sklearn
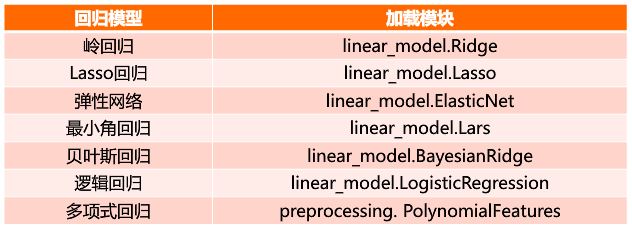
分类任务、回归任务、聚类任务、降维任务、模型选择、数据预处理

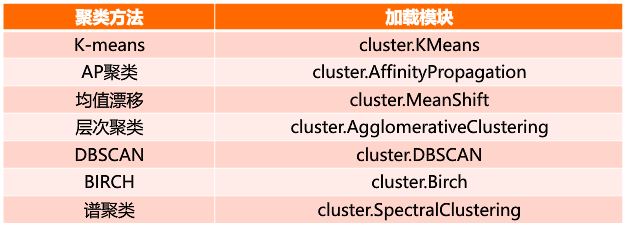
from sklearn.cluster import KMeans
import numpy as np
def loadData(filePath):
fr = open(filePath,'r+',encoding='UTF-8')
lines = fr.readlines()
retData = []
retCityName = []
for line in lines:
items = line.strip().split(',')
retCityName.append(items[0])
retData.append([float(items[i]) for i in range(1,len(items))])
#print(retData)
#print(retCityName)
return retData,retCityName
if __name__=='__main__':
data,cityName = loadData('city.txt')
km = KMeans(n_clusters=4)
label = km.fit_predict(data)
#print(label) # data中每一条的类别
#print(km.cluster_centers_) # 聚类中心
expenses = np.sum(km.cluster_centers_,axis=1)
CityCluster=[[],[],[],[]]
for i in range(len(cityName)):
CityCluster[label[i]].append(cityName[i])
for i in range(len(CityCluster)):
print('Expenses:%.2f' % expenses[i])
print(CityCluster[i])


 浙公网安备 33010602011771号
浙公网安备 33010602011771号