node抓取页面之分析数据
一、起因:
昨天有个打算,爬个中小学试卷的数据,但是发现这个网站比我之前爬的数据难分析,到不是因为页面数据难分析,我要爬的页面数据很简单,到时URL地址把我难到了!
首先页面的URL地址符是这样子的(ps:真实页面地址就不贴了,毕竟不是什么光彩的事情):
主地址:域名用:http://hmy666.cn代替
http://hmy666.cn/' + 【学年阶段】 + '/' + 【课程】 + '/' + 【年级】 + '/1/' + 【数字】 + '.htm'
首先:
学年阶段的可选值为:高中,初中,小学;
课程的可选值为:语文,数学,英语,政治,历史,地理,生物,化学,物理;
年级的可选值为:一年级,二年级,三年级,四年级,五年级,六年级;
我的目的是要爬取8888页的数据;
开始分析:
如果单纯是页面的URL地址栏数字变化而已,那么爬取的是易如反掌,我只要弄个for循环,然后地址栏数字相应增加就好了,这个也是我爬过最多的一种方式。但是这个页面的地址符有四个可选值,相应的可选值变化又是随机的,举个例子:
http://hmy666.cn/' + 【小学】 + '/' + 【数学】 + '/' + 【1年级】 + '/1/' + 【10】 + '.htm' http://hmy666.cn/' + 【小学】 + '/' + 【英语】 + '/' + 【3年级】 + '/1/' + 【18】 + '.htm' http://hmy666.cn/' + 【初中】 + '/' + 【数学】 + '/' + 【1年级】 + '/1/' + 【104】 + '.htm' http://hmy666.cn/' + 【高中】 + '/' + 【化学】 + '/' + 【3年级】 + '/1/' + 【1005】 + '.htm' http://hmy666.cn/' + 【小学】 + '/' + 【语文】 + '/' + 【1年级】 + '/1/' + 【1152】 + '.htm'
(1)URL地址符的解决方案:
首先上面都是随机性的,不过还好都是可选范围的随机,页面的id的幸亏也是可选范围的随机,不然我真的没办法做了,如果来个编码,把它加密,我就肯定选择放弃,虽然也可以做,就是用相应的编码去解密,不过我还没试过,先不乱说了。
所以我对应的开始制作可选范围的数组,设计如下:
//中文数组用于生成标签,拼音数组用于生成url let Class = ['小学', '初中', '高中'] let grade = ['一年级', '二年级', '三年级', '四年级', '五年级', '六年级']; let subject = ['语文', '数学', '英语', '政治', '地理', '生物', '化学', '历史', '物理']
let Class_p = ['xiaoxue', 'chuzhong', 'gaozhong'] let grade_p = ['nianji1', 'nianji2', 'nianji3', 'nianji4', 'nianji5', 'nianji6']; let subject_p = ['yuwen', 'shuxue', 'yingyu', 'zhengzhi', 'dili', 'shengwu', 'huaxue', 'lishi', 'wuli']
上面的数组分为两类,拼音的字符串数组是用来匹配页面的地址符的,中文的字符串数组是我用来生成标签的,以插入数据库,到时候才可以根据现应的标签反馈给用户,供于分类与搜索用的。
设计好了基本的数组类型,我开始设计我的逻辑思路:
由于地址符对应的页面是随机的,我只能用穷举法,但是你想一下,用穷举法,你看看需要多少次,先看一下我算的一笔账:
首先是8888个页面 * 学年阶段【3个可选值】* 年级阶段【小学有六个可选值,中学三个可选值】* 课程【小学三个可选值,中学九个可选值】
算一笔精确一点的:
小学:8888 * 6 * 3 = 159984
初中+高中:2 * 8888 * 3 * 9 = 479952
所以小学+初中+高中 = 639936
所以本来是访问8888个页面就好,现在要访问639936,从千级别到十万级别,多了72倍,假设我访问一个页面加上保存数据只用一秒就好(ps:我抓取的时候还真是设置一秒访问一个页面),首先一分钟60秒,一个小时60分钟等于3600秒,所以我总共要访问:177.76个小时合计为:7.406666天,差不多得爬一个星期。
(2)试图优化方案:
单纯穷举法,首先撇开长时间的爬取被封ip号的可能性,这个可以用代理池,不过可能需要钱,这个先不考虑,因为我也没用过需要钱的代理;
所以我想,我是不是可以创建一个数组,这个数组保存着许多个对象,对象中会有一个索引值,即ID,因为我是穷举,我生成的对象会有639936个对象,一个对象代表一个访问的网页,我从1开始访问,每次访问到一个对象,就把这个索引删掉。
打个比方,我不是创建了6千多万个对象吗,这6千多万个对象都有很多重复的ID,里面只有8888个对应的ID与学年,与年级与课程全部正确的。669936除以8888等于72,就说明我相同ID的对象,每一个相同ID都有72个,所以我一旦访问到这个正确的,就可以把其他相同ID的对象删掉,减少一部分访问量,画个图表示一下:
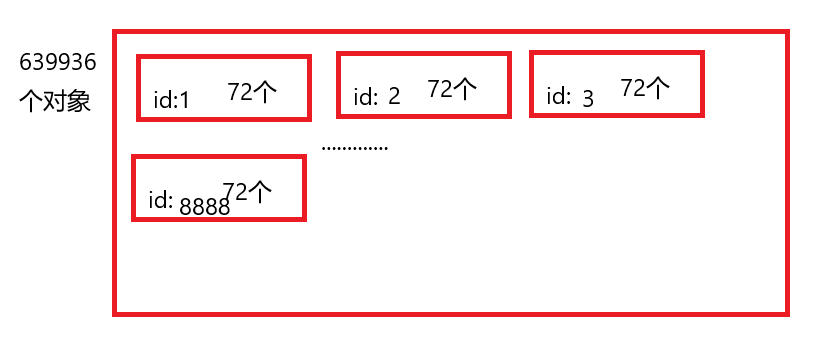

所以这个方法可以达到减少访问次数的目的,具体减少多少还得看运气,访问到一个页面,数组对象就会减少几十个,这样就提高了访问成功的效率。
另外,其实程序还可以优化的地方,比如一年级小学没有英语,二年级才有,如果对其进行处理,那么可以减少8888个对象,减少了8888秒,但是实际不会减少这么多,因为我只要请求到响应的id就进行数组对象删除操作,不过我觉得还是可以提高一点性能的,
可以看到只要查询到数据,数组长度就会减少:
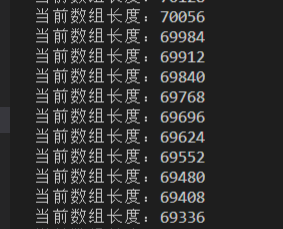
这是我测试请求前1000个页面的结果,不过后来的请求结果很多都是404,大概是初中高中的数据大部分在1000.HTML后面吧,越到后面越难遍历
最后还剩下2万多对象没有删掉,然而已经遍历到高三了:
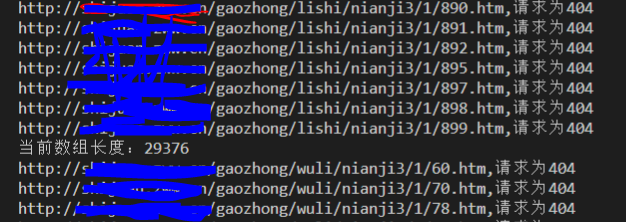
数据库请求到500多条:

难道是请求漏掉的,答案不是的,其实除了这些常见科目,它还有一些作文啊,科学啊这些我没有爬取,这些应该就是剩下的漏网之鱼,1000个网页爬到500多,还行吧,就是速度慢了点。爬了的确7个多小时。可以看到我的优化方案,不断删除数组还是有效果的,因为出去29000条数组还没删除,我总共大概删了43000个对象,也就是我访问了43000个网页,原本时间应该是43000秒=11.94179个小时,现在只用了7个多小时,效率提高50%
所以接下来我打算爬取剩下的7888个网页,打算同时运行20个程序,放在我的服务器上面耗,这样应该明天早上就可以得到这些结果了。
附上源码demo(我的算法的设计还需优化,不然效率还是太慢):
const mongoose = require('mongoose')
var iconv = require('iconv-lite')
var request = require('request');
const cheerio = require('cheerio');
proxies = [
{//为了防止被封ip,可以使用代理池,这些当然你是通过一些途径获得,或是免费,或是收费,自己网上查查ip代理,我这里弄了250个ip
"http": "123.xx.xxx.170:9999",
"https": "123.xx.xxx.170:9999"
},
{
"http": "36.248.xxx.xx:9999",
"https": "36.248.xxx.xx:9999"
}
]
let headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0"//请求头,假装自己是浏览器
}
//连接mongo
mongoose.connect('mongodb://hmy:123@localhost:27017/we_teach?authSource=admin', {
useNewUrlParser: true,
useUnifiedTopology: true
})
.then(
() => {
console.log("连接成功")
}
).catch(err => {
console.log("连接失败")
})
// 操作表(集合),定义一个schema,每一个schema映射一个表,字段和表一一对应
var Tests_schema = mongoose.Schema({
id: String,
title: String, //文章名称
content: Array, //文章内容
tag: Array
})
//中文数组用于生成标签,拼音数组用于生成url
let Class = ['小学', '初中', '高中']
let grade = ['一年级', '二年级', '三年级', '四年级', '五年级', '六年级'];
let subject = ['语文', '数学', '英语', '政治', '地理', '生物', '化学', '历史', '物理']
let Class_p = ['xiaoxue', 'chuzhong', 'gaozhong']
let grade_p = ['nianji1', 'nianji2', 'nianji3', 'nianji4', 'nianji5', 'nianji6'];
let subject_p = ['yuwen', 'shuxue', 'yingyu', 'zhengzhi', 'dili', 'shengwu', 'huaxue', 'lishi', 'wuli']
let indexArr = []
//生成url数组对象
function generateUrl() {
for (let i = 0; i < 3; i++) {
let chooseClass = Class_p[i] //中小学阶段
let tagClass = Class[i]
if (chooseClass) {
let gradeNum; //年级数
let subNum; //课程数目
if (chooseClass == 'xiaoxue') {
gradeNum = 6 //小学年级数有6个,课程3个
subNum = 3
} else {
gradeNum = 3 //中学年级数有3个,课程9个
subNum = 9
}
for (let i = 0; i < gradeNum; i++) {
let chooseGrade = grade_p[i]
let tagGrade = grade[i]
for (let i = 0; i < subNum; i++) {
let chooseSubject = subject_p[i]
let tagSubject = subject[i]
let tag = (tagClass + ',' + tagGrade + ',' + tagSubject).split(','); //生成标签数组
if(chooseClass=='xiaoxue'&&chooseGrade=='nianji1'&&chooseSubject=='yingyu'){//如果是小学且是一年级,那么英语就跳过,不搜索
continue;
}
for (iid = 3766; iid <= 4160; iid++) {
let urlObj = {
"id": iid, //id编号
"class": chooseClass, //中小学阶段
"grade": chooseGrade, //年级
"subject": chooseSubject, //课程
//url地址形式:http://hmy666.cn/chuzhong/yuwen/nianji1/1/5165.htm
"url": 'http://hmy666.cn/' + chooseClass + '/' + chooseSubject + '/' + chooseGrade + '/1/' + iid + '.htm',
"tag": tag //标签
}
indexArr.push(urlObj)
}
}
}
}
}
}
//创建数据库表模型,操作表表,
var Tests = mongoose.model('ss_tests', Tests_schema)
// let tag = []
// let url = indexArr[i]["url"];//链接
async function get_test(url) {
return await new Promise(async (resolve) => {
await request({
url: url,
headers: headers,
proxies: proxies[Math.floor(Math.random * 249 + 1)],//使用随机ip进行访问
encoding: null // 关键代码,设置请求数据不编码,因为我爬的是用gbk编码的,因为node本身解码不了gbk编码的,不设置的话,它会默认用utf-8解码,得到的是乱码
}, (err, status, resData) => {
resolve(resData)
return resData;
});
})
}
generateUrl();//开始生成url
let a;
let count = 0;
let timer = setInterval(() => {
if(count>indexArr.length-2){clearInterval(timer)}
let content = [];
let title = ''
a = get_test(indexArr[count]['url'])
a.then(html => {
var html = iconv.decode(html, 'gbk') //将上面没有解码的buffer数据,利用iconv解码为gbk格式
let $ = cheerio.load(html, {
decodeEntities: false
});
//试题名称与内容
title = $('.col1 h1').text()
$('.content p').each(function (i, elem) {
content.push($(this).html()) //文章内容
})
if (title != '' && content != '') {
var tests = new Tests({
id: indexArr[count]["id"],
title: title,
content: content,
tag: indexArr[count]['tag'],
})
tests.save();
let index = indexArr[count]["id"]; //如果编号为iid的内容被访问过了,就删除数组对象中拥有相同id的对象
for (let i in indexArr) {//遍历数组中所有对象
if (indexArr[i]["id"] == index) {//判断当前遍历到的对象的ID是否和当前访问过的id一致,是的话就删除
indexArr.splice(i, 1) //删除当前访问过的iid标签的对象,js的splice会直接修改数组,然后返回一个删除的元素,所以此处直接使用该方法,而不是用一个变量接收
// console.log("删除下标:"+i)
}
}
console.log("当前数组长度:"+indexArr.length);//每次保存成功,就打印一下当前数组长度
}else{
console.log(indexArr[count]['url']+",请求为404");//如果当前访问不成功,那么就打印一下当前不成功的页面地址,其实这里你可以把log数据写入数据库,然后下次要爬的时候,生成数组的情况下,可以查询数据库,见这些404对象从数组删除
}
}).then(() => {
count++;
}).catch(err => {
console.log(err)
})
}, 1000)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号