并查集及其应用专题--全网最详细版
并查集
并查集是用来查找和合并集合关系的
这个集合必须是不交集
支持查找和合并两种操作,修改后可以支持删除单个元素并分离集合。
使用动态开点线段树还可以实现可持久化并查集
来自 https://oi-wiki.org/ds/dsu/
并查集类似于树,普通并查集是无向的,但是加权并查集是可以做到有向的,详见NOI2001食物链
查找操作:查找两个元素是否在同一集合
假设有一个集合,元素是{1,2,3}
还有一个集合元素是{4,5,6}
现在查找2和4在不在同一个集合,则需要枚举2所在或4所在集合所有元素直到找到4或到最后也没有4
太慢了,有一个更好的方法,如果我们随便选一个集合中的某个元素作为该集合的代表元素,
其它该集合中的元素都指向这个元素
当查找元素所在集合时,只要找到这个元素的指向的元素的最顶级元素即根,这个根就是代表节点
最后判断这两个元素的根是否相同即可
这里遇到一个问题,就是这个根元素怎么标记呢,可以让它所指向的元素是自己,这样询问时只要遇到指向元素是自己的元素,那么说明找到根了,即可停止
我们把这个指向的元素叫做这个元素的父亲
注意树不只有两层,因为在合并操作时集合被合并,原先两个集合的根中有一个变成了子节点,此时层数会增加,而这个代表元素是整棵树的根,这个点的父亲只是它的原来的集合的根,因为集合已经合并,所以判断两个元素是否在同一集合中时要用整棵树的根,因此要递归寻找这个元素的父亲直到元素的父亲是自身时停止寻找并返回该元素。当然这个过程可以循环解决,只需要定义临时变量为该元素的父亲,然后这个变量不断等于这个变量的父亲,直到其父亲等于自身为止,然后返回该变量即可
举例:
假设集合1以3为根,集合2以6为根,则
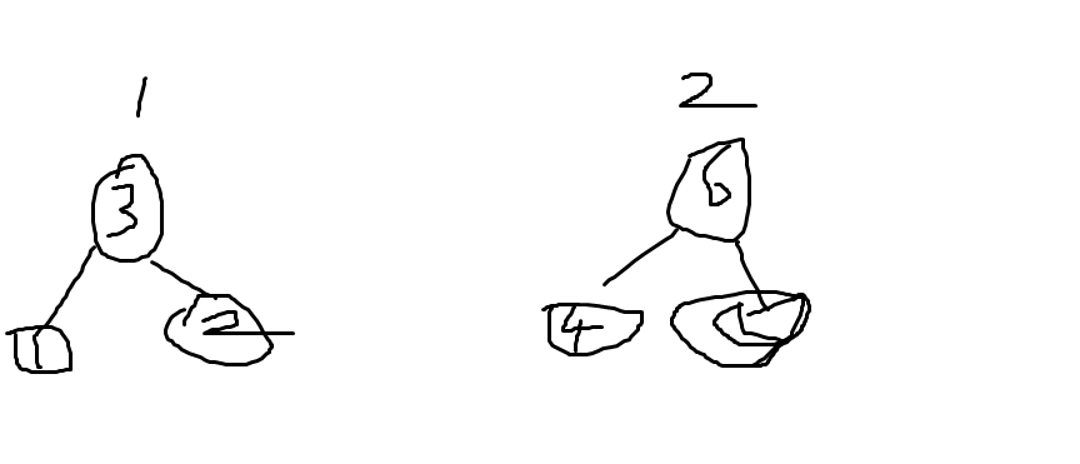
2和4的根分别是3和6,不等,所以不在一个集合
1和3的根分别是3和3,相等,所以在一个集合。
合并操作:
把两个元素 所在集合 合并为一个集合,合并后两个集合等同于在一个大集合中,此时一个元素所在集合的根要变成子节点,另一个作为大集合的根。
如何合并:
很简单,先查找两个元素的根,然后把一个根的父亲改为另一个根,这样就完成了合并 ,但是如果两个元素的根相同说明在一个集合就直接返回不用合并
例:
以查找时为例
合并前:
假设新根是6
合并后:
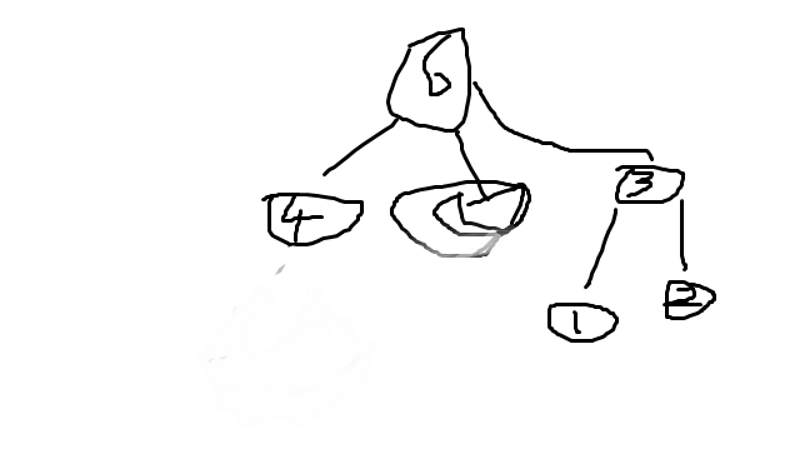
再查找2和4:
2的父亲是3,3的父亲是6,6的父亲是6
4的父亲是6
在一个集合
注意合并时要把一个根直接接到另一个根上,而不是接到子节点上!!
路径压缩
在查找时我们不关心这个元素的父亲,只要这个元素通过找父亲能找到根即可,所以每次查找后把查找的这条链上的元素的父亲直接改为根,这样不影响查找,而且减少以后查找的次数(减小树高)
递归时只要返回时return fa[x]=find(fa[x])即可,这样会递归到最后找到根把父亲从上往下回溯着改
循环法要找到根后再开一个循环,先让循环变量=它的父亲,然后把它的父亲改为根,直到 父亲=父亲 时停止(到根了),这是自下往上的。
但是一次只能保证这条链上的,不能是全树都改好,所以后面删除元素时比较麻烦
按秩合并:(启发式合并)
在合并时我们要将其中一个元素所在集合的根变为子节点,另一个变为新根,可是哪一个变为子节点呢?
显然将尺寸小的接到尺寸大的集合上更好,这样查找大的时还是那个复杂度,可反之要花更多的时间,但是尺寸小的集合造成影响小,所以要把尺寸小的接到尺寸大的集合上
但是尺寸是什么呢?
尺寸既可以是一个集合的元素个数即点数,也可以是树的高度,它们优化的效果是等价的
如果以点数为尺寸,那么合并时把点数小的根父亲等于点数大的根,点数大的根的点数+=点数小的根的点数,这个叫做启发式合并,其他数据结构也常用
如果以高度为尺寸,那么合并时把高度小的根父亲等于高度大的根,但是高度不变,为什么? 这个叫做按秩合并,不是很常用
只要a的高度小于b,因为高度是整数,所以a的高度比b至少少一,把a接到b的下面,此时这个高度不能超过b
什么时候高度改变?当a和b高度相等时,可以随便接,但是无论怎么接高度都增加1
假如a接在b下面,那么b的这个子树的高度为b,而b的其他子树中最大的高度是b-1,因此b的高度变为b+1!
复杂度:
\(n\)个元素,\(m\)次操作(查找或合并)
空间复杂度:
由于每个元素都有一个父亲,所以\(fa\)数组大小是\(n\),故空间复杂度\(O(n)\)
时间复杂度:
既使用路径压缩,又使用按秩合并:
每个操作平均时间复杂度\(O(α(n))\)
\(α\)是反阿克曼函数,近似于常数
总操作平均复杂度\(O(mα(n))\)
只使用路径压缩:
总操作平均复杂度\(O(mα(n))\)
总操作最坏复杂度\(O(m logn )\)
只使用按秩合并:
总操作平均复杂度\(O(m logn )\)
删除操作:
修改后的并查集支持单个元素的删除
但是需要注意的是删除不是说删除这个点和这个点所连的点,而是仅仅删除这个点,其余与他相连的点仍然在原并查集中,但这个点独立成一个集合
在完美形态的并查集中,每个节点的父亲都是根,此时删除一个节点就是把这个节点的父亲改为自己,这样不影响其他节点,但是实际上路径压缩只能将这条链上的节点的父亲改为根,所以实际并查集形态不可估计
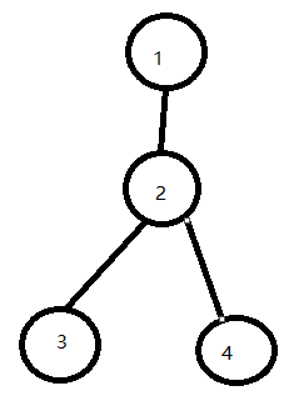
删除2后
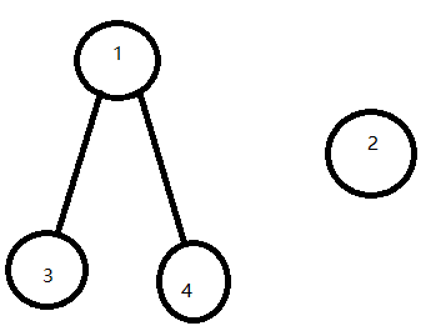
那么我们可以用盒子来代替这个真正的节点去合并,而我们真正的每一个节点都指向每一个盒子
详细:
每一个节点都对应一个盒子,每个节点的父亲起初都是对应的一个新盒子
当我们合并集合时,我们只合并节点指向的盒子的所在集合,仍然符合按秩合并
当我们删除时把节点的父亲改为一个新的,从未使用过的盒子,原盒子保持空,这样原来集合的关系可以通过这个空盒子保留
当我们查找时查找节点所在盒子的根
仍然可以用路径压缩
一旦这个节点被删除,就到了新盒子,此时这个节点和原来的集合并不在一个集合中,所以删除有效
删除的节点再和别的节点合并改变的是它新盒子的集合
与原来集合无关
还可以有还原操作,就是删除后把这个节点还原到它最近被删除的集合中,显然可以再合并 ,但也可以数组记录每个节点上一次被删除的盒子编号,然后把这个节点的指向改为上一次被删除的盒子编号,这样就完全还原上一次这个节点的形态,不需要合并了
#include<iostream>
#include<cstdio>
#include<cstring>
using namespace std;
int fa[10006],fa1[90006],t=10007,lasts[10006];
inline int finds(int x ){
if(fa1[x]==x)return x;
return fa1[x]=finds(fa1[x]);
}
inline void inserts(int x,int y){
int a=finds(x),b=finds(y);
if(a==b)return;
fa1[a]=b;
}
inline void deletes(int x){
lasts[x]=fa[x];
fa[x]=t;
++t;
}
inline void restore(int x){
fa[x]=lasts[x];
}
int main(){
memset(fa,-1,sizeof fa);
memset(lasts,0,sizeof lasts);
for(int i=0;i<90006;++i){
fa1[i]=i;
}
int m;
cin>>m;
for(int i=0;i<m;++i){
char op ;int x,y;
cin>>op;
if(op=='U'){
cin>>x>>y;
if(fa[x]==-1)fa[x]=x;
if(fa[y]==-1)fa[y]=y;
inserts(fa[x],fa[y]);
}else if(op=='F'){
cin>>x>>y;
if(fa[x]==-1)fa[x]=x;
if(fa[y]==-1)fa[y]=y;
if(finds(fa[x])!=finds(fa[y])){
cout<<0<<endl;
}else{
cout<<1<<endl;
}
}else if(op=='D'){
cin>>x;
deletes(x);
}else{
cin>>x;
restore(x);
}
}
return 0;
}
带权并查集:
本质是并查集的向量拓展
把树看成dag图,每个元素的权值记录的是它和它父亲之间的边权,主要记录的是一种关系,这里是一些普通的数字,但在实际问题中边权往往是一些关系,最后可能还要取模
目的是利用路径压缩求出元素到根节点的边权和,然后给定任意两个元素求出这两个元素之间的某些关系(与根有关的和差)
假设权值数组为\(w\)
路径压缩时可以先递归找根并存储,然后把w[x]+=w[fa[x]],最后把fa[x]改成根
因为是递归,所以会先找到根,然后回溯像前缀和一样层层加,直到加到当前元素为止,此时w[x]就为x到根节点的权值和,同时这条链上的元素都把权值改了
但是重点在合并
合并两个元素x,y所在集合,其中x,y两个元素之间权值为有向值s(把x合并到y或把y合并到x)
由于x到y和y到x只需调换顺序即可,所以只考虑x到y
假如x的根是px,,y的根是py,省略中间的链,因为路径压缩时会改,问题在于x到y的权值明确,x到px的权值明确,y到py的权值明确,但是px到py就不知道了
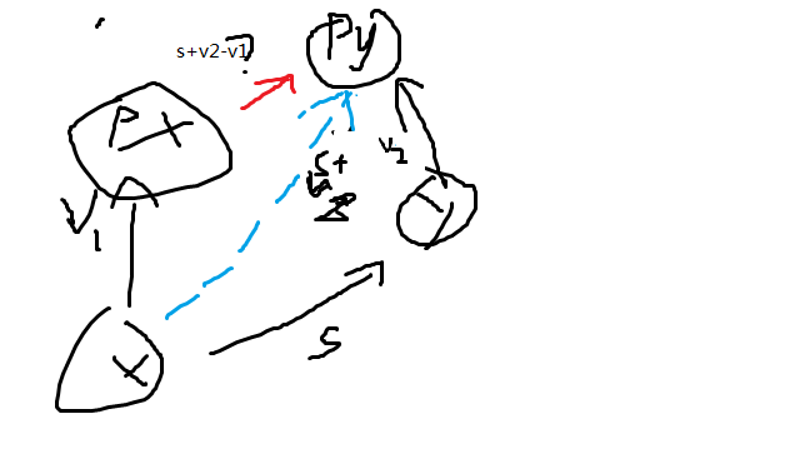
可以辅助线来解决
先求x到py,这里x到y和y到py等价于x到py,所以x到py权值用向量加法为s+v2
同理,x到py又等于v1+px到py
所以px到py=s+v2-v1
这是个抽象问题,这里加的是向量,而不是向量的模,很懵逼
但是实际问题往往要取模或者是压根再开一个数组,详见NOI2002银河英雄传说
基础操作就是这些,还有一些例题
HDU-3038-How Many Answers Are Wrong
来自 https://blog.csdn.net/yjr3426619/article/details/82315133
有M个数,不知道它们具体的值,但是知道某两个数之间(包括这两个数)的所有数之和,现在给出N个这样的区间和信息,需要判断有多少个这样的区间和与前边已知的区间和存在矛盾。例如给出区间和\([1,4]\)为20,\([3,4]\)为15,再给出\([1,2]\)为30,显然这个\([1,2]\)的值就有问题,它应该为20-15=5。
由于不知道每句区间是否正确,所以要根据先前的正确的区间来推出这个区间,如果推不出就是对的,因为是新的,如果推出了,若题目给的与之前的正确的区间推出的区间的值相等就说明正确,可以忽略,若不相等,则不正确,也忽略,留下正确的值
注意不相等是唯一矛盾的时候,\([1,10]=50\) ,\([1,5]=100\)这看起来不对,但实际上题目没说每个数是正数,所以这也是对的,可能\([6,10]=-50\)
我们想到区间的合并,很像并查集
但是这是个闭区间,没有公共点,我们需要半开半闭区间,不能全开区间,这样\([1,4]=(0,5)\) \([3,4]=(2,5)\) \([1,2]=(0,3)\),没有公共点
常见左闭右开区间,这样\([1,4]=[1,5)\) \([1,2]=[1,3)\) \([3,4]=[3,5)\)
可以把1 3和3 5合成1 5
所以要先改区间
然后就可以用并查集了。
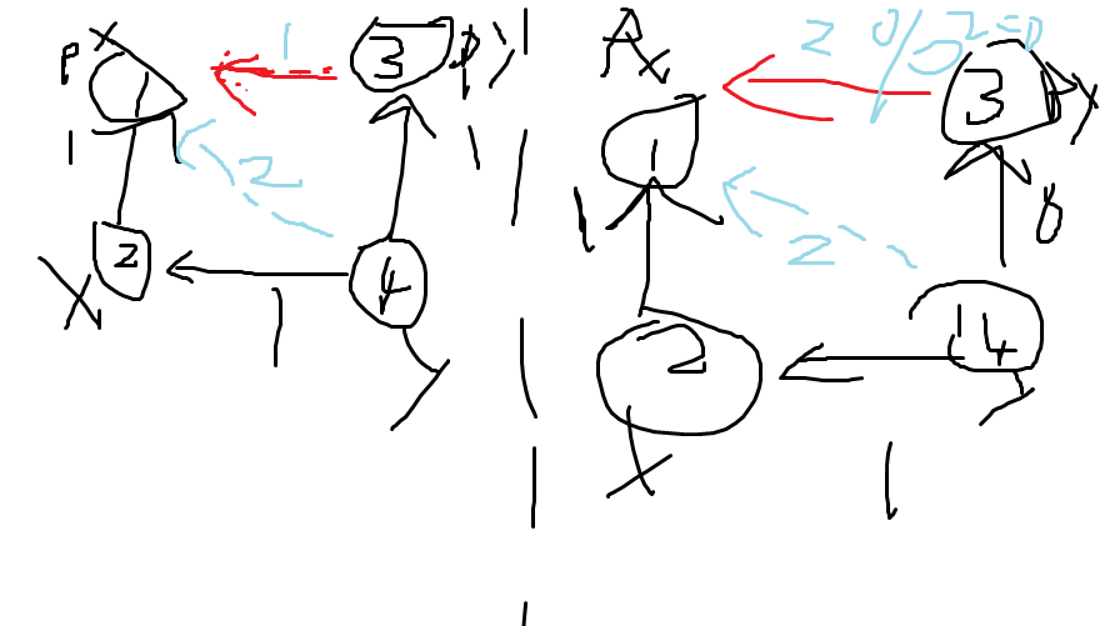
看图:
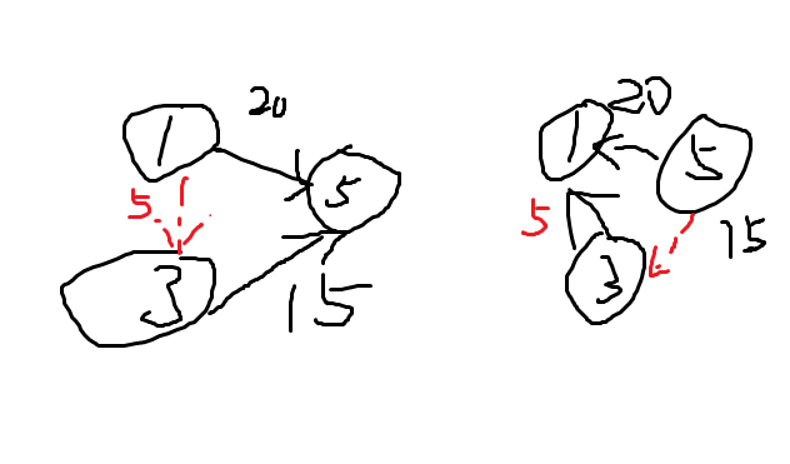
这两种都是对的
都是向量的加法
第一种以5为根,合并时并没有真正1 3连边和求值,要 求 1 3时只需要用1 5的和减去3 5的和即可
第二种以1为根,合并时用公式s+v2-v1,因为3是孤立点,所以v2=0,即s-v1,这就算出了1 3
然后求1 3的和用1 3的和 减去 1 1的和即可
由此可见询问区间x y时是sum x - sum y还是反过来完全取决于合并时把x的集合并到y还是把y的集合并到x,如果x-》y就sum x -sum y
如果y-》x就sum y -sum x
所以不能启发式合并
那么什么时候算不出x y的和?
当区间两个端点在一个集合时说明两个sum可以用向量求,而不在一个集合时求不出,因为两个集合没有交集,中间的数不知道是多少
因此,思路如下:
读入区间
合并两个区间端点,若在一个集合中时公式算出和,比对给出的,不合法记录下来
不在一个集合时认为这个和是对的,把这两个合并,以这个和为权值
合并时用基本向量公式
若x->y就用w(x,y)+w(y,py)-w(x,px)
若y->x就用w(x,y)+w(x,px)-w(y,py)
px就是x的根
w就是之间的和
初始化把w数组置为0,即使是根节点到自身也满足上面的公式
把fa【i】=i不要等于-1,容易出错
#include<iostream>
#include<cstdio>
#include<cstring>
using namespace std;
int fa[2000003],v[2000003];
inline int find(int x){
if(fa[x]==x)return x;
int k=find(fa[x]);
v[x]+=v[fa[x]];
fa[x]=k;
return k;
}
inline void inserts(int x,int y,int a,int b,int z){
fa[a]=b;
v[a]=z+v[y]-v[x];
}
int main(){
memset(fa,-1,sizeof fa);
memset(v,0,sizeof v);
int n,m;
cin>>n>>m;
int cnt=0;
for(int i=0;i<m;++i){
int x,y,z;
cin>>x>>y>>z;
y=y+1;//闭区间改成开区间
if(fa[x]==-1)fa[x]=x;
if(fa[y]==-1)fa[y]=y;
int a=find(x),b=find(y);
if(a!=b){
inserts(x,y,a,b,z);
}else{
if(v[x]-v[y]!=z)cnt++;
}
}
cout<<cnt<<endl;
return 0;
}
另一个例题:
HihoCoder-1515-分数调查
描述
小Hi的学校总共有N名学生,编号1-N。学校刚刚进行了一场全校的古诗文水平测验。
学校没有公布测验的成绩,所以小Hi只能得到一些小道消息,例如X号同学的分数比Y号同学的分数高S分。
小Hi想知道利用这些消息,能不能判断出某两位同学之间的分数高低?
输入
第一行包含三个整数N, M和Q。N表示学生总数,M表示小Hi知道消息的总数,Q表示小Hi想询问的数量。
以下M行每行三个整数,X, Y和S。表示X号同学的分数比Y号同学的分数高S分。
以下Q行每行两个整数,X和Y。表示小Hi想知道X号同学的分数比Y号同学的分数高几分。
对于50%的数据,$1 <= N, M, Q <= 1000 $
对于100%的数据,\(1 <= N, M, Q<= 100000 1 <= X, Y <= N -1000 <= S <= 1000\)
数据保证没有矛盾。
输出
对于每个询问,如果不能判断出X比Y高几分输出-1。否则输出X比Y高的分数。
样例输入
10 5 3
1 2 10
2 3 10
4 5 -10
5 6 -10
2 5 10
1 10
1 5
3 5
样例输出
-1
20
0
分析一下:
考虑传递性和向量性
显然是图,x比y高可以x-》y连一条边,权值是x比y高的分数
看图:
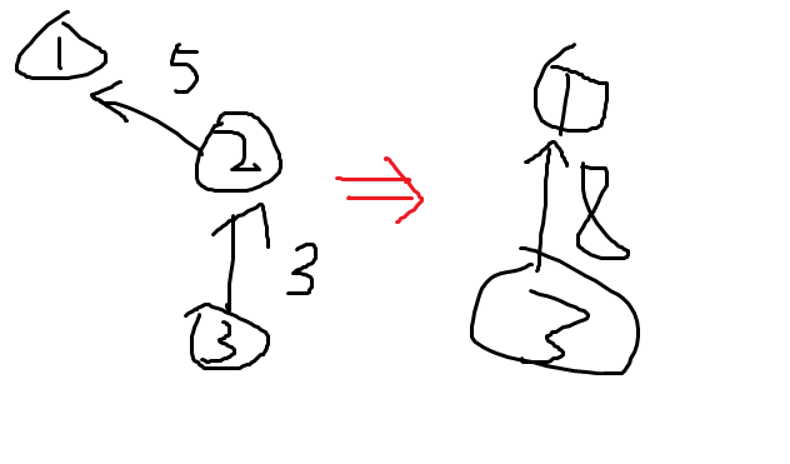
3比2高3分,2比1高5分,所以3比1高8分
具有传递性
向量合并:
对于1比2高8分
3比4高3分
1比3高3分
则1比4高6分
则2比4高-2分
注意当x比y低时就是x比y高y比x高的分数的相反数
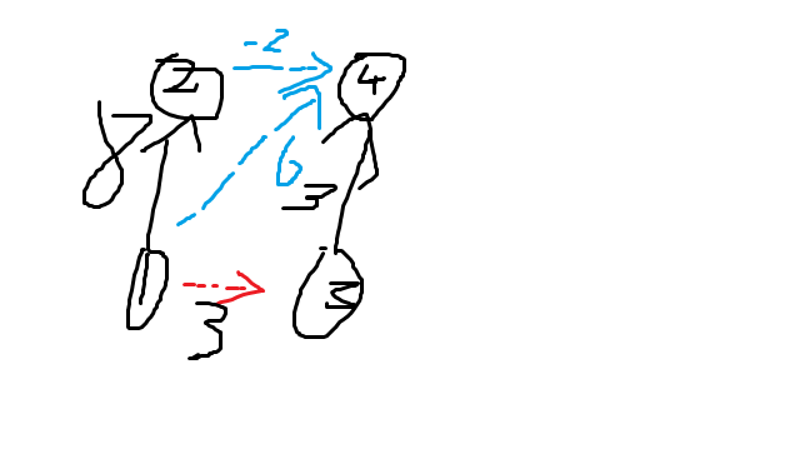
具有向量性
因此可以用并查集
那么怎么由x到根节点权值和y到根节点权值推出x比y高的分呢?
即w【x】-w【y】
什么时候无解呢?
当x与y在一个并查集时可以根据根节点来求x与y的权值,当x与y不在一个并查集时不能得出x到y的权值,
如:
1比2高3分,3比4高2分,无法求出2比3高的分数
w数组代表x比x的父亲高的分数
路径压缩时统计和,得知x到根的权值
合并时同样不能启发式合并,要把x合并到y
向量法计算合并后的权值
合并x和y所在集合
询问时先判断x与y是否在一个并查集,是输出w[x]-w[y]
不是输出-1!
#include<iostream>
#include<cstdio>
#include<cstring>
using namespace std;
int fa[100003],v[100003];
inline int find(int x){
if(fa[x]==x)return x;
int k=find(fa[x]);
v[x]+=v[fa[x]];
return fa[x]=k;
}
inline void inserts(int a,int b,int x,int y,int z){
fa[a]=b;
v[a]=z+v[y]-v[x];
}
int main(){
memset(fa,-1,sizeof fa);
memset(v,0,sizeof v);
int n,m,q;
cin>>n>>m>>q;
for(int i=0;i<m;++i){
int x,y,k;
cin>>x>>y>>k;
if(fa[x]==-1)fa[x]=x;
if(fa[y]==-1)fa[y]=y;
int a=find(x),b=find(y);
if(a!=b){
inserts(a,b,x,y,k);
}
}
for(int i=0;i<q;++i){
int x,y;
cin>>x>>y;
// cout<<9;
if(fa[x]==-1)fa[x]=x;
if(fa[y]==-1)fa[y]=y; //这里注意可能x和y还没出现过,所以要检验-1,因为-1做下标会re
int g=find(x),f=find(y);
if(g!=f){
cout<<-1<<endl;
}else{
cout<<v[x]-v[y]<<endl;
}
}
return 0;
}
种类并查集:
当我们在维护一些复杂的传递关系时,普通的并查集无法满足需求
维护朋友的朋友是朋友,敌人的敌人是朋友,
异性的异性是同性
\(a\)吃\(b\) \(b\)吃\(c\) 则\(c\)吃\(a\)
这种具有反向传递性的关系时,可以用加权并查集
当然很复杂
于是有一种占空间更大但是简单的种类并查集
我们可以根据关系的数目确定出要把fa数组开一定的倍数
然后把这个数组分成几类,用来维护反向传递性
洛谷P1525 关押罪犯
来自 https://zhuanlan.zhihu.com/p/97813717
团伙
食物链
异性问题
这是最简单的
因为只有男和女两种
当a和b同性b和c同性时a和c同性,这是基础并查集的合并
当a和b异性b和c异性时a和c同性
当a和b同性b和c异性则a和c异性
后两个具有反向传递性
这里我们fa多开一倍数组
我们假定\(a\)和\(a+n\)为异性,\(n\)是正常开的数组大小
所以当\(a\)为\(n-1\)时\(a+n=2n-1\),因此需要开两倍数组
当\(a\)和\(b\)是同性时,我们可以合并\(a\)和\(b\)所在集合,因为都是同性
还可以合并\(a+n\)和\(b+n\)所在集合,因为\(a+n\)是与\(a\)异性的,\(b+n\)是与\(b\)异性的,当\(a\)和\(b\)同性时,\(a\)的异性和\(b\)的异性是同性
而\(a+n\)里的所有元素全是一个性别
\(b+n\)也是
所以可以合并
当\(a\)和\(b\)异性时
那么把\(a\)的异性和\(b\)合并,把\(b\)的异性和\(a\)合并
即合并\(a+n,b\) ; \(b+n,a\)
因为\(a\)的异性肯定和\(b\)同性
\(b\)的异性肯定和\(a\)同性
为什么这样可以做到那三条?
第一条显然满足
第三条\(a\)和\(b\)同性则\(a,b\) \(a+n,b+n\)分别在一个并查集,\(b\)和\(c\)异性则\(b+n ,c\) \(c+n,b\)分别在一个并查集,所以\(a+n\)和\(c\) \(a\)和\(c+n\)分别在一个并查集,\(a\)和\(c\)不在一个并查集,所以\(a\)和\(c\)是异性
第二条比较复杂
\(a\)和\(b\)是异性时\(a\)和\(b\)不在一个并查集,但是\(b\)和\(a+n\),,\(a\)和\(b+n\)分别都在一个并查集
\(b\)和\(c\)异性时\(b\)和\(c\)不在一个并查集,但是\(b\)和\(c+n\) ,,\(c\)和\(b+n\)分别在一个并查集
所以\(a+n\)和\(c+n\)在一个并查集,,\(a\)和\(c\)也在一个并查集
所以\(a+n\)和\(c+n\),,,\(a\),\(c\)分别在一个并查集
即它们分别同性
所以第二条满足
那么查找时问\(a\)和\(b\)同性还是异性只需要看:
\(a\)和\(b\)在一个并查集时说明是同性,\(a\)和\(b\)不在一个并查集时若\(a\)和\(b+n\)同性\(a\)和\(b\)就是异性(就两种性别)
注意\(a\)和\(b\)不在一个并查集不能说明是异性
因为如1 2同性
3 4同性
再说2 3同性,2和3
不在一个并查集中,而2的异性集合中没有3,所以2 3同性这是对的
但是原题:
每次给出两个昆虫的关系(异性关系),然后发现这些条件中是否有悖论
所以要动态判断
当输入\(a\)和\(b\)后
若\(a\)和\(b\)有一个没有初始化就先初始化(\(a,b,a+n,b+n\)中没有初始化的都要初始化)然后把\(a\)和\(b\)按照前面的规则合并
然后这个数据是对的
若\(a\)和\(b\)已经初始化也不能说明它们的关系已经确定,如上面的例子,此时判断\(a\)和\(b\)关系是否与输入的相符,若相符就是对的,若不符就是不对的,就跳过。若不在一个并查集中且\(a\)的异性和\(b\)也不在一个并查集中关系就未确定,此时\(a\)和\(b\)的关系再合并,\(a\)和\(b\)的关系是对的
这时路径压缩和按秩合并都可以用
#include<iostream>
#include<cstdio>
#include<cstring>
using namespace std;
int fa[200002];
inline int find(int x){
if(fa[x]==x)return x;
return fa[x]=find(fa[x]);
}
inline void inserts(int x,int y){
int a=find(x),b=find(y);
if(a==b)return;
fa[a]=b;
}
int main(){
int n,m;
cin>>n>>m;
memset(fa,-1,sizeof fa);
for(int i=0;i<m;++i){
int x,y;
cin>>x>>y;
if(fa[x]==-1)fa[x]=x;
if(fa[y]==-1)fa[y]=y;
int a=find(x),b=find(y);
if(a==b)cout<<"N"<<endl;
else{
if(fa[y+n]==-1)fa[y+n]=y+n;//注意y+n x+n可能没用过,所以要先初始化
if(fa[x+n]==-1)fa[x+n]=x+n;
inserts(x,y+n);
inserts(x+n,y);
cout<<"Y"<<endl;
}
}
return 0;
}
再用加权并查集做一下:
w数组记录x到x父亲的关系(1异性 0同性)
路径压缩时求和,但是要取模2
为什么?
有1号 2号 3号
成链状,现在把3路径压缩,使得w【3】是1与3的关系
1与2同性且2与3同性时:w[1]=0 w[2]=0 w[3]=0 w[3new]=w[1]+w[2]+w[3]=0 0%2=0 满足1 3同性
1与2同性且2与3异性时 w[1]=0 w[2]=0 w[3]=1 w[3new]=w[1]+w[2]+w[3]=1 1%2=1 满足1 3异性
1与2异性且2与3同性时w[1]=0 w[2]=1 w[3]=0 w[3new]=w[1]+w[2]+w[3]=1 1%2=1 满足1 3异性
1与2异性且2与3异性时最重要 w[1]=0 w[2]=1 w[3]=1 w[3new]=w[1]+w[2]+w[3]=2 2%2=0 满足异性的异性是同性
可见在压缩求和时可以顺便%2,这样最后的关系是正确的,实际上这是分了两类,所以%2
然后合并,同样不能按秩合并
向量法
具有向量性,但要取模
由此可见,我们把y连到x的向量公式\(w[py]=w(x,y)+w[x]-w[y]+2\)再取模2即可,这样合并后px和py的关系是正确的
+2是为了防止\(w[x]\)与\(w(x,y)\)都是为0,而\(w[y]=1\),会出现负数
那么询问关系时怎么处理?
询问\(x\)和\(y\)的关系
当\(x\)和\(y\)在一个并查集时即\(x\)和\(y\)的关系确定
当\(x\)和\(y\)不在一个并查集时\(x\)和\(y\)的关系不确定,给出的这个关系是对的,然后合并
注意与种类并查集不同的是:\(x\)和\(y\)在一个并查集并不能说明x和y的关系是同性,只能说明它们有明确的关系,而同异性是根据权值数组w来确定的
当关系确定时
若\(x\)和\(y\)的共同根节点是\(px\),那么\(x\)和\(y\)的关系就是$(w[x]-w[y]+2) \mod 2 $
+2同样防止出现负数
如\(x\)到\(px\)是1,y到py是1
则\(x\)到\(y\)是1-1=0 0%2=0
符合要求
然后判断与给出的是否符合即可
注意初始化每个节点的w都是0,即根节点和它自己是同性,否则会造成问题。
注意这里给出\(x\) \(y\)时我们把\(y\)连向\(x\)
#include<iostream>//x连接向y
#include<cstdio>
#include<cstring>
using namespace std;
int fa[1006],w[1006];
inline int finds(int x){
if(fa[x]==x)return x;
int k=finds(fa[x]);
w[x]=(w[x]+w[fa[x]])%2;
return fa[x]=k;
}
inline void inserts(int x ,int y,int a,int b,int z){
fa[a]=b;
w[a]=z+w[y]-w[x];
w[a]=w[a]+2;
w[a]=w[a]%2;
}
int main(){
memset(fa,-1,sizeof fa);
memset(w,0,sizeof w);
int n,m;
cin>>n>>m;
for(int i=0;i<m;++i){
int x,y;
cin>>x>>y;
if(fa[x]==-1)fa[x]=x;
if(fa[y]==-1)fa[y]=y;
int a=finds(x),b=finds(y);
if(a!=b){
inserts(x,y,a,b,1);
cout<<"Y"<<endl;
}else{
if((w[y]-w[x]+2)%2==1){
cout<<"Y"<<endl;
}else{
cout<<"N"<<endl;
}
}
}
return 0;
}
种类并查集可以维护敌人的敌人是朋友这样的关系,这种说法不够准确,较为本质地说,种类并查集(包括普通并查集)维护的是一种循环对称的关系。
来自 https://zhuanlan.zhihu.com/p/97813717
还有一类问题:
拆地毯
修复公路 贪心
||
营救 贪心
这两道题等价,都是最大值的最小化
星球大战 倒推
这些题都是些思维题,主要是倒推和贪心
拆地毯是星球大战和修复公路结合
并查集联通块数量统计
关于并查集联通块数量统计,首先要知道初始状态的联通块个数,然后每一次合并是若不在一个并查集则合并能使联通块数量减少\(1\),若在一个并查集则没有贡献,切忌哈希统计
这指的是一个节点原先是独立的集合时。
但是如果是一个节点从原先不存在到出现并连边,联通块的数量要分类讨论
若这个点没有任何边将要和它相连,那么出现后联通块个数反而加一,,若这个节点出现并连第一条边,则联通块数量不变,因为节点出现相当于增加了一个联通块,连一条边合并后联通块减少了\(1\),所以不变
若这个节点已经出现且连的不是第一条边,那么合并(当然不在一个集合时)后联通块数量减少\(1\),因为此时这个节点已经在一个集合中了,若再与另一个集合连边,就会使得集合数目减少\(1\)
当遇到拆毁/彻底删除(连着点和边一起删除,破坏了集合关系)时,应该倒推,寻求全部
删除后的状态,然后倒着合并
当遇到移动集合元素,分离单一元素为独立集合(保持原来集合关系,只是那一个元素空了)时,应该用盒子来做,,即源节点指向盒子,对于合并与查找都是操作盒子,当移动或分离改变源节点指向的盒子,就可以保留原来集合关系,但是实现源节点的转移或分离。
并查集的另一种写法
就是路径压缩 启发式合并 找父亲 使用了一个数组完成
当f【i】为负数时,说明这个节点是根节点,此时f[i]的值是这个根节点的树的节点个数的相反数
当f[i]为正数时,f[i]是i的父亲
这样查找x的根时,当f[x]<0时返回x,是根节点,其余情况照常路径压缩return f[x]=find(f[x])
合并时x y先找根节点,如果根节点不同,那么就进行合并
设x的根为rx
y的根为ry
如果f[rx]>f[ry] 就交换rx和ry
这样f[rx]一定<=f[ry]
即-f[rx]>=-f[ry]
此时rx的树的尺寸大小>=ry的树的尺寸大小
rx做根
f[rx]+=f[ry]
更新rx的尺寸的相反数
f[ry]=rx
此时ry就指向了rx,做了儿子
这两步顺序不能错,因为在第二步之前f[ry]记录的是ry下的树尺寸的相反数,f[rx]+=f[ry]可以更新尺寸,而第二步是因为ry做了儿子,所以f[ry]成了ry的父亲,如果颠倒,那么f[rx]就可能变成正数从而误认为不是根节点
理解:
对于两个集合的根节点rx,ry
它们的f已经计算好,是它们的树的尺寸的相反数,合并是通过比较这个尺寸来实现启发式 合并,然后假设rx做新根
那么rx的尺寸相反数自然要更新,加上ry的尺寸的相反数(都是负数),然后ry的f就变成了指向父亲的作用,ry的父亲是rx
查找时若x是根节点,f[x]不一定=-1,也有可能<-1,代表的是尺寸的相反数,同时能说明找到了根节点
当f[x]>0时说明f【x】是x的父亲,要继续递归并路径压缩
初始化时f[]要置为-1,代表每个树尺寸为1
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
int f[10006];
inline int finds(const int&x ){
if(f[x]<0)return x;
return f[x]=finds(f[x]);
}
inline void unions(const int&x,const int &y){
int rx=finds(x);
int ry=finds(y);
if(rx==ry)return;
if(f[rx]>f[ry])swap(rx,ry);
f[rx]+=f[ry];
f[ry]=rx;
}
int main(){
memset(f,-1,sizeof f);
int n,m;
cin>>n>>m;
for(int i=1;i<=m;++i){
int opt;
cin>>opt;
int x1,y1;
cin>>x1>>y1;
if(opt==1){
unions(x1,y1);
}else{
int rx1=finds(x1);
int ry1=finds(y1);
if(rx1==ry1)cout<<"Y"<<endl;
else cout<<"N"<<endl;
}
}
return 0;
}
例题详解
P1197 [JSOI2008]星球大战
https://www.luogu.com.cn/problem/P1197
特殊的倒推法
问题等价于\(n\)个节点\(m\)条无向边
然后拆掉一些点和它们相连的所有边,每拆一个点就输出联通块个数
暴力肯定超时
有合并且无向,可以用并查集
需要想一个特殊的方法
我们不拆点,这样很困难
我们倒着加点
先把除了所有拆的点有关的所有边之外的剩下的边用并查集合并
这是拆掉这些点后的状态,枚举剩下的点求出联通块个数
然后从后往前加点,因为前面的点拆掉时后面的点还要连着
接下来每加一个点就把它们相连的边合并一下,然后合并时若两个点都在一个并查集则合并这两个点对联通块没有影响,若不在一个并查集那么合并,注意加一个节点可能合并多条边并减小多个联通块数目
然后把这个减小后的变量记录 下来逆序输出
我们要把所有要摧毁的点所相连的边存起来,以便于后面倒推加边,并且剩下的边要合并起来作为所有都拆毁后的联通块,联通块一定要边合并边统计,切忌最后哈希统计
我们如果哈希记下边,读拆毁点时找边太难了,但我们可以哈希记下拆毁点,再遍历边时找出拆毁点相连的边会容易,同时还可以合并剩下的边,这是哈希的第一个妙用
原来\(n\)个点
去掉\(k\)个后\(n-k\)个,此时每合并一次减小一个联通块
接下来倒着加点,把点所连的边合并
注意:
有时一条边的另一个点也是拆毁点,此时要看先后顺序来决定是否连边
当拆毁点靠前时,实际上这个点现在已经被拆毁,不能向他连边
当拆毁点靠后时,这个点已经恢复,所以要向他连边
因为从后往前,所以每恢复一个点就要把\(hash\)改为\(2\),即已恢复,此时可以向他连边,而非拆毁点肯定要向他连边,而\(hash\)为\(1\)的还处于拆毁状态,不连边
然后算联通块的个数
注意:
这里拆毁节点不是把边断开,而是连同点一块删除,因此加边后联通块不能减1
#include<iostream>
#include<cstdio>
#include<cstring>
#include<vector>
using namespace std;
int fa[400006];
struct edge{
int a,b;
}edges[200006];
int goal[400006];
int hash1[400006];//hash1数组记录这个节点状态,0为不是要摧毁的节点,1为当前已摧毁的节点,2为当前未摧毁的节点(即已倒退回来到这个节点)
vector<int> edge2[400006];//每一个要摧毁的节点所相连的边
int out[400006];//因为从后往前加边,所以要逆序输出
int num=0;
inline int finds(int x){
if(fa[x]==x)return x;
return fa[x]=finds(fa[x]);
}
inline void inserts(int x,int y,int a,int b){
// if(a==b)return ;
fa[a]=b;
}
int main(){
memset(hash1,0,sizeof hash1);
for(int i=0;i<400006;++i){
fa[i]=i;
}//不要memset -1,这样后面要一个个改,要提前初始化好
int n,m;
cin>>n>>m;
for(int i=0;i<m;++i){
int x,y;
cin>>x>>y;
edges[i].a =x;//edge数组存边
edges[i].b=y;
}
int k;
cin>>k;
for(int i=0;i<k;++i){
cin>>goal[i];
hash1[goal[i]]=1;//哈希表定为1因为这个点是已经拆毁了的
}
int lian1=n-k;
for(int i=0;i<m;++i){
if(hash1[edges[i].a ]==1){
edge2[edges[i].a].push_back(edges[i].b );
}//这两个if要并列不要else,因为两个a b点有可能都是要拆毁的点
if(hash1[edges[i].b ]==1){
edge2[edges[i].b].push_back(edges[i].a );
}
if((!hash1[edges[i].a ])&&(!hash1[edges[i].b ])){
int root1=finds(edges[i].a ),root2=finds(edges[i].b);//如果两个都不拆毁,那么就要合并来算出联通块
if(root1!=root2){//根节点相同时合并没有用,联通块不变
inserts(edges[i].a,edges[i].b,root1,root2);
lian1-=1;
}
}
}
//cout<<lian1<<endl;
out[num]=lian1;
++num;
for(int i=k-1;i>=0;--i){//要等于0,因为全部恢复后是全连好的联通块,是要求输出的
int root1=finds(goal[i] );
int fl1=1,fl2=1;//fl1是看这个点是否孤立,若整个遍历没有可以连的边说明它是孤立的,此时恢复后联通块反而加1,fl2看这个点是否是第一次连边
若是,说明这是把原先不存在的点和一个集合连边,此时一旦连起之后联通块不减少,因为原先这个点不存在,而现在连起之后就存在了
而若不是第一次连边,那么这个点已经存在了,此时它与其他点构成了集合
那么这是连边就能将联通块个数减一
for(int j=0;j<edge2[goal[i]].size();++j){
if(hash1[edge2[goal[i]][j]]!=1){
fl1=0;
int root2=finds(edge2[goal[i]][j]);
if(root1!=root2){
inserts(edge2[goal[i]][j],goal[i],root2,root1);
if(fl2){
fl2=0;
continue;
}
lian1-=1;
}
}
}
if(fl1)lian1+=1;
hash1[goal[i]]=2;
out[num++]=lian1;
}
for(int i=num-1;i>=0;--i){
cout<<out[i]<<endl;
}
return 0;
}
P1111 修复公路
https://www.luogu.com.cn/problem/P1111
这是并查集的贪心算法
\(n\)个节点\(m\)条无向边,给定边的修好时间
求最小能使\(n\)个节点相互连通的时间
无向图,连边相当于合并,可以使用并查集
因为是最小。可以考虑贪心,先把边按时间由小到大排序并遍历
然后从小开始遍历,每遍历一条边就把这两个节点合并起来,用\(size\)数组记录根的尺寸,启发式合并,如果这个根的\(size\)是\(n\),那就说明所有节点都在一个并查集中,就输出此时的时间,否则若到最后也没有联通,就输出\(-1\)
为什么贪心正确?
我们选择的时间是从小到大中刚刚保持联通的时间,假设有完成联通的时间比这个小的情况,那么之前遍历到的时间中就必定有这个时间,那么答案就会更小,而如果有联通时间比这个大的话那么这个时间下已经保持联通,再加边也没有用,不如这个更小的时间
虽然前面合并的时候有一些对联通无用的重复边被加上了,但这并不影响答案,因为我们不求和,而是求一个满足条件的最小值,时间是一点点流逝的,修建公路是同步进行的,修这些无用的公路之时也在修有用的公路,所以这些重复边对答案没有影响
这个题与
P1396 营救
来自 https://www.luogu.com.cn/problem/P1396
有相似之处
P1396 营救
来自 https://www.luogu.com.cn/problem/P1396
这是个重点题
题目的意思是说找一条从\(s\)到\(t\)的路径使其边权的最大值是所有每条\(s\)到\(t\)的路径中边权最大值最小的那个
就是说\(s\)到\(t\)的某条路径权值是这条\(s\)到\(t\) 路径中边权的最大值
而要求一条路径使其权值最小,输出这个最小值
而最小值最大是指\(s\)到\(t\)某条路径权值是这条路径中边权的最小值
要求1条路径使得权值最大
也可以按边权从小到大排序,从小开始合并,直到刚好\(s\)到\(t\)联通,输出这个权值
为什么成立呢?
考虑这个权值显然是这里\(s\)到\(t\)边权中的最大值,但如何保证它是所有路径中最小的?
假设还有联通路径的最大值比这个还小,那么这条路径的所有边权都比这个还小,那么它们应该在这个的前面访问到,如果前面能构成联通,那么就会更早选择,而不会选择这个,所以是这个最小的
最小值最大就应该从大到小排序合并到刚好联通为止
而这个权值也是当前路径的最小值。
假设还有联通路径的最小值比这个还大,那么路径所有边权都比这个大,那么它们就会在这个之前访问,若能构成联通就会更早选择,可是选择了这个就说明没有比这个还大的解
P2330 [SCOI2005]繁忙的都市
来自 https://www.luogu.com.cn/problem/P2330
改造的道路尽量少就是要刚好保持联通不要有无用的边
所以从小到大排序合并时如果当前的两个点已经在一个并查集中就说明这条边无用,不要统计数量,跳过
P2121 拆地毯
来自 https://www.luogu.com.cn/problem/P2121
不要求联通,只是要求取的点不能有环
所以就像星球大战那样先把所有边拆掉,然后按权值从大到小排序
注意这里统计和,从大到小遍历,把当前两个点合并,如果发现已经在一个并查集就说明已经联通,再加边就会形成环,就不要把这个权值加进去
一直加到\(k\)个真正的地毯(不成环),输出和
因为这是从大到小最大的\(k\)个或是除去一些之后最大的\(k\)个
所以和是最大的
黄粱一梦,终是一空
本文来自博客园,作者:hicode002,转载请注明原文链接:https://www.cnblogs.com/hicode002/p/19526925

 浙公网安备 33010602011771号
浙公网安备 33010602011771号