

大数据概述
1.用图表描述Hadoop生态系统的各个组件及其关系。
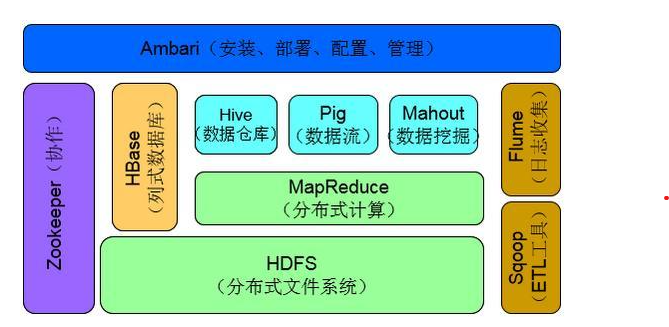
2.阐述Hadoop生态系统中,HDFS, MapReduce, Yarn, Hbase及Spark的相互关系。
HDFS
HDFS是Hadoop体系中数据存储管理的基础,它是一个高度容错的系统,能检测和应对硬件故障,在低成本的通用硬件上运行。HDFS简化了文件的一次性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适用带有数据集的应用程序。HDFS提供一次写入多次读取的机制,数据以块的形式,同时分布存储在不同的物理机器上。
MapReduce
MapReduce是第一代计算引擎。MapReduce是一种分布式计算模型,用以进行海量数据的计算。它屏蔽了分布式计算框架细节,将计算抽象成Map 和Reduce两部分,其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce非常适合在大量计算机组成的分布式并行环境里进行数据处理。
Yarn
Yarn它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
HBase
Hbase(分布式列存数据库)源自Google的BigTable论文,发表于2006年11月,HBase是Google Table的实现。HBase是一个建立在HDFS之上,面向结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。HBase采用了BigTable的数据模型,即增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起
Spark
Tez和Spark是第二代计算引擎。除了内存 Cache 之类的新 feature,本质上来说,是让 Map/Reduce 模型更通用,让 Map 和 Reduce 之间的界限更模糊,数据交换更灵活,更少的磁盘读写,以便更方便地描述复杂算法,取得更高的吞吐量。
有了 MapReduce之后,程序员发现,MapReduce 的程序写起来真麻烦。之前的 Map Reduce 类似于汇编语言,那么现在的 spark 就类似于 python 了,功能和 Map Reduce 类似,但是对于开发人员更加的友好,更方便使用。
MapRedcue先于Spark出现,也曾风骚一时。当初MapReduce选择磁盘,除了要保证数据存储安全之外,另一个主要原因是大容量内存的价格高昂,如果一开始就选择基于内存的解决方案,可能很难推广。而Spark的出现赶上了好时候,中大型公司有能力部署多台大内存机器,可以直接处理线上数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号