
MYSQL之索引,B+tree的简介梳理
索引的本质,就是加快查询的速度,类似于查字典,不断的缩小范围,直到查出我们要到数据。
那么索引有几种类型?
1,普通索引:加速查找
2,唯一索引:
primary key:主键就是一个索引,不为空,约束,没有重复
unique:唯一索引,不为空,唯一,约束,可以为null,但只有一个null
3,联合索引:(注意,这里联合索引一定要遵循最左原则,下面举例说明)
例如:primary key + name,主键和name一起联合索引
unique + phone唯一索引
name + phone 普通联合索引
4,fulltext:全文索引,用于一大段的文章,效果比较好
关于磁盘IO:
我们知道,数据库的所有数据都是存放到硬盘里面的,而且是机械硬盘,不会存到固态硬盘(固态硬盘的存储寿命有限,存固态硬盘会有风险)。
那么读取数据时候,硬盘就会有IO操作,而且硬盘读取的时候,会把相邻的也读取到内存中,例如ABC三个磁盘块,读取B时候,会把A和C也加载到内存中。因此,数据的结构就很关键了。
索引的数据机构:
举个例子:比如没有索引,数据全部都存在磁盘上, 有上百万条数据,那么数据库在查找某一个数据的时候,是不是要按顺序遍历,这样会导致大量的IO操作,这也是导致查找变慢的原因,因此B+树就很好的控制了这个查找次数。
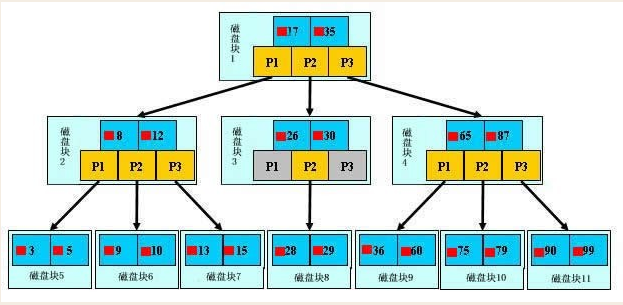
B+ 树是一种树数据结构,通常用于数据库和操作系统的文件系统中。B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。B+ 树元素自底向上插入,这与二叉树恰好相反。
举个例子:
假如要查找数据15,那么从根节点出发,此时,磁盘进行一次IO操作,把磁盘块1加载到内存中,进行对比,15,比17小,那么直接通过P1指针,加载磁盘模块2
加载磁盘模块2,这时候磁盘进行第二次IO操作,15和8,12进行对比,比8和12大,那么和二叉树一样,最右边,通过P3指针,把找到磁盘模块7
加载磁盘模块7,这时候进行了第三次IO操作,15和13,15比对,15=15,那么数据就找到了。非常快!
而且,三层的B+树可以表示上百万的数据,三次IO就可以查到上百万数据里的一条,可以说是非常快了!
这里提一句:B+树是把所有的键值都存在叶子节点,普通节点是不存储数据的,只有指针,所以这棵树就是特别的矮胖。
B树则是每个节点都有键值,因此比B+树高很多。
接下来,就是建立索引和测试索引:
先建立个app_user表
CREATE TABLE `app_user` ( `id` bigint UNSIGNED NOT NULL AUTO_INCREMENT, `name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `email` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `phone` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `gender` tinyint UNSIGNED NULL DEFAULT 0, `password` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `age` tinyint NULL DEFAULT NULL, `create_time` datetime NULL DEFAULT CURRENT_TIMESTAMP, `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) USING BTREE, INDEX `id_name_phone_app_user`(`name`, `phone`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 3000001 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
插入三百万条数据:
delimiter $$
CREATE DEFINER=`root`@`localhost` FUNCTION `mcok_data`() RETURNS int
BEGIN declare num int DEFAULT 3000000; declare i int DEFAULT 1; WHILE i<num DO insert into app_user(name,email,phone,gender,password,age) VALUES (concat('用户',i),'122345@qq.com',CONCAT('18',FLOOR(RAND()*((999999999-100000000)+100000000))), FLOOR(RAND()*2),UUID(),FLOOR(RAND()*100)); set i=i+1; END WHILE; RETURN i; END
运行:select mcok_data();
先试试,没有索引的情况下,随便差一个数据的速度
select * from app_user app where app.`name`='用户2000000' ;
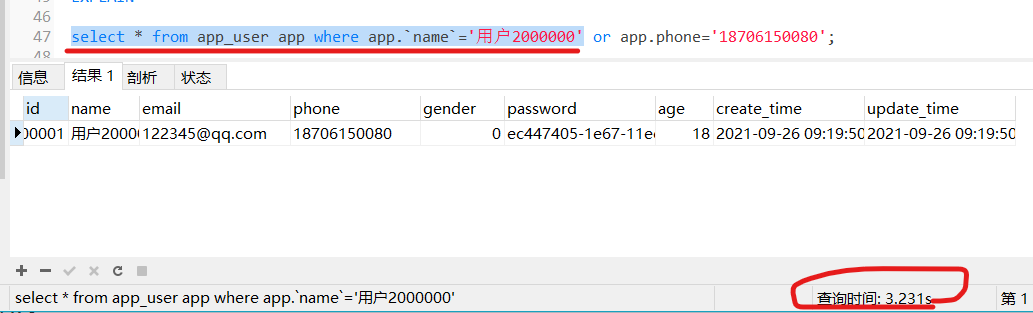
3.231s,差一个数据要三秒多
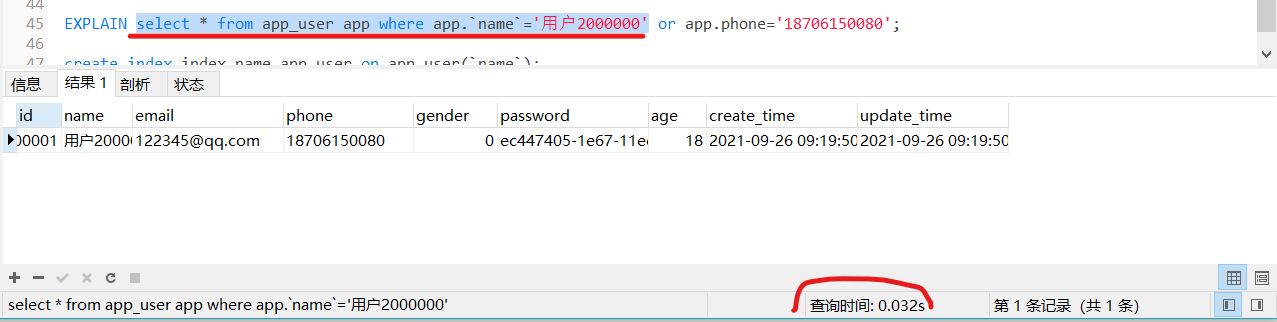
EXPLAIN select * from app_user app where app.`name`='用户2000000' or app.phone='18706150080';
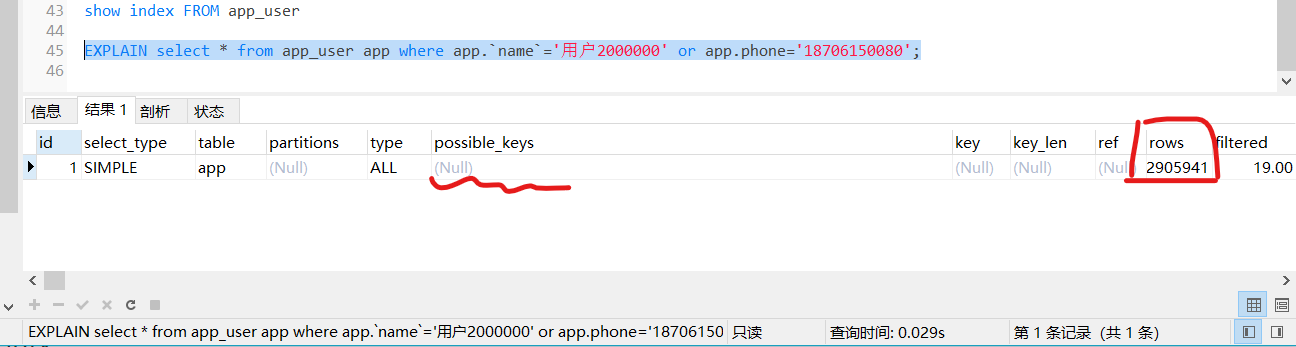
查这个语句搜索了2905941次
没必要啊,如果是高访问量的网站,这用户体验就非常非常差了。甚至会挂掉。
那么,我们来加个name的索引试试:
语法:create index 索引名称 on 表名(字段);
create index index_name_app_user on app_user(`name`);
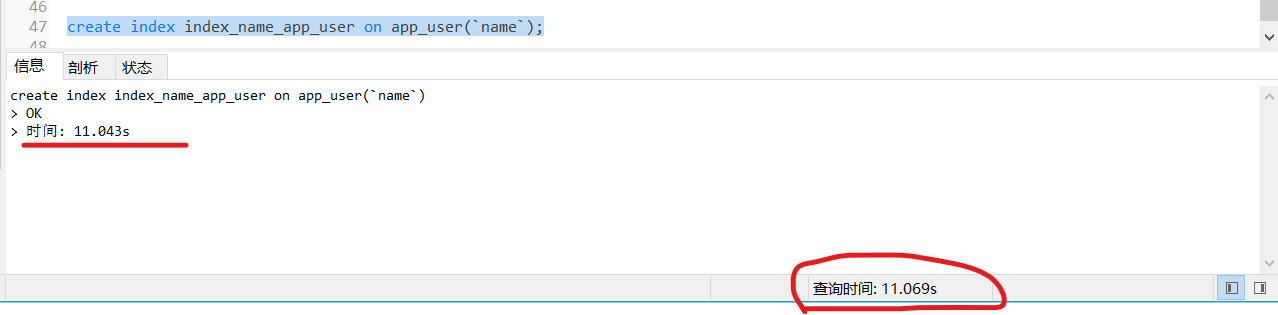
我们再来试一下:
select * from app_user app where app.`name`='用户2000000';速度提升巨大
select * from app_user app where app.`name`='用户2000000' or app.phone='18706150080';
但是,如果加上or条件后,速度又变了回去?这里就要提一嘴,phone字段是不是没有建立索引?
用or条件,必须两个都要有索引,否则索引会失效!
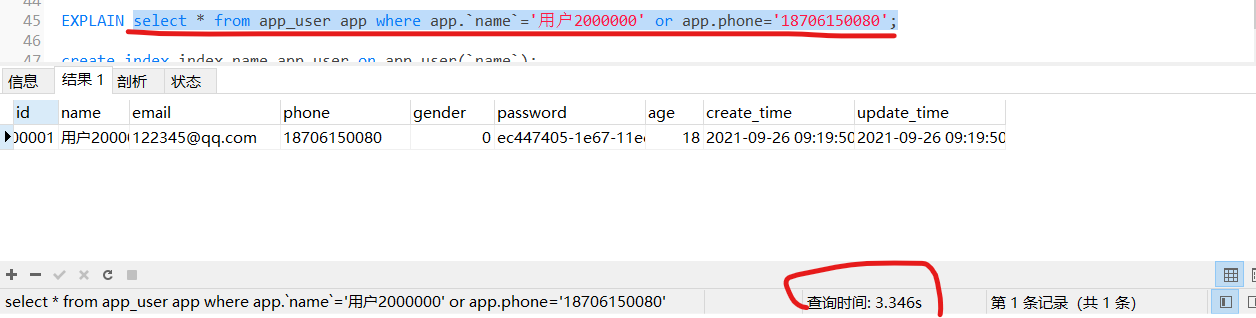
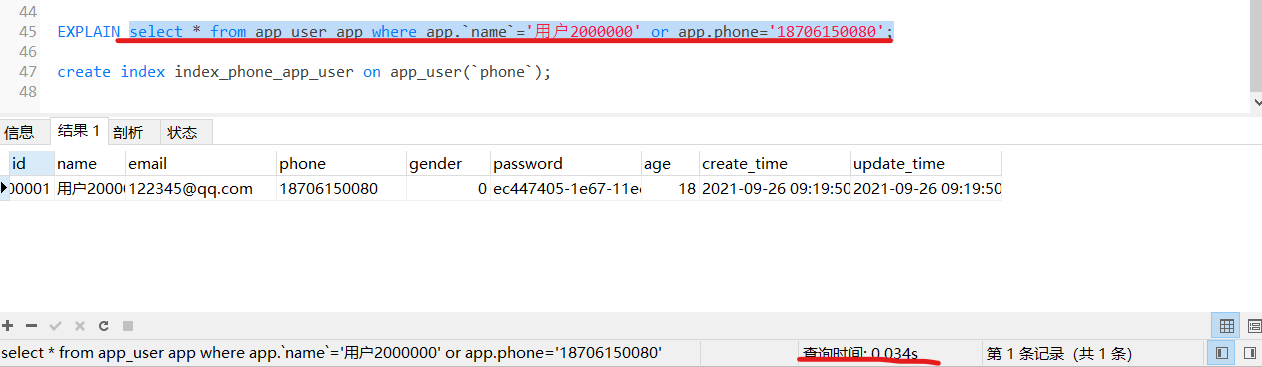
加了一个phone的索引后
再试一下主键索引:
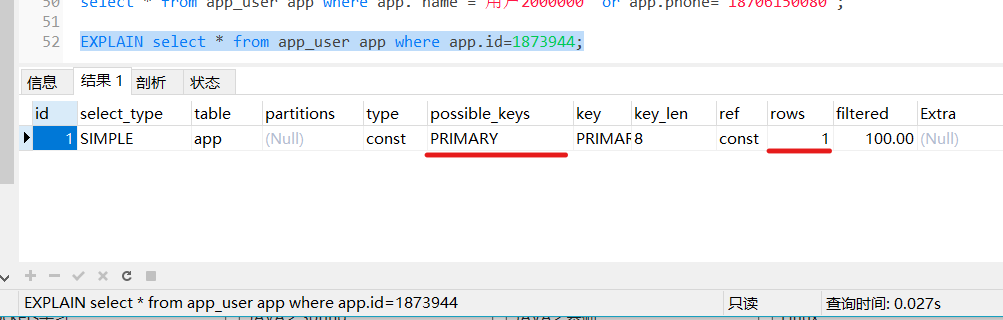
select * from app_user app where app.id=1873944;
非常快
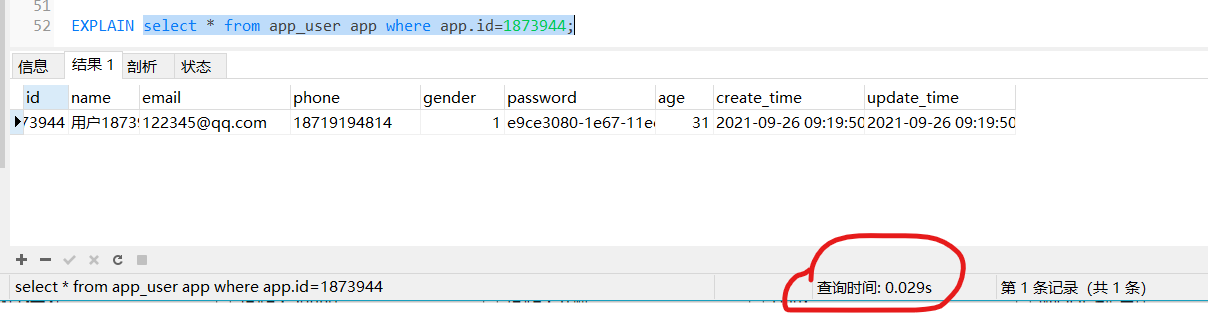
用explain看一下,索引是primary,行数只查了1行,直接就定位到了
那么接下来,试试联合索引
create index index_name_phone_app_user on app_user(`name`,`phone`);
另外两个索引删掉,只剩这个
index_name_phone_app_user
试试。
使用or关键词,是用不了这个索引的
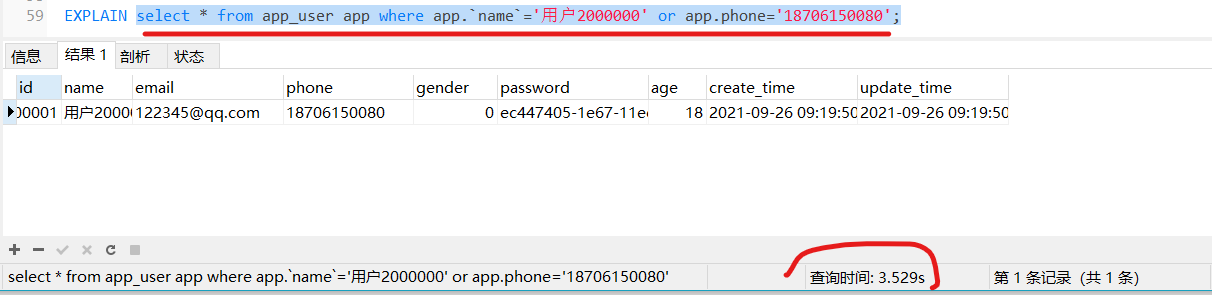
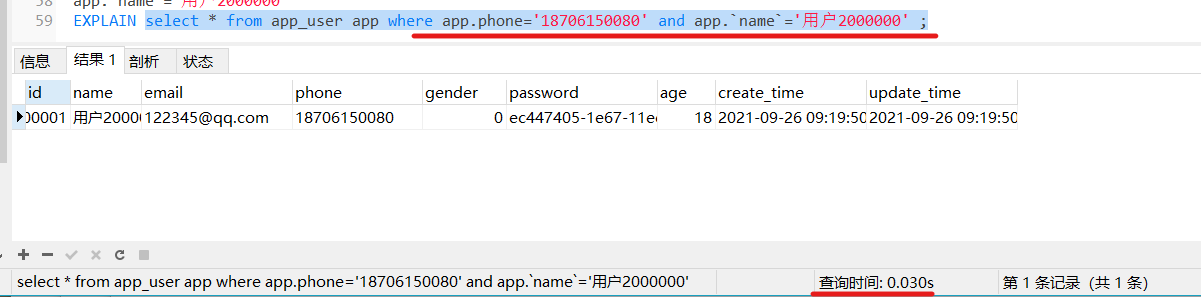
使用and关键词,可以使用索引
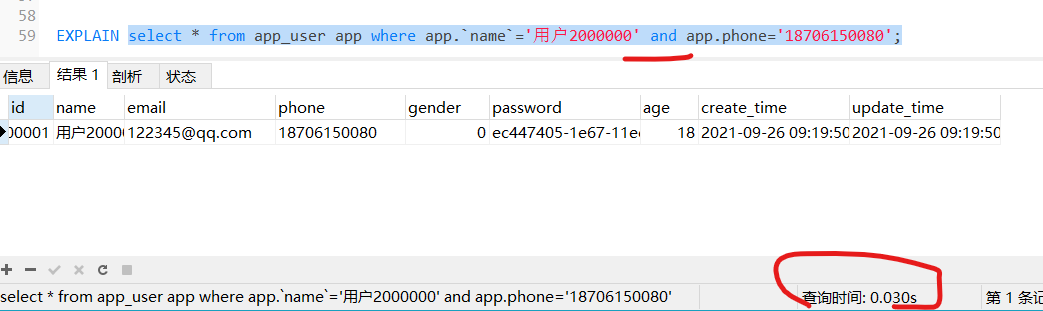
那么试试单独查找看
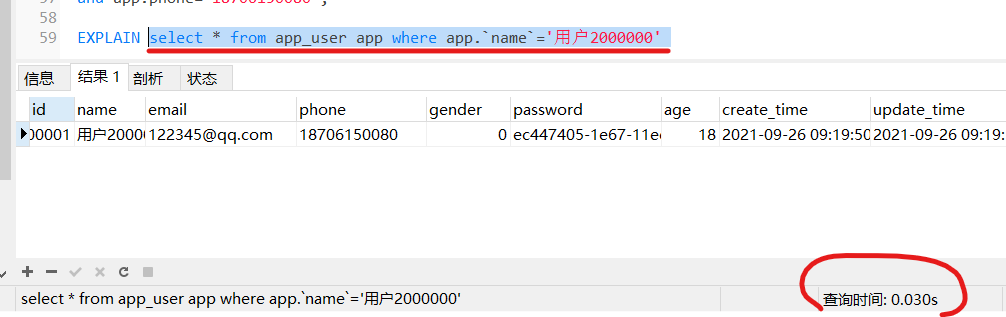
可以看到,单独的name作为条件查询,是可以使用联合索引的,如果使用phone单独查询呢?
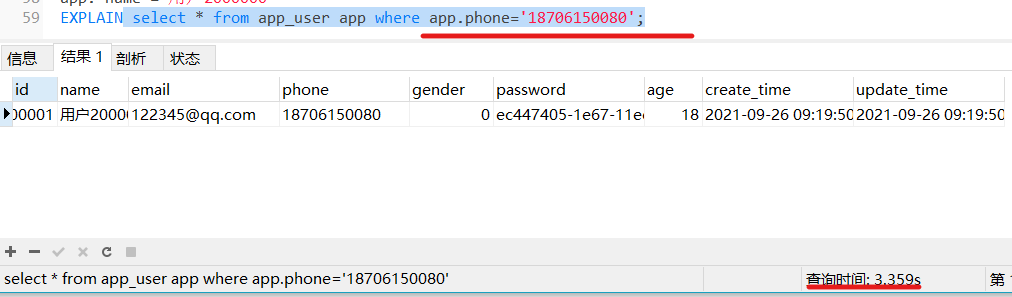
无法使用索引!!
这里就是最左原则:查询条件里面,必须要有索引里最左边的字段,索引才会被使用,这个字段可以在where条件的任意地方,但是,要有。

至此,MYSQL的笔记从oneNote全整理到blog了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号