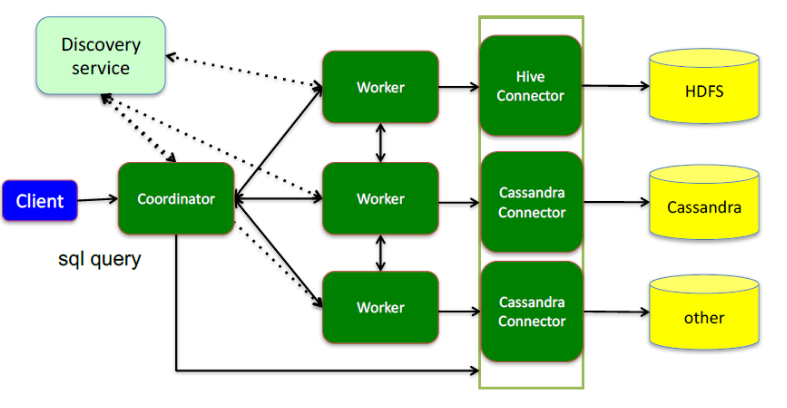
Coordinator,是一个中心的查询角色,它主要的一个作用是接受查询请求,将他们转换成各种各样的任务,将任务拆解后分发到多个worker去执行各种任务的节点
1、解析SQL语句
2、⽣成执⾏计划
3、分发执⾏任务给Worker节点执
Worker,是一个真正的计算的节点,执行任务的节点,它接收到task后,就会到对应的数据源里面,去把数据提取出来,提取方式是通过各种各样的connector:
1、负责实际执⾏查询任务
Discovery service,是将coordinator和woker结合到一起的服务:
2、Worker节点启动后向Discovery Server服务注册
3、Coordinator从Discovery Server获得Worker节点
coordinator和woker之间的关系是怎么维护的呢?是通过Discovery Server,所有的worker都把自己注册到Discovery Server上,Discovery Server是一个发现服务的service,Discovery Server发现服务之后,coordinator便知道在我的集群中有多少个worker能够给我工作,然后我分配工作到worker时便有了根据
最后,presto是通过connector plugin获取数据和元信息的,它不是数据存储引擎,不需要有数据,presto为其他数据存储系统提供了SQL能力,客户端协议是HTTP+JSON
数据模型
数据模型即数据的组织形式。Presto使用Catalog、Schema和Table,3层结构来管理数据。
Catalog
一个 Catalog 可以包含多个 Schema,物理上指向一个外部数据源,可以通过Connector访问该数据源。一次查询可以访问一个或多个 Catalog。
Schema
相当于一个数据库示例,一个Schema包含多张数据表。
Table
数据表,与一般意义上的数据库表相同。
使用:
presto --server emr-header-1:9090 --catalog hive --schema default --user hadoop
presto:default> show schemas;
presto --help 命令可以获取控制台的帮助
使用JDBC:
Java 应用可以使用 Presto 提供的 JDBC driver 连接数据库,使用方式与一般 RDBMS 数据库差别不大
在 Maven 中引入:
可以在 pom 文件中加入如下配置引入 Presto JDBC driver:
<dependency>
<groupId>com.facebook.presto</groupId>
<artifactId>presto-jdbc</artifactId>
<version>0.187</version>
</dependency>
Driver 类名
Presto JDBC driver 类为com.facebook.presto.jdbc.PrestoDriver
连接字串:
可以使用如下格式的连接字串:
jdbc:presto://<COORDINATOR>:<PORT>/[CATALOG]/[SCHEMA]
例如:
jdbc:presto://emr-header-1:9090 # 连接数据库,使用Catalog和Schema
jdbc:presto://emr-header-1:9090/hive # 连接数据库,使用Catalog(hive)和Schema
jdbc:presto://emr-header-1:9090/hive/default # 连接数据库,使用Catalog(hive)和Schema(default)
数据类型
常用sql命令:
https://help.aliyun.com/document_detail/109147.html?spm=a2c4g.11186623.6.842.74f673daQlAUtv


 浙公网安备 33010602011771号
浙公网安备 33010602011771号