【C++】多线程
前言
实现多线程(win32 API、pthread、std::thread)、线程同步(互斥量、原子变量、读写锁、条件变量、线程局部存储)、如何调试。
多线程
线程:是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
多线程:是多任务处理的一种特殊形式。
一般情况下,两种类型的多任务处理:基于进程和基于线程。
- 基于进程的多任务处理是程序的并发执行。
- 基于线程的多任务处理是同一程序的片段的并发执行。
- 并发:多个任务在时间片段内交替执行,表现出同时进行的效果。
- 并行:多个任务在多个处理器或处理器核上同时执行。
C++ 多线程编程涉及在一个程序中创建和管理多个并发执行的线程。
实现多线程
在C++ 11 新特性中std::thread对linux中的pthread和windows中的Win32 API进行封装,支持跨平台、移动语义等特点,本文主要使用std::thread,对pthread和Thread简单使用。
使用<windows.h>实现
windows下的原生API进行创建线程。
- 接口
//创建线程
HANDLE CreateThread(
_In_opt_ LPSECURITY_ATTRIBUTES lpThreadAttributes, // 安全属性
_In_ SIZE_T dwStackSize, // 堆栈大小
_In_ LPTHREAD_START_ROUTINE lpStartAddress, // 线程函数地址
_In_opt_ LPVOID lpParameter, // 线程参数
_In_ DWORD dwCreationFlags, // 创建标志
_Out_opt_ LPDWORD lpThreadId // 接收线程ID
);
//关闭句柄
CloseHandle(
_In_ _Post_ptr_invalid_ HANDLE hObject
);
//待线程结束
//等待事件、信号量等同步对象
DWORD WaitForSingleObject(
_In_ HANDLE hHandle, // 要等待的对象句柄
_In_ DWORD dwMilliseconds // 超时时间(毫秒)
);
// 使用标志变量让线程自然退出
// 使用事件对象通知线程退出
BOOL TerminateThread(
_In_ HANDLE hThread, // 要终止的线程句柄
_In_ DWORD dwExitCode // 线程退出码
);
// 检查线程是否仍在运行
// 获取线程的执行结果
// 调试和错误处理
BOOL GetExitCodeThread(
_In_ HANDLE hThread, // 线程句柄
_Out_ LPDWORD lpExitCode // 接收退出码的指针
);
// 设置当前线程属性(优先级、亲和性等)
// 在线程函数中操作自身
HANDLE GetCurrentThread(VOID); // 无参数,返回当前线程伪句柄
- 实现
#include <windows.h>
#include <iostream>
using namespace std;
DWORD WINAPI threadrun(LPVOID lpParamter)
{
for (int i = 0; i < 10; i++) {
cout << "Threadrun:" << i << endl;
Sleep(50);
}
return 0;
}
int main()
{
HANDLE hThread = CreateThread(NULL, 0, threadrun, NULL, 0, NULL);
CloseHandle(hThread); //CloseHandle只是关闭了句柄,并不会终止线程。但是,如果主线程退出,进程会终止,所有线程都会结束。
for (int i = 0; i < 10; i++) {
cout << "Main:" << i << endl;
Sleep(10);
}
//WaitForSingleObject(hThread, INFINITE); //等待线程完成 ,前提是hThread没有关闭
return 0;
}
使用pthread实现
- 接口
// 创建线程
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine)(void *), void *arg);
// 线程退出
void pthread_exit(void *retval);
// 等待线程结束
int pthread_join(pthread_t thread, void **retval);
// 分离线程
int pthread_detach(pthread_t thread);
// 取消线程
int pthread_cancel(pthread_t thread);
// 获取当前线程ID
pthread_t pthread_self(void);
// 比较线程ID
int pthread_equal(pthread_t t1, pthread_t t2);
// 初始化线程属性
int pthread_attr_init(pthread_attr_t *attr);
// 销毁线程属性
int pthread_attr_destroy(pthread_attr_t *attr);
// 设置分离状态
int pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate);
// 获取分离状态
int pthread_attr_getdetachstate(const pthread_attr_t *attr, int *detachstate);
// 设置堆栈大小
int pthread_attr_setstacksize(pthread_attr_t *attr, size_t stacksize);
// 设置调度策略
/*
* 参数:policy -
* SCHED_FIFO 先进先出
* SCHED_RR 轮转
* SCHED_OTHER 其他(默认)
*/
int pthread_attr_setschedpolicy(pthread_attr_t *attr, int policy);
- 实现
#include <pthread.h> // POSIX 线程库头文件
#include <stdio.h> // 标准输入输出头文件
#include <stdlib.h> // 标准库头文件(包含exit等函数)
#include <unistd.h> // Unix标准库头文件,包含getpid(), sleep()等系统调用
#include <iostream> // C++标准输入输出流
#include <cstring>
using namespace std; // 使用std命名空间
// 线程函数 - 子线程的入口点
// 参数:threadid - 传递给线程的参数(这里用作线程标识符)
// 返回值:void* - 线程退出时可以返回一个指针(这里返回NULL)
void *PrintThread(void *threadid)
{
// 获取当前线程ID的方式:
// 使用pthread_self()获取POSIX线程ID(pthread_t类型)
pthread_t id = pthread_self();
pid_t tid = getpid(); // 这获取的是进程ID,不是线程ID
cout << "ChildThread:" << " pid=" << tid << endl; // 这里打印的是进程ID
cout << "ChildSelf:" << " id=" << id << endl;
for(int i = 0; i < 100; i++){
cout << i << endl;
sleep(1); // 休眠1秒,模拟耗时操作
}
// 线程退出
pthread_exit(NULL); // 显式退出线程,参数NULL表示不返回任何值
// 或者直接: return NULL; // 等效的退出方式
}
int main(int argc, char *argv[])
{
// 获取当前进程ID(注意:主线程也在同一个进程中)
pid_t tid = getpid(); // 获取当前进程ID
cout << "main thread" << " pid=" << tid << endl; // 打印主线程所在进程的ID
pthread_t id = pthread_self();
cout << "main Self:" << " id=" << id << endl;
pthread_t thread; // 线程句柄/标识符(用于引用创建的线程)
pthread_attr_t attr; //线程属性对象
int result; // 存储函数返回码(return code)
long param = 1; // 线程参数,这里作为线程ID使用(值为1)
result = pthread_attr_init(&attr); //初始化属性
if (result != 0) {
cerr << "Error: pthread_attr_init failed: " << strerror(result) << endl;
return 0;
}
//设置分离状态 PTHREAD_CREATE_JOINABLE 或 PTHREAD_CREATE_DETACHED
result = pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE);
if (result == 0) {
cout << "设置线程为可连接状态(JOINABLE)" << endl;
}
// 设置堆栈大小(256KB)
size_t stacksize = 256 * 1024; // 256KB
result = pthread_attr_setstacksize(&attr, stacksize);
if (result == 0) {
size_t actual_stacksize;
pthread_attr_getstacksize(&attr, &actual_stacksize);
cout << "设置堆栈大小: " << actual_stacksize << " bytes" << endl;
}
// 设置调度策略 普通应用用 SCHED_OTHER分时调度
result = pthread_attr_setschedpolicy(&attr, SCHED_OTHER);
if (result == 0) {
cout << "设置调度策略: SCHED_OTHER" << endl;
}
// 设置继承调度属性(使用显式设置而非继承)
result = pthread_attr_setinheritsched(&attr, PTHREAD_EXPLICIT_SCHED);
if (result == 0) {
cout << "设置显式调度继承" << endl;
}
//设置竞争范围(Linux只支持系统级) Linux只支持 PTHREAD_SCOPE_SYSTEM
result = pthread_attr_setscope(&attr, PTHREAD_SCOPE_SYSTEM);
if (result == 0) {
cout << "设置竞争范围: PTHREAD_SCOPE_SYSTEM" << endl;
}
// 创建新线程
// &thread: 用于存储新线程的标识符
// NULL: 线程属性(使用默认属性)
// PrintThread: 线程函数指针(新线程执行的函数)
// (void *)param: 传递给线程函数的参数(将long转换为void*)
result = pthread_create(&thread, &attr, PrintThread, (void *)param);
// 检查线程创建是否成功
if (result) // rc != 0 表示创建失败
{
// pthread_create返回错误码(非零)
// 通常应该处理错误,这里直接返回
return 0;
}
result = pthread_attr_destroy(&attr);
// 主线程继续执行自己的工作(与子线程并发执行)
for(int i = 0; i < 5; i++){
cout << "Main thread " << i << endl; // 主线程输出
sleep(2); // 休眠2秒(子线程休眠1秒,所以子线程输出更频繁)
}
pthread_join(thread, NULL);
return 0;
}
- out
main thread pid=6255
main Self: id=139668265477952
设置线程为可连接状态(JOINABLE)
设置堆栈大小: 262144 bytes
设置调度策略: SCHED_OTHER
设置显式调度继承
设置竞争范围: PTHREAD_SCOPE_SYSTEM
Main thread 0
ChildThread: pid=6255
ChildSelf: id=139668265473792
调用普通函数
pthread_create接收的是函数指针,传入普通函数会报错参数类型错误,必须接收
void * ( * )(void * )
采用外面线程包装函数
error: invalid conversion from ‘void (*)()’ to ‘void* (*)(void*)’ [-fpermissive] rc = pthread_create(&thread, &attr, &PrintThread_1, NULL);
void PrintThread_1()
{
for(int i = 0; i < 100; i++){
cout << i << endl;
sleep(1);
}
return;
}
void* thread_wrapper(void* arg) {
(void)arg; // 忽略参数(防止编译器警告)
// 调用真正的无参数函数
PrintThread_1();
return NULL; // 线程返回值
}
int result = pthread_create(&thread, &attr, thread_wrapper, NULL);
调用静态函数
static void* PrintThread_2(void* arg) {
(void)arg;
for(int i = 0; i < 100; i++){
cout << i << endl;
sleep(1);
}
return NULL;
}
int result = pthread_create(&thread, &attr, PrintThread_2, (void*)param);
调用 类静态函数
#include <pthread.h>
#include <iostream>
#include <unistd.h>
using namespace std;
class MyClass {
public:
// 静态成员函数 - 可以作为线程函数
static void* PrintThread_3(void* arg) {
cout << "Static member function called" << endl;
for(int i = 0; i < 10; i++){
cout << "fun: " << i << endl;
sleep(1);
}
cout << "Static member function finished" << endl;
return nullptr;
}
};
int main() {
pthread_t thread;
int param = 42;
// 直接调用类的静态成员函数
//pthread_create(&thread, NULL, &MyClass::PrintThread_3,¶m);
// 通过类名调用静态函数
pthread_create(&thread, NULL, MyClass::PrintThread_3, ¶m);
for(int i = 0; i < 10; i++){
cout << "main:" << i << endl;
sleep(1);
}
pthread_join(thread, nullptr);
cout << "Main: Thread completed" << endl;
return 0;
}
C++11 std::thread 实现
- std::thread主要接口
thread() noexcept; // 创建不表示线程的空线程对象
template< class Function, class... Args >
explicit thread( Function&& f, Args&&... args ); // 创建新线程并执行函数
thread( const thread& ) = delete; // 不可复制构造
thread( thread&& other ) noexcept; // 移动构造
join() //阻塞当前线程,直到目标线程执行完毕
detach() //分离线程,允许线程独立执行;分离后线程对象不再管理该线程
joinable() //检查线程是否可合并
//返回 true 的情况:
//1.通过构造函数创建且未调用 join/detach
//2.已移动但未管理的线程对象
get_id() //返回线程的唯一标识符,如果线程不可合并,返回默认构造的 id
hardware_concurrency() //返回硬件支持的并发线程数,用于指导线程池大小设置
void swap(thread& _Other) noexcept//交换两个 std::thread 对象的底层句柄
-实例
#include <stdio.h> // 标准输入输出头文件
#include <stdlib.h> // 标准库头文件(包含exit等函数)
#include <iostream> // C++标准输入输出流
#include <cstring>
#include <thread>
#include <chrono>
using namespace std; // 使用std命名空间
// 线程函数 - 子线程的入口点
void PrintThread(int param)
{
thread::id thread_id = this_thread::get_id();
cout << "ChildThread:" << " id=" << thread_id<< endl; // 这里打印的是进程ID
for (int i = 0; i < 100; i++) {
cout << i << endl;
this_thread::sleep_for(chrono::seconds(1)); // 休眠1秒,模拟耗时操作
}
}
//静态函数
static void staticPrintThread(int param){
return PrintThread(param);
}
int main(int argc, char* argv[])
{
thread::id main_id = this_thread::get_id(); // 获取当前进程ID
cout << "main Self:" << " id=" << main_id << endl;
int temp = 50;
// 创建新线程
thread t(PrintThread,temp);
//thread t(staticPrintThread,temp);
//引用传递
//thread t(PrintThread,ref(temp);
// 主线程继续执行自己的工作(与子线程并发执行)
for (int i = 0; i < 5; i++) {
cout << "Main thread " << i << endl; // 主线程输出
this_thread::sleep_for(chrono::seconds(2)); // 休眠2秒(子线程休眠1秒,所以子线程输出更频繁)
}
if (t.joinable()) {
t.join();
}
return 0;
}
Lambda表达式
int temp = 5;
thread t([temp](int count){
for (int i = temp; i < count; i++) {
cout << i << endl;
this_thread::sleep_for(chrono::seconds(1)); // 休眠1秒,模拟耗时操作
}
},30);
调用类普通方法、类静态方法
#include <iostream>
#include <thread>
#include <chrono>
#include <functional>
using namespace std;
class ProgramA{
public:
void PrintThread(){
thread::id thread_id = this_thread::get_id();
cout <<"thread_id: "<<thread_id<<endl;
for(int i = 0;i<50;i++){
cout<<"fun" << i <<endl;
this_thread::sleep_for(chrono::seconds(1));
}
return;
};
static void staticPrintThread(){
thread::id thread_id = this_thread::get_id();
cout <<"thread_id: "<<thread_id<<endl;
for(int i = 0;i<50;i++){
cout<<"static" << i <<endl;
this_thread::sleep_for(chrono::seconds(1));
}
return ;
}
};
int main(){
thread t1(ProgramA::staticPrintThread);
ProgramA PA;
thread t2(&ProgramA::PrintThread,&PA);
thread t3(bind(&ProgramA::PrintThread,&PA));
thread t4(&ProgramA::PrintThread,&PA);
t1.join();
t2.join();
t3.join();
t4.join();
}
promise、future、async
问题:如果有一个使用场景计算A需要5min,计算B需要4分钟,执行C动作需要完成A和B。不使用多线程时需要9min
才能执行C,使用多线程时只需要5min就可以完成前面步骤。
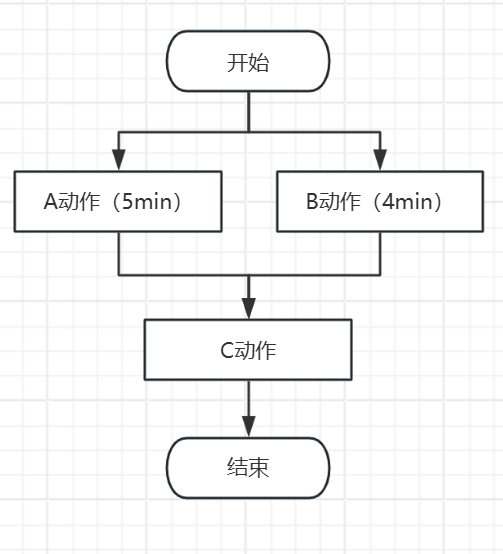
但是如何保证AB完成后才让C执行。
-
在执行C之前让A、B join();
-
使用promise、future、async
promise-future 对是通过共享状态,来帮助线程间传递值或异常的一种沟通通道。是实现线程同步的一种方式。
std::promise:数据提供者;用于存储一个值或异常,之后可以通过与之关联的std::future来获取这个值或异常。
std::future: 数据接收者;提供一个异步操作结果的访问。它可以等待(阻塞)直到std::promise设置好值,然后获取该值。
std::async :用于异步执行任务,并返回一个 std::future 对象来获取结果
- promise、future示例
promise
get_future(): 返回一个与该promise关联的future对象。每个 promise 只能调用一次
get_future(),多次调用会抛出std::future_error异常。
set_value(value): 设置异步操作的结果值。如果多次调用会抛出std::future_error异常。
set_exception(exception_ptr): 设置异步操作的异常。
set_value_at_thread_exit(value): 设置异步操作的结果值,但该值会在当前线程退出时才变得可用。
set_exception_at_thread_exit(exception_ptr): 设置异步操作的异常,但该异常会在当前线程退出时才变得可用。
future
get(): 阻塞当前线程,直到异步操作完成并返回结果。
get()只能调用一次,第二次调用会抛出std::future_error异常。
wait(): 阻塞当前线程,直到异步操作完成,但不获取结果。
wait_for(duration): 阻塞当前线程,直到异步操作完成或指定的时间已过。
wait_until(time_point): 阻塞当前线程,直到异步操作完成或到达指定的时间点。
设置返回值
1 #include <iostream>
2 #include <thread>
3 #include <chrono>
4 #include <functional>
5 #include <future>
6
7 using namespace std;
8 void computeA(promise<int> &&prom){
9 this_thread::sleep_for(chrono::seconds(5));//5s
10 cout<< "A执行完成! 5s" <<endl;
11 prom.set_value(1);//设置结果值
12 }
13
14
15 void computeB(promise<float> &&prom){
16 this_thread::sleep_for(chrono::seconds(4));//4s
17 cout<< "B执行完成! 4s" <<endl;
18 prom.set_value(1);//设置结果值
19 }
20
21
22 void computeC(future<int> &&futi,future<float> &&futf){
23 cout<< "C开始!" <<endl;
24 futi.get();
25 futf.get();
26 cout<< "C接受A B结果后执行!" <<endl;
27 }
28
29 int main(){
30
31 promise<int> prom_i;
32 future<int> resultFutI = prom_i.get_future();
33
34 promise<float> prom_f;
35 future<float> resultFutF= prom_f.get_future();
36
37
38 thread threadA = thread(computeA , move(prom_i));
39
40 thread threadB = thread(computeB , move(prom_f));
41
42 thread threadC = thread(computeC , move(resultFutI) , move(resultFutF));
43
44
45 threadA.join();
46
47 threadB.join();
48
49 threadC.join();
50 }
设置异常
1 #include <iostream>
2 #include <thread>
3 #include <chrono>
4 #include <functional>
5 #include <future>
6 using namespace std;
7 void funAThrowException(std::promise<int>&& prom) {
8 try {
9 throw std::runtime_error("An error occurred");
10 } catch (...) {
11 prom.set_exception(std::current_exception());
12 }
13 }
14
15 void funBReceiveException(std::future<int>&& fut) {
16 try {
17 int value = fut.get();
18 } catch (const std::exception& e) {
19 std::cout << "Caught exception: " << e.what() << std::endl;
20 }
21 }
22
23
24 int main(){
25 cout<<"main fun! "<<endl;
26 promise<int> prom;
27 future<int> fut = prom.get_future();
28 thread threadA = thread(funAThrowException,move(prom));
29 thread threadB = thread(funBReceiveException,move(fut));
30 threadA.join();
31 threadB.join();
32 return 0;
33
34 }
shared_future
- 若需要使用一个线程的结果,让多个线程获取呢?
可以使用shared_future
可多次调用
get():与std::future不同,shared_future的get()可多次调用线程安全:多个线程可同时调用
get(),但返回引用类型时要小心数据竞争异常传播:异常会被存储,每次
get()都会重新抛出生命周期:共享状态由所有副本共同管理,最后一个副本销毁时释放资源
复制廉价:复制操作只增加引用计数,适合传递到多个线程
值语义优先:尽量返回值类型而非引用类型,避免悬挂引用
检查有效性:使用前检查
valid(),避免操作空的shared_future内存模型:
get()提供memory_order_acquire语义,确保结果可见性
1 #include <iostream>
2 #include <thread>
3 #include <chrono>
4 #include <functional>
5 #include <future>
6
7 using namespace std;
8 void computeA(promise<int> &&prom){
9 cout<< "进入A!" <<endl;
10 this_thread::sleep_for(chrono::seconds(5));//5s
11 cout<< "A完成! 5s" <<endl;
12 prom.set_value(1);//设置结果值
13 }
14
15
16 void computeB(shared_future<int> shared_fut){
17 cout<< "进入B!"<< endl;
18 shared_fut.get(); //等待A完成
19 this_thread::sleep_for(chrono::seconds(4));//4s
20 cout<< "B完成! 4s" <<endl;
21
22 }
23
24
25 void computeC(shared_future<int> shared_fut){
26 cout<< "进入C!" <<endl;
27 shared_fut.get();
28 cout<< "C完成!" <<endl;
29 }
30
31 int main(){
32
33 promise<int> prom_i;
34 future<int> resultFutI = prom_i.get_future();
35 shared_future<int> shared_fut = resultFutI.share();//两步获取shared_future
36 // 直接从 promise 获取 shared_future
37 //share_future<int> share_fut = prom_i.get_future().share();
38
39 thread threadA = thread(computeA , move(prom_i));
40
41 thread threadB = thread(computeB , shared_fut);
42
43 thread threadC = thread(computeC , shared_fut);
44
45
46 threadA.join();
47
48 threadB.join();
49
50 threadC.join();
51 }
- aysnc
1 #include <iostream>
2 #include <thread>
3 #include <chrono>
4 #include <functional>
5 #include <future>
6
7 using namespace std;
8 int computeA(){
9 cout<< "进入A!" <<endl;
10 this_thread::sleep_for(chrono::seconds(5));//5s
11 cout<< "A完成! 5s" <<endl;
12 return 100;
13 }
14
15
16 void computeB(shared_future<int> shared_fut){
17 cout<< "进入B!"<< endl;
18 int result = shared_fut.get(); //等待A完成
19 this_thread::sleep_for(chrono::seconds(4));//4s
20 cout<< "B完成! 4s result = "<< result <<endl;
21
22 }
23
24 int main(){
25 cout<<"main fun! "<<endl;
26 future<int> fut = async(launch::async,computeA);
27 shared_future<int> shared_fut = fut.share();
28 thread threadA = thread(computeB,shared_fut);
29 for(int i = 0;i<50;i++){
30 cout<<"main: i = "<< i <<endl;
31 }
32 threadA.join();
33 return 0;
34
35 }
线程同步
线程同步是多线程编程中协调线程执行顺序的机制,通过控制多个线程对共享资源的访问顺序,防止数据竞争与不可预知的数据损坏。其核心在于保证同一时刻仅有一个线程操作关键数据段。
为什么要线程同步
解决竞争条件和数据不一致性。线程同步的本质就是保证数据操作原子性。
线程同步的方法:
互斥锁、读写锁、条件变量、原子变量、线程局部存储。
互斥锁 mutex和原子变量 atomic
mutex:提供基本的锁定和解锁功能;
recursive_mutex:递归互斥锁,允许同一个线程多次锁定同一个互斥锁,避免自死锁。
timed_mutex:带超时功能的互斥锁,可以尝试锁定一段时间,避免永久阻塞。
recursive_timed_mutex:结合递归和超时功能的互斥锁.
-
锁管理器 (RAII机制)
- lock_guard:轻量级,自动释放,构造时加锁
- unique_lock:支持延时锁定,手动锁定/解锁,所有权转移
- 延迟锁定:
std::unique_lock<std::mutex> lock(mtx, std::defer_lock);
- 延迟锁定:
- scoped_lock - 多锁管理 C++ 17
std::mutex mtx1, mtx2, mtx3; // 同时锁定多个互斥锁,避免死锁 std::scoped_lock lock(mtx1, mtx2, mtx3);
atomic内存序
内存序(Memory Order)是因为编译器和 CPU 为了性能,会进行指令重排(Instruction Reordering)。
memory_order_relaxed
relaxed读/写无同步,仅保证操作原子化(常用于计数器)。
consume读比 acquire 更轻,只同步有数据依赖的变量(不推荐初学者使用)。
acquire读配合 release,防止读操作被重排到后面。
release写配合 acquire,防止写操作被重排到前面。
acq_rel读-改-写同时具有 acquire 和 release 的特性。
seq_cst读/写最严格,所有线程看到完全一致的顺序。默认。
实例:
1 #include <iostream>
2 #include <thread>
3 #include <chrono>
4 #include <functional>
5 #include <future>
6 #include <mutex>
7 #include <atomic>
8
9 using namespace std;
10 //atomic<int> shared_data(0); atomic适用于基本类型
11 int shared_data = 0;
12 mutex g_mutex;
13
14 //测试不准确
15 //不加锁 0ms 结果错误
16 //atomic 3ms
17 //mutex 加锁 12ms
18 //lock_guard 13ms
19 //unique_lock 15ms
20
21 void addValue() {
22 for(int i = 0;i<100000;++i){
23 // mutex加锁
24 // g_mutex.lock();
25 // ++shared_data;
26 // g_mutex.unlock();
27
28 unique_lock<mutex> lock(g_mutex,defer_lock);
29 lock.lock();
30 ++shared_data;
31 lock.unlock();
32
33 }
34 }
35
36
37 int main(){
38 auto startTime = chrono::high_resolution_clock::now();
39 cout<<"main fun! "<<endl;
40 thread threadA = thread(addValue);
41 thread threadB = thread(addValue);
42 threadA.join();
43 threadB.join();
44 auto stopTime = chrono::high_resolution_clock::now();
45 auto duration = chrono::duration_cast<chrono::milliseconds>(stopTime-startTime).count();
46 cout<<"sharedData: "<<shared_data<<" 时间:"<<duration<< "ms"<<endl;
47 return 0;
48
49 }
读写锁
允许多个读线程同时访问共享资源,但只允许一个写线程独占访问
- 读锁(共享锁):多个线程可以同时持有读锁
- 写锁(独占锁):同一时间只能有一个线程持有写锁,且持有写锁时不能有读锁
// 读写锁的状态转换
// 无锁状态 -> 可以加读锁或写锁
// 有读锁时 -> 可以再加读锁,不能加写锁
// 有写锁时 -> 不能加读锁,也不能加写锁
// 写者优先(Writer-preference) 或防止写饥饿(Write starvation prevention) 的策略。
1 #include <iostream>
2 #include <thread>
3 #include <shared_mutex>
4 #include <vector>
5 #include <chrono>
6
7 class ThreadCounter {
8 private:
9 mutable std::shared_mutex mutex_;
10 int value_ = 0;
11
12 public:
13 // 读取操作:使用共享锁
14 int read(int i) const {
15 std::cout<<"读线程调用!"<<std::endl;
16 std::shared_lock<std::shared_mutex> lock(mutex_); // 共享锁
17 std::cout << " (线程ID: " << std::this_thread::get_id() << ") 读操作 顺序号:"<< i << std::end l;
18 std::this_thread::sleep_for(std::chrono::milliseconds(1000));
19 return value_;
20 }
21
22 // 写入操作:使用独占锁
23 void write(int i) {
24 std::cout<< "写线程调用!"<<std::endl;
25 std::unique_lock<std::shared_mutex> lock(mutex_); // 独占锁
26 std::cout << " (线程ID: " << std::this_thread::get_id() << ") 写操作 顺序号:" << i << std::en dl;
27 std::this_thread::sleep_for(std::chrono::milliseconds(5000));
28 ++value_;
29 }
30
31 // 写入操作:重置值
32 void reset() {
33 std::unique_lock<std::shared_mutex> lock(mutex_); // 独占锁
34 std::cout << " (线程ID: " << std::this_thread::get_id() << ") 重置操作" << std::endl;
35 std::this_thread::sleep_for(std::chrono::milliseconds(10));
36 value_ = 0;
37 }
38 };
39
40 int main() {
41 std::cout << "=== 基本读写锁示例 ===" << std::endl;
42
43 ThreadCounter counter;
44 std::vector<std::thread> threads;
45
46 // 启动多个读线程
47 for (int i = 0; i < 5; ++i) {
48 threads.emplace_back([&counter, i]() {
49 for (int j = 0; j < 3; ++j) {
50 counter.read(i);
51 }
52 });
53 }
54
55 // 启动写线程
56 threads.emplace_back([&counter]() {
57 for (int i = 0; i < 2; ++i) {
58 counter.write(i);
59 }
60 });
61
62 for (auto& t : threads) {
63 t.join();
64 }
65 return 0;
66 }
条件变量 condition_variable
条件变量实现多个线程间的同步操作,当条件不满足时,相关线程被一直阻塞,直到某种条件出现,这些线程才会被唤醒
典型流程
mutex 条件变量运行状态切换时的同步
condition_variable 等待/唤醒
共享数据
条件
1 #include <iostream>
2 #include <queue>
3 #include <thread>
4 #include <mutex>
5 #include <condition_variable>
6 #include <vector>
7
8 class ProducerConsumer {
9 private:
10 std::queue<int> queue; // 共享资源:缓冲区队列
11 std::mutex mtx; // 互斥锁,保护队列
12 std::condition_variable cv_prod; // 条件变量:控制生产者(当队列满时等待)
13 std::condition_variable cv_cons; // 条件变量:控制消费者(当队列空时等待)
14 size_t capacity; // 缓冲区最大容量
15
16 public:
17 explicit ProducerConsumer(size_t capacity) : capacity(capacity) {}
18
19 // 生产者调用的入队函数
20 void prod(int value) {
21 // 获取锁:保护共享资源 queue
22 std::unique_lock<std::mutex> lock(mtx);
23
24 // 等待判断:如果队列满了,生产者阻塞并释放锁,直到消费者消费后唤醒
25 // 使用 lambda 表达式防止虚假唤醒
26 //wait()的谓词返回true时继续等待,返回false时才退出等待
27 cv_prod.wait(lock, [this]() { return queue.size() < capacity; });
28
29 // 执行生产
30 queue.push(value);
31 std::cout << "Produced: " << value << " | Queue size: " << queue.size() << std::endl;
32
33 // 唤醒:告诉正在等待的消费者,现在有货了
34 cv_cons.notify_one();
35
36 // 作用域结束,lock 自动析构并释放锁
37 }
38
39 // 消费者调用的出队函数
40 int cons() {
41 std::unique_lock<std::mutex> lock(mtx);
42
43 // 等待判断:如果队列空了,消费者阻塞并释放锁,直到生产者生产后唤醒
44 cv_cons.wait(lock, [this]() { return !queue.empty(); });
45
46 // 执行消费
47 int value = queue.front();
48 queue.pop();
49 std::cout << "Consumed: " << value << " | Queue size: " << queue.size() << std::endl;
50
51 // 通知:告诉正在等待的生产者,现在有空位了
52 cv_prod.notify_one();
53
54 return value;
55 }
56 };
57
58 // --- 测试代码 ---
59 void producer_task(ProducerConsumer& q, int id) {
60 for (int i = 0; i < 5; ++i) {
61 q.prod(id * 100 + i); // 生产数据
62 std::this_thread::sleep_for(std::chrono::milliseconds(100)); // 模拟生产耗时
63 }
64 }
65
66 void consumer_task(ProducerConsumer& q) {
67 for (int i = 0; i < 10; ++i) {
68 q.cons(); // 消费数据
69 std::this_thread::sleep_for(std::chrono::milliseconds(150)); // 模拟消费耗时
70 }
71 }
72
73 int main() {
74 ProducerConsumer q(5); // 缓冲区容量为 3
75
76 // 开启 2 个生产者线程和 1 个消费者线程
77 std::thread p1(producer_task, std::ref(q), 1);
78 std::thread p2(producer_task, std::ref(q), 2);
79 std::thread c1(consumer_task, std::ref(q));
80
81 p1.join();
82 p2.join();
83 c1.join();
84
85 return 0;
86 }
wait-notify之间做了什么
释放锁并进入等待(原子性阶段)
当你调用 cv.wait(lock) 时,底层会立即执行以下操作:
- 释放锁:自动释放当前线程持有的
std::unique_lock<std::mutex>。 - 加入队列:将当前线程放入该条件变量的等待队列中。
- 进入休眠:挂起当前线程,不再消耗 CPU 资源。
核心细节:释放锁和进入等待这两个动作是原子性的。这意味着不会出现“刚释放锁,还没进入等待队列,通知就来了”的情况(即错失信号)。
被唤醒并尝试重新获取锁
当另一个线程调用 cv.notify_one() 或 cv.notify_all() 时:
- 唤醒:操作系统将线程从等待队列中移出,状态变为“就绪”。
- 重新抢锁:线程在
wait内部尝试重新获取(acquire)之前释放的那个mutex。 - 阻塞等待锁:如果锁此时被其他线程持有(比如通知者还没释放锁),被唤醒的线程会停在
wait内部,直到它抢到了锁。
返回阶段
只有当成功重新持有锁后,cv.wait(lock) 才会结束阻塞并返回。此时,你的线程恢复了对共享资源的独占访问权限。
信号丢失&虚假唤醒
信号丢失:A发送信号唤醒B,A已经发送信号,但是B还没进入等待,就会倒是B收不到A的信号,这个信号就丢失了。
虚假唤醒:感官上是程序中没有调用notify,唤醒某些处于阻塞的线程。
- 如何解决
在调用wait前检查条件,生产者只有在队列满的情况下阻塞;消费者在队列空的情况下阻塞;
使用if检查条件可以避免信号丢失。使用while检查变量可以解决信号丢失和虚假唤醒。
为什么 if 可以防止信号丢失?
信号丢失(Lost Wake-up) 发生在:生产者发出了“队列已满”的信号,但消费者此时并没有在等待,或者生产者在消费者还没来得及进入 wait 状态时就发送notify。
- 检查条件的必要性: 在调用
wait()之前 检查条件(无论是if还是while),本质上是为了确认当前是否真的需要阻塞。 - 逻辑: 消费者进入临界区后,先看一眼队列。如果队列不为空,它直接拿走数据,根本不调用
wait()。这样即使生产者之前发过信号,消费者也已经处理了数据,不会因为错过信号而死锁。
为什么 while 是金标准?
使用 while 循环检查条件被称为 "Mesa-style monitoring"。它的逻辑是:被唤醒后,必须再次检查条件。
使用while检查状态等效于 cv.wait(unique_lock(mutex),pred)
// 伪代码:cv.wait(lock, pred) 的等效实现
while (!pred()) {
wait(lock);
}
线程局部存储
thread_local 每一个线程都是独立的副本变量,线程销毁时临时变量销毁。
truct ThreadContext {
int thread_id;
std::string name;
std::vector<int> local_data;
ThreadContext() : thread_id(0) {
std::cout << "构造线程局部结构体" << std::endl;
}
~ThreadContext() {
std::cout << "析构线程局部结构体,线程ID: " << thread_id << std::endl;
}
};
// C++11 thread_local
thread_local ThreadContext ctx;
如何调试
gdb命令
## 编译生成 加-g
g++ -g test.cpp test -pthread
## 帮助
help /h
## 启动调试
gdb test
## 查看代码
list
## 运行
run /r 运行到第一个断点
start 运行到第一行执行程序
## 打断点
break / b 行号/函数名
## 查看所有断点
info b
info breakpoints
## 执行
next / n 下一步 不进函数 逐过程
step / s 下一步 进函数 逐语句
continute /c 跳转下一个断点
finish 结束当前函数
info 查看函数局部变量的值
## 退出
quit /q
## 输出
print / p 变量
p m_vector
p m_map
p *(m_vector._M_impl._start_)@m_vector.size()
display 追踪具体变量值
undisplay 取消追踪
watch 设置观察点 变量修改时打印显示
# x 查看内存
## 查看所有进程
info thread
## 跳转进程
thread i
## 打印调用独占
bt
## 打印所有线程的调用堆栈
thread apply all bt
## 生成日志文件,开启日志模式
set logging on # 日志功能开启
## 观察点 watchpoint
watch
set scheduler-locking on #锁定调度。设置后,当你 next 时,只有当前线程运行,其他线程暂停。防止你在调试 A 线程时,B 线程也在跑,导致输出混乱。
# 查找线程id
ps -ef | grep hello
gdb hello -p pid
- set scheduler-locking on/step/off
| 模式 | 命令 | 行为 |
|---|---|---|
| off (默认) | set scheduler-locking off |
所有线程自由运行,GDB可能在任何线程停止时切换 |
| step | set scheduler-locking step |
单步执行时锁定当前线程,其他情况不锁定 |
| on | set scheduler-locking on |
只运行当前线程,其他线程被冻结 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号