
python实验报告四
20233309 2025-3-26 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 2333
姓名: 侯成子
学号:20233309
实验教师:王志强
实验日期:2025年5月14日
必修/选修: 公选课
前言:
Python这门计算机语言的用途非常广泛,我的专业是通信工程,但专业学习中也与Python息息相关。例如在参加了去年的北京市电子设计竞赛,这一与电通系的专业学习关系紧密的比赛的过程中,用到了openmv,K210等模块,这些模块都是Python语言进行编程的。因此,在参加本次课程前,我就已经对于编写一定难度的Python程序以及Python的用处有了一定程度的了解。在去年参加比赛的时候,我们选择的题目中有一个要求,是判断音频信号的种类,题目要求我们能区分出人声和音乐。当时我们的解决方案是使用了K210模块,最终在我们3人小组的合作下用Python写出了程序,利用了K210硬件I2S接口读取麦克风数据,用了类似于机器学习训练的方法对声音数据进行了一系列的采集与处理后判断出声音是人声还是音乐。在本次实验中,我修改了这个程序,从原来的通过麦克风采集数据改成直接读取电脑上的wav音频文件,判断是人声还是音乐的同时输出频谱图。

1.实验分析与设计
在本次实验中区分人声与音乐主要基于两者在频谱能量分布、谐波结构和时域特性上存在差异:人声的声学特征集中于低频段(80-500Hz),其能量分布呈现以基频和少量共振峰为核心的稀疏谐波结构,且具有短时平稳性,表现为低频能量显著高于高频;而音乐(尤其是器乐)的频谱覆盖全频段(20Hz-20kHz),包含密集的泛音成分和高频谐波能量,时域上表现为持续稳定的振动模式。基于心理声学临界频带理论,通过量化低频区(0-500Hz)与高频区(500-4000Hz)的加权能量比值,结合动态阈值判定(人声典型能量比R较高,音乐R较低),可有效区分二者——人声因基频能量集中导致比值显著偏高,音乐则因泛音丰富使高频能量占比提升而比值偏低。该方法在代码中通过FFT频谱分析提取频域特征,利用能量比公式融合人耳听觉感知特性,实现了对声源类别的物理特征建模,到最后实现区分。
为实现功能,程序通过对音频信号进行分帧FFT变换,计算平均频谱能量分布,并基于人声与音乐在不同频段的能量差异实现分类:使用0-6号频段(低频,1.5倍加权)代表人声特征,7-49号频段(高频,分两段2.2/1.0倍加权)表征音乐特征,最终通过计算低频加权和与高频加权和的比值(6倍放大),以经验阈值4.8和3.5作为分界,判断音频类型为人声、音乐或不确定(参数需要根据情况调整)。
2.实验过程及结果
(1)实验代码:
import numpy as np import librosa import matplotlib matplotlib.use('TkAgg') import matplotlib.pyplot as plt def analyze_audio(file_path): sample_rate = 38640 # 采样率 sample_points = 1024 # 采样点数 fft_points = 512 # FFT点数 hist_x_num = 80 # 频谱分段数 target_Training_rounds = 150 # 训练轮数 Separate_num = 5 # 高低频分界点 # 加载音频并重采样 y, sr = librosa.load(file_path, sr=sample_rate) # 分割为多个采样段(模拟实时采样) total_frames = len(y) // sample_points valid_frames = min(total_frames, target_Training_rounds) y = y[:valid_frames * sample_points] # 初始化能量累计数组 fft_amp_Ave = np.zeros(hist_x_num) # 采样 for i in range(valid_frames): audio_segment = y[i * sample_points: (i + 1) * sample_points] # 执行FFT(保持原代码处理方式) fft_res = np.fft.rfft(audio_segment, n=fft_points) fft_amp = np.abs(fft_res)[:hist_x_num] * 2 / fft_points # 振幅计算 # 累计频谱 fft_amp_Ave += fft_amp # 计算平均频谱 fft_amp_Ave = fft_amp_Ave / valid_frames # 计算高低频能量 Low_F = 0 High_F = 0 for i in range(hist_x_num): if i < 12: #低频 Low_F += fft_amp_Ave[i] * 1.8 elif 12 <= i <= 36: High_F += 2.5 * fft_amp_Ave[i] elif 36 < i < 50: High_F += fft_amp_Ave[i] * 1.0 # 计算能量比 Low_High_Rate = 5.2 * Low_F / (High_F + 1e-9) # 防止除以零 if Low_High_Rate > 6.0: result = "人声" elif Low_High_Rate < 5.5: result = "音乐" else: result = "无法判断" return result, Low_High_Rate, Low_F, High_F, fft_amp_Ave def plot_spectrum(fft_amp_Ave): # 绘制频谱直方图 plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体 plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题 plt.figure(figsize=(12, 4)) plt.bar(range(len(fft_amp_Ave)), fft_amp_Ave, width=0.8) plt.title('平均频谱分析') plt.xlabel('频段') plt.ylabel('振幅') plt.axvline(x=5.5, color='r', linestyle='--', label='低频分界') plt.axvline(x=15.5, color='g', linestyle='--', label='高频分界') plt.legend() plt.axvspan(0, 5.5, alpha=0.2, color='blue', label='人声特征区') plt.axvspan(6, 25, alpha=0.2, color='red', label='音乐主特征区') plt.axvspan(26, 59, alpha=0.2, color='orange', label='音乐次特征区') plt.legend() plt.show() if __name__ == "__main__": import sys if len(sys.argv) != 2: print("用法: python audio_judge.py <音频文件路径>") sys.exit(1) file_path = sys.argv[1] # 执行分析 result, ratio, low, high, fft_data = analyze_audio(file_path) # 输出结果 print("\n=== 音频分析报告 ===") print(f"文件路径: {file_path}") print(f"低频能量: {low:.2f}") print(f"高频能量: {high:.2f}") print(f"能量比率: {ratio:.2f}") print(f"判断结果: {result}") # 显示频谱图 plot_spectrum(fft_data)
(2)代码解释:
①代码的开头是模块的导入与初始化
numpy: 用于数值计算,尤其是FFT和数组操作。
librosa: 音频处理库,用于加载音频文件和重采样。
matplotlib: 绘图库,用于生成频谱图。
②主分析函数analyze_audio
a.参数设置
sample_rate = 38640 # 重采样后的采样率 sample_points = 1024 # 每段音频的采样点数 fft_points = 512 # FFT计算点数 hist_x_num = 80 # 频谱分段数(保留前80个频段) target_Training_rounds = 150 # 最大处理帧数 Separate_num = 5
先设置了采样率38640,每段音频的采样点数为1024,对每段音频进行512点FFT,输出257个频点,但仅保留前80个。
b.加载音频与重采样
y, sr = librosa.load(file_path, sr=sample_rate)
加载音频文件,强制重采样到 38640 Hz。
c.音频分段
total_frames = len(y) // sample_points valid_frames = min(total_frames, target_Training_rounds) y = y[:valid_frames * sample_points]
将音频切分为1024点的片段,最多处理150段。
d.FFT与频谱计算
for i in range(valid_frames):
audio_segment = y[i*sample_points : (i+1)*sample_points]
fft_res = np.fft.rfft(audio_segment, n=fft_points)
fft_amp = np.abs(fft_res)[:hist_x_num] * 2 / fft_points
fft_amp_Ave += fft_amp
FFT计算: 对每段音频进行实数FFT,得到幅度谱。
幅度归一化: 2/fft_points 用于归一化振幅。
累计平均:对所有段的频谱求平均,减少噪声影响。
e.高低频能量计算
Low_F = sum(fft_amp_Ave[0:12] * 1.8) # 低频(0-12频段)
High_F = sum(fft_amp_Ave[12:37] * 2.5) + \
sum(fft_amp_Ave[37:50] * 1.0) # 高频(12-50频段)
低频加强: 前12频段乘以权重1.8,增强人声(通常集中在低频)。
高频分段处理: 12-36频段权重2.5,37-50频段权重1.0,强调音乐高频特征。
f. 分类逻辑
Low_High_Rate = 5.2 * Low_F / (High_F + 1e-9)
if Low_High_Rate > 6.0:
result = "人声"
elif Low_High_Rate < 5.5:
result = "音乐"
else:
result = "无法判断"
能量比公式 5.2 × 低频能量 / 高频能量,阈值经验值6.0和5.5。(这些参数是根据测算许多音乐文件和人声音乐调整出来的参数)
人声判断: 低频占比高(人声集中在低频)。
音乐判断: 高频占比高(音乐高频更丰富)。
g.绘图函数plot_spectrum
plt.bar(...) plt.axvline(x=5.5, ...) # 低频分界 plt.axvline(x=15.5, ...) # 高频分界 plt.axvspan(0-5.5, ...) # 人声特征区 plt.axvspan(6-25, ...) # 音乐主特征区
可视化频谱分布,标注人声和音乐的特征频段。
h.主程序逻辑
if __name__ == "__main__":
# 命令行参数处理
result, ratio, low, high, fft_data = analyze_audio(file_path)
# 输出结果与绘图
接受音频文件路径,输出分析报告并显示频谱图。
(3)实验过程
①在对应文件夹打开终端,如图3所示。文件夹中已准备两个人声文件和两个音乐文件,如图4所示。
②输入指令,指令需包含Python程序文件的全称以及需要检测的音频文件的全称。
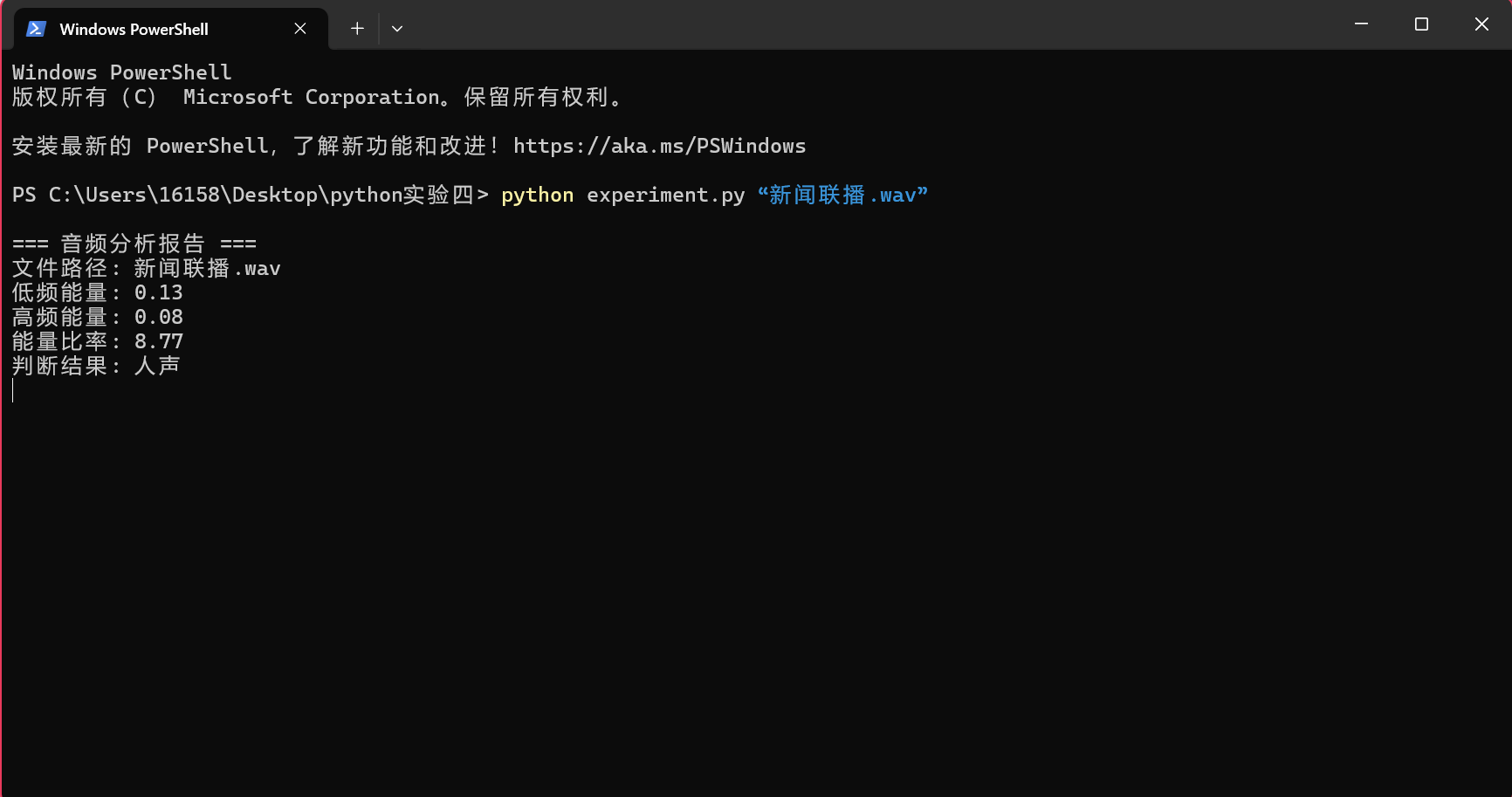
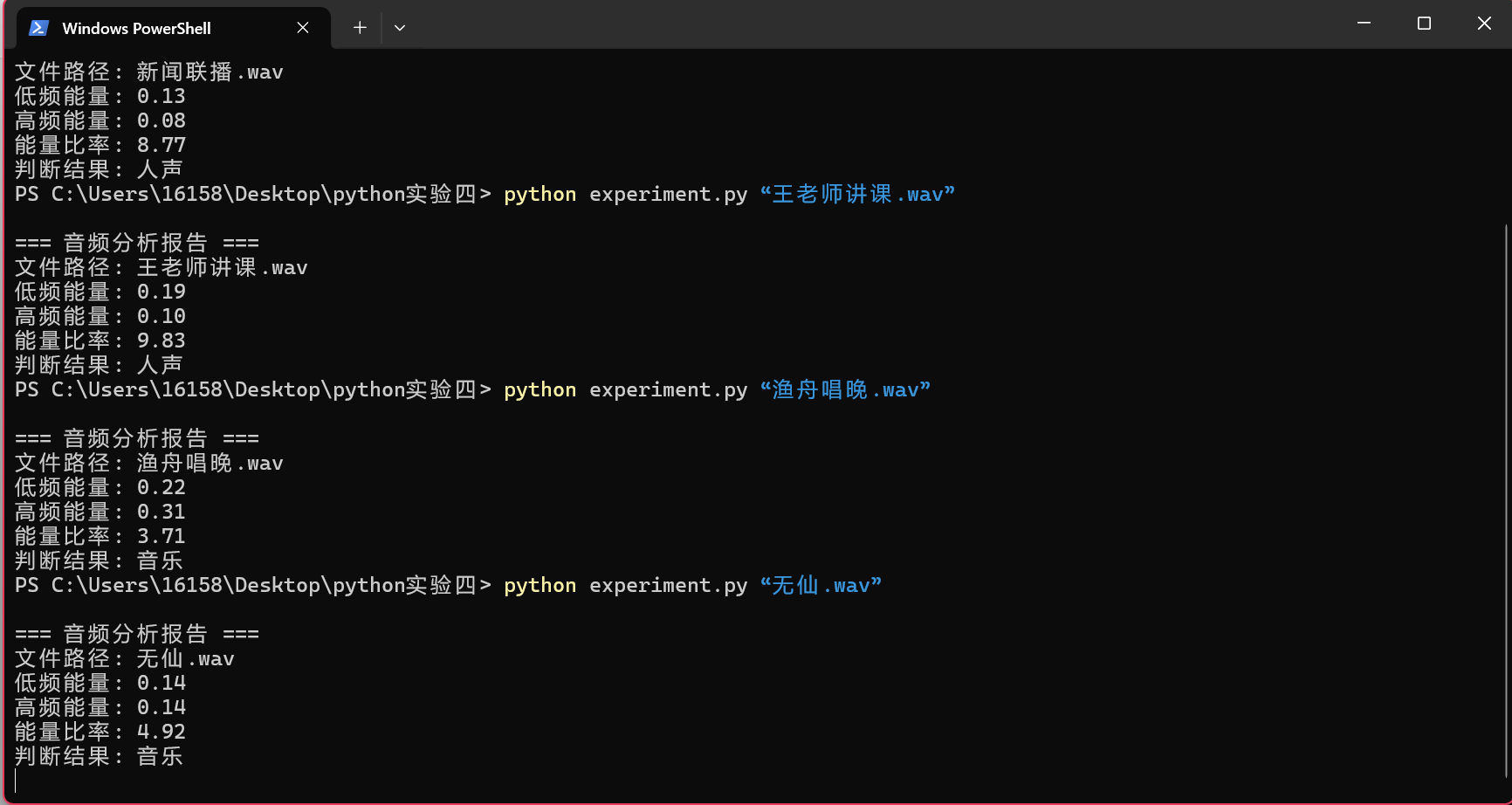
a.输入指令python experiment.py “新闻联播.wav”,检测结果如图5,图6所示。可以看到,检测结果为人声。
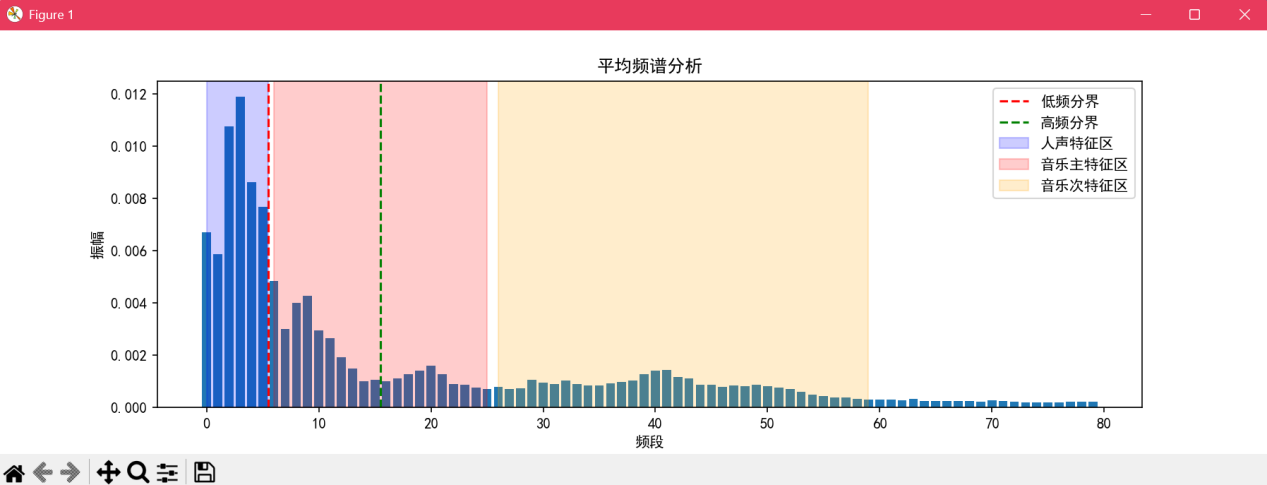
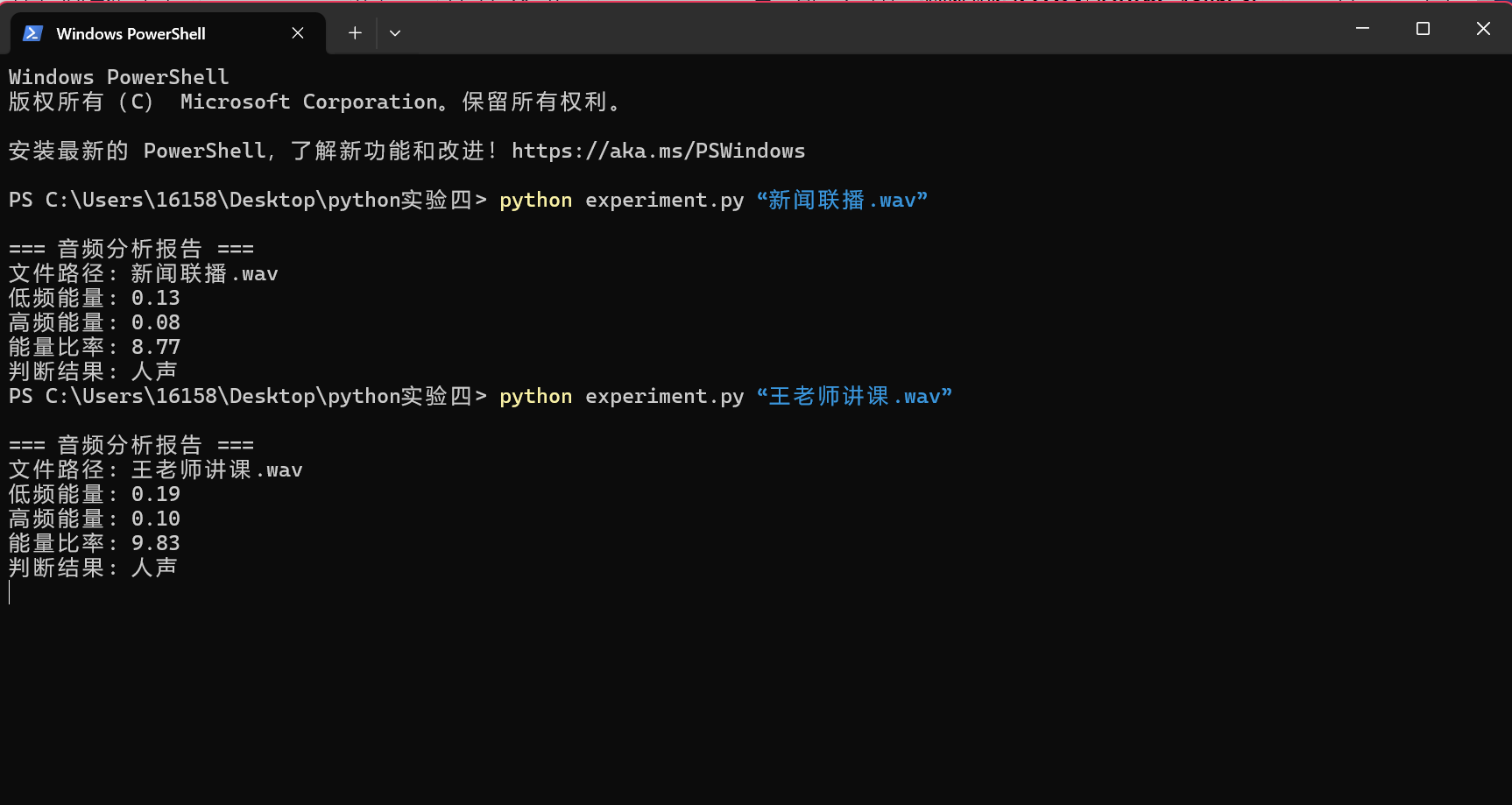
b.输入指令python experiment.py “王老师讲课.wav”(这个文件是王老师在上计网课时偷偷录的音,应该没有侵权吧...),检测结果如图7,图8所示。可以看到,检测结果为人声。
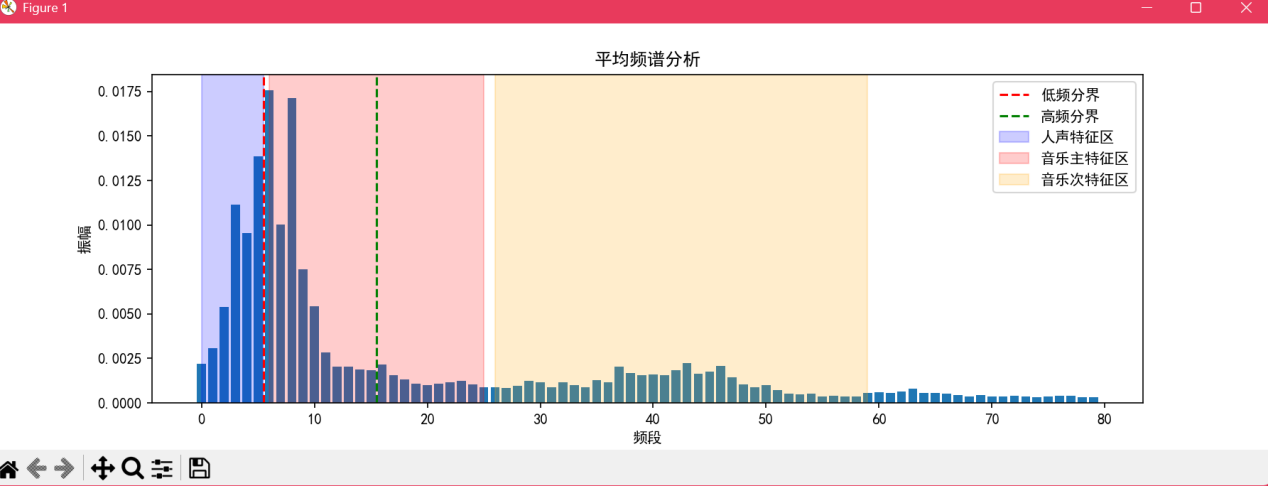
c.输入指令python experiment.py “渔舟唱晚.wav”,检测结果如图9,图10所示。可以看到,检测结果为音乐。
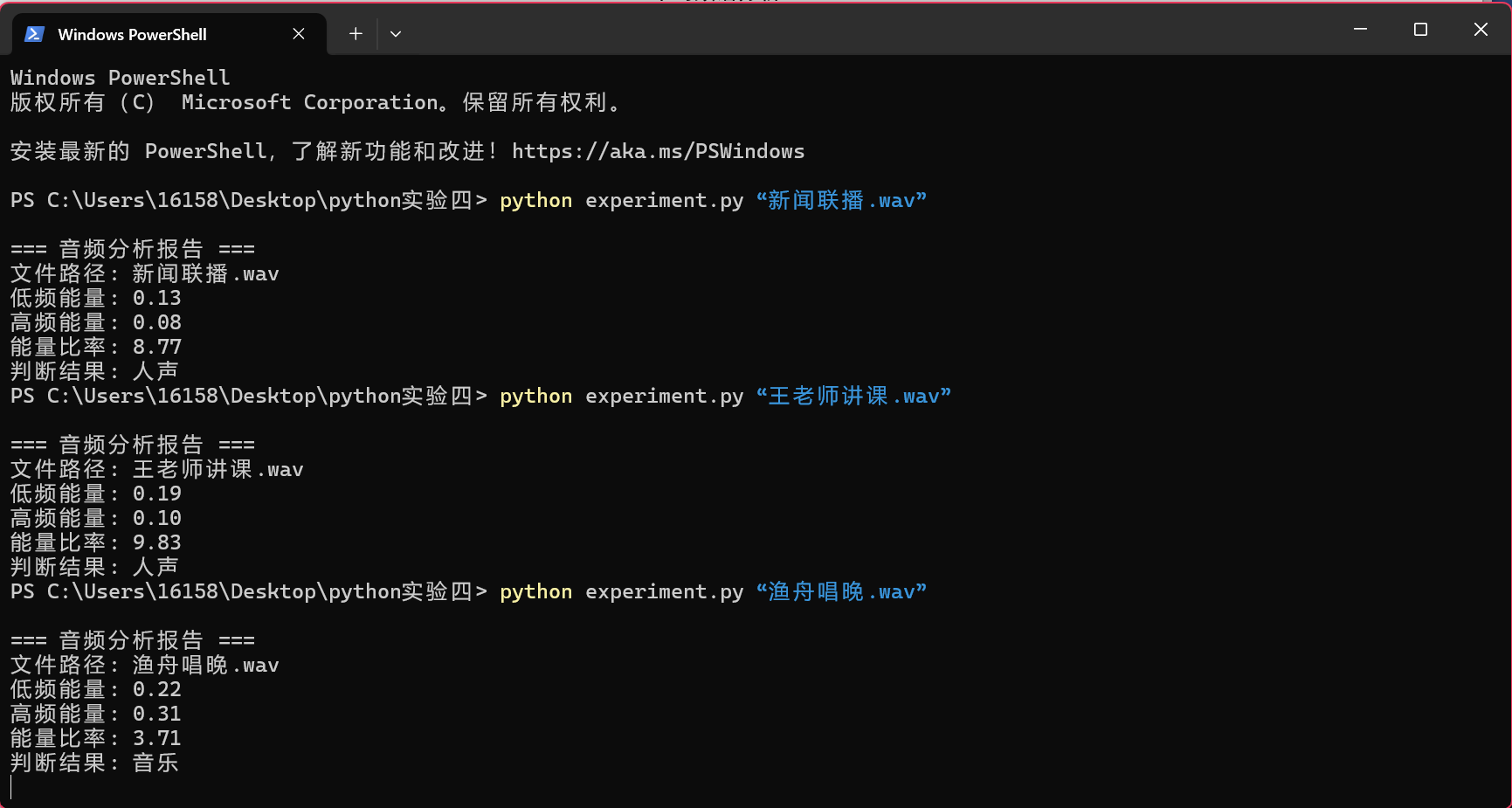
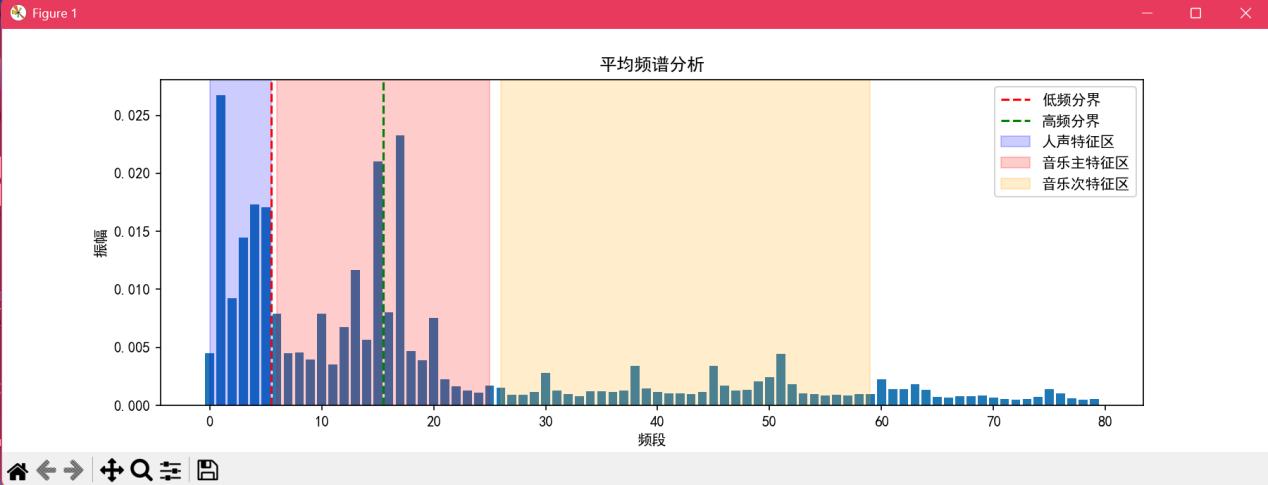
d.输入指令python experiment.py “无仙.wav”,检测结果如图10,图11所示。可以看到,检测结果为音乐。
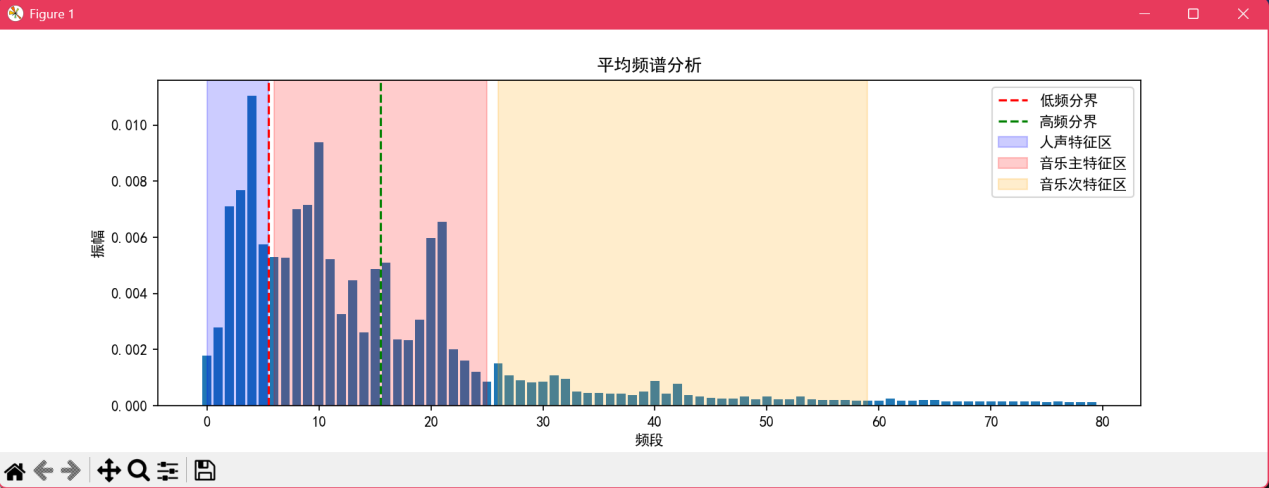
③可以看到检测结果均正确,因此该程序基本可以识别出人声和音乐。
④将该代码上传到gitee上,步骤如下图13,图14,图15所示。
4.实验过程中遇到的问题和解决过程
这个代码的原版是通过传感器识别声音,因此数据会受到环境噪声等因素的影响,参数需要根据环境来调整。但我修改后识别电脑本机的音乐,参数无需太大改变,基本能识别出人声和音乐。
本次实验自我感觉良好,融入了自己专业的知识,与Python相关联在一起,实现了一个在没接触前看起来比较困难的问题。
5.课程感想体会
Python是一个很重要的语言,用途非常广泛。但是仅仅通过一门选修课可能只能窥见Python大帝的冰山一角。因此,对于python的学习更多还会是在使用它的过程中来自学。在课程中,我们大致地学习了Python的基本语法,同时socket等的一些使用也在另外的课程中(例如计算机网络)用到,c语言,python,专业课知识等知识逐渐产生关联,知识体系逐渐建立起来了。王老师上的课一直都很有趣也很轻松,不需要像别的课程一样绞尽脑汁的想办法卷高分数(个人感觉大学的课程就该这样子,应该在于学知识而不是卷分数),很有梗也很有节目,在讲授知识的时候也会让我们欢笑不断。因此很喜欢王老师的课。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号