
机器学习笔记 - 入门
前言
最近在学习吴恩达的机器学习课程。学习过程中经常忘记已经学习过的知识,需要重新观看视频或查阅资料进行复习。为了方便以后的复习,把一些自己认为重要的知识整理在博客上。
机器学习定义
Arthur Smauel在1959年给出的定义:
the field of study that gives computers the ability to learn without being explicitly programmed.
在没有明确设置的情况下,使计算机具有学习能力的研究领域。
Tom Mitchell在1998年给出的定义:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
上面定义的直译有点奇怪。大意就是,计算机程序通过学习以往的经验(数据)来提高解决任务的性能指标(准确率)。
机器学习类别
- 监督学习(Supervised learning):
用带有标签的数据进行训练。识别垃圾邮件、识别手写数字等可用这类算法建立模型。常见的算法有逻辑回归和反向传播神经网络。
- 无监督学习(Unsupervised learning):
用无标签数据训练。最典型的应用就是聚簇(Clustering),将相似的数据分为一组。常见算法是K-Means。
- 半监督学习(Semi-Supervised Learning):
使用有标签和无标签的数据进行训练。先用无标签数据进行建模,再此基础上对有标签数据进行预测调整模型准确性。
- 强化学习(Reinforcement):
强化学习就是智能系统从环境到行为映射的学习,以使奖励信号最大。如果Agent的某个行为策略导致环境正的奖赏(强化信号),那么Agent以后产生这个行为策略的趋势便会加强。
常用概念
1、要进行机器学习的训练,就必须先有数据,最简单的数据分集可以分为以下两种
- 训练集(training set):对于监督学习来说,训练集是带有标签的一组数据。无监督学习的训练集则不需要标签。这里的标签指的就是你希望模型输出的结果,例如下面的图片,我们给的标签分别是5,0,4,1。
- 测试集(test set) :用于测试训练结果的准确度。将数据拆分为训练集和测试集很有必要,用单独的测试集进行评估模型,更容易将模型推广到其他数据上(比如线上数据)。
2、根据数据是否有标签,我们还需要确定学习算法类别,是使用监督学习还是无监督学习。
监督学习常用算法:
- 线性回归
- 逻辑回归
- K-临近算法
- 支持向量机(SVM)
- 决策树和随机森林
- 神经网络
无监督学习常用算法:
- K-means
- 主要成分分析(PCA)
- EM(Expectation Maximization)
3、这些算法根据输出是否连续又可以分为回归模型和分类模型
- 回归(regression)模型:对数值型连续随机变量进行预测和建模的监督学习算法。比如线性回归。
- 线性回归:线性回归(左下图),训练结果就是图中的一元一次函数(蓝线)。函数中每一个输入对应一个输出,可用于预测趋势。
- 分类(classification)模型:分类通常用于输出离散的模型。比如逻辑回归。
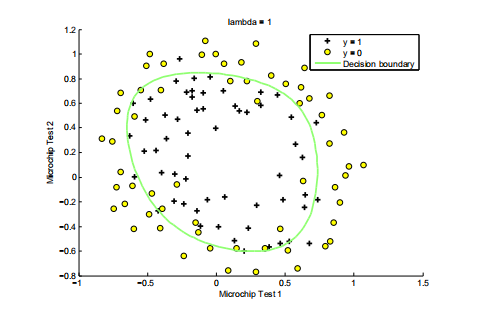
- 逻辑回归:逻辑回归(右下图),图中绿色的线是模型训练出的决策边界(Decision boundary),决策边界将数据分为两类是A或不是A,所以输出就是1或者0,是离散的。如果需要将结果分为n类,则需要训练n个决策边界,用hot-ont vectors(一个n列或n行的向量)结构来记录结果,大概是这样([1,0,0,0,0,0,0,0,0,0,0...]),向量的哪一列为1,就代表数据属于哪一类,结果也是离散的。

4、在确定算法以后,就需要知道怎么来训练我们的模型。这里我们使用线性回归作为例子来说明,左上图的横轴是城市的人口数,纵轴是餐车平均利润,我们需要预测不同人口时餐车利润是多少。
首先我们需要一个假设函数,在图中(左上)的数据(红叉)大概能看出用一元函数(一条直线)就能拟合(用一元函数还有一个原因是入门简单),因此我们使用下图的函数作为假设函数。
- 假设函数(hypothesis ):这个函数是对训练模型的一个假设,需要根据训练数据的特征数量来确定假设函数(线性回归中是多元函数)是几元的。
其中,函数的元数代表了输入特征的数量, θ(theta)代表了每个特征的权重。θ0比较特殊,它被称为偏置量。

有了假设函数后,我们随机初始化它的权重。比如 theta0 = -1,theta1 = 2,那么我们的假设函数会被初始为h = 2 * x - 1,是不是相当的简单。
初始化出来的假设函数肯定预测能力很差,我们就需要一个标准来判断假设函数的预测能力。在线性回归中我们使用最小二乘损失函数(如下图)来评估它的预测能力,这个用来评估的函数被称之为损失函数(loss)或者代价函数(cost)。
其中,m代表训练数据的数量,h(x)代表假设函数的预测值,y代表训练数据的标签(正确值)。函数就是把数据集的每一条数据的预测值和正确值的差距做平方,把得到的值求和,再除以数据量的两倍。

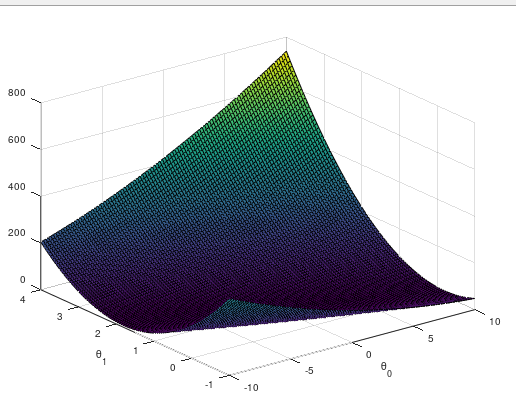
这个线性回归的代价函数大概是上左图这样,代价函数是衡量模型好坏的标准,那么我们让模型变好的方法就是找到代价函数的最小值或局部最小值。 我们刚才初始化的假设函数h = 2 * x - 1,如果用这个权重进行计算,代价函数会得到一个比较大的值。说明现在的模型很差,怎么办呢?
我们就需要用梯度下降算法来解决这个问题。想法就是,对代价函数中的每个权重求偏导,偏导在这个点(目前的权重值)的值是正的,说明函数沿着这个这个方向递增,需要减小这个权重值。偏导是负的,则需要加上这个权重值。然后批量对每个权重进行更新,最终得到我们的最优解或局部最优解。下面则是这个算法的公式:
θj代表当前的权重值,α代表学习率,α后面是偏导函数
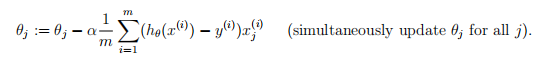
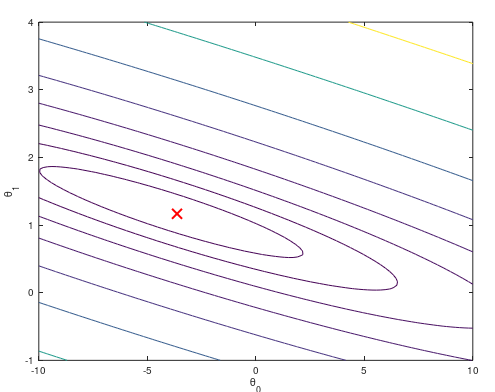
得到最优解后,我们的权重向量会到达左上图的最低点,也就是右上图(等高线图)中的红叉位置。将权重带入假设函数,就得到了我们的训练结果。
由于刚刚开始写博客,机器学习也刚入门,有错误的地方请多多指教。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号