一次系统延迟性优化案例
一次系统延迟性优化案例
延迟的本质
本质是cpu没有及时的运行程序代码。
进程内部
网络io,磁盘io,cpu调度 达到瓶颈
第三方系统
调用的第三方系统慢,mysql,redis等基础组件调度慢, 第三方应用系统调用慢
问题背景
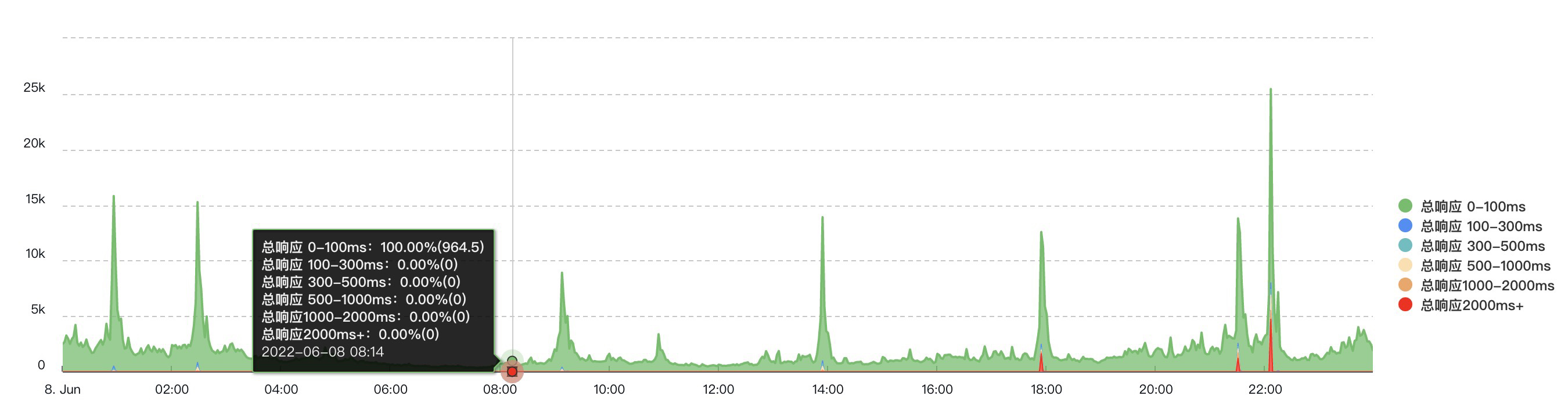
线上隔三差五晚上10点左右总会有sql报警出现,且是同样的sql,我们的sql报警是在应用程序内部通过对sql操作增加钩子函数,对sql前后执行的位置进行计时,然后sql执行完毕后,对时间进行判断,大于1s则报警。
晚上10点正好是我们的业务高峰。部分接口也会在此期间出现超过2s的响应。
探索过程
排查sql慢查询
通过后台的慢查询日志,没有发现这条慢sql打印出来,且重新执行该sql,执行时间仍然在毫秒内完成,排除掉sql写法本身带来的性能问题。
排查系统各项指标
查看系统cpu,网络带宽Mbps,磁盘iops,Bps,均未到达瓶颈,仅在高峰期有波峰。

系统是4核系统,唯一达到瓶颈的也就是系统负载达到了5。说明有进程或线程在等待执行。
为什么系统各个硬件指标都不是很高,程序反而慢了呢,cpu为什么没有干更多活来执行更多的指令呢。
考虑程序在执行一个cpu使用率不高的动作,但是这个动作却不是在执行用户代码
一般通过go tool pprof 查看cpu的使用率是查看hot-cpu,也就是cpu真正执行的时间,但是如果要看等待cpu的时间得看off-cpu,go提供了这样的工具(github.com/felixge/fgprof)

可以看到一个方法在执行时由于查询了数据库,cpu在withLock 和等待数据库返回数据库时耗费了很多等待时间。但是这里只能看出这部分代码等待cpu的时间占所有等待时间的大部分,无法确定程序真正等待的时间。
用go trace分析系统延迟
基于上面分析,为更进一步确定是数据库查询带来的耗时, 采用更加精确化的工具 go trace分析程序运行时的动作。go trace 是golang提供的官方工具。
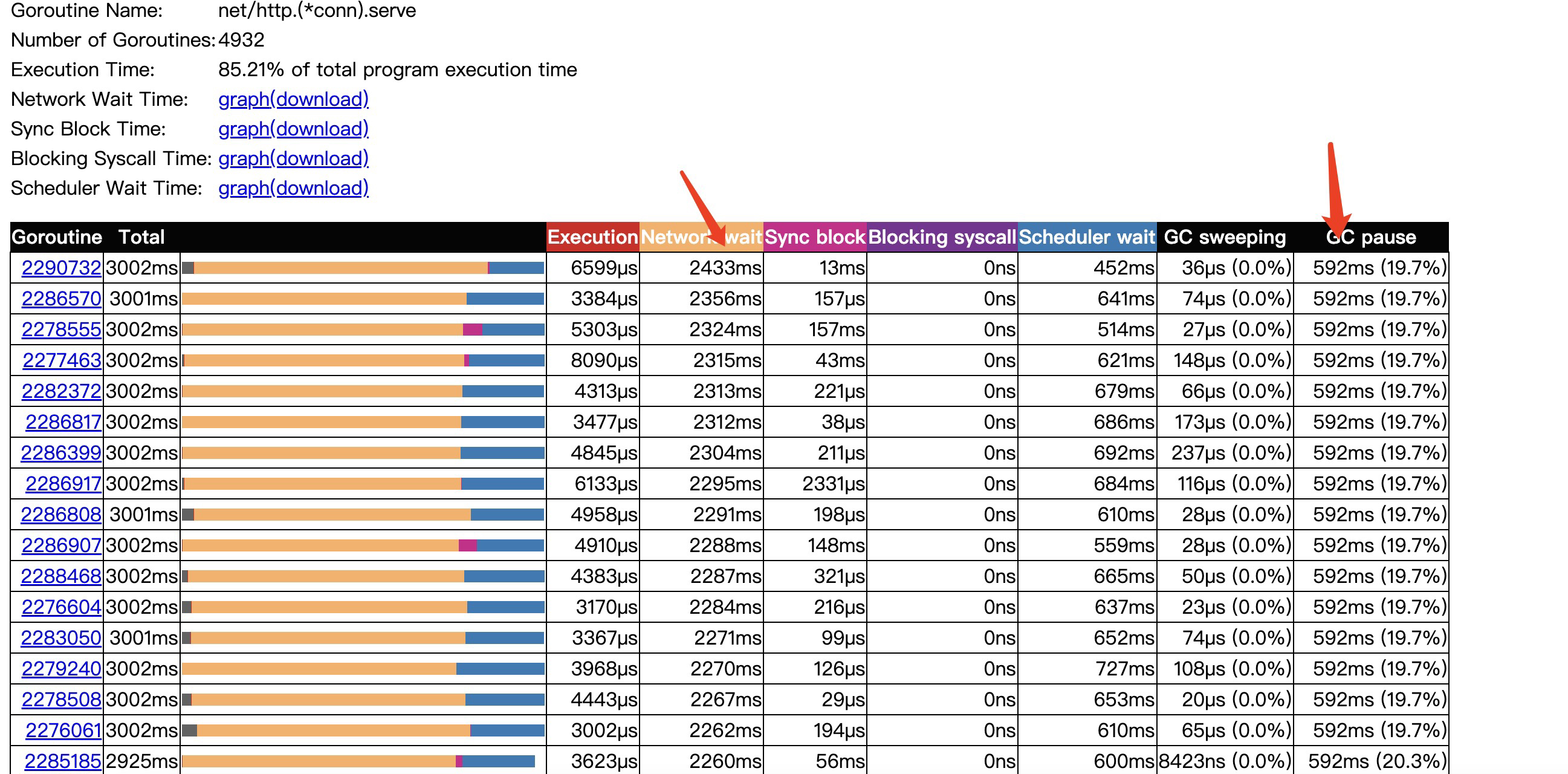
进行了3s的采样,其中网络io等待时间就占了2秒多,我的理解程序会在网络io系统调用开始时记录下此时协程的时间,并将协程从p队列拿下来,然后异步等到epoll回调通知,等到文件描述符可读后,将协程重新加入到p队列,重新执行调度。这里的Network wait就是从p队列拿下来到加入到p队列的时间间隔,然后真正执行是要等待Scheduler wait 调度等待时间才会被调度。
这里协程的网络等待时间长,但是不能完全说明是导致系统延迟的原因,因为在keepAlive开始时,一个协程是有可能处理多个网络请求的,所以有可能是多次请求间,读等待时间较长导致。所以继续看下其他指标。
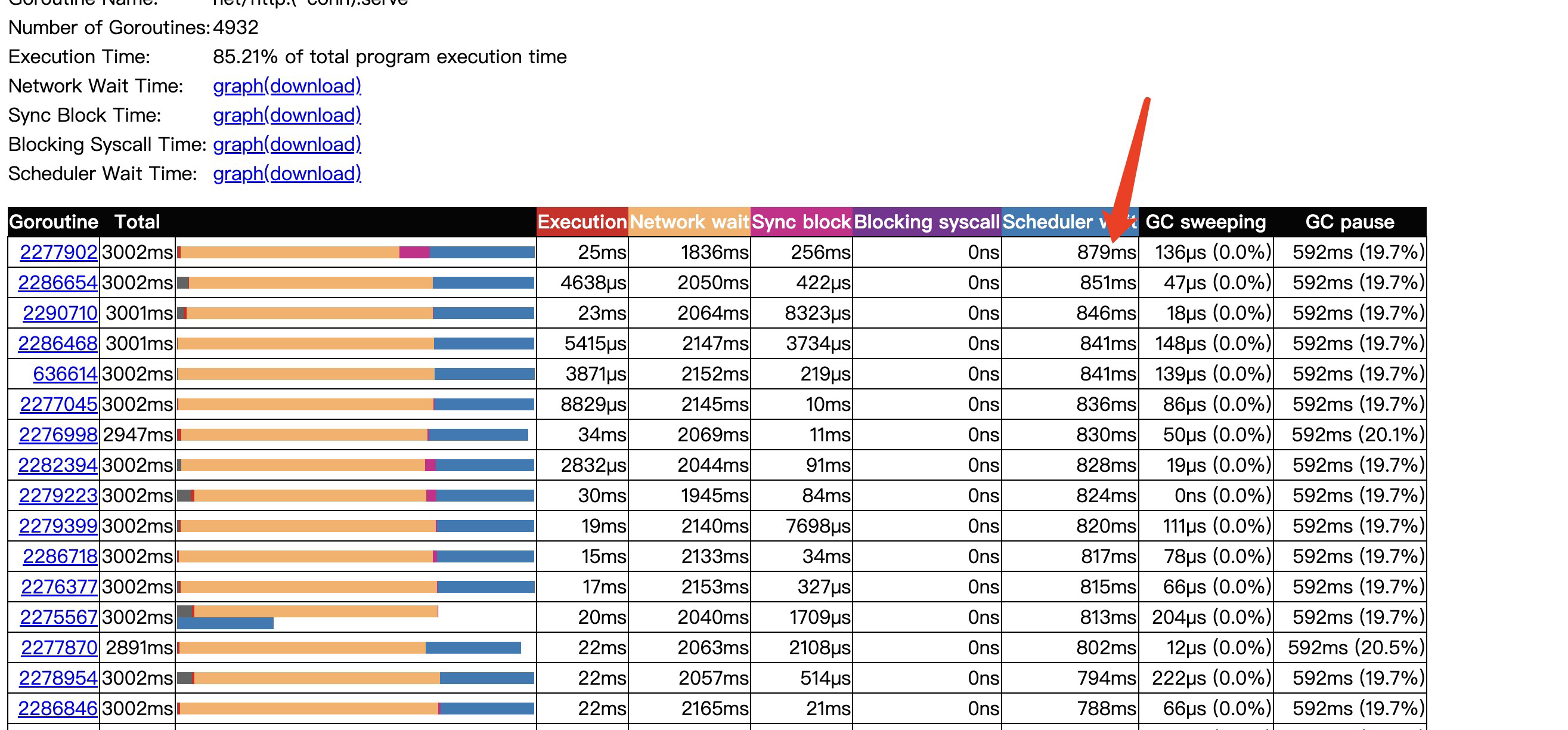
协程从就绪可运行状态到真正被调度耗时了879ms,可见协程调度的压力也是过大的。
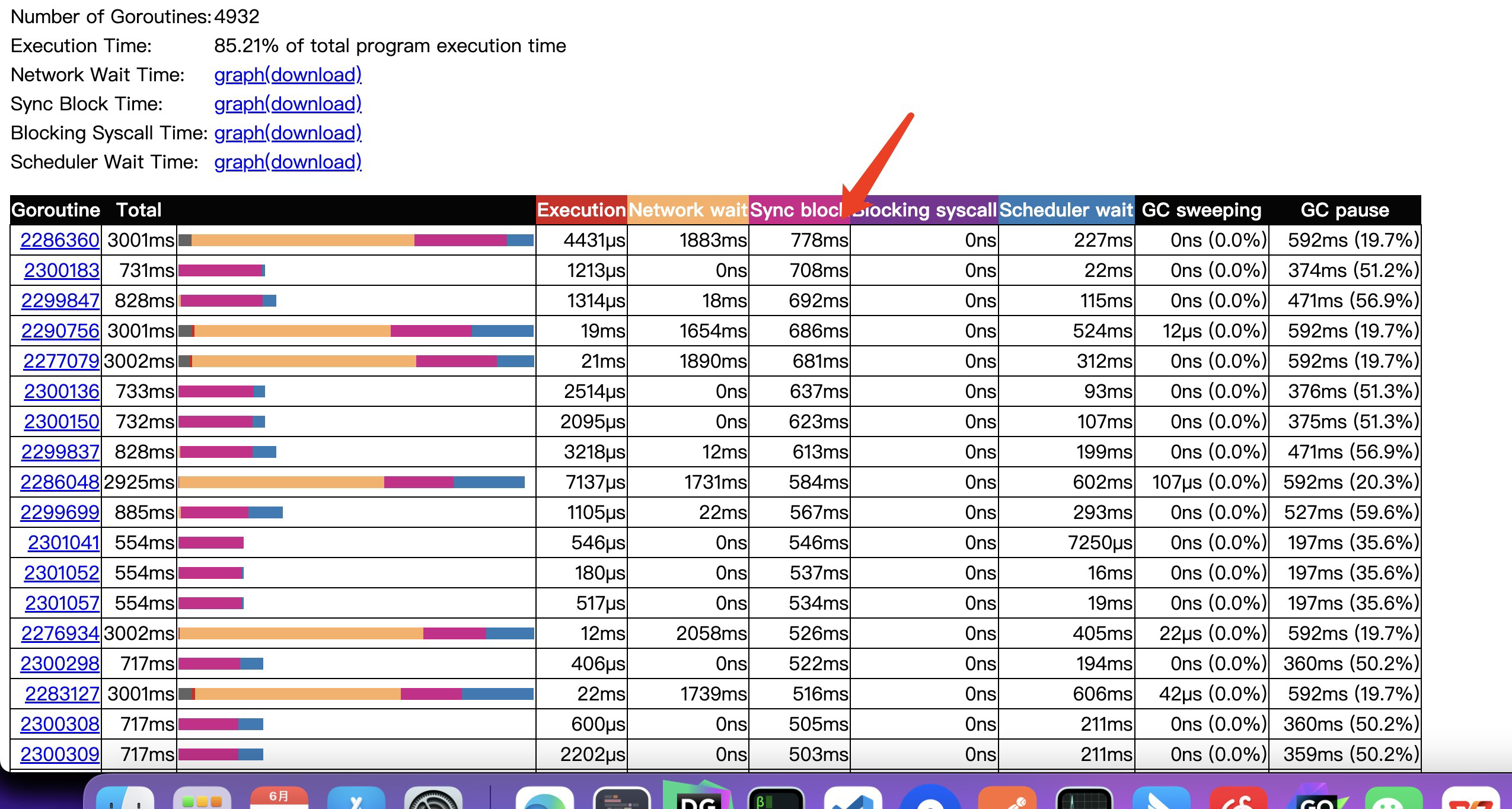
由于程序阻塞带来的延迟开销也是不小的,达到778ms。
对应于之前off-cpu看到的网络和阻塞开销就是执行数据库操作时的网络请求以及withlock操作,由于阻塞更加剧了协程调度的开销。每次阻塞都会引发协程的重新调度。当然go trace左上角可以点击graph同样能观察得出上述结论。
优化
由于程序的阻塞虽然不是慢查询导致,但是依然是由于数据库操作带来的,所以简单直接的优化就是减少数据库操作,或者更直接点说,在高并发接口下,尽可能减少网络等阻塞操作。
将这部分查询数据提前存到内存里,通过内存直接查询。
成果
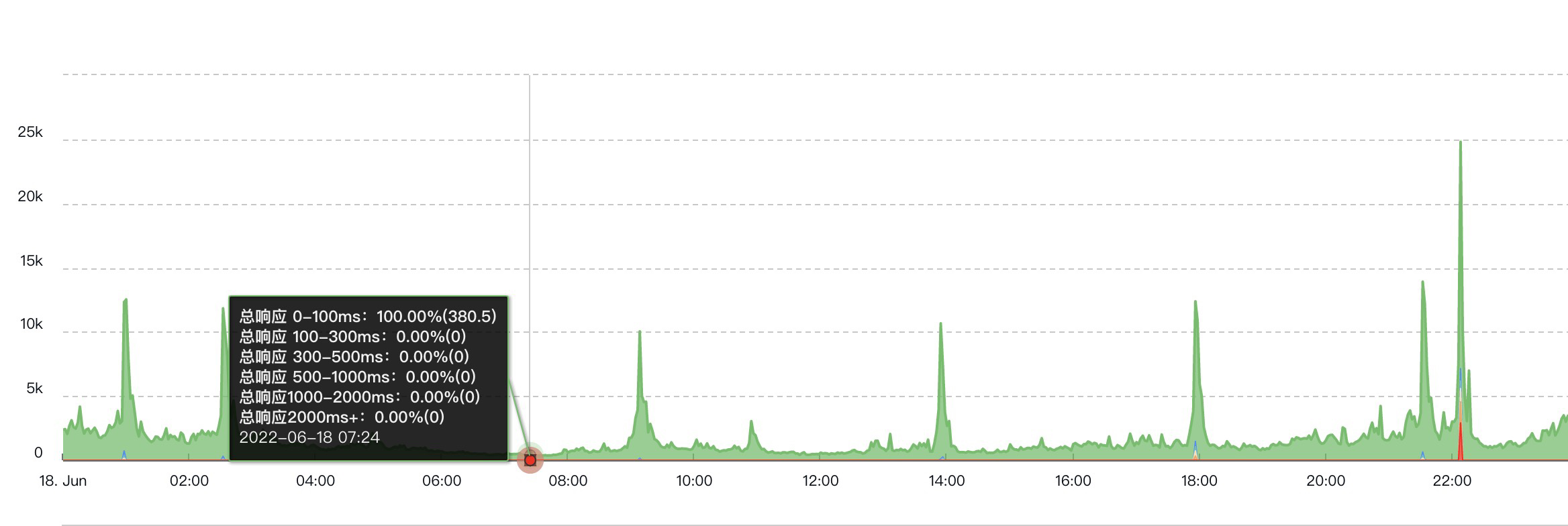
可以看到对比之前情况,除开22点峰值,已经没有超过2s的响应了,但是22点峰值时还是会有,原因是我们线上的机器同时部署了多台服务,由于其他服务的影响导致,所以后续可能还会继续做优化,将其他服务的处理接口能力提升上去,或者更好的做好隔离。
结论
go trace 是个很好的分析系统延迟的工具。
对高并发接口的设计最好减少网络以及其他阻塞操作,流量上去后,这些阻塞很可能带来系统延迟。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号