

第10章 简洁代码的特性“盛宴”
第10章 简洁代码的特性“盛宴”
10.1 using static 指令
10.1.1 引入静态成员
using static 指令可以简化 静态 方法的调用。
使用该指令后,以下几种成员可以通过名称直接引用,无需附带类型名:
- 静态字段和属性。
- 静态方法。
- 枚举值。
- 嵌套类型。
如下两段代码等价,显然第二段更为简洁:
using System;
...
static Point PolarToCartesian(double degrees, double magnitude)
{
double radians = degrees * Math.PI / 180;
return new Point(
Math.Cos(radians) * magnitude,
Math.Sin(radians) * magnitude);
}
using static System.Math;
...
static Point PolarToCartesian(double degrees, double magnitude)
{
double radians = degrees * PI / 180;
return new Point(
Cos(radians) * magnitude,
Sin(radians) * magnitude);
}
Notice
通过 using static 引入的成员,在进行成员查找时,它们的优先级要 低 于其他同名成员。
假设引入了 System.Math,而此时类中还声明了一个
Sin 方法,那么Sin() 调用的将是 自己 声明的Sin 方法,而不是 Math 中的方法。
Info
using static 中虽然有 static,但它并不要求引入的类型必须是 静 态的。以下代码引入了非静态的
string 类型,也是合法的:using static System.String; ... string[] elements = { "a", "b" }; Console.WriteLine(Join(" ", elements));
10.1.2 using static 与扩展方法
在 C#6 之前的代码中,同一命名空间下的扩展方法,我们只能全部引入或全部舍弃。C#6 通过 using static 解决了这一问题。该用法有两个特别之处:
- 使用 using static 指令引入的某个类型的扩展方法,不会导致对应命名空间下的其他扩展方法被 引入 。
- 通过类型引入扩展方法,不能按照一般的 静态 方法调用(比如
Math.Sin()),而是像 实例 方法一样调用。
第一点以 LINQ 中的 System.Linq.Queryable (支持 IQueryable<T> 扩展方法的类)和 System.Linq.Enumerable (支持 IEnumerable<T> 扩展方法的类)为例,下面这段代码演示了只引入 IQueryable<T> 扩展方法、隔离 IEnumerable<T> 扩展方法:
using static System.Linq.Queryable;
...
var query = new[] { "a", "bc", "d" }.AsQueryable(); // 创建一个 IQueryable<string>
Expression<Func<string, bool>> expr = // 创建一个
x => x.Length > 1; // 委托和
Func<string, bool> del = x => x.Length > 1; // 表达式树
var valid = query.Where(expr); // 合法,使用 Queryable.Where
var invalid = query.Where(del); // 非法,查找范围内不存在接受 Func<...> 为参数的 Where 方法
Notice
上述代码如果不小心使用了
using System.Linq,最后一句代码也是合法的。
第二点同样以 LINQ 进行展示。如下代码对字符串序列调用 Enumerable.Count() 方法,其中以扩展方法的方式调用是 合 法的,以普通静态方法的方式调用是 非 法的:
using System.Collections.Generic;
using static System.Linq.Enumerable;
...
IEnumerable<string> strings = new[] { "a", "b", "c" };
int valid = strings.Count(); // 合法
int invalid = Count(strings); // 非法
Warn
将现有的静态方法改造成扩展方法(在第一个参数前添加 this 修饰符),以前是非破坏性的改动;对于 C#6,特性二使得该行为属于破坏性改动。
10.2 对象初始化器和集合初始化器特性增强
我们在3.3 对象和集合的初始化讲解了两个初始化器。C#6 对二者又进行了增强:
- 对象初始化器增加了对索引器的支持;
- 集合初始化器增加了对扩展方法的支持。
10.2.1 对象初始化器中的索引器
自 C#6 开始,我们可以在对象初始化器中使用索引器。其语法为 [index] = value。如下代码演示了索引器的使用:
string text = "This text needs truncating";
StringBuilder builder = new StringBuilder(text)
{
Length = 10,
[9] = '\u2026'
};
Console.OutputEncoding = Encoding.UTF8; // 确保 Console 支持 Unicode 编码
Console.WriteLine(builder);
Warn
Dictionary<,> 添加元素更推荐使用 集合 初始化器,而非对象初始化器中为索引器赋值。试比较如下两段代码,两段代码都错误的添加了相同 Key,但是第 一 段代码会报错。var collectionInitializer = new Dictionary<string, int> { { "A", 20 }, { "B", 30 }, { "B", 40 } };var objectInitializer = new Dictionary<string, int> { ["A"] = 20, ["B"] = 30, ["B"] = 40 };
下面几种情况应使用对象初始化器,而非集合初始化器:
-
当前类型没有实现
IEnumerable 接口或者没有适合的 Add() 方法,导致集合初始化器不能使用时。 -
当前类型的索引器和
Add() 方法对于 重复键值 的处理方式一致。
Dictionary<,> 显然不符合这一条 -
确实需要 替换 现有元素而不是添加新元素。
例如可能需要使用现有字典来新建一个字典,然后替换特定键值。
-
其他情况:在可读性和可靠性之间斟酌
10.2.2 在集合初始化器中使用扩展方法
我们在3.3.3.1 工作流程提到:
自定义集合类型想使用集合初始化器,需要满足以下两个条件:
- 实现了
IEnumerable 接口;- 具有
Add() 方法。
Add() 方法也有诸多限制:
- 任何没有大括号包围的元素,都被视为调用 单 参数的
Add() 方法。如果需要调用 多 参数的Add() 方法,则需要用大括号包围这些参数。
C#6 拓宽了 Add() 方法“合适”的限制:它可以是扩展方法。
以如下代码为例,因 重载决议 失败,它在 C#6 之前是无法通过编译的:
List<string> strings = new List<string>
{
10,
"hello",
{ 20, 3 }
};
// 等价于:
List<string> strings = new List<string>();
strings.Add(10);
strings.Add("hello");
strings.Add(20, 3);
在 C#6 中,添加如下扩展方法可以使上述代码通过编译:
public static class StringListExtensions
{
public static void Add(this List<string> list, int value, int count = 1)
{
list.AddRange(Enumerable.Repeat(value.ToString(), count));
}
}
可以看到:
- 扩展方法可以用于 集合 初始化器;
- 扩展方法 可以 是泛型的(上述代码未演示);
- 扩展方法 可以 使用可选形参。
10.2.2.1 创建其他通用的 Add 方法
通过自定义 Add() 扩展方法实现 AddRange() 功能可以将集合元素的添加工作挪至集合初始化器中。以如下代码为例,它实现了 List<T> 类型使用集合初始化器时可以接受 集合 元素:
static class ListExtensions
{
public static void Add<T>(this List<T> list, IEnumerable<T> collection)
{
list.AddRange(collection);
}
}
10.2.2.2 创建专有的 Add 方法
专有的 Add 方法还可以用来简化业务代码。
假设我们有如下 Person 类:
class Person
{
public string Name { get; set; }
}
我们需要创建一个字典,其 Key 是 Person 的 Name 属性,Value 是相应的 Person 实例。为此我们不得不创建 临时变量 以记录 Person 实例:
var person1 = new Person { Name = "Jon" };
var person2 = new Person { Name = "Holly" };
var dictionary = new Dictionary<string, Person>
{
{person1.Name, person1},
{person2.Name, person2},
};
此时我们可以添加一个专门服务于 Dictionary<,> 和 Preson 的 Add 方法:
static class PersonDictionaryExtensions
{
public static void Add(
this Dictionary<string, Person> dictionary, Person person)
{
dictionary.Add(person.Name, person);
}
}
此时为字典添加元素无需 临时的局部变量 :
var dictionary = new Dictionary<string, Person>
{
{ new Person { Name = "Jon" } },
{ new Person { Name = "Holly" } },
};
10.2.2.3 重新暴露显式实现的接口方法
以 ConcurrentDictionary<,> 为例,它的 Add() 方法以显式方式实现,因此如下代码非法:
var dictionary = new ConcurrentDictionary<string, int>
{
{ "x", 10 },
{ "y", 20 }
};
我们可以实现针对 IDictionary<,> 接口的扩展方法,以支持 ConcurrentDictionary<,> 使用集合初始化器:
public static class DictionaryExtensions
{
public static void Add<TKey, TValue>(this IDictionary<TKey, TValue> dictionary, TKey key, TValue value)
{
dictionary.Add(key, value);
}
}
Tips
上述代码把所有字典类型都扩展了,过于宽泛。我们可以把目标锁定于
ConcurrentDictionary<,>,防止应用范围扩大化。
10.3 空值条件运算符
空值条件运算符 ?. 于 C#6 引入。
10.3.2 关于空值条件运算符的更多细节
?. 运算符可用于方法、字段、索引器。其基本工作原理是:
-
每遇到一个空值条件运算符,编译器都会为
?. 前面的值插入一条 空值检查 语句; -
如果值为 null,那么整个表达式 的运算终止 ,并返回 null 值;
-
如果值不为 null,则表达式继续向右对属性、方法、字段或者索引进行运算,而不需要对左边做重复运算。
该原理令所有表达式只运算 一 次,很好的规避了多线程的静态条件造成的影响。
如果整个表达式是非可空值类型,一旦其中出现了空值条件运算符,整个表达式的类型就会变成 对应的可空值 类型。
10.3.3 处理布尔值比较
通过 ?. 得到的运算结果,在进行相等比较时需要通过 == 进行,而非 Equals() 方法(可空类型的 Equals() 方法返回的结果是 bool? ,它无法直接进行条件判断)。以如下代码为例,它无法通过编译:
c => c.Profile?.DefaultShippingAddress?.Town?.Equals("Reading")
在条件判断中使用空值条件运算符时,需要考虑以下 3 种可能的执行情况:
- 表达式中的每一部分都运算过了,结果是 true;
- 表达式中的每一部分都运算过了,结果是 false;
- 表达式因为 null 值而中断,结果是 null
我们需要将第三种情况映射到 true 或 false。一般有两种实现方式:与某个 bool 类型的常量做比较,或者使用 空合并 运算符 ?? 。
下面演示了两种方案的使用:
// 如果 name 为 null,则不执行
if (name?.Equals("X") ?? false)
if (name?.Equals("X") == true)
// 如果 name 为 null,则执行
if (name?.Equals("X") ?? true)
if (name?.Equals("X") != false)
Suggest
作者建议使用 空合并运算符 ,它可以理解为“尝试执行比较操作,如果操作没有执行完,就采用
?? 后的值”。
10.3.4 索引器与空值条件运算符
索引器使用空值条件运算符,其问号要放在方括号之 前 :
int[] array = null;
int? firstElement = array?[0];
10.3.5 使用空值条件运算符提升编程效率
空值条件运算符常用场景有二:
1. 安全便捷的事件触发
在空值条件运算符出来之前,触发事件的代码一般编写如下:
EventHandler handler = Click; // 通过局部变量防止竞态条件
if (handler != null)
{
handler(this, EventArgs.Empty);
}
使用空值条件运算符后可简化成一行代码:
Click?.Invoke(this, EventArgs.Empty);
2. 最大程度地利用返回 null 的 API
我们在内插字符串中有提到:
无意义的消耗 内存
有时我们的格式化字符串并不会用到,但是内插字符串会提前创建
string/FormattableString 实例,导致内存消耗:Preconditions.CheckArgument(start.Year < 2000, Invariant($"Start date {start:yyyy-MM-dd} should not be earlier than year 2000."));这在日志系统十分常见。
如果日志系统的 API 支持返回 null,像下面这样:
public interface ILogger
{
IActiveLogger Debug { get; } //
IActiveLogger Info { get; } // 如果未开启日志
IActiveLogger Warning { get; } // 则属性返回 null
IActiveLogger Error { get; } //
}
public interface IActiveLogger
{
void Log(string message);
}
当 Debug 为 null 时,如下这段代码的内插字符串 不会被创建 :
logger.Debug?.Log($"Received request for URL {request.Url}");
Tips
Element("xyz").Value 调用在 xyz 元素不存在时将 抛出 NullReferenceException 。XElement 为string 类型定义了显式转换,可以通过强制类型避免此异常。即:string xyz = (string)settings.Element ("xyz");当然,我们也可以使用
?.
10.3.6 空值条件运算符的局限性
空值条件运算符表达式的结果是一个 值 ,而不是 变量 。该限制导致我们不能把空值条件运算符用在赋值号(=)的左边,例如以下几种写法均 非 法:
person?.Name = "";
stats?.RequestCount++;
array?[index] = 10;
此时需要使用 if 语句进行判断。
10.4 异常过滤器
10.4.1 异常过滤器的语法和语义
异常过滤器的语法为:
- 关键字
when 之后跟一对小括号,括号中是表达式。 - 表达式可以使用 catch 块中声明的异常变量,且执行结果必须是布尔类型。
它的简单应用如下,该代码会输出:“ Caught 'You can catch this '”和“ Caught 'You can catch this too '”:
string[] messages =
{
"You can catch this",
"You can catch this too",
"This won't be caught"
};
foreach (string message in messages)
{
try
{
throw new Exception(message);
}
catch (Exception e)
when (e.Message.Contains("catch")) // 只有当 message 中包含 catch 时才捕获
{
Console.WriteLine($"Caught '{e.Message}'");
}
}
10.4.1.1 双通路异常模型
CLR 处理异常采用双通路模型,方式如下:
-
异常抛出,第 1 条通路开始。
-
CLR 自上而下检查栈空间,寻找可以处理当前异常的 catch 块。
这里我们将该块称为“处理 catch 块”,这不是官方术语。
- 只有具备 兼容异常类型 的 catch 块才会被考虑。
- 如果该 catch 块中有异常过滤器,那么先执行异常过滤器。如果过滤器返回 false ,则 catch 块不处理异常。
- 不包含异常过滤器的 catch 块等价于包含异常过滤器返回 true 的 catch 块。
-
处理 catch 块确定了之后,第 2 条通路开始。
-
CLR 把从异常抛出的位置开始到 catch 块确定了的位置的调用栈释放。
在释放栈的过程中,所有 finally 块将被执行。(不包括处理 catch 块所对应的 finally块。)
-
处理 catch 块执行。
-
如果处理 catch 块有对应的 finally 块,那么该部分代码也会被执行。
如下代码演示了上述流程:
Bottom();
static bool LogAndReturn(string message, bool result)
{
Console.WriteLine(message);
return result;
}
static void Top()
{
try
{
throw new Exception();
}
finally //
{ // 在第2条通路中执行
Console.WriteLine("Top finally"); // 的 finally 块
} //
}
static void Middle()
{
try
{
Top();
}
catch (Exception e) when (LogAndReturn("Middle filter", false))
{
Console.WriteLine("Caught in middle");
}
finally //
{ // 在第2条通路中执行
Console.WriteLine("Middle finally"); // 的 finally 块
} //
}
static void Bottom()
{
try
{
Middle();
}
catch (IOException e) when (LogAndReturn("Never called", true))
{
}
catch (Exception e) when (LogAndReturn("Bottom filter", true))
{
Console.WriteLine("Caught in Bottom");
}
}
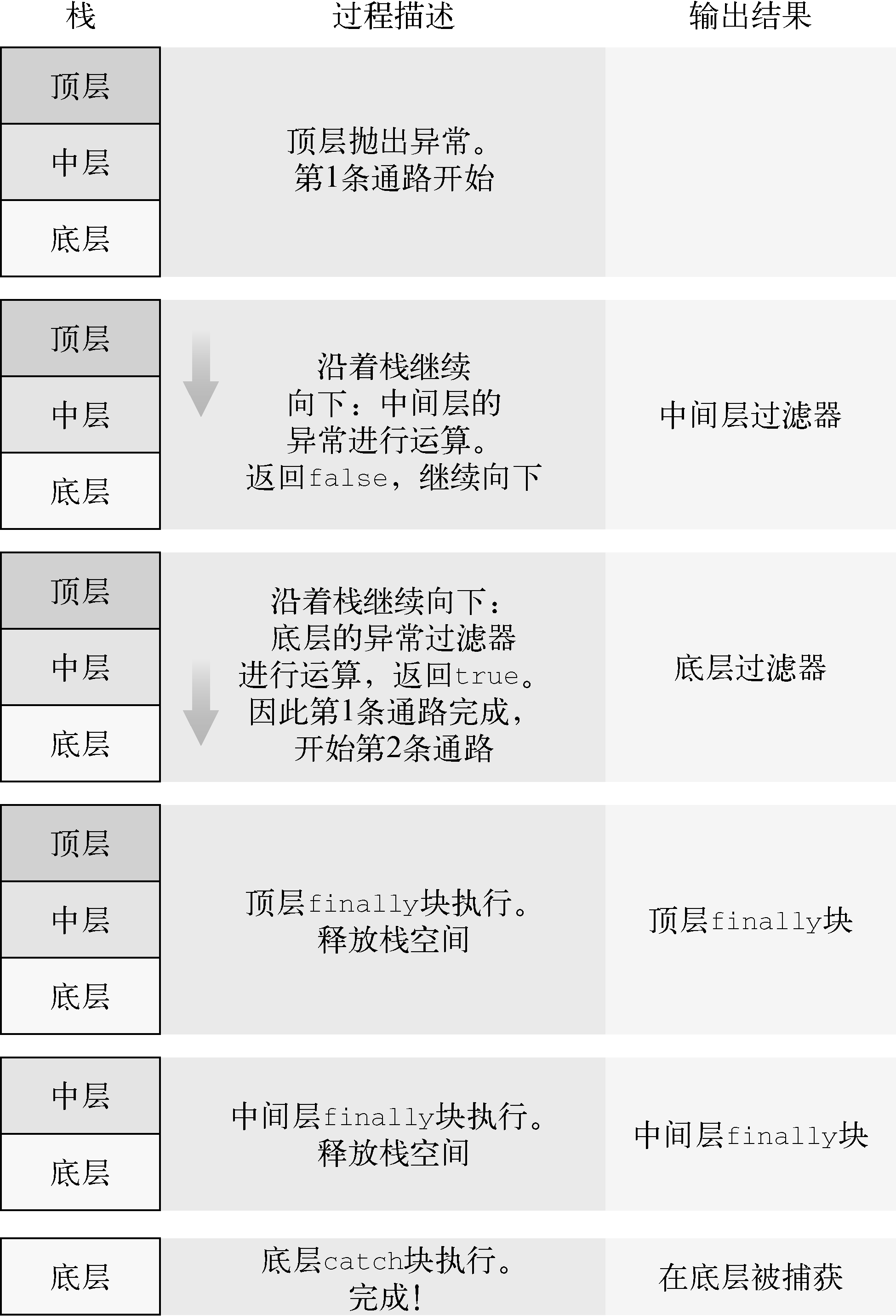
Warn
上述流程我们可以发现:when 块的内容是 先 于 finally 块执行的!这意味着恶意开发者可以通过在自己的 when 块中执行恶意代码!
双通路模型的安全影响
finally 块执行的时序会影响 using 和 lock 语句,这一点对于 try/finally 或者 using中的内容有重要影响,因为代码的执行环境可能包含恶意代码。如果有非受信代码调用我们的方法,而我们的方法可以抛出异常,调用方就可以在 finally 块执行之前通过异常过滤器来执行代码了。
以上内容表明:对安全敏感的代码不要出现在 finally 块中。例如在 try 块中进入一个较高权限的状态,然后 finally 块中的代码回到一个较低权限的状态,此时其他代码就可能在仍处于较高权限时被执行。不过很少需要考虑此类安全问题,因为代码多数时候是在比较友好的环境中运行的,但是我们必须意识到存在这样的风险。若想提升安全度,可以添加一个带有异常过滤器的空 catch 块,该过滤器负责移除相关权限并返回 false(这样异常就不会被捕获了),不过我一般不会这么做。
10.4.1.2 多次捕获同一类型的异常
同一个 try 块在不同的 catch 块中捕获同一个异常类型,且未使用 异常过滤器 ,代码将无法通过编译。如下代码演示了不同 catch 块捕获相同异常,并使用异常过滤块:
try
{
// 尝试 Web 操作
}
catch (WebException e) when (e.Status == WebExceptionStatus.ConnectFailure)
{
// 处理连接失败
}
catch (WebException e) when (e.Status == WebExceptionStatus.NameResolutionFailure)
{
// 处理名称决议失败
}
10.4.2 重试操作
异常过滤器常用于特定条件下的重试操作。如下代码演示了一个通用方法,它可以做到:
- 执行外部传入的操作
- 执行失败则尝试操作若干次
static T Retry<T>(Func<T> operation, int attempts)
{
while (true)
{
try
{
attempts--;
return operation();
}
catch (Exception e) when (attempts > 0)
{
Console.WriteLine($"Failed: {e}");
Console.WriteLine($"Attempts left: {attempts}");
Thread.Sleep(5000);
}
}
}
10.4.3 记录日志的“副作用”
我们可以利用异常过滤器记录全部异常。实现方式很简单:
- 在 异常过滤器 中调用记录日志的方法
- 返回 false 表明不需要捕获当前异常
类似的代码如下:
static void Main()
{
try
{
UnreliableMethod();
}
catch (Exception e) when (Log(e))
{
}
}
static void UnreliableMethod()
{
throw new Exception("Bang!");
}
static bool Log(Exception e)
{
Console.WriteLine($"{DateTime.UtcNow}: {e.GetType()} {e.Message}");
return false;
}
10.4.4 单个、有针对性的日志过滤器
略
10.4.5 为何不直接抛出异常
以如下两段代码为例:
catch (Exception e) when (condition)
{
...
}
catch (Exception e)
{
if (!condition)
{
throw;
}
...
}
它们有这些区别:
- 调用栈 不同
代码一会保持原异常抛出的调用栈,代码二则从当前位置重新计算。
这也意味着二者的 finally 块的调用是有细微差别的。试比较10.4.1.1 双通路异常模型中的示例代码和如下代码输出内容的区别:
Bottom();
static bool LogAndReturn(string message, bool result)
{
Console.WriteLine(message);
return result;
}
static void Top()
{
try
{
throw new Exception();
}
finally
{
Console.WriteLine("Top finally");
}
}
static void Middle()
{
try
{
Top();
}
catch (Exception e)
{
if (!LogAndReturn("Middle filter", false))
{
throw;
}
Console.WriteLine("Caught in middle");
}
finally
{
Console.WriteLine("Middle finally");
}
}
static void Bottom()
{
try
{
Middle();
}
catch (Exception e)
{
if (!LogAndReturn("Bottom filter", true))
{
throw;
}
Console.WriteLine("Caught in Bottom");
}
}
- throw 语句可以保留大部分原始调用栈,但仍存在细微差别

 浙公网安备 33010602011771号
浙公网安备 33010602011771号