隐马尔科夫模型 HMM(Hidden Markov Model)
本科阶段学了三四遍的HMM,机器学习课,自然语言处理课,中文信息处理课;如今学研究生的自然语言处理,又碰见了这个老熟人;
虽多次碰到,但总觉得一知半解,对其了解不够全面,借着这次的机会,我想要直接搞定这个大名鼎鼎的模型,也省着之后遇到再费心。
Outline
- 模型引入与背景介绍
- 从概率图讲起
- 贝叶斯网络、马尔科夫模型、马尔科夫过程、马尔科夫网络、条件随机场
- HMM的形式化表示
- Markov Model的形式化表示
- HMM的形式化表示
- HMM的两个基本假设
- HMM的三个基本问题
- Evalution
- Learning
- Decoding
- 案例
Notes
一、 模型引入与背景介绍
1.1 从概率图讲起
在面对一个复杂问题时,“图” 是一种有效的利器,它仅仅利用点和线就能表达实体之间复杂关联和约束,如果给关联实体的边附上概率,则它更能进一步的表达实体之间的强弱联系和逻辑关系。
具体到机器学习领域,概率图模型就是一套 用图来表示特征和类别、特征和特征、类别与类别之间依赖关系 的理论。它利用图来表示“与模型有关的变量的联合概率分布”,从本质上来说,它是一种生成式模型(generative model)。
在遇到一个实际问题时,概率图模型则用观测结点表示观测到的数据,用隐含结点表示潜在的知识,用边来描述知识与数据的相互关系,最后基于这样的关系图获得一个概率分布,很好的获得了隐藏在数据中的知识。
概率图中的点分为隐含结点和观测节点,边也分为有向边和无向边。根据边的不同,可将概率图模型分为贝叶斯网络和马尔科夫网络两大类。
而我们在介绍HMM之前,也将对其相关的概念进行梳理,方便进行区分。
1.2 贝叶斯网络、马尔科夫模型、马尔科夫过程、马尔科夫随机场、条件随机场
与马尔科夫相关的概念有许多,在之前的学习中,也都是零散的知识点,今天发掘到一条从概率图出发的逻辑链,很好的将这些知识整合到一起,大家从上到下依次阅读,应该就能明白了:
- 将随机变量作为结点,若两个随机变量不独立,则将二者连接一条边;若给定若干随机变量,则形成一个有向的概率图。
- 如果该网络是有向无环图,则这个网络称为贝叶斯网络。
- 如果这个图退化成线性链的方式,则得到马尔科夫模型;因为每个结点都是随机变量,将其看成各个时刻(或空间)的相关变化,以随机过程的视角,则可以看成是马尔科夫过程。若每个状态的转移都依赖于其之前的n个状态,则这个过程称为一个N阶马尔科夫过程。其中最典型的例子就是【n-gram中引入马尔科夫假设,即这个模型的每个状态都只依赖于之前的状态,它是N-1阶的马尔科夫过程】。
- 但马尔科夫模型不能很好地描述我们处理问题的模型,例如每天早上,我们都可以通过【行人穿衣服的多少】(观测状态)来判断今天【温度】(隐状态)是多少,这种含有未知参数的马尔科夫过程叫做隐马尔科夫模型(HMM)。
- 若上述网络是无向的,则是无向图模型,又称马尔科夫随机场或者马尔科夫网络。
- 如果在给定某些条件的前提下,研究这个马尔可夫随机场,则得到条件随机场(CRF)。注意:CRF利用的是马尔科夫随机场(无向图),而HMM的基础是贝叶斯网络(有向图),二者的基本问题相同,大致计算方法相似,但基本的理念是不同的。
- 如果使用条件随机场解决标注问题,并且进一步将条件随机场中的网络拓扑变成线性的,则得到线性链条件随机场。
二、Hidden Markov Model的形式化表示
在上文中,我们已经对相关概念进行了系统性的阐述,但我们仍需对其中的重点的概念进行进一步的阐释,在这一节中,我们将更进一步的审视马尔科夫模型 和 隐马模型。
2.1 马尔科夫模型的形式化表示
一个马尔可夫模型是一个三元组(S, Π, A),其中 S是状态的集合,Π是初始状态的概率, A是状态间的转移概率,其具体的含义将在HMM的形式化表示中进行介绍,在此仅用一个实例对此进行展示:
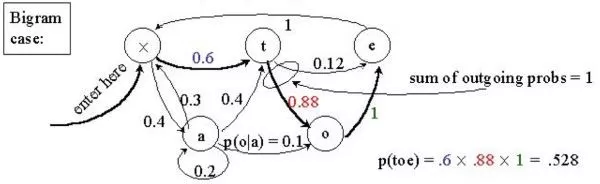
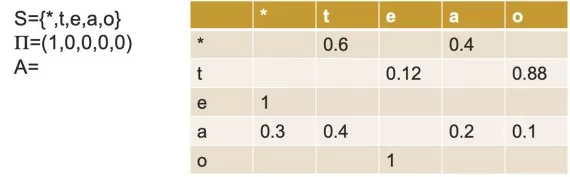
2.2 隐马尔科夫模型的形式化表示
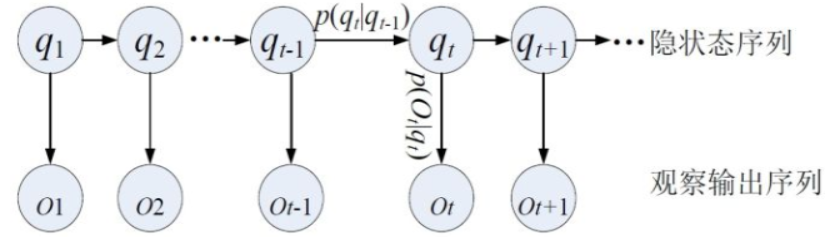
- 设 $\mathbb{Q}=\left\{\mathbf{q}_{1}, \mathbf{q}_{2}, \cdots, \mathbf{q}_{Q}\right\}$ 是所有可能的状态的集合,即状态变量的取值空间;$\mathbb{V}=\left\{\mathbf{v}_{1}, \mathbf{v}_{2}, \cdots, \mathbf{v}_{V}\right\}$ 是所有可能的观测的集合,即观测变量的取值空间。其中下标Q是可能的状态数量, 下标V是可能的观测数量,一般来说Q=V。
- 设$\mathbf{I}=\left(i_{1}, i_{2}, \cdots, i_{T}\right)$ 是长度为T的状态序列,$\mathbf{O}=\left(o_{1}, o_{2}, \cdots, o_{T}\right)$ 是对应的观测序列。
- $i_{t} \in\{1, \cdots, Q\}$是一个随机变量,代表状态变量$\mathbf{q}_{i_{t}}$
- $o_{t} \in\{1, \cdots, V\}$也是一个随机变量,代表观测变量$\mathbf{v}_{o_{t}}$
- 设$\mathbf{A}$为状态转移概率矩阵,
$\mathbf{A}=\left[\begin{array}{cccc}{a_{1,1}} & {a_{1,2}} & {\cdots} & {a_{1, Q}} \\ {a_{2,1}} & {a_{2,2}} & {\cdots} & {a_{2, Q}} \\ {\vdots} & {\vdots} & {\vdots} & {\vdots} \\ {a_{Q, 1}} & {a_{Q, 2}} & {\cdots} & {a_{Q, Q}}\end{array}\right]$
其中,$a_{i, j}=P\left(i_{t+1}=j | i_{t}=i\right)$,表示在时刻t处于$\mathbf{q}_{i}$状态的条件下,在t+1时刻转移到$\mathbf{q}_{j}$状态的概率。
- 设$\mathbf{B}$为发射矩阵,也称观测概率矩阵,
$\mathbf{B}=\left[\begin{array}{cccc}{b_{1}(1)} & {b_{1}(2)} & {\cdots} & {b_{1}(V)} \\ {b_{2}(1)} & {b_{2}(2)} & {\cdots} & {b_{2}(V)} \\ {\vdots} & {\vdots} & {\vdots} & {\vdots} \\ {b_{Q}(1)} & {b_{Q}(2)} & {\cdots} & {b_{Q}(V)}\end{array}\right]$
其中$b_{j}(k)=P\left(o_{t}=k | i_{t}=j\right)$,表示在时刻t处于$\mathbf{q}_{i}$状态的条件下,生成观测变量$\mathbf{v}_{k}$的概率。
- 设$\vec{\pi}=\left(\pi_{1}, \pi_{2}, \cdots, \pi_{Q}\right)^{T}$ 是初始状态概率分布,其中$\pi_{i}=P\left(i_{1}=i\right)$ 是$t=1$时状态处于$\mathbf{q}_{i}$的概率。
在定义了上述的内容后,我们可以形式化的定义一个HMM模型,即用一个五元组表示$\lambda=(\mathrm{Q}, \mathrm{V}, \mathrm{\Pi}, \mathrm{A}, \mathrm{B})$,其中,$\mathbf{A}, \mathbf{B}, \vec{\pi}$称为隐马尔科夫模型的三要素:
- 状态转移概率矩阵$\mathbf{A}$和初始状态概率向量$\vec{\pi}$确定了隐藏的马尔科夫链,生成不可预测的状态序列。
- 观测矩阵矩阵$\mathbf{B}$确定了如何从状态变量生成观测变量,并与状态序列$\mathbf{I}$一起确定了如何产生观测序列。
2.3 隐马尔科夫模型的链两个基本假设
- 齐次Markov假设,也叫有限历史假设,即假设隐藏的马尔可夫链在任意时刻的状态只依赖于它在前一时刻的状态,与其他状态和观测无关,即:
$P\left(i_{t} | i_{t-1}, o_{t-1}, \cdots, i_{1}, o_{1}\right)=P\left(i_{t} | i_{t-1}\right), \quad t=1,2, \cdots, T$
- 观测独立性假设,也称为时间不变性假设 ,即假设任意时刻的观测值只依赖于该时刻的隐状态,与其他观测及状态无关,即:
$P\left(o_{t} | i_{T}, o_{T}, \cdots, i_{t-1}, o_{t+1}, i_{t}, i_{t-1}, o_{t-1}, \cdots, i_{1}, o_{1}\right)=P\left(o_{t} | i_{t}\right), \quad t=1,2, \cdots, T$
三、隐马尔科夫的三个基本问题
- 概率计算问题,或称为评估问题(Evoluation):
- 给定模型$\lambda=(\mathrm{Q}, \mathrm{V}, \mathrm{\Pi}, \mathrm{A}, \mathrm{B})$和观测序列$\mathbf{O}=\left(o_{1}, o_{2}, \cdots, o_{T}\right)$,计算观测序列$\mathbf{O}$出现的概率$P(\mathbf{O} | \lambda)$
- 即使用前向算法,来评估模型$\lambda$ 与观测序列$\mathbf{O}$的匹配程度
- 例如:给定一个关于天气的隐马尔可夫模型,包括第一天的天气,天气转移概率矩阵,特定天气下树叶的湿度概率分布。求树叶第一天湿度为 1,第二天湿度为 2,第三天湿度为 3 的概率
- 模型构建问题,即学习问题(Learning):
- 已知观测序列$\mathbf{O}=\left(o_{1}, o_{2}, \cdots, o_{T}\right)$,评估获得 模型$\lambda=(\mathrm{Q}, \mathrm{V}, \mathrm{\Pi}, \mathrm{A}, \mathrm{B})$的参数,使在该模型下观测序列概率$P(\mathbf{O} ; \lambda)$最大。
- 即使用极大似然估计(EM算法)估计参数
- 例如:已知树叶第一天湿度为 1,第二天湿度为 2,第三天湿度为 3。求得一个天气的隐马尔可夫模型,包括第一天的天气,天气转移概率矩阵,特定天气下树叶的湿度概率分布。
- 隐状态求解问题,即解码问题(Decoding):
- 给定模型$\lambda=(\mathrm{Q}, \mathrm{V}, \mathrm{\Pi}, \mathrm{A}, \mathrm{B})$和观测序列$\mathbf{O}=\left(o_{1}, o_{2}, \cdots, o_{T}\right)$,求对给定的观测序列的条件概率$P(\mathbf{I} | \mathbf{O})$最大的状态变量序列$\mathbf{I}=\left(i_{1}, i_{2}, \cdots, i_{T}\right)$。
- 即给定观测序列,求最可能的对应的状态序列 。
- 例如:在语音识别任务中,观测值为语音信号,隐藏状态为文字。解码问题的目标就是:根据观测的语音信号来推断最有可能的文字序列。
四、Evolution
给定模型$\lambda=(\mathrm{Q}, \mathrm{V}, \mathrm{\Pi}, \mathrm{A}, \mathrm{B})$和观测序列$\mathbf{O}=\left(o_{1}, o_{2}, \cdots, o_{T}\right)$,计算观测序列$\mathbf{O}$出现的概率$P(\mathbf{O} | \lambda)$
4.1 Naive Approach
最直接的方法就是按照概率公式直接计算:通过列举所有可能的长度为T的在状态序列$\mathbf{I}=\left(i_{1}, i_{2}, \cdots, i_{T}\right)$,求各个状态序列$\mathbf{I}$与观测序列$\mathbf{O}=\left(o_{1}, o_{2}, \cdots, o_{T}\right)$的联合概率$P(\mathbf{O}, \mathbf{I} | \lambda)$,然后对所有可能的状态求和得到$P(\mathbf{O} | \lambda)$

上述的直接计算方法,时间复杂度太大,只在理论中可行,无法投入真正的使用
4.2 前向算法
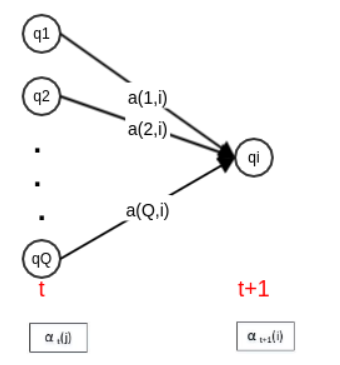
- 根据定义,$\alpha_{t}(j=P\left(o_{1}, o_{2}, \cdots, o_{t}, i_{t}=j | \lambda\right)$是在时刻$t$观察到$o_{1}, o_{2}, \cdots, o_{t}$,且隐状态为$q_{j}$的概率。
- 前向概率$\alpha_{t}(j)\times$状态转移概率$a_{j, i}$ ,则表示在观测变量不变的前提下,在时刻$t$的隐状态为$q_{j}$,且在时刻$t+1$的隐状态为$q_{i}$的概率。
- 而考虑所有Q个状态累加后,则可以消除$t$时刻的状态限制,得到$\sum_{j=1}^{Q} \alpha_{t}(j) \times a_{j, i}$,它表示在观测变量不变的前提下,在时刻$t+1$的隐状态为$q_{i}$的概率。
- 而结合$t+1$时刻的隐状态和发射概率$b_{i}\left(o_{t+1}\right)$,就得到了该时刻的观测值.由此构建$t+1$时刻的前向概率,可以得到递推公式为:
$\alpha_{t+1}(i)=\left[\sum_{j=1}^{Q} \alpha_{t}(j) a_{j, i}\right] b_{i}\left(o_{t+1}\right)$
由此,我们也就得到了前向算法的流程与描述:
- Input:
- 隐马尔科夫模型 $\lambda=(\mathrm{Q}, \mathrm{V}, \mathrm{\Pi}, \mathrm{A}, \mathrm{B})$
- 观测序列$\mathbf{O}=\left(o_{1}, o_{2}, \cdots, o_{T}\right)$
- Output:观测序列概率$P(\mathbf{O} | \lambda)$
- 算法步骤:
- 初始化: $\alpha_{1}(i)=\pi_{i} b_{i}\left(o_{1}\right), \quad i=1,2, \cdots, Q$,该初值是初始时刻的状态$i_{1}=i$和观测 $o_{1}$的联合概率。
- 根据递推公式递推:对于$t=1,2, \cdots, T-1$:$\alpha_{t+1}(i)=\left[\sum_{j=1}^{Q} \alpha_{t}(j) a_{j, i}\right] b_{i}\left(o_{t+1}\right), \quad i=1,2, \cdots, Q$
- 终止: $P(\mathbf{O} | \lambda)=\sum_{i=1}^{Q} \alpha_{T}(i)$,其中$\alpha_{T}(i)$表示在时刻T,观测序列为$o_{1}, o_{2}, \cdots, o_{T}$,且隐状态为$q_{i}$的概率;对所有可能的Q个状态求和,可以得到$P(\mathbf{O} | \lambda)$

 浙公网安备 33010602011771号
浙公网安备 33010602011771号