Seed Lab实验:Secret-Key Encryption
SEEDLAB Secret-Key Encryption
Task1.用频率分析破解单表代换密码。
在ctf中遇到这种简单的单表代换密码常用quipqiup快速解密,但这里为了实验目的,因此手动推理一次。
先用python统计字频,分别统计单个字母,两个、三个连续字母出现的频次。
from collections import Counter
import re
def read_file(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
# 使用正则表达式移除非字母字符,并转换为小写以简化统计
return re.sub(r'[^a-zA-Z]', '', content).lower()
def count_ngrams(text, n=1):
ngrams = [text[i:i+n] for i in range(len(text)-n+1)]
return Counter(ngrams)
def main():
file_path = './ciphertext.txt'
text = read_file(file_path)
# 单个字母的统计
letter_counts = count_ngrams(text, 1)
# 双字母组合的统计
digram_counts = count_ngrams(text, 2)
# 三字母组合的统计
trigram_counts = count_ngrams(text, 3)
# 输出统计结果
print("Letter frequencies:")
for letter, count in letter_counts.most_common():
print(f"{letter}: {count}")
print("\nDigram frequencies:")
for digram, count in digram_counts.most_common():
print(f"{digram}: {count}")
print("\nTrigram frequencies:")
for trigram, count in trigram_counts.most_common():
print(f"{trigram}: {count}")
if __name__ == '__main__':
main()
如下所示:
Letter frequencies:
n: 488 y: 373 v: 348 x: 291 u: 280 q: 276 m: 264 h: 235 t: 183 i: 166 p: 156 a: 116 c: 104 z: 95 l: 90 g: 83 b: 83 r: 82 e: 76 d: 59 f: 49 s: 19 k: 5 j: 5 o: 4 w: 1
Digram frequencies:
yt: 116 tn: 89 mu: 74 nh: 66 nq: 62 hn: 59 vu: 58 vh: 57 qy: 55 xu: 53 nv: 50 up: 47 yn: 47 np: 46 vy: 45 xh: 45 nu: 44 ym: 39 uy: 37 vi: 37 yx: 36 vq: 35 uv: 34 my: 32 gn: 32 av: 31 xz: 30 ur: 29 tv: 29 na: 29 qn: 28 uq: 27 qv: 27 mq: 27 hq: 26
Trigram frequencies:
ytn: 79 vup: 30 nqy: 22 pyt: 20 mur: 20 ynh: 18 xzy: 16 nhn: 16 nuy: 14 mxu: 14 ytv: 14 gnq: 14 bxh: 14 vii: 13 vyn: 13 tmq: 12 lvq: 12 uvy: 12 qyt: 12 nvh: 12 tnv: 11 muv: 11 vym: 11 upy: 11
因此,能推断出ytn应当对应的是the。
然后观察密文,发现v总是单个出现,且频率特别高,因此猜测v是a

然后结合vup总是三个结合出现、v是a、vu有时单独出现且出现次数比vup多、vup出现的频率特别高,猜测vup是and

tr 'ytnvup' 'THEAND' < ciphertext.txt > answer.txt
这里注意可以用大小写区分是否已经解密
发现这时候文章结尾最后一个词是gETlEEN,易得g是b,l是w(理论上也可以去词库比对,找到相似度最高的词)
tr 'ytnvupgl' 'THEANDBW' < ciphertext.txt > answer.txt
以此类推。。。
tr 'ytnvupglbhmaxrqiezjcdsfwko' 'THEANDBWFRICOGSLPUQMYKVZXJ' < ciphertext.txt > answer.txt
得出结果(转成小写)
the oscars turn on sunday which seems about right after this long strange
awards trip the bagger feels like a nonagenarian too
the awards race was bookeneded by the demise of harvey weinstein at its outset
and the apparent implosion of his film company at the end and it was shaped by
the emergence of metoo times up blackgown politics armcandy activism and
a national conversation as brief and mad as a fever dream about whether there
ought to be a president winfrey the season didnt just seem extra long it was
extra long because the oscars were moved to the first weekend in march to
avoid conflicting with the closing ceremony of the winter olympics thanks
pyeongchang
one big question surrounding this years academy awards is how or if the
ceremony will address metoo especially after the golden globes which became
a jubilant comingout party for times up the movement spearheaded by
powerful hollywood women who helped raise millions of dollars to fight sexual
harassment around the country
signaling their support golden globes attendees swathed themselves in black
sported lapel pins and sounded off about sexist power imbalances from the red
carpet and the stage on the air e was called out about pay inequity after
its former anchor catt sadler quit once she learned that she was making far
less than a male cohost and during the ceremony natalie portman took a blunt
and satisfying dig at the allmale roster of nominated directors how could
that be topped
as it turns out at least in terms of the oscars it probably wont be
women involved in times up said that although the globes signified the
initiatives launch they never intended it to be just an awards season
campaign or one that became associated only with redcarpet actions instead
a spokeswoman said the group is working behind closed doors and has since
amassed million for its legal defense fund which after the globes was
flooded with thousands of donations of or less from people in some
countries
no call to wear black gowns went out in advance of the oscars though the
movement will almost certainly be referenced before and during the ceremony
especially since vocal metoo supporters like ashley judd laura dern and
nicole kidman are scheduled presenters
another feature of this season no one really knows who is going to win best
picture arguably this happens a lot of the time inarguably the nailbiter
narrative only serves the awards hype machine but often the people forecasting
the race so-called oscarologists can make only educated guesses
the way the academy tabulates the big winner doesnt help in every other
category the nominee with the most votes wins but in the best picture
category voters are asked to list their top movies in preferential order if a
movie gets more than percent of the firstplace votes it wins when no
movie manages that the one with the fewest firstplace votes is eliminated and
its votes are redistributed to the movies that garnered the eliminated ballots
secondplace votes and this continues until a winner emerges
it is all terribly confusing but apparently the consensus favorite comes out
ahead in the end this means that endofseason awards chatter invariably
involves tortured speculation about which film would most likely be voters
second or third favorite and then equally tortured conclusions about which
film might prevail
in it was a tossup between boyhood and the eventual winner birdman
in with lots of experts betting on the revenant or the big short the
prize went to spotlight last year nearly all the forecasters declared la
la land the presumptive winner and for two and a half minutes they were
correct before an envelope snafu was revealed and the rightful winner
moonlight was crowned
this year awards watchers are unequally divided between three billboards
outside ebbing missouri the favorite and the shape of water which is
the baggers prediction with a few forecasting a hail mary win for get out
but all of those films have historical oscarvoting patterns against them the
shape of water has nominations more than any other film and was also
named the years best by the producers and directors guilds yet it was not
nominated for a screen actors guild award for best ensemble and no film has
won best picture without previously landing at least the actors nomination
since braveheart in this year the best ensemble sag ended up going to
three billboards which is significant because actors make up the academys
largest branch that film while divisive also won the best drama golden globe
and the bafta but its filmmaker martin mcdonagh was not nominated for best
director and apart from argo movies that land best picture without also
earning best director nominations are few and far between
也可以直接用大数据统计的每个字母出现频率进行分析,然后手动微调。
Task2.用AES加密算法(128位密钥,CBC模式)加密一个文件并进行解密。
使用openssl
openssl enc -aes-128-cbc -e -in ./plaintext.txt -out cipher.bin -K 00112233445566778889aabbccddeeff -iv 0102030405060708
openssl enc -aes-128-cbc -d -in cipher.bin -out out.txt -K 00112233445566778889aabbccddeeff -iv 0102030405060708
-aes-128-cbc 指定使用的加密算法为AES-128位,在CBC(Cipher Block Chaining,密文链接模式)模式下工作。CBC是一种常见的块加密模式,它确保相同的明文块在不同消息中加密后产生不同的密文块,从而增加安全性。
-e: 表示进行加密操作。
-in ./plaintext.txt: 指定输入文件,即要被加密的明文文件。
-out cipher.bin: 指定输出文件,即加密后的密文将被保存到这个文件中。
-K 00112233445566778889aabbccddeeff: 指定用于加密的密钥。这里是一个128位(16字节)的密钥,以十六进制形式表示。
-iv 0102030405060708: 指定初始化向量(Initialization Vector,IV)。IV是CBC模式中一个重要的参数,用于保证相同的数据使用相同的密钥加密会产生不同的密文,增强安全性。这里使用的是一个8字节的值,但需要注意,对于AES-128-CBC,IV应该是16字节长。
-d`: 表示进行解密操作。
Task 3.用AES加密算法(128位密钥),分别采用ECB和CBC模式加密一个bmp图片,查看加密后的图片。
openssl enc -aes-128-ecb -in ./pic_original.bmp -out ./pic_ecb.bmp -e -K 00112233445566778889aabbccddeeff
openssl enc -aes-128-cbc -in ./pic_original.bmp -out ./pic_cbc.bmp -e -K 00112233445566778889aabbccddeeff -iv 0102030405060708

加密后无法打开,这是因为文件头也被加密了
使用winhex打开:
原来的文件头:

把加密后的文件头修改回原来的文件头
原图片:

ECB加密:

CBC加密:

ECB加密:将数据按照8个字节一段进行DES加密或解密得到一段段的8个字节的密文或者明文,各段数据之间互不影响。
CBC加密:首先将数据按照8个字节一组进行分组得到D1D2…Dn(若数据不是8的整数倍,用指定的PADDING数据补位),第一组数据D1与初始化向量I异或后的结果进行DES加密得到第一组密文C1(初始化向量I为全零),第二组数据D2与第一组的加密结果C1异或以后的结果进行DES加密,得到第二组密文C2,之后的数据以此类推,得到Cn,按顺序连为C1C2C3…Cn即为加密结果。
因此,ECB加密后还是能看得出原图片的一些特征,而CBC加密则不能看出。
Task 4.Padding:
(1)分别创建大小为5,10,15字节的文件;
echo -n "12345" > p5.txt
echo -n "1234567890" > p10.txt
echo -n "123456789012345" > p15.txt
ls -l p5.txt p10.txt p15.txt

(2)先用AES加密算法(128位密钥,CBC模式)加密这些文件,然后解密这些密文(选择解密时不去除padding的选项),观察解密后各个文件的尺寸大小;
openssl enc -aes-128-cbc -e -in p5.txt -out c5.txt -k 00112233445566778899AABBCCDDEEFF -iv 000102030405060708090a0b0c0d0e0f
openssl enc -aes-128-cbc -e -in p10.txt -out c10.txt -k 00112233445566778899AABBCCDDEEFF -iv 000102030405060708090a0b0c0d0e0f
openssl enc -aes-128-cbc -e -in p15.txt -out c15.txt -k 00112233445566778899AABBCCDDEEFF -iv 000102030405060708090a0b0c0d0e0f
ls -l c5.txt c10.txt c15.txt
解密
openssl enc -aes-128-cbc -d -in c5.txt -out CBC5.txt -k 00112233445566778899AABBCCDDEEFF -iv 000102030405060708090a0b0c0d0e0f -nopad
openssl enc -aes-128-cbc -d -in c10.txt -out CBC10.txt -k 00112233445566778899AABBCCDDEEFF -iv 000102030405060708090a0b0c0d0e0f -nopad
openssl enc -aes-128-cbc -d -in c15.txt -out CBC15.txt -k 00112233445566778899AABBCCDDEEFF -iv 000102030405060708090a0b0c0d0e0f -nopad
ls -l CBC5.txt CBC10.txt CBC15.txt

(3)用xxd命令查看各个解密文件中padding的内容;
xxd CBC5.txt
xxd CBC10.txt
xxd CBC15.txt

(4)用AES加密算法(128位密钥,ECB模式,CFB模式,OFB模式)进行类似上述(2)和(3)的操作,查看各个解密文件中padding的内容。
ECB:
openssl enc -aes-128-ecb -e -in p5.txt -out cECB5.txt -k 00112233445566778899AABBCCDDEEFF
openssl enc -aes-128-ecb -e -in p10.txt -out cECB10.txt -k 00112233445566778899AABBCCDDEEFF
openssl enc -aes-128-ecb -e -in p15.txt -out cECB15.txt -k 00112233445566778899AABBCCDDEEFF
openssl enc -aes-128-ECB -d -in cECB5.txt -out ECB5.txt -k 00112233445566778899AABBCCDDEEFF -nopad
openssl enc -aes-128-ECB -d -in cECB10.txt -out ECB10.txt -k 00112233445566778899AABBCCDDEEFF -nopad
openssl enc -aes-128-ECB -d -in cECB15.txt -out ECB15.txt -k 00112233445566778899AABBCCDDEEFF -nopad
ls -l CBC5.txt CBC10.txt CBC15.txt
xxd ECB5.txt
xxd ECB10.txt
xxd ECB15.txt
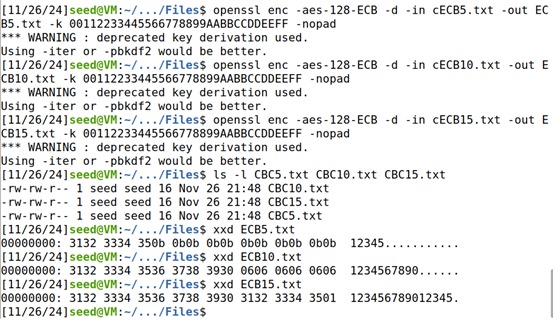
CFB:
openssl enc -aes-128-cfb -e -in p5.txt -out cCFB5.txt -k 00112233445566778899AABBCCDDEEFF -iv 000102030405060708090a0b0c0d0e0f
openssl enc -aes-128-cfb -e -in p10.txt -out cCFB10.txt -k 00112233445566778899AABBCCDDEEFF -iv 000102030405060708090a0b0c0d0e0f
openssl enc -aes-128-cfb -e -in p15.txt -out cCFB15.txt -k 00112233445566778899AABBCCDDEEFF -iv 000102030405060708090a0b0c0d0e0f
openssl enc -aes-128-cfb -d -in cCFB5.txt -out CFB5.txt -k 00112233445566778899AABBCCDDEEFF -iv 000102030405060708090a0b0c0d0e0f -nopad
openssl enc -aes-128-cfb -d -in cCFB10.txt -out CFB10.txt -k 00112233445566778899AABBCCDDEEFF -iv 000102030405060708090a0b0c0d0e0f -nopad
openssl enc -aes-128-cfb -d -in cCFB15.txt -out CFB15.txt -k 00112233445566778899AABBCCDDEEFF -iv 000102030405060708090a0b0c0d0e0f -nopad
ls -l CFB5.txt CFB10.txt CFB15.txt
xxd CFB5.txt
xxd CFB10.txt
xxd CFB15.txt
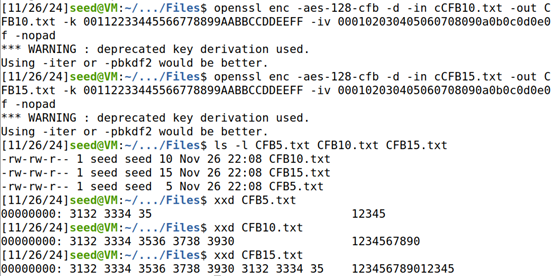
OFB:
openssl enc -aes-128-ofb -e -in p5.txt -out cOFB5.txt -k 00112233445566778899AABBCCDDEEFF -iv 000102030405060708090a0b0c0d0e0f
openssl enc -aes-128-ofb -e -in p10.txt -out cOFB10.txt -k 00112233445566778899AABBCCDDEEFF -iv 000102030405060708090a0b0c0d0e0f
openssl enc -aes-128-ofb -e -in p15.txt -out cOFB15.txt -k 00112233445566778899AABBCCDDEEFF -iv 000102030405060708090a0b0c0d0e0f
openssl enc -aes-128-ofb -d -in cOFB5.txt -out OFB5.txt -k 00112233445566778899AABBCCDDEEFF -iv 000102030405060708090a0b0c0d0e0f -nopad
openssl enc -aes-128-ofb -d -in cOFB10.txt -out OFB10.txt -k 00112233445566778899AABBCCDDEEFF -iv 000102030405060708090a0b0c0d0e0f -nopad
openssl enc -aes-128-ofb -d -in cOFB15.txt -out OFB15.txt -k 00112233445566778899AABBCCDDEEFF -iv 000102030405060708090a0b0c0d0e0f -nopad
ls -l OFB5.txt OFB10.txt OFB15.txt
xxd OFB5.txt
xxd OFB10.txt
xxd OFB15.txt
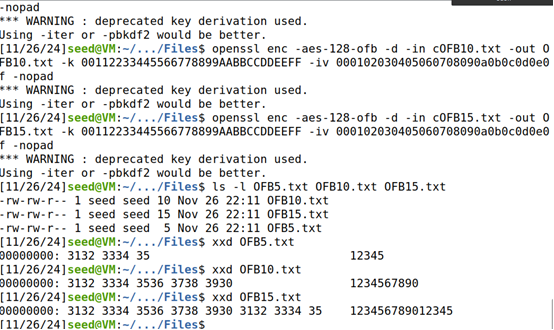
总结:
ECB、CBC都有填充:因为ECB和CBC每次加密都是对于一整块分组,因此必须填充满最后一个分组。填充规则为填充至明文长度为分组长度的整数倍,且当填充前明文长度已经是分组长度整数倍时填充一个分组长度。填充的每一个字节的内容都表示填充的字节长度。
CFB、OFB没有填充:因为CFB、OFB是流密码,每个分组中都是一位一位加密的,因此不需要填充。
Task 5.密文的错误传递
(1)创建一个至少1000字节大的文本文件;
sequence = "0123456789"
with open("1000bytetxt.txt", "w") as f:
for i in range(100):
f.write(sequence)
(2)用AES加密算法(128位密钥,ECB模式)加密这个文件;
openssl enc -aes-128-ecb -e -in 1000bytetxt.txt -out 1000bytetxtcECB.txt -K 00112233445566778889aabbccddeeff
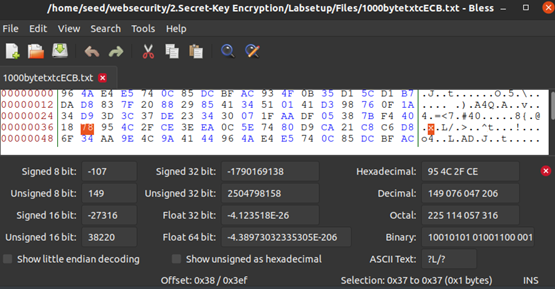
(3)用bless工具修改密文中第55个字节中的1个bit;
bless 1000bytetxtcECB.txt
若为奇数-1 若为偶数+1 这样才能只修改一个比特
(4)解密被上述修改后的密文,查看解密后的明文有什么变化;
openssl enc -aes-128-ecb -d -in 1000bytetxtcECB.txt -out 1000bytetxtECB.txt -K 00112233445566778889aabbccddeeff
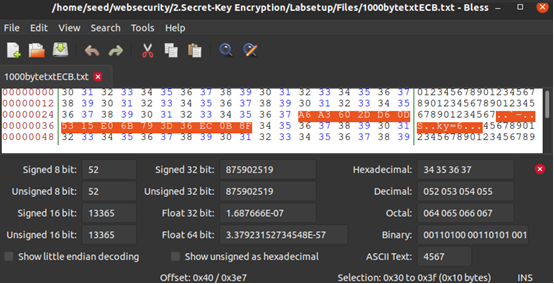
丢失了16字节信息。
(5)用AES加密算法(128位密钥,CBC模式,OFB模式)进行类似上述(2)-(4)的操作,查看对应解密后的明文有什么变化。
| 加密算法 | 损失信息 | 损失原因 |
|---|---|---|
| ECB | 16byte | 损失了修改字节所在的一整个块 |
| CBC | 16byte | 损失了一个分组(最多损失两个分组) |
| OFB | 1bit | 流密码 |
Task 6.初始化向量(IV)
6.1 IV的唯一性
(1)用AES加密算法(128位密钥,CBC模式),采用相同的密钥和不同的初始化向量加密一个相同的文件,观察加密结果是否相同;
创建ivplain.txt,在里面输入 hello world!
加密
openssl enc -aes-128-cbc -e -in ivplain.txt -out ivcipher.txt \
-k 00112233445566778899AABBCCDDEEFF \
-iv 000102030405060708090a0b0c0d0e0f \
-nosalt

使用不同的初始化向量加密:
openssl enc -aes-128-cbc -e -in ivplain.txt -out ivdiffercipher.txt \
-k 00112233445566778899AABBCCDDEEFF \
-iv 000102030405060708090a0b0c0d0e0e \
-nosalt

不同的初始化向量加密后不同
(2)用AES加密算法(128位密钥,CBC模式),采用相同的密钥和相同的初始化向量加密一个相同的文件,观察加密结果是否相同;
openssl enc -aes-128-cbc -e -in ivplain.txt -out ivsamecipher.txt \
-k 00112233445566778899AABBCCDDEEFF \
-iv 000102030405060708090a0b0c0d0e0f \
-nosalt

相同的初始化向量加密后相同
(3)思考为什么IV必须唯一。
对CBC模式来说,IV在加密时影响所有块,但解密时只影响第一块。第一块往往是文件的头部,记录了文件内容等信息。如果重复使用IV,会导致可以采用碰撞攻击,从而获得IV,因此IV必须唯一。
6.2 已知明文攻击:假设采用OFB模式进行加密,加密时所采用的IV是相同的,请破译P2的内容
修改sample_code.py:
#!/usr/bin/python3
# XOR two bytearrays
def xor(first, second):
return bytearray(x^y for x,y in zip(first, second))
MSG = "This is a known message!"
HEX_1 = "a469b1c502c1cab966965e50425438e1bb1b5f9037a4c159"
HEX_2 = "bf73bcd3509299d566c35b5d450337e1bb175f903fafc159"
# Convert ascii string to bytearray
D1 = bytes(MSG, 'utf-8')
# Convert hex string to bytearray
D2 = bytearray.fromhex(HEX_1)
D3 = bytearray.fromhex(HEX_2)
r1 = xor(D1, D2)
r2 = xor(r1, D3)
print(r2.decode('utf-8'))

6.3 选择密文攻击:请确定密文C1对应的明文内容是“Yes”还是“No”。
打开docker
docker-compose build
docker-compose up
nc 10.9.0.80 3000
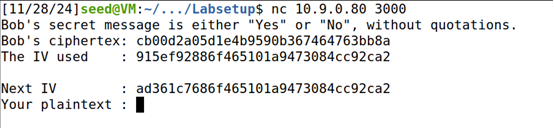
已知:
构造代码如下:
# XOR two bytearrays
def xor(first, second):
return bytearray(x^y for x,y in zip(first, second))
# 填充
YES = b"Yes" + bytes("\x0d"*13, 'utf-8')
NO = b"No" + bytes("\x0e"*14, 'utf-8')
IV1 = "915ef92886f465101a9473084cc92ca2"
IV2 = "ad361c7686f465101a9473084cc92ca2"
# 计算明文
r1 = xor(bytearray.fromhex(IV1), bytearray.fromhex(IV2))
r2 = xor(r1, YES)
r3 = xor(r1, NO)
print(r2.hex()) #猜测Yes构造的明文
print(r3.hex()) #猜测No构造的明文

650d96530d0d0d0d0d0d0d0d0d0d0d0d
7207eb500e0e0e0e0e0e0e0e0e0e0e0e
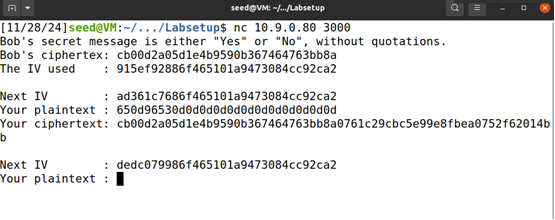
把构造Yes的明文输入,得到的密文的前24字节与Bob的密文相同,因此能猜测出Bob的明文是Yes。后面多出来的是对填充,即padding的加密,没有实际意义,不用管。
Task 7.基于Openssl的Crypto函数库编写程序破译密文所采用的加密密钥。
基本思路就是遍历words.txt,尝试爆破key
注意的点有:与word.txt比对时要记得去掉行尾换行符;解密后要去除PKCS7填充。
关于PKCS7:
PKCS7是当下各大加密算法都遵循的填充算法,且 OpenSSL 加密算法默认填充算法就是 PKCS7。PKCS7Padding的填充方式为当数据长度不足数据块长度时,缺几位补几个几,eg.对于AES128算法其数据块为16Byte(数据长度需要为16Byte的倍数),如果数据为”00112233445566778899AA”一共11个Byte,缺了5位,采用PKCS7Padding方式填充之后的数据为“00112233445566778899AA0505050505”。
特别注意的一点是如果是数据刚好满足数据块长度也要在元数据后在按PKCS7规则填充一个数据块数据,这样做的目的是为了区分有效数据和补齐数据。仍以AES128为例:如果数据为”00112233445566778899AABBCCDDEEFF”一共16个符合数据块规则采用PKCS7Padding方式填充之后的数据为“00112233445566778899AABBCCDDEEFF10101010101010101010101010101010”。
发现key是Syracuse,即作者任职的雪城大学。
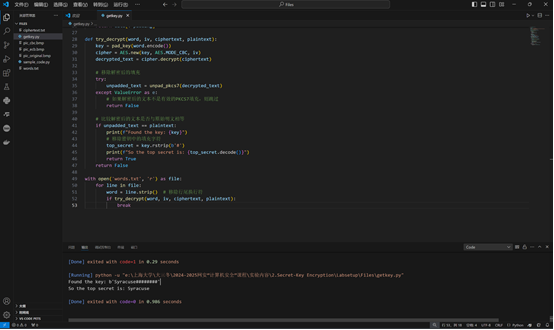
from Crypto.Cipher import AES
import binascii
# 已知信息
plaintext = b'This is a top secret.'
ciphertext_hex = '764aa26b55a4da654df6b19e4bce00f4ed05e09346fb0e762583cb7da2ac93a2'
iv_hex = 'aabbccddeeff00998877665544332211'
# 将十六进制字符串转换为字节
ciphertext = binascii.unhexlify(ciphertext_hex)
iv = binascii.unhexlify(iv_hex)
def pad_key(key):
# 确保密钥长度为16字节 (128 bits)
if len(key) > 16:
key = key[:16]
elif len(key) < 16:
key += b'#' * (16 - len(key))
return key
def unpad_pkcs7(data):
# 移除PKCS7填充
padding = data[-1]
if padding < 1 or padding > 16:
raise ValueError("Invalid padding")
return data[:-padding]
def try_decrypt(word, iv, ciphertext, plaintext):
key = pad_key(word.encode())
cipher = AES.new(key, AES.MODE_CBC, iv)
decrypted_text = cipher.decrypt(ciphertext)
# 移除解密后的填充
try:
unpadded_text = unpad_pkcs7(decrypted_text)
except ValueError as e:
# 如果解密后的文本不是有效的PKCS7填充,则跳过
return False
# 比较解密后的文本是否与原始明文相等
if unpadded_text == plaintext:
print(f"Found the key: {key}")
# 移除密钥中的填充字符
top_secret = key.rstrip(b'#')
print(f"So the top secret is: {top_secret.decode()}")
return True
return False
with open('words.txt', 'r') as file:
for line in file:
word = line.strip() # 移除行尾换行符
if try_decrypt(word, iv, ciphertext, plaintext):
break

 浙公网安备 33010602011771号
浙公网安备 33010602011771号