

初识:Precision、Recall、Accuracy、F1-Score
一、定义
本人现有学习领域不涉及机器学习,本文仅涉及相关评价指标。
当系统将样本分为真(positive),假(negative)两类,下方框图表示所有需要的样本(all testing instances),其中黄色圆圈代表预测为真(positive)的样本,绿色圆圈代表实际为真(positive)的样本。
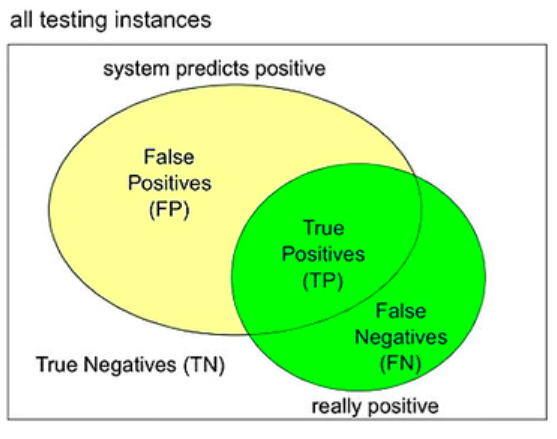
因此一般会产生四种结果:TP、TN、FP、FN(T:true,表示正确;F:false,表示错误;P:positive;N:negative)
TP:true positive,真样本,预测为真样本;(黄绿相交的那一部分)
TN:true negative,假样本,预测为假样本;(框图内白色的那一部分)
FP:false positive,假样本,预测为真样本;(绿色圆圈以外黄色那一部分)
FN:false negative,真样本,预测为假样本;(黄色圆圈以外绿色那一部分)
由上述概念可得到如下推论:
总样本数:TP+TN+FP+FN;
实际真/假样本数:TP+FN/TN+FP;
测量结果为真样本的数目:TP+FP;
测量结果为假样本的数目:TN+FN;
二、False Alarm rate--False Positive rate
false alarm rate,实际为假的样本中有多少预测为真的样本。计算方式如下:
![]()
三、Miss rate--False Negative rate
Miss rate,实际为真的样本中有多少预测为假的样本。计算方式如下:
![]()
四、Recall(召回率)--True Positive rate
Recall,实际为真的样本中有多少预测为真的样本。其计算方式如下:
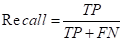
Recall+Miss rate=1
五、Precision(精确率)
Precision,用于评估算法对所有待测目标的正确率,也就是测量为真的样本(TP+FP)中实际为真的样本(TP)比例。其计算方式如下:
![]()
六、F1-Score(F-Measure,综合评价指标)
当Recall和Precision出现矛盾时,我们需要综合考虑他们,最常见的方法就是F1-Score,其实就是Precision和Recall的加权调和平均(P指代Precision,R指代Recall):
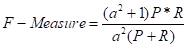
当a=1时,Recall与Recall的权重相同,可以得到:
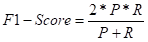
七、Accuracy(准确率)--测量正确的样本占总样本的比例
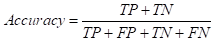
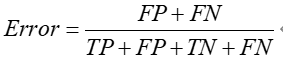
相比于前两者,Accuracy是一种很直观的评价标准,但准确率越高不等价于算法越好(在正负样本失衡的情况下,准确率存在很大的缺陷--e.g., 互联网推广中,某些广告点击量很少,也就是测量均为负样本(不点计量)在99%以上也没有任何意义)。
单纯利用Accuracy评价一个算法模型是远远不够的(针对于分布不均衡的样本)。
以上内容仅记录本人学习,如有错误之处,敬请指正!谢谢!
八、参考
召回率(recall)和精度(precision)_THE@JOKER的博客-CSDN博客_recall召回率
机器学习:准确率(Precision)、召回率(Recall)、F值(F-Measure)、ROC曲线、PR曲线_nana-li-DevPress官方社区 (csdn.net)
机器学习中常用的评价指标 | 分类任务、回归任务 (cuc.edu.cn)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号