论文归纳-面向后训练的数据选择
| 方法名称 (会议/年份) | 任务类型 | 数据表示 (Representation) | 多样性策略 (Diversity) | 质量/难度策略 (Quality) |
|---|---|---|---|---|
| LESS (ICML 24) | Targeted IT | LoRA Adam 梯度投影 | 基于相似性的 Top-k | 梯度相似性 (Influence Function) |
| DiverseEvol (Arxiv 23) | General IT | 模型中间层 Embedding | K-Center-Sampling (主动学习) | N/A (以代表性为主) |
| CherryLLM (NAACL 24) | General IT | 语义 Embedding | K-means 聚类采样 | IFD (指令遵循难度) |
| Superfiltering (ACL 24) | General IT | PPL / 困惑度 | N/A | IFD (弱模型到强模型的一致性) |
| Small2Large (ACL 24) | General IT | Sentence Embedding | K-means 聚类 | LP (学习百分比/困惑度下降比例) |
| Nuggets (ACL 24) | General IT | One-shot 推理表现 | N/A | Golden Score (基于 ICL 的性能增益) |
| Data Whisperer (ACL 25) | Targeted IT | ICL 表现 + 注意力权重 | N/A | Few-shot 分数 + 注意力加权得分 |
| MIG (ACL 25) | General IT | 语义标签图 (Label Graph) | 信息增益 (次模函数) | 标签权重 + 语义传播 |
| G2IS (ACL 25) | Targeted IT | LoRA Adam 梯度 | 梯度混合图 (Graph Walk) | 核心知识 (Anchor) 梯度相似性 |
| Exp. Design (ACL F. 24) | General SFT | Token 概率/不确定性 | K-center / 设施选址 (FL) | 最小边际 (Min Margin) / 熵 |
| QDIT (EMNLP F. 24) | General IT | Sentence Embedding | 设施选址 (FL) | GPT 打分 / 打分模型 |
| ClusterUCB (EMNLP 25) | Targeted IT | LoRA 梯度 | K-means 聚类 (簇管理) | UCB 奖励 (基于梯度的影响估计) |
| NovelSum (ACL 25) | General IT | 语义距离 (Density-Aware) | NovelSum (近邻加权差异) | N/A (论文旨在纯多样性评估) |
LESS: Selecting Influential Data for Targeted Instruction Tuning
ICML 2024, Princeton
Targeted Instruction Tuning
https://github.com/princeton-nlp/LESS

文章提出了一种基于低秩梯度相似性的数据挑选方法 LESS (Low-rank gradiEnt Similarity Search),旨在从大量数据中挑选最相关的数据来提升模型的特定能力。LESS方法包含四个步骤:
- 使用Lora对选择模型(selection model)进行warmup
- 对每个候选数据,使用选择模型计算其Lora Adam一阶梯度特征用于估计数据的影响,并存储起来
- 计算目标任务上少量样本的梯度特征,并根据梯度相似性从数据集中选择top-5%的数据
- 使用选择后的数据微调模型,提升模型在目标任务上的能力。
优点:
- 传统
影响函数(influence function)是对于SGD优化器的,LESS能够适用于大模型训练常用的Adam优化器; - 降维:采用Lora、维度投影两个技术降低梯度特征的维度,从而减小计算开销。
Self-Evolved Diverse Data Sampling for Efficient Instruction Tuning
arxiv 2023, 阿里
Instruction Tuning
https://github.com/OFA-Sys/DiverseEvol
文章提出了一种自我进化的多样化数据采样方法,旨在解决大模型指令微调中数据量大、成本高的问题。DiverseEvol通过迭代的方式扩展训练数据池,包含以下几个步骤:
- 初始训练数据池为\(P_0\),训练初始Chat Model \(M_0\)
- 将候选数据点投影到当前模型\(M_t\)的嵌入空间上
- 在嵌入空间上执行
K-Center-Sampling,选择与现有训练数据在嵌入空间中距离最远的\(k\)个数据点,加入的训练数据,得到新的训练数据池\(P_{t+1}\)。此步意在确保训练数据具有代表性,能够覆盖完整数据集。 - 使用新的训练数据池指令微调得到新的Chat Model \(M_{t+1}\)。
- 跳转第2步,直至得到循环上限\(T\)次。
该方法使用原始数据集2%-8%的数据量即可匹配或超过全量数据微调的性能。
缺点:本质上是基于多样性的主动学习(Active Learning),需要迭代地采集样本和微调模型,计算开销大。
From Quantity to Quality: Boosting LLM Performance with Self-Guided Data Selection for Instruction Tuning
NAACL 2024, University of Maryland
Instruction Tuning
https://github.com/tianyi-lab/Cherry_LLM
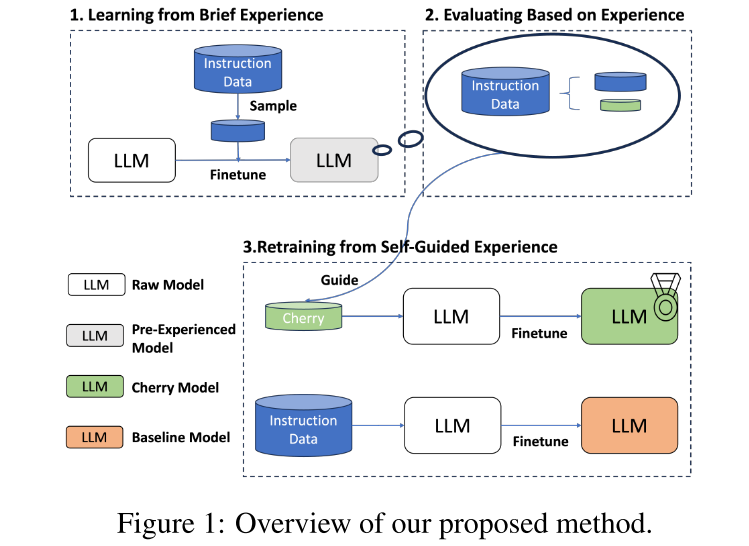
文章提出了一种自引导数据选择框架(无需额外的选择模型),自主筛选对自身调优最有效的样本。CherryLLM分为三个阶段:
- 用目标数据集的少量样本训练初始模型\(M0\),得到模型\(M_1\),使其具备基础的指令遵循能力。下面是根据源码得到的具体细节:
- 多样性:使用初始模型对所有数据进行编码,在嵌入空间中使用Kmeans聚类,从100个簇中各选10个样本。
- 质量/难度:选择IFD分位数在25%-75%之间的指令,即难度适中。
- 使用\(M_1\),计算指令遵循难度 IFD(instruction following difficulty),即模型在
“有指令”时生成答案的损失与“无指令”时的生成答案的损失的比值。IFD分数越小,说明指令对模型的引导作用越弱,样本难度越大,数据对微调任务的价值越高。IFD大于1的指令无指导作用,直接舍弃。- 有指令\(Q\)时的损失(交叉熵):\(L_{\theta}(A|Q)=-\frac{1}{N}\sum \log P(w_i^A|Q,w_1^A,\dots,w_{i-1}^A;\theta)\)
- 无指令时的损失:\(L_{\theta}(A)=-\frac{1}{N}\sum \log P(w_i^A|w_1^A,\dots,w_{i-1}^A;\theta)\)
- IFD:\(IFD_\theta(Q,A) = \frac{L_{\theta}(A|Q)}{L_{\theta}(A)}\)
- 筛选IFD分数较高的样本,微调最终模型\(M_2\)。
缺点:使用GPT4和人工进行打分,得到winning score,感觉不是很客观。Huggingface Open LLM Leaderboard似乎是不错的benchmark。(此处存疑,是否有更好的LLM评估方法还需要进一步调研)
Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning
ACL 2024, University of Maryland
Instruction Tuning
https://github.com/tianyi-lab/Superfiltering
在CherryLLM的基础上继续做了一篇文章。文章具有以下贡献:
- 作者提出猜想:在理解和感知指令微调数据难度方面,弱语言模型和强语言模型之间具有强一致性。实验结果表明,
困惑度PPL和指令遵循难度IFD的排序在不同规模的模型之间具有较强的一致性(通过pearlson 系数衡量)。 - 基于上述观察,文章直接利用小语言模型(如GPT-2),计算IFD,进而筛选top-k的数据,极大地减少数据筛选的时间和成本。(原先的数据筛选方法要么基于大模型,要么需要进行额外的训练,时间和成本较高)。
Smaller Language Models are capable of selecting Instruction-Tuning Training Data for Larger Language Models
ACL 2024, University of California San Diego
Instruction Tuning
https://github.com/dheeraj7596/Small2Large
文章提出了学习百分比 LP来衡量指令数据的难度。过去对深度神经网络的研究表明:模型倾向于先记住简单样本,然后学习难样本。难样本对于提升模型的能力更重要。
学习百分比\(LP(i)\)的定义:样本在训练第\(i\)轮的困惑度下降比例。\(LP(i)=\frac{P_{i-1}-P_i}{P_0-P_n}\).- 因为大模型1个epoch即可学习大部分信息,主要使用\(LP(1)\)排序。\(LP(1)\)越小,困惑度下降越少,样本越难。
- 多样性:文章对在整个数据集上使用all-MiniLM-L6-v2得到的sentence embedding使用Kmeans聚类。从每个簇中选取\(LP(1)\)最小的top-k%,最终组成筛选后的数据集。
文章还指出难度具有传递性,即小模型觉得难的数据,大模型也可能觉得难。因此能够类似预训练中常见的代理模式(proxy),用小模型为大模型服务,提高数据选择效率。
One-Shot Learning as Instruction Data Prospector for Large Language Models
ACL 2024, 阿里
Instruction Tuning,有Predefined Task
https://github.com/pldlgb/nuggets
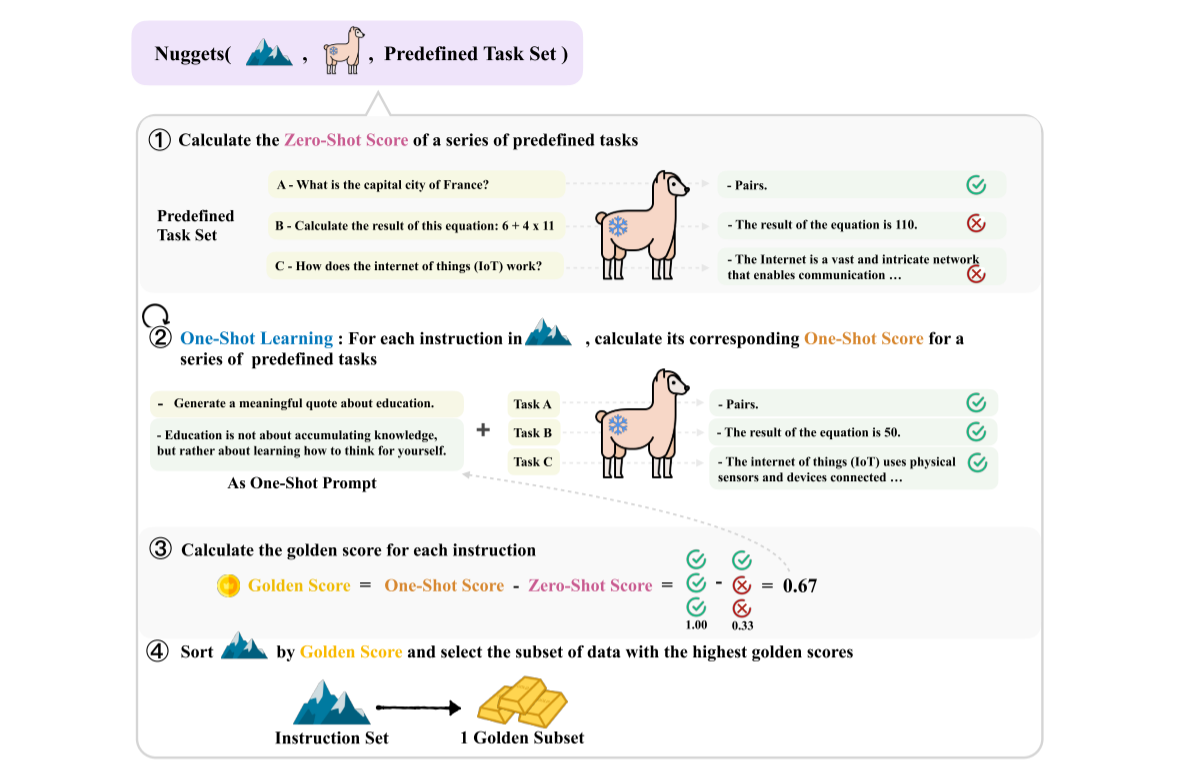
文章利用了上下文学习(In Context Learning)中的单样本学习 (One-Shot Learning)来评估指令数据的价值。上下文学习和微调之间存在着微妙的关系:
- 直觉上,一条数据在指定任务上的one-shot learning中表现出色,则在训练中也是有价值的。
- 部分研究认为,上下文学习是通过提示词隐式地微调大模型,而指令微调是通过梯度显式地进行微调。
- 上下文学习的时间开销 < 微调的时间开销
Nuggets的基本思想是通过对比模型在“无指令”和“单样本”在预定义任务集上的表现,计算黄金分数,从而评估指令质量。Nuggets包括以下几个步骤:
- 构建预定义任务集,包含\(m\)个任务(随机选取1000个样本 或 Kmeans聚类后选取)。
- 计算模型在预定义任务集上的表现,得到零样本分数(zero-shot score)。
- \(s_{zsl}^j = \frac{1}{L} \sum_{i=1}^L \log p(w_i^{A_j}|C; LLM)\). 其中\(A_j\)表示第\(j\)个任务的答案,\(C\)表示第\(j\)个任务以及\(w_{1}^{A_j},\dots,w_{i-1}^{A_j}\).
- \(S_{zsl} = [s_{zsl}^1, s_{zsl}^2, \dots,s_{zsl}^m]\),有\(m\)个任务
- 对指令集中的每个样本,将其作为单样本提示拼接到预定义的任务前,计算模型的单样本分数(one-shot score)。
- \(s_{iit}^j = \frac{1}{L} \sum_{i=1}^L \log p(w_i^{A_j}|\text{One-shot Prompt}, C; LLM)\)
- \(S_{iit} = [s_{iit}^1, s_{iit}^2, \dots,s_{iit}^m]\)
- One-shot Prompt中包含了候选的指令数据
- 根据单样本分数、零样本分数计算每个样本的
黄金分数,选取top-k的指令数据作为高质量子集。- \(GS(z_k) = \frac{1}{m} \sum_{i=1}^m \mathbf{I}(s_{iit}^i(z_k) > s_{zsl}^i(z_k))\),其中\(z_k\)表示样本数据。
缺点:虽然不用多次微调,但是需要进行很多次推理,总推理次数=预定义任务集 * 总样本数。(鉴于上下文学习的时间成本小于微调,此处存疑)
Data Whisperer: Efficient Data Selection for Task-Specific LLM Fine-Tuning via Few-Shot In-Context Learning
ACL 2025, 上海交通大学
Task-specific Fine Tuning
https://github.com/gszfwsb/Data-Whisperer
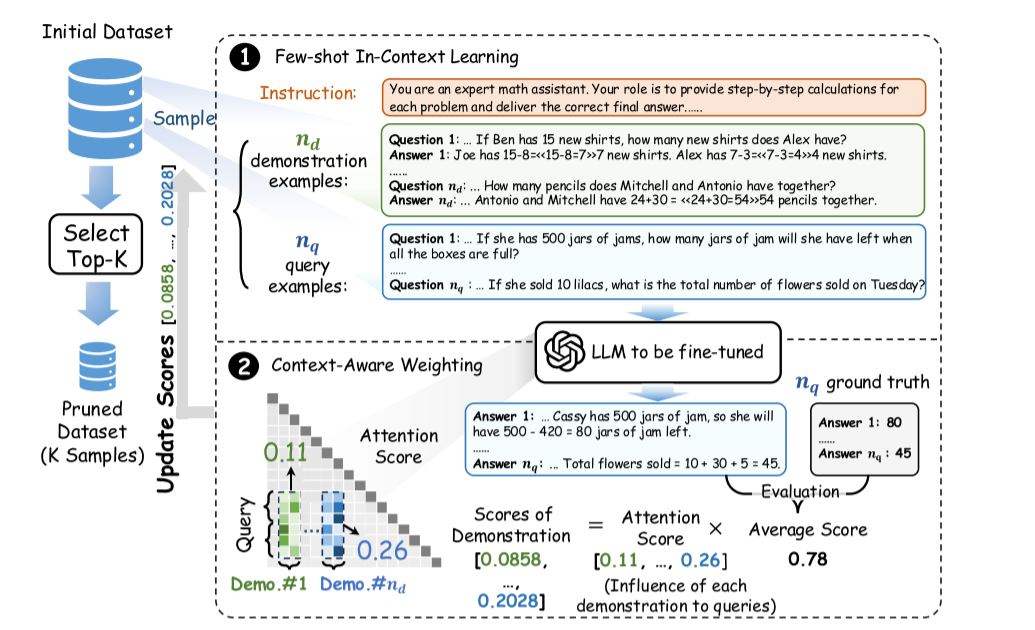
传统的数据选择方法通常需要在目标数据集上进行微调,得到评分模型,时间和资源开销大。针对上述问题,文章提出了一种基于少样本上下文学习(Few-Shot In-Context Learning)和注意力机制的数据选择方法 Data Whisperer。该方法无需训练,大幅提升了数据选择的速度。其基本想法是:上下文学习和微调都存在相似性,而上下文学习无需训练成本较低,可以用来替代之前数据选择方法中常用的先微调再筛选。Data Whisperer 主要包含以下几个步骤:
- 每次循环随机选取\(n_d\)个
示例样本和 \(n_q\)个查询样本,然后结合指令\(I\),构建上下文学习的提示词。 - 计算分数:用待微调的模型根据步骤1构建的提示词回答问题。将回答与ground truth比较,进行打分(数学题用准确率,摘要用ROUGE-L)。分数会分配给示例样本。
- 注意力加权:采用模型中间层的注意力分数作为分数的权重,修正上下文提示词中示例样本顺序带来的影响。
- 所有样本都作为示例并累计得分(第2步的分数与第3步的权重加权求和),最终筛选出评分最高的数据子集。
MIG: Automatic Data Selection for Instruction Tuning by Maximizing Information Gain in Semantic Space
ACL 2025, 上海AI Lab
Instruction Tuning
https://yichengchen24.github.io/projects/mig
传统方法的多样性仅关注嵌入空间的距离/聚类,未能捕捉指令中的语义。文章引入标签图(Lable Graph)来建模语义空间,用于度量指令数据在语义空间上的质量和多样性。基于标签图,文章提出了一种采样方法MIG,迭代式地采集能够最大化语义空间信息增益的样本点,从而兼顾数据的质量和全局语义多样性。
标签图的节点为标签(如”医学咨询“),每个标签都分配有分数。标签图的边权重为不同标签之间的相似度。语义相近的节点之间会通过信息传播的机制,将分数进行进一步分配,用于修正标注偏差。
使用一种单调递增上凸函数 / 次模函数(submodular function)来量化每个标签的信息(图上某种类型的节点越多,新增同类型节点带来的收益越小;边际效用递减)。每次采样,贪心地从候选集中选取能够最大化当前标签图信息增益的数据点。最终得到目标数据子集,用于微调LLM。
- Tips:次模函数是边际效用递减的形式化表达。如果和
贪心算法相结合,可以计算和最优解的近似比。
Beyond Similarity: A Gradient-based Graph Method for Instruction Tuning Data Selection
ACL 2025, Scir Lab
Instruction Tuning, Targeted(有验证集)
https://github.com/zy125413/G2IS
传统方法只考虑从大数据集中选择与目标域相似的指令,而没有考虑到指令间的联合分布和依赖关系。文章通过混合梯度图来构建指令之间的关系,然后通过图上的游走算法,筛选出高质量的指令数据。
G2IS包含以下步骤:
- 梯度计算:有文献认为梯度是模型知识的一种动态反映。文章对训练集计算Adam梯度,对验证机计算SGD梯度。为了降低计算开销,仅对Lora层计算梯度,并且使用随机投影进行降维。
- 核心知识提取:对验证集的梯度做PCA,选取前50%作为核心知识(anchor),表征模型解决目标任务需要的关键能力。
- 构建梯度图:节点为训练集样本的梯度,边权重为梯度间的余弦相似度(梯度为正表示相似/有益,梯度为负表示知识冲突)。
- 梯度游走筛选:从anchor对应的样本出发,迭代选择同时满足以下三种约束的样本
- 与现有样本不冲突:相似度≥0
- 贴合核心知识:添加该样本后,相似度衰减≤20%
- 与上一个选中的样本连贯:相似度最高
baseline:LESS, Sentence-Bert
benchmark: Open LLM Leaderboard Harness
models: Llama3.1-8B, Gemma-7B, Mistral-7Bv0.3
An Experimental Design Framework for Label-Efficient Supervised Finetuning of Large Language Models
ACL finding 2024, University of Washington
Prompt Selection for Instruction Tuning
该研究针对监督微调(SFT)中 “高质量指令标注成本高、主动学习计算开销大” 的痛点,提出基于实验设计的标签高效数据选择框架,通过不确定性、多样性及次模函数优化策略筛选高价值指令,在生成式与分类任务中能够节省 50% 的标注成本。与传统主动学习的迭代训练不同,本实验仅基于预训练模型一次性筛选待标注的数据,计算开销小。文章设计了三种策略:
- 基于不确定性 uncertainty-based:
- 平均熵(Mean Entropy):计算生成序列的平均 token 熵,熵越高不确定性越强。
- 最小置信度(Least Confidence):取生成序列概率乘积的负值,概率越低越不确定。
- 平均边际(Mean Margin):计算每个 token Top1 与 Top2 概率差的平均值,差值越小不确定性越强。
- 最小边际(Min Margin,创新):取生成序列中最小的 Top1-Top2 概率差,更敏感捕捉关键不确定位置。
- 基于多样性 diversity-based:
- k-center:选择特征空间中覆盖所有样本的k个中心样本
设施选址(Facility location)(次模函数的一种),最大化样本间相似度覆盖,平衡多样性与代表性,支持余弦相似度、径向基函数(RBF)等核函数。
- 混合策略:通过次模函数,平衡不确定性和多样性
benchmark:MMLU, BBH-CoT, alpaca-eval-gpt4
models: Llama2-7B, Lora
实验结果表明:设施选址(FL)> 最小边际(Min Margin)> 其他不确定性 / 多样性策略,随机采样表现最差。
Data Diversity Matters for Robust Instruction Tuning
EMNLP finding 2024, Georgia Institute of Technology
Instruction Tuning
面向指令调优的数据选择主要关注两个因素:数据质量(quality)、多样性(diversity)。只关注质量,会导致模型鲁棒型不足;只关注多样性会影响整体性能。
文章提出了QDIT方法,通过线性加权数据质量和多样性,来实现两者的平衡。其中:
- 数据多样性通过设施选址函数(FL)来反映,旨在选出具有代表性的样本。\(d(A) = \sum_{v \in V} max_{a \in A} sim(a, v)\). A为选出的子集,\(sim()\)为sentence embedding后的余弦相似度。
- 数据质量通过GPT打分,或是通过训练的打分模型打分,表示为\(q(\cdot)\)
- 总分数为\(score(a) = (1-\alpha)d(a|A) + \alpha q(a)\)
- 因为FL是一种单调的次模函数,可以通过贪心算法近似求解,近似比\(1-\frac{1}{e}\)。通过lazy greedy可以进一步加速。
相比于质量驱动的数据选择方法,QDIT能够提升数据的覆盖度,从而在“最差案例”上的表现有所提升,即题目中的鲁棒型。
ClusterUCB: Efficient Gradient-Based Data Selection for Targeted Fine-Tuning of LLMs
EMNLP 2025, 北京大学
SFT on the target task
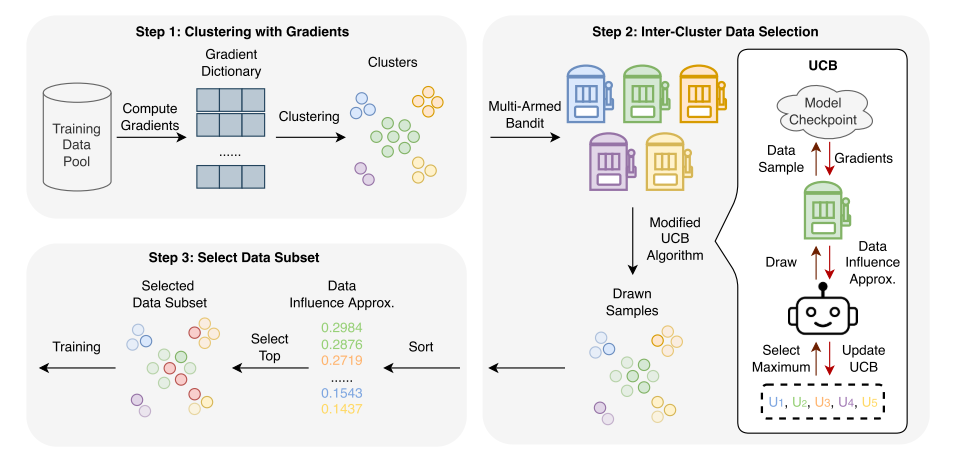
现有基于梯度的数据选择方法(如LESS, Dynamic)需要计算大量样本的梯度来评估数据的影响力,计算开销大。文章提出了ClusterUCB方法,在与原有方法性能相当的同时,将基于梯度方法的计算开销降低至原来的20%。ClusterUCB的基本思想是:梯度特征相似的样本产生的影响力相似,因此可以先聚类,然后从每个簇中选取高影响力的样本作为代表,从而避免计算所有样本的梯度,降低计算开销。ClusterUCB包含以下几个步骤:
- 梯度计算与聚类:基于预训练模型计算所有训练样本的 LoRA 层梯度,通过 K-means 按梯度余弦相似度聚类。
- 簇间选择建模:将每个簇视为多臂摇杆机的 “臂”,计算预算为总样本的 20%,每次从簇中随机抽取样本计算影响力作为 “奖励”。
- 改进UCB算法选择:记录每个簇的历史奖励,用 “均值 +β× 标准差” 估计置信上界(β=1),优先选择置信上界最高的簇(包含高影响力样本概率更高的簇);初始预算用于冷启动,按簇大小分配以积累初始奖励。
- 高影响力样本筛选:对所有抽取样本的按影响力排序,选择 Top-p%(默认 5%)作为最终微调子集。
baseline: LESS, Dynamic
train data set: Flan-v2, CoT, Dolly, Open Assistant v1, GPT4-alpaca, ShareGPT, GSM8k-train, Code-alpaca
benchmark: MMLU(知识问答)、TydiQA(多语言 QA)、GSM8k(数学推理)、HumanEval(代码生成)
models: Llama2-7B, Lora
Measuring Data Diversity for Instruction Tuning: A Systematic Analysis and A Reliable Metric
ACL 2025, 复旦大学
Instruction Tuning
https://github.com/UmeanNever/NovelSum
这篇文章对现有研究中的多样性策略进行了系统评估,认为“多样性”的量化和定义缺乏统一指标,导致很多方法甚至不如随机选择。文章将现有的多样性指标分为3类:
- 词汇多样性(TTR, vocd-D):仅关注词汇的重复率,无法区别语义差异,性能差
- 距离型语义多样性(DistSum, KNN Distance):忽略了语义空间中的信息密度,高估“远距离样本”的多样性,低估高密度领域(如代码、数学)中样本的细微差距
- 分布型语义多样性(Facility Location, Partition Entropy):仅关注数据集对全量数据的覆盖度,忽略了单个样本的独特性,低估“样本间距离”大的数据集的多样性
基于以上分析,文章提出了一种新的多样性评估指标 NovelSum:一个样本的独特性可以通过与邻近点的差异量化(Proximity-Weighted Sum),同时对于信息密度高的区域应该赋予更高权重(Density-Aware Distance)。然后基于该指标进行贪心选择。
其中,接近度权重 \(w()\) 为距离排名的倒数,密度因子\(\sigma()\)为KNN平均距离的倒数(密度越高,值越大)。
消融实验显示近邻加权是NovelSum性能提升的关键(提升了43%),密度感知提升了(6.2%)
baseline: K-Center-Greedy、QDIT、K-means、Repr Filter、Random(所有的quality filter都被去掉了)
train data set: 全量数据源由 WizardLM(196K)、ShareGPT(103K)、UltraChat(207K)混合而成,筛选后子集规模固定为 10K;
benchmark: MT-bench, AlpacaEva(GPT4 as Judge)
models: Llama3-8B, Qwen-2.5-7B

 浙公网安备 33010602011771号
浙公网安备 33010602011771号