

02 Spark架构与运行流程
1. 为什么要引入Yarn和Spark。
yarn是作业调度和集群资源管理的一个框架,从一定程度上溺化了多计算框架的优劣之争,解决了扩展性差,单点故障以及只能局限于MR计算框架等的问题。在MapReduce时代,很多人评论MapReduce不适合迭代计算和流失计算,于是出现了Spark和Storm等计算框架。MapReduce是运行在Yarn之上的一类应用程序抽象,Spark和Strom本质上也是,他们只是针对不同类型的应用开发的,没有优劣之别,各有所长,合并共处。
2. Spark已打造出结构一体化、功能多样化的大数据生态系统,请简述Spark生态系统。
Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算。Spark不仅支持Scala编写应用程序,而且支持Java和Python等语言进行编写,特别是Scala是一种高效、可拓展的语言,能够用简洁的代码处理较为复杂的处理工作。Spark具有很强的适应性,能够读取HDFS、Cassandra、HBase、S3和Techyon为持久层读写原生数据,能够以Mesos、YARN和自身携带的Standalone作为资源管理器调度job,来完成Spark应用程序的计算。
3. 用图文描述你所理解的Spark运行架构,运行流程。
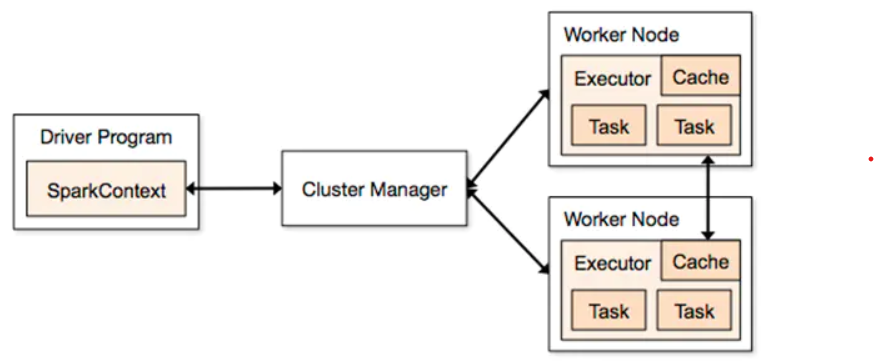
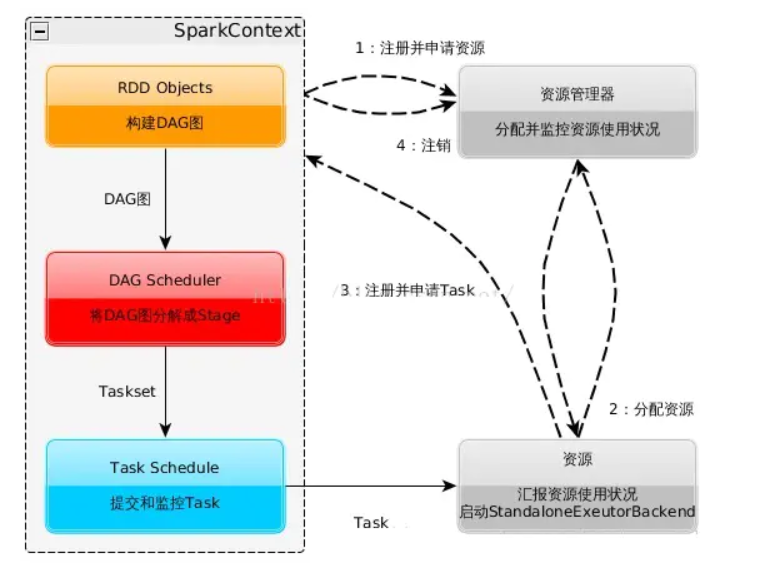
名词解释:
1.parkContext:创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中有SparkContext负责与ClusterManager通信,进行资源申请、任务的分配和监控等,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭,通常用SparkContext代表Driver(SparkContext也是我们对Spark编程的核心入口)
2.Executor: 某个Application运行在worker节点上的一个进程, 该进程负责运行某些Task, 并且负责将数据存到内存或磁盘上,每个Application都有各自独立的一批Executor, 在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutor Backend。一个CoarseGrainedExecutor Backend有且仅有一个Executor对象, 负责将Task包装成taskRunner,并从线程池中抽取一个空闲线程运行Task, 这个每一个CoarseGrainedExecutor Backend能并行运行Task的数量取决与分配给它的cpu个数
3.Cluster Manager:指的是在集群上获取资源的外部服务。目前有三种类型
Standalon : spark原生的资源管理,由Master负责资源的分配
Apache Mesos:与hadoop MR兼容性良好的一种资源调度框架
Hadoop Yarn: 主要是指Yarn中的ResourceManager

 浙公网安备 33010602011771号
浙公网安备 33010602011771号