Hadoop基础-13-Hive实战
源码见:https://github.com/hiszm/hadoop-train
外部表在Hive中的使用
带有EXTERNAL关键字的就是外部表
不然一般都是内部表(managed_table)
CREATE EXTERNAL TABLE emp_external(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
LOCATION '/hive/emp_external';
| 内部表 | 外部表 |
|---|---|
| 内部表数据由Hive自身管理 | 外部表数据由HDFS管理; |
内部表数据存储的位置是hive.metastore.warehouse.dir(默认: /user/hive/warehouse), |
外部表数据的存储位置由自己制定(如果没有LOCATION,Hive将在 HDFS上的/user/hive/warehouse文件夹下以外部表的表名创建一个文件夹,并将属于这个表的数据存放在这里); |
删除内部表会直接删除元数据(metadata)及存储(HDFS)数据; |
删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除; |
| 对内部表的修改会将修改直接同步给元数据 | 而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;) |
track_info分区表的创建
Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大。
分区为 HDFS 上表目录的子目录,数据按照分区存储在子目录中。如果查询的 where 字句的中包含分区条件,则直接从该分区去查找,而不是扫描整个表目录,合理的分区设计可以极大提高查询速度和性能。
create external table trackinfo(
ip string,
country string,
province string,
city string,
url string,
time string,
page string
)partitioned by (day string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
location '/project/trackinfo';
将ETL的数据加载到Hive表
crontab表达式进行调度
Azkaban调度: ETLApp==>其它的统计分析
LOAD DATA INPATH 'hdfs://hadoop000:8020/project/input/etl/part-r-00000' OVERWRITE INTO TABLE trackinfo partition(day='2013-07-21');
[hadoop@hadoop000 data]$ hadoop fs -ls /project/trackinfo
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2020-09-09 22:45 /project/trackinfo/day=2013-07-21
[hadoop@hadoop000 data]$
使用Hive完成统计分析功能
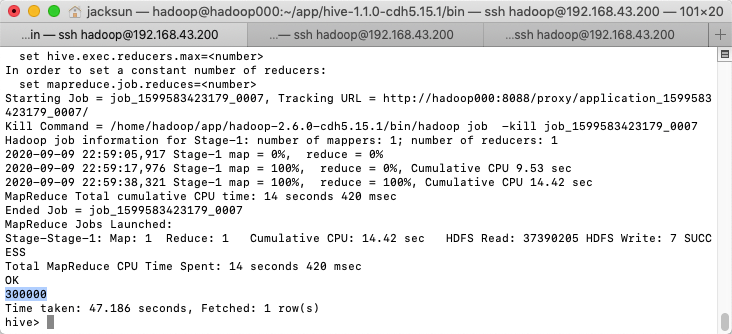
统计 pv
select count (*) from trackinfo where day ='2013-07-21';
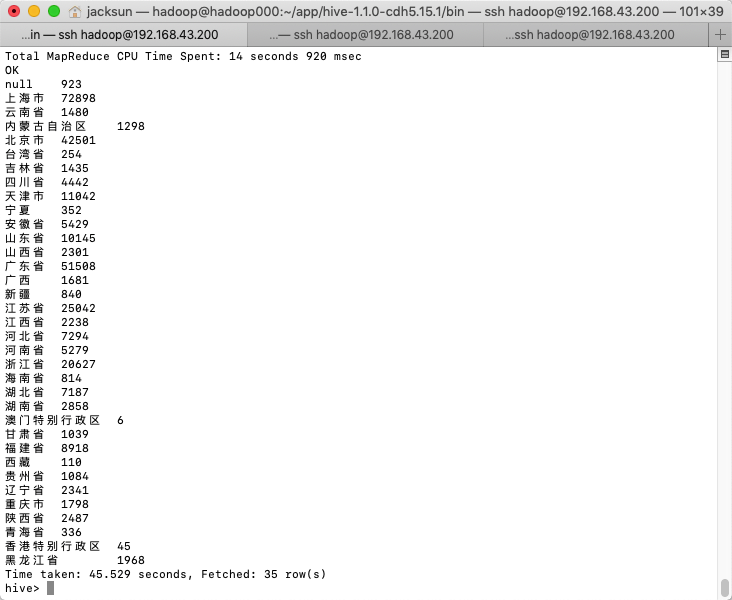
城市统计
select province , count (*) from trackinfo where day ='2013-07-21' group by province;
'
省份临时统计表
create external table trackinfo_province(
province string,
cnt bigint
)partitioned by (day string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
location '/project/trackinfo/province';
insert overwrite table trackinfo_province partition(day='2013-07-21')
select province , count (*) as cnt from trackinfo where day ='2013-07-21' group by province;
select * from trackinfo_province where day='2013-07-21';
然后用sqoop导入到RDMS里面
- ETL
- 将ETL加入到trackinfo里面
- 然后讲统计结果按照分区一次导入到各个表中
- 再把数据导入关系数据库里面
上述过程可以封装起来然后用crontab/Azkaban直接运行即可

|
🐳 作者:hiszm 📢 版权:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,万分感谢。 💬 留言:同时 , 如果文中有什么错误,欢迎指出。以免更多的人被误导。 |
 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号