Docker系列——InfluxDB+Grafana+Jmeter性能监控平台搭建(二)
在上一篇博文中,主要是讲了InfluxDB的配置,博文链接:https://www.cnblogs.com/hong-fithing/p/14453695.html,今天来分享下Jmeter的配置。
在介绍Jmeter之前,必须是要有Jmeter环境的,至于环境怎么配,工具怎么用,可以看以前的博文。环境搭建:Jmeter——环境搭建;Jmeter系列博文:Jmeter系列。所以这些就不多讲了,可以自行查看,今天以性能监控平台配置为主,介绍Jmeter运行脚本来采集对应数据。
Jmeter配置
添加监听器
在线程组中,添加监听器(Listener)-> Backend Listener,如下图所示:
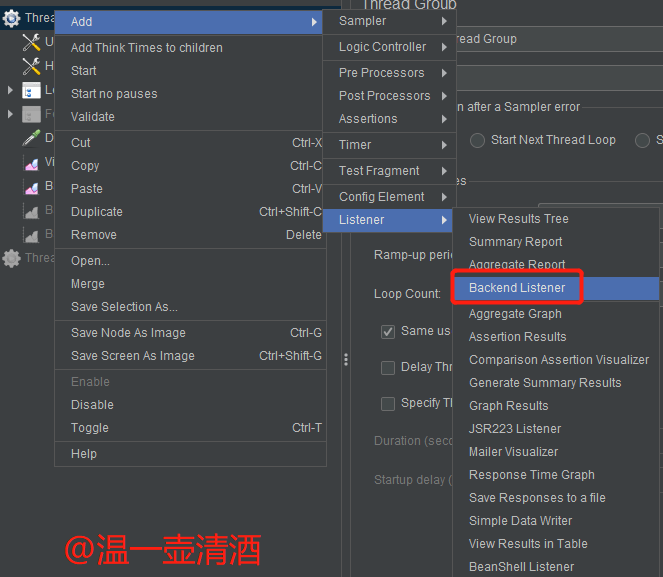
配置Backend Listener监听方式
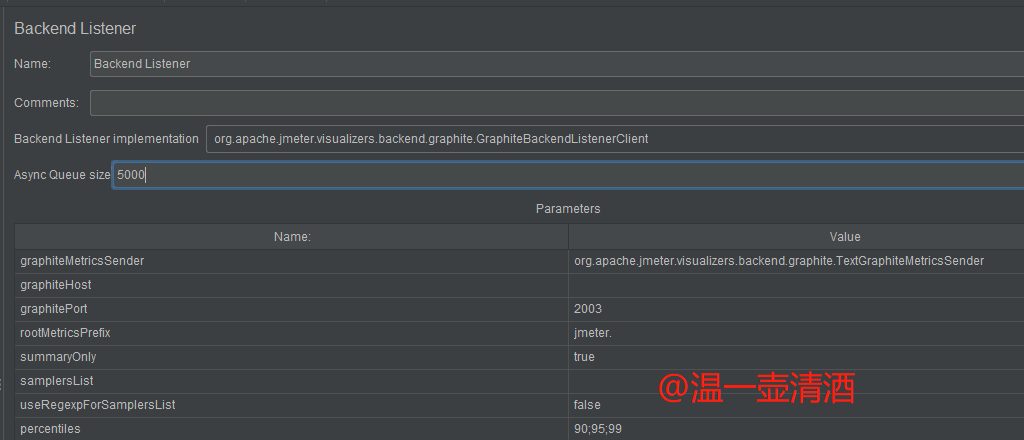
添加监听后,监听方式默认为GraphiteBackendListenerClient,如下图所示:
监听方式是可以修改的,监听器没扩展的情况下,共有2种,扩展后,支持四种方式,如下所示:
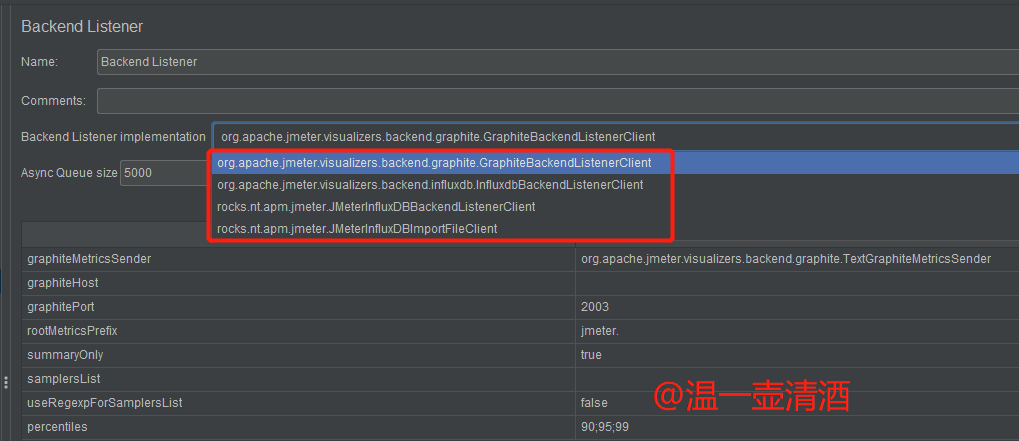
我已经扩展过了,所以展示4种,具体扩展方式,稍后再说。今天介绍主要以前三种监听方式为主,三种方式采集的数据,也有些许不同,我们详细来看。
GraphiteBackendListenerClient监听
界面配置
配置监听方式为GraphiteBackendListenerClient,不同的监听方式,配置面板上的配置字段也有不同之处,配置如下所示:
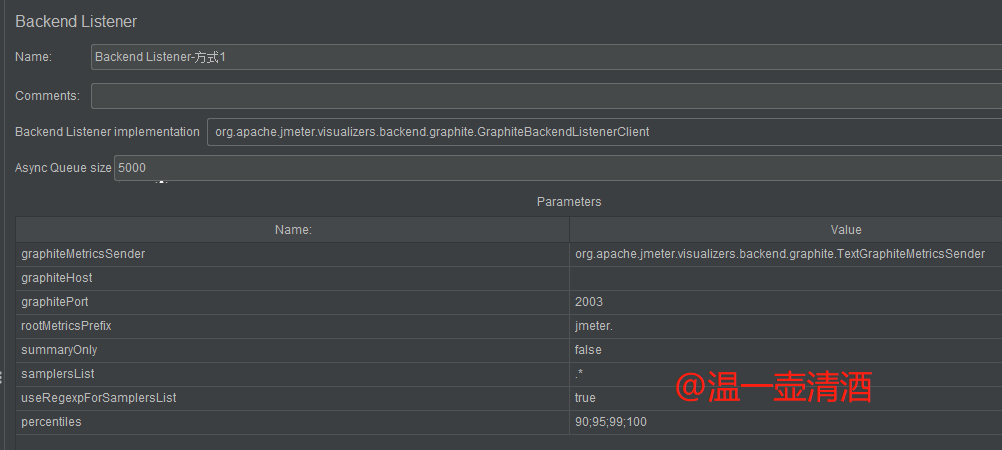
配置界面的详细字段如下:
graphiteHost:InfluxDB安装的服务器ipgraphitePort:端口;默认就是2003。ps:除非你自己安装InfluxDB时设置了其他端口。按自己的实际端口配置即可rootMetricsPrefix:指标的根前缀;将测试结果存入数据库时,不同指标会生成不同表summaryOnly:当你线程组有多个请求又想知道每个请求的结果数据时,最好填false,因为true只会返回所有请求的集合数据报告,不会输出每条请求的数据报告samplersList:取样器列表;想收集哪些请求就填哪些,最好用正则去匹配useRegexpForSamplersList:是否使用正则;如果true则使用,samplersList里可以匹配正则表达式percentiles:百分比;即类似聚合报告里90% Line,95% Line,99% Line的数据;倘若想要99.9时,需要写成【99_9】,用下划线代替点
运行脚本
运行脚本,运行没报错,便会产生数据了,可以通过服务器客户端查看,或者上篇博文中介绍的客户端工具查询。查询数据如下所示:
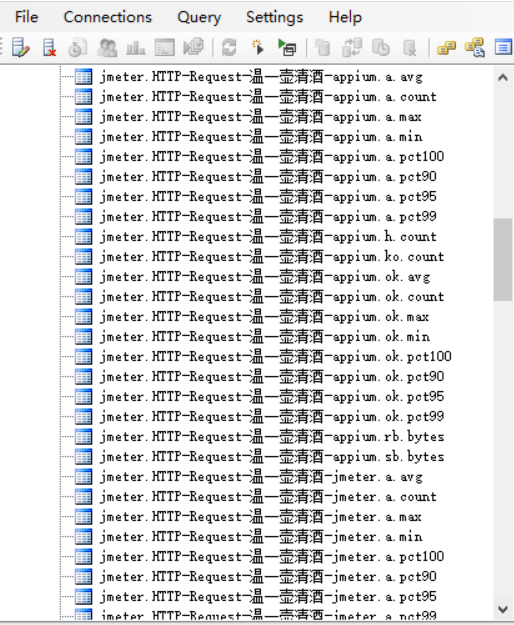
通过查询数据发现,总共会生成三种前缀的表,分别是:jmeter.请求名称、jmeter.all、jmeter.test。通过数据可以看到,请求数据都是整齐划一的以jmeter.开头,是因为我们刚才配置的时候,设置的是jmeter.;如果你配置成其他,那就会以自定义的前缀生成数据了。
- 前缀说明
jmeter.all :代表了所有请求;当summaryOnly=true时,就只有samplerName=all的表了
jmeter.请求名称 :如图所示,HTTP请求的名字是HTTP Request 温一壶清酒 appium
jmeter.test :线程组设置相关的指标数据
参数指标
参数指标说明,在jmeter官网有介绍,地址是:https://jmeter.apache.org/usermanual/realtime-results.html,可以查看原文档。我在这里就按中文来说明了。
线程/虚拟用户指标
Thread/Virtual Users metrics - 线程/虚拟用户指标
运行完脚本,生成的数据中,是有对应的5个指标数据的,如下所示:

| 指标 | 全称 | 含义 |
|---|---|---|
| <rootMetricsPrefix>test.minAT | Min active threads | 最小活跃线程数 |
| <rootMetricsPrefix>test.maxAT | Max active threads | 最大活跃线程数 |
| <rootMetricsPrefix>test.meanAT | Mean active threads | 平均活跃线程数 |
| <rootMetricsPrefix>test.startedT | Started threads | 启动线程数 |
| <rootMetricsPrefix>test.endedT | Finished threads | 结束线程数 |
响应时间指标
Response times metrics - 响应时间指标
每个sampler都包含了所有响应时间指标,每个sampler的每个指标都会有单独的一个表存储结果数据
| 指标 | 含义 |
|---|---|
| <rootMetricsPrefix><samplerName>.ok.count | sampler的成功响应数 |
| <rootMetricsPrefix><samplerName>.h.count | 服务器每秒命中次数(每秒点击数,即TPS) |
| <rootMetricsPrefix><samplerName>.ok.min | sampler响应成功的最短响应时间 |
| <rootMetricsPrefix><samplerName>.ok.max | sampler响应成功的最长响应时间 |
| <rootMetricsPrefix><samplerName>.ok.avg | sampler响应成功的平均响应时间 |
| <rootMetricsPrefix><samplerName>.ok.pct<percentileValue> | sampler响应成功的所占百分比 |
| <rootMetricsPrefix><samplerName>.ko.count | sampler的失败响应数 |
| <rootMetricsPrefix><samplerName>.ko.min | sampler响应失败的最短响应时间 |
| <rootMetricsPrefix><samplerName>.ko.max | sampler响应失败的最长响应时间 |
| <rootMetricsPrefix><samplerName>.ko.avg | sampler响应失败的平均响应时间 |
| <rootMetricsPrefix><samplerName>.ko.pct<percentileValue> | sampler响应失败的所占百分比 |
| <rootMetricsPrefix><samplerName>.a.count | sampler响应数(ok.count+ko.count) |
| <rootMetricsPrefix><samplerName>.sb.bytes | 已发送字节 |
| <rootMetricsPrefix><samplerName>.rb.bytes | 已接收字节 |
| <rootMetricsPrefix><samplerName>.a.min | sampler响应的最短响应时间 (ok.count和ko.count的最小值) |
| <rootMetricsPrefix><samplerName>.a.max | sampler响应的最长响应时间 (ok.count和ko.count的最大值) |
| <rootMetricsPrefix><samplerName>.a.avg | sampler响应的平均响应时间 (ok.count和ko.count的平均值) |
| <rootMetricsPrefix><samplerName>.a.pct<percentileValue> | sampler响应的百分比(根据成功和失败的总数来计算) |
InfluxDBBackendListenerClient监听
界面配置
配置方式一样,只是选择不同的监听方式而已,直接上图,配置也如下图所示:
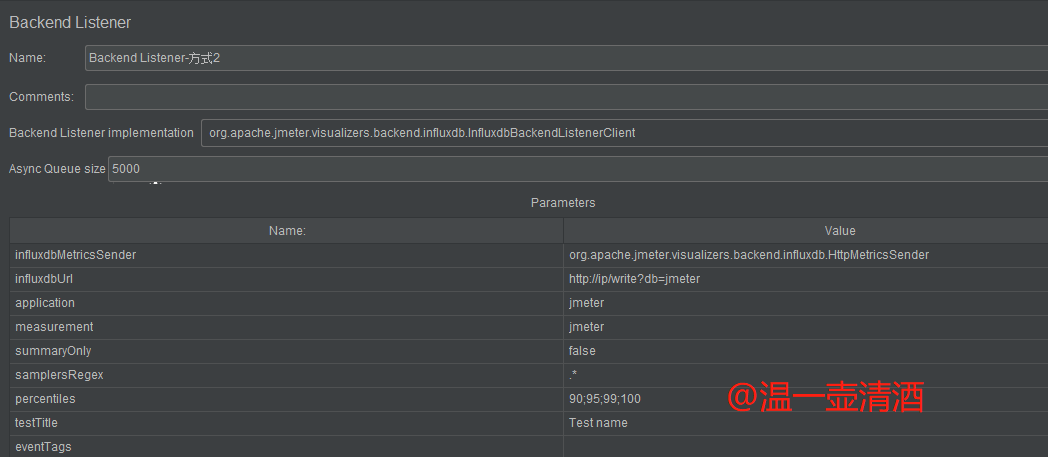
每个配置项的含义如下:
influxdbUrl:安装influxdb的路径;主要格式:http://主机地址:8086/write?db=数据库名application:应用名称;在 events 表中对应的字段是 applicationmeasurement:表名;数据存储到哪个表,默认是jmeter,不用改即可summaryOnly:当你线程组有多个请求又想知道每个请求的结果数据时,最好填false,因为true只会返回所有请求的集合数据报告,不会输出每条请求的数据报告samplersRegex:取样器列表;想收集哪些请求就填哪些,最好用正则去匹配percentiles:百分比;即类似聚合报告里90% Line,95% Line,99% Line的数据;倘若想要99.9时,需要写成【99_9】,用下划线代替点testTitle:测试名称;在 events 表中对应的字段是 text ,JMeter在测试的开始和结束时自动生成注释,该注释的值以'started'和'ended'结尾eventTags:Grafana允许为每个注释显示标签;在 events 表中对应的字段是 tags
运行脚本
我们还是用客户端工具查看,这次只生成了2张表,分别是:events 和 jmeter。如下所示:
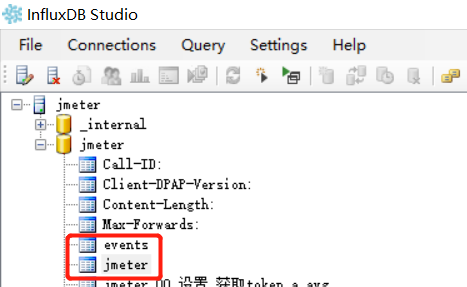
表作用
events表:用于存储事件的
jmeter表:存储测试结果数据,Grafana也是从这个表获取数据再展示
在讲配置项含义解释时,application和testTitle对应数据表中对应的字段,我们查询events表数据,如下所示:
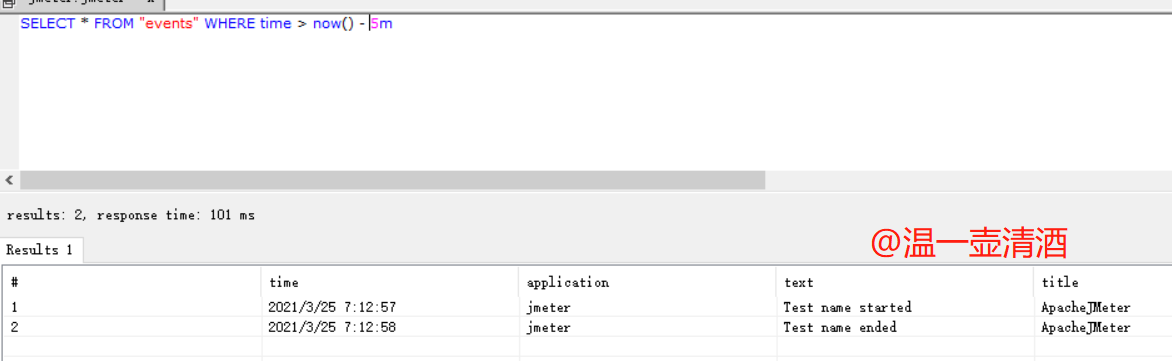
application默认为jmeter;testTitle对应的是text,落的数据值为Test name started/Test name ended,Test name就是我们在界面配置的名称;time字段的时间差,就是脚本的运行时间了。
jmeter面板中也看出的确只运行了1s,如下所示:
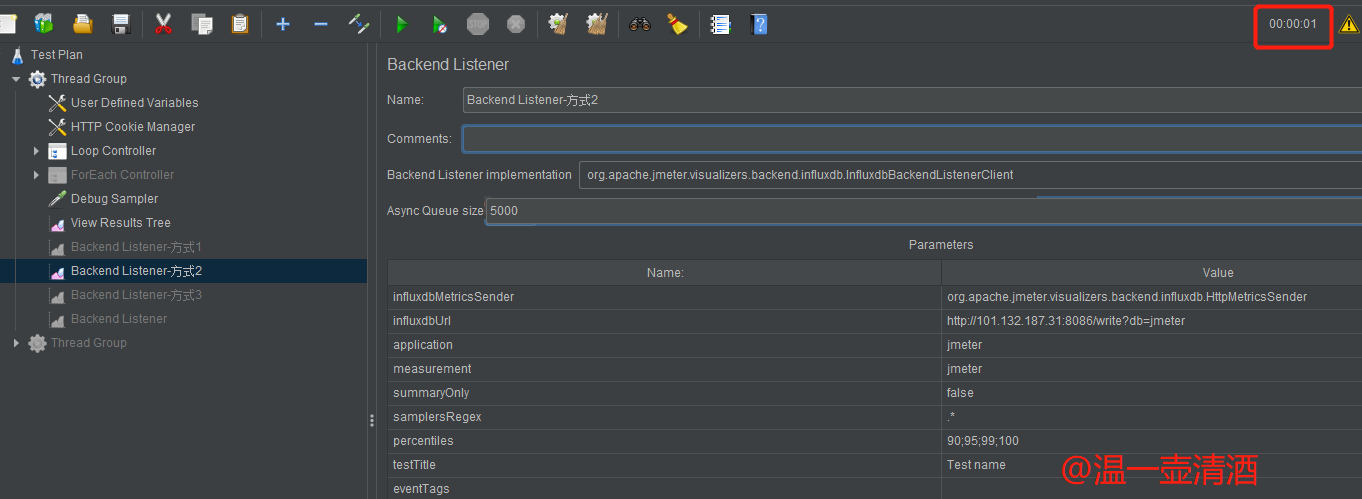
JmeterInfluxDBBackendListenerClient监听
这种方式是在查询Grafana监控模板时找到的,这次博文先不讲Grafana的监控指标的配置,先把脚本监听方式讲完。
Grafana官网介绍如下:
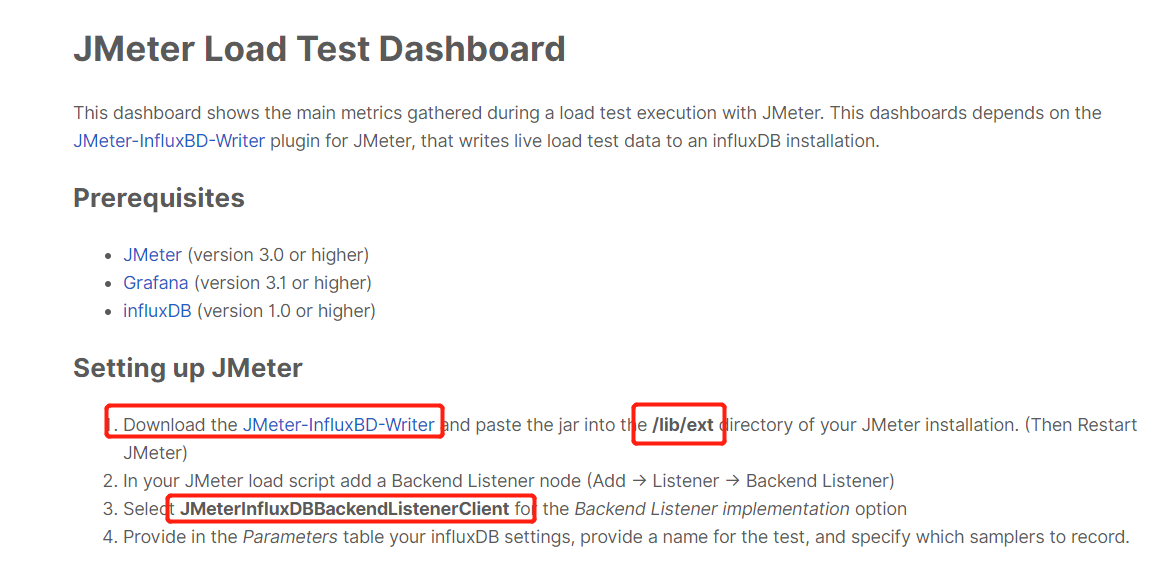
插件引用
下载插件
插件下载地址,下载对应的jar包即可。
jmeter配置
将下载的插件放到Jmeter的/lib/ext目录下,如果jmeter是启用的,则需要重新启动下才能生效;jmeter没启用的情况下,则不需要。
界面配置
配置方式一样,只是选择不同的监听方式而已,引入插件后,就多了两种监听方式,我们选择JmeterInfluxDBBackendListenerClient,配置如下图所示:
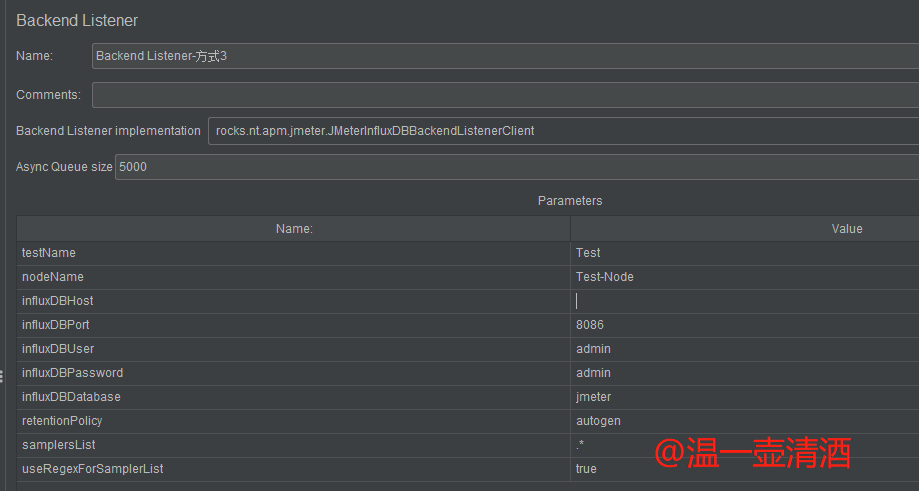
每个配置项的含义如下:
testName:测试名称;在 testStartEnd 表中对应的字段是 testNamenodeName:节点名称;在 testStartEnd 表中对应的字段是 nodeNameinfluxDBHost:InfluxDB安装的服务器ipinfluxDBPort:端口;influxDB端口,默认是8086,不用改即可influxDBUser:数据库用户名influxDBPassword:数据库密码influxDBDatabase:数据库名称,我们之前配置的数据库是jmeter,所以填入即可retentionPolicy:默认即可samplersList:取样器列表;想收集哪些请求就填哪些,最好用正则去匹配useRegexForSamplerList:是否使用正则;如果true则使用,samplersList里可以匹配正则表达式
运行脚本
按自己所需配置完成后,运行脚本,我们通过客户端查看数据,生成如下三张表:
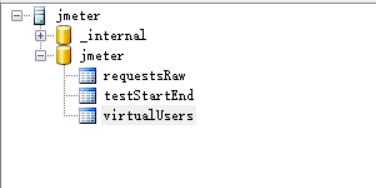
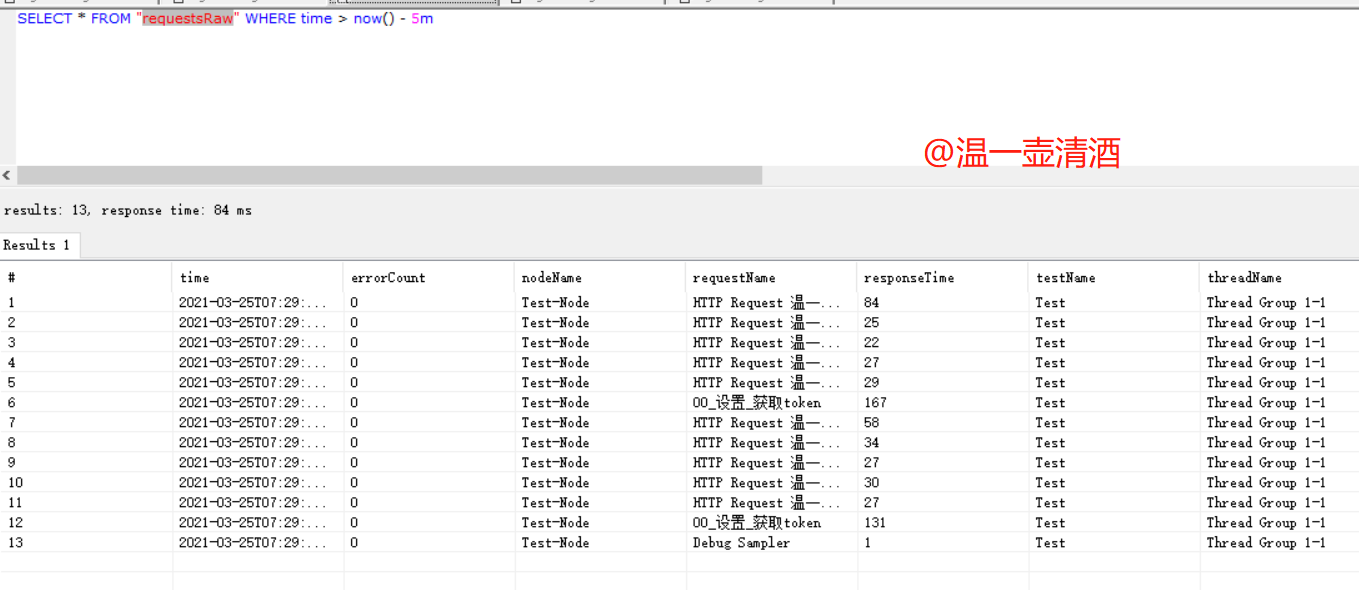
requestsRaw表
主要是存储请求信息数据,包含:请求时间,请求名称,线程名称等信息。如下所示:
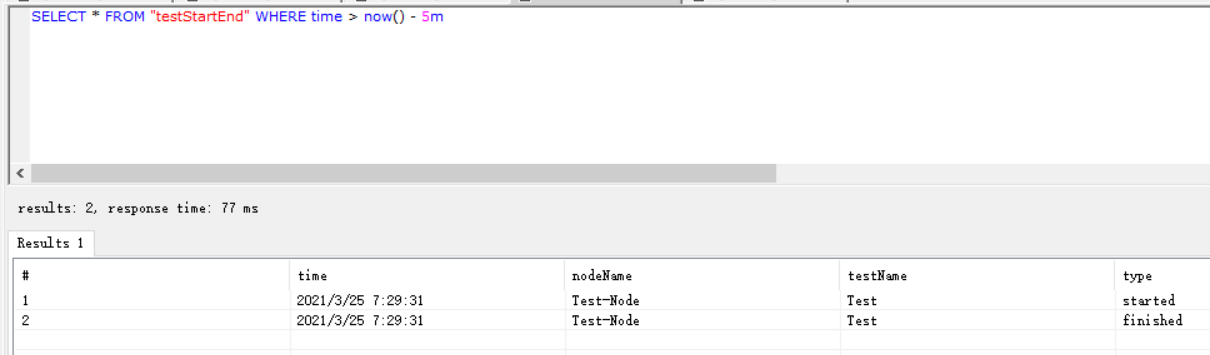
testStartEnd表
主要是用于存储事件信息,如下所示:
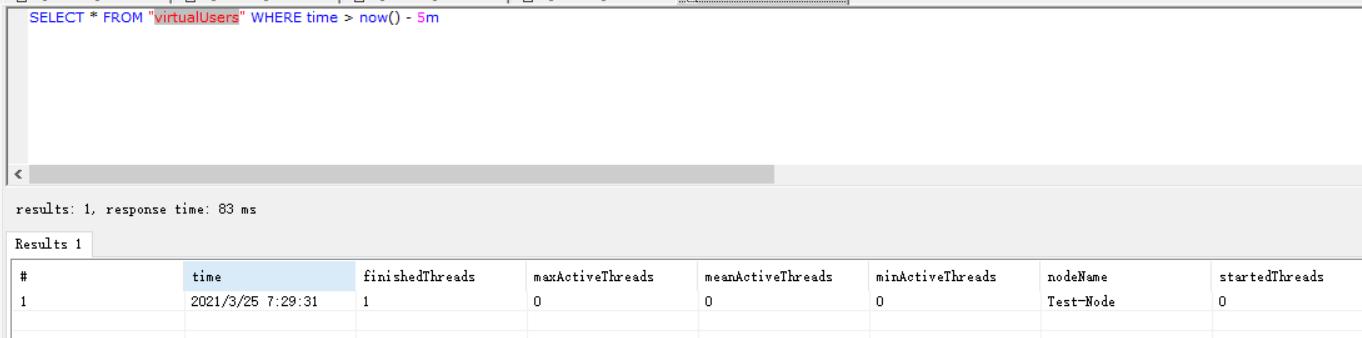
virtualUsers表
存储线程相关信息,如下所示:
脚本生成数据的方式,就介绍到这了,离最终效果图只差一步了哟。今天介绍了三种方式,配置Grafana监控面板时,也对应有三种模板,下期再来细说。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号