

DD出行供需匹配、单量预测分析
背景描述
在出行问题上,中国市场人数多、人口密度大,总体的出行频率远高于其他国家,滴滴出行占领了国内绝大部分的网络呼叫出行市场,面对着巨大的数据量以及与日俱增的数据处理需求。为实现高频出行下的运力均衡,供需预测就是其中的一个关键问题。供需预测的目标是准确预测出给定地理区域在未来某个时间段的出行需求量及需求满足量。如果能预测到在未来的一段时间内某些地区的出行需求量比较大,就可以提前对营运车辆提供一些引导,指向性地提高部分地区的运力,从而提升乘客的整体出行体验。
一、提出问题
1. 运营情况?日活跃用户数(DAU)
2. 高峰期、平峰期的供需匹配?
3.地区未来7天单量预测
4.用户价值分析(RFM)
5.司、乘高活跃向低活跃监控?
二、数据来源与说明
数据来源:https://www.heywhale.com/mw/dataset/5f16971a94d484002d2a2eba/content
数据说明:训练数据集为M市2016年1月连续三周的打车出行数据信息。(数据级850W+)
具体数据如下,选取订单信息表、区域定义表、天气信息表进行分析。订单信息表
| 字段 | 类型 | 含义 | 示例 |
|---|---|---|---|
| order_id | string | 订单ID | 70fc7c2bd2caf386bb50f8fd5dfef0cf |
| driver_id | string | 司机ID | 56018323b921dd2c5444f98fb45509de |
| passenger_id | string | 用户ID | 238de35f44bbe8a67bdea86a5b0f4719 |
| start_district_hash | string | 出发地区域哈希值 | d4ec2125aff74eded207d2d915ef682f |
| dest_district_hash | string | 目的地区域哈希值 | 929ec6c160e6f52c20a4217c7978f681 |
| Price | double | 价格 | 37.5 |
| Time | string | 订单时间戳 | 2016-01-15 00:35:11 |
订单信息表主要覆盖了一张订单的基本信息,包括这张订单的乘客,以及接单的司机(driverid =NULL表示driverid为空,即这个订单没有司机应答),及出发地,目的地,价格和时间。
区域定义表
| 字段 | 类型 | 含义 | 示例 |
|---|---|---|---|
| district_hash | string | 区域哈希值 | 90c5a34f06ac86aee0fd70e2adce7d8a |
| district_id | string | 区域映射ID | 1 |
区域定义表主要表示区域的信息,结果需将区域哈希值映射为其相应的ID。
天气信息表
| 字段 | 类型 | 含义 | 示例 |
|---|---|---|---|
| Time | string | 时间戳 | 2016-01-15 00:35:11 |
| Weather | int | 天气 | 7 |
| temperature | double | 温度 | -9 |
| PM2.5 | double | pm25 | 66 |
天气信息表主要表示整个城市的每天间隔5分钟段的天气情况(实际采集数据有缺失,实际间隔时间有19min、7h不等,不能以统一5min间隔作为表连接条件)。其中的weather字段表示天气的实时描述信息,而温度以摄氏温度表示,PM2.5为实时空气污染指数。
指标定义
应答率:呼叫订单被应答的比例,应答订单/呼叫订单。
应答完单率:应答订单被完成订单比例,应答订单/完成订单。
三、导入数据
1.用Navicat将数据导入MySQL数据库。
发现 weather表不同日期行数不一致,即每天的时间戳不等,先不合并,视需要情况而定。
2.查看表结构
desc `order_data_2016-01-01`; desc `weather_data_2016-01-01`; desc cluster_map;
3.合并表信息(订单表、区域表)
3.1合并订单表、区域表
#新建空订单表 drop table if exists `order_data_2016_01`; create table `order_data_2016_01`( order_id varchar(32) ,driver_id varchar(32) ,passenger_id varchar(32) ,start_district_hash varchar(32) ,dest_district_hash varchar(32) ,price double ,time timestamp ); #合并订单表 insert into order_data_2016_01 select * from `order_data_2016-01-01` union all select * from `order_data_2016-01-02` union all select * from `order_data_2016-01-03` union all select * from `order_data_2016-01-04` union all select * from `order_data_2016-01-05` union all select * from `order_data_2016-01-06` union all select * from `order_data_2016-01-07` union all select * from `order_data_2016-01-08` union all select * from `order_data_2016-01-09` union all select * from `order_data_2016-01-10` union all select * from `order_data_2016-01-11` union all select * from `order_data_2016-01-12` union all select * from `order_data_2016-01-13` union all select * from `order_data_2016-01-14` union all select * from `order_data_2016-01-15` union all select * from `order_data_2016-01-16` union all select * from `order_data_2016-01-17` union all select * from `order_data_2016-01-18` union all select * from `order_data_2016-01-19` union all select * from `order_data_2016-01-20` union all select * from `order_data_2016-01-21`
3.2 关联地址
#关联地址表,地址去哈希化(转为区域映射ID) drop table if exists order_data_01; select @i:=0; create table order_data_01 as( select (@i:= @i+1) as r1_id ,order_id ,driver_id ,passenger_id ,c1.district_id as start_id ,c2.district_id as dest_id ,price ,time from order_data_2016_01 left join cluster_map c1 on start_district_hash = c1.district_hash left join cluster_map c2 on dest_district_hash =c2.district_hash );
四、数据清洗
4.1 检查重复值
drop table if exists order_data_02; select @a:=0; create table order_data_02 as( with t1 as( select * ,row_number()over(partition by order_id order by r1_id) as row_n ,count(order_id) over(partition by order_id order by r1_id) as cnt_n from order_data_01 where r1_id > 0 ) #查看重复值 -- select -- * -- from t1 -- where r1_id > 0 and cnt_n>1
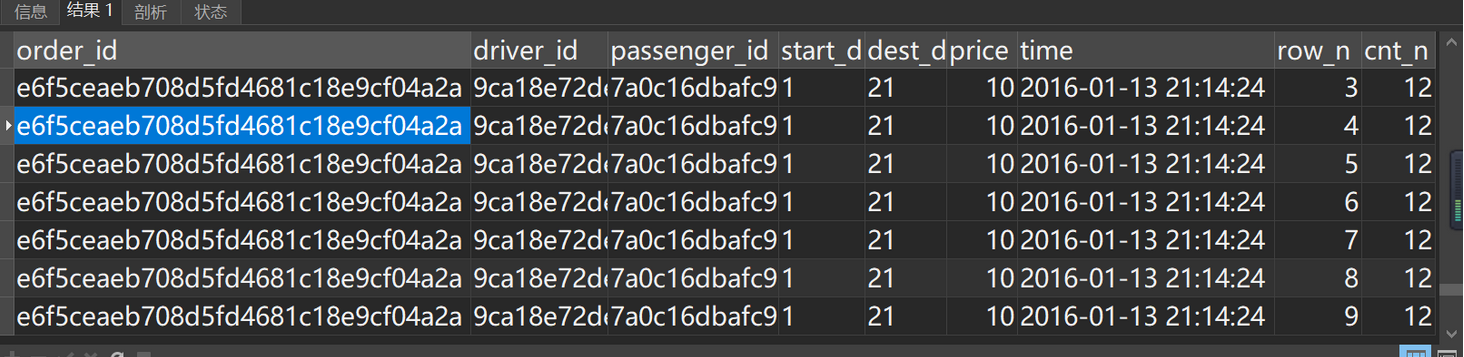
#去重复 select (@a:= @a+1) as r2_id ,order_id ,driver_id ,passenger_id ,start_id ,dest_id ,price ,time from t1 where r1_id >0 and row_n=1 );
4.2 检查空值
select sum(ISNULL(r2_id)) as r2_idn ,sum(ISNULL(order_id)) as order_idn ,sum(ISNULL(driver_id)) as driver_idn ,sum(ISNULL(passenger_id)) as passenger_idn ,sum(ISNULL(start_id)) as start_idn ,sum(ISNULL(dest_id)) as dest_idn ,sum(ISNULL(price)) as pricen ,sum(ISNULL(time)) as timen from order_data_02 where r2_id >0

目的地 dest_id 缺失 1346269 条数据,其他0缺失,目的地id不影响分析,可忽略。
4.3 检查异常值
#查看数据整体情况,以及订单价格区间,时间范围,是否有异常 select count(1) as'订单数' ,count(distinct driver_id) as'司机数' ,count(distinct passenger_id) as'乘客数' ,min(price) ,max(price) ,min(time) ,max(time) from order_data_02 where r2_id>0 and price<1000000000 and time<'2029-02-01 00:00:00';

4.3.1 价格侧
#查看price=0 订单
select
count(1) as '0元单量'
,concat(round((count(1)/8518049)*100,2),'%') as '0元单量占比'
from order_data_02
where r2_id> 0
and price= 0
and time<'2029-02-01 00:00:00'
 0元订单占比0.06%,可能是0元打车活动
0元订单占比0.06%,可能是0元打车活动
#查看最大价格price=1731 订单
select * from order_data_02 where r2_id>0 and price= 1731 and time<'2029-02-01 00:00:00';

订单司机为空,属未应答订单。
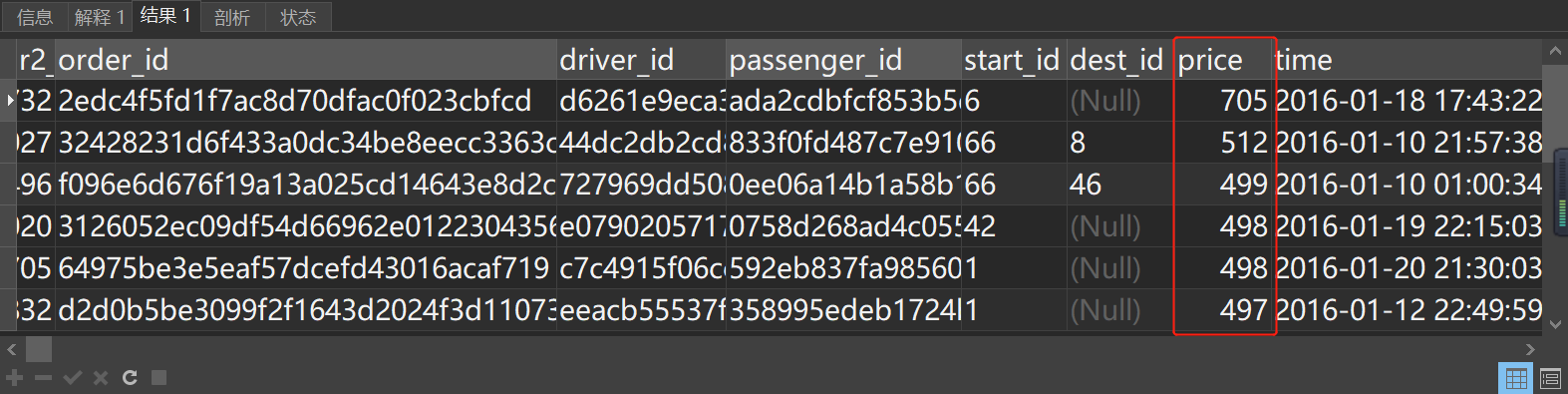
#查看已接订单的价格TOP
select * from order_data_02
where r2_id>0
and price<1000000000
and time<'2029-02-01 00:00:00'
and driver_id<>'NULL'
order by price desc limit 10
#查看705乘客的订单
select * from order_data_02
where r2_id>0
and price<1000000000
and time<'2029-02-01 00:00:00'
and driver_id<>'NULL'
-- order by price desc limit 10
and passenger_id='ada2cdbfcf853b5d4ae96c963631c50c' limit 50;
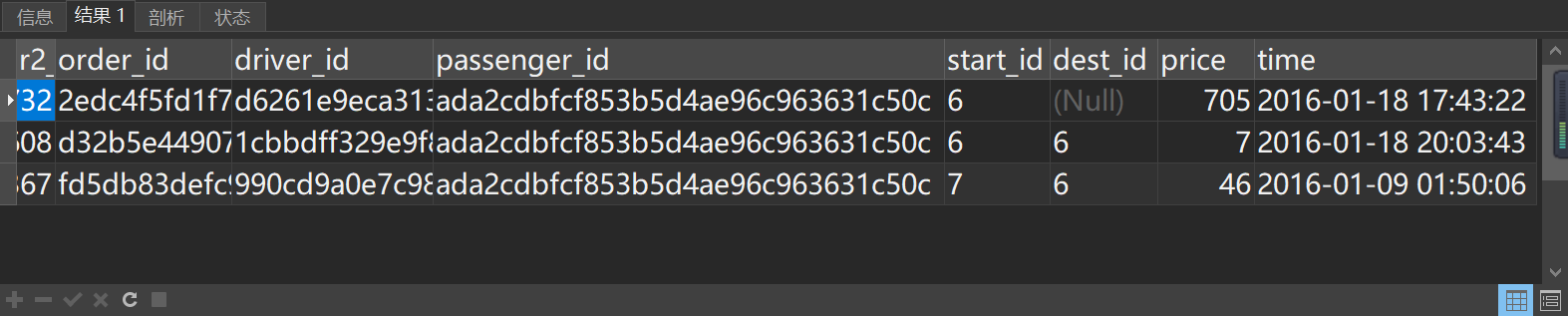
推测可能是专车,长途来回车程,加来回高速费
4.3.2 乘客侧
#检查乘客侧打车次数
select passenger_id ,count(1) as'打车次数' ,count(1)/count(distinct date(time)) as '日均打车次数' from order_data_02 where r2_id>0 and time<'2026-02-01 00:00:00' and driver_id <>'NULL' group by passenger_id order by count(1) desc limit 10;
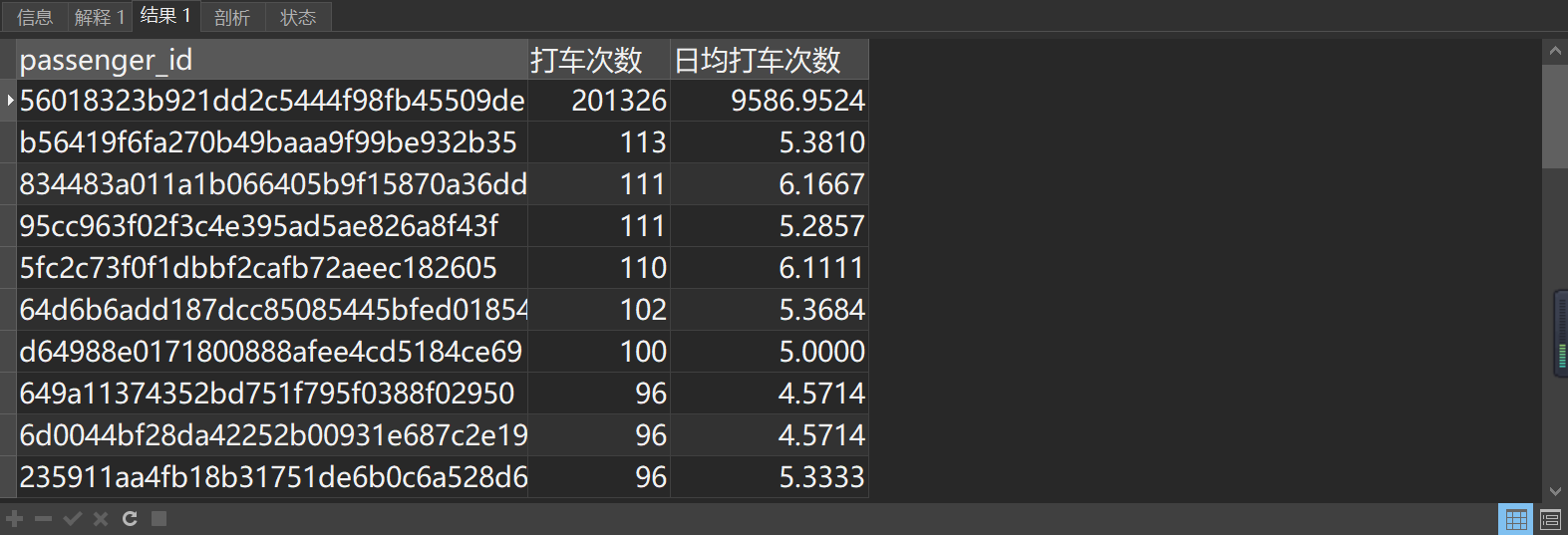
异常乘客 passenger_id='56018323b921dd2c5444f98fb45509de' 打车次数 201175,日均9587次。(官方解释是因为之前通过其他方式叫车的部分用户没有登录,所以都是统一的ID,并不是数据问题)
#查看异常乘客订单明细
select *
from order_data_02
where r2_id>0
and time<'2026-02-01 00:00:00'
and driver_id <>'NULL'
and passenger_id= '56018323b921dd2c5444f98fb45509de'
order by time
limit 20;
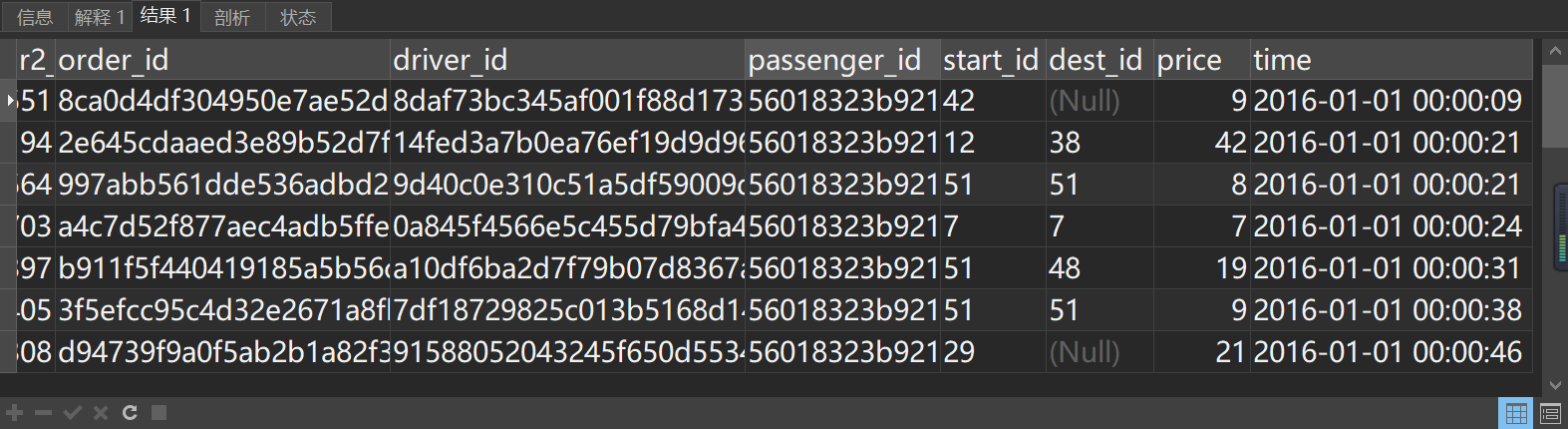
对该ID下的订单进一步核查发现同一时段内订单、司机、出发地均不一致,可以判定非同一乘客订单,先保留该数据,后续新增一列ID状态,将该ID产生的订单统一标记为:异常乘客ID。
4.3.3 司机侧
#司机侧检查接单次数
select driver_id ,count(1) as '接单次数' ,count(1)/count(distinct date(time)) as '日均接单次数' from order_data_02 where r2_id>0 and driver_id <>'NULL' and time<'2026-02-01' group by driver_id order by '日均接单次数' desc limit 50;
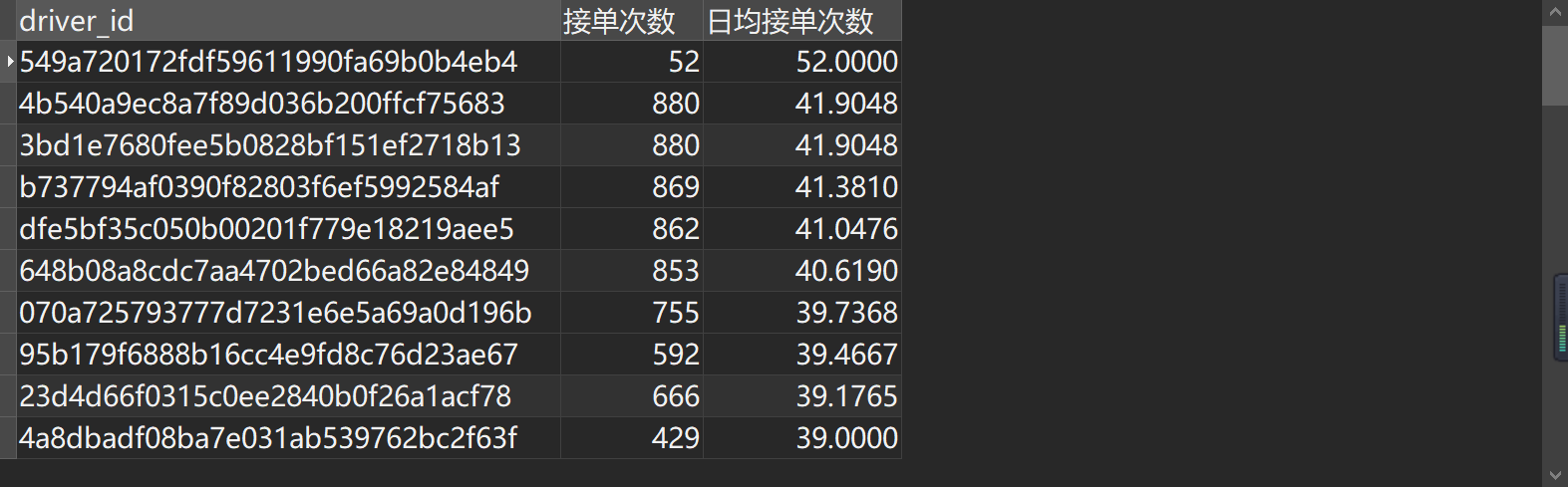
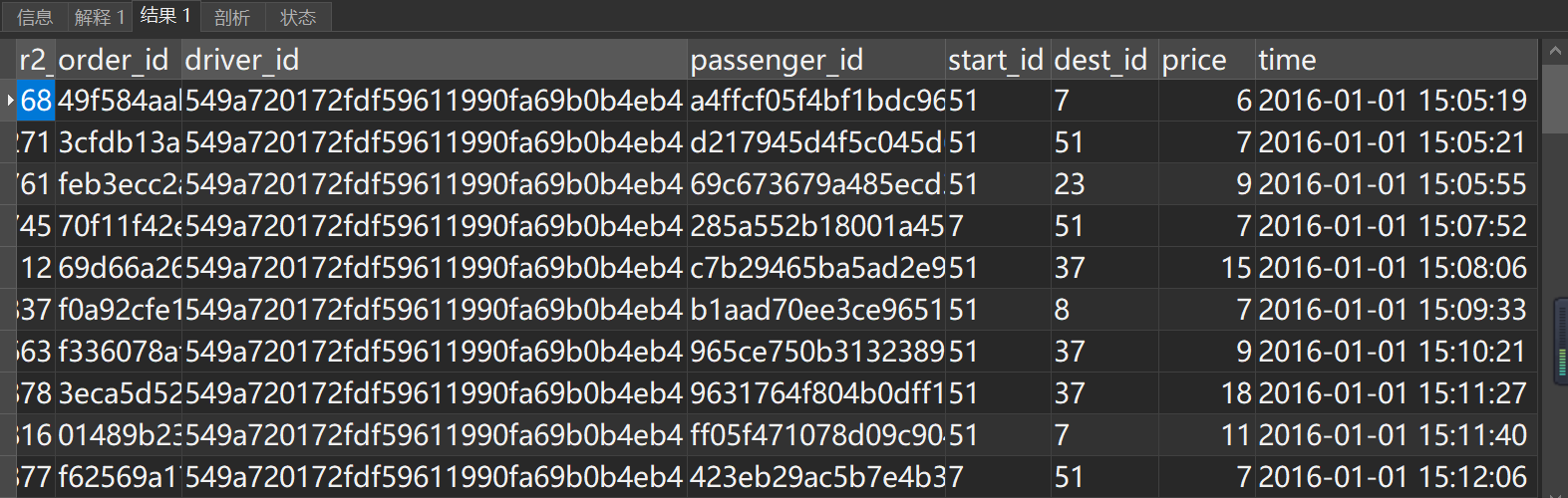
#异常司机driver_id ='549a720172fdf59611990fa69b0b4eb4' 接单明细
select
*
from order_data_02
where r2_id>0
and driver_id ='549a720172fdf59611990fa69b0b4eb4'
and time<'2026-02-01'
order by time limit 100;
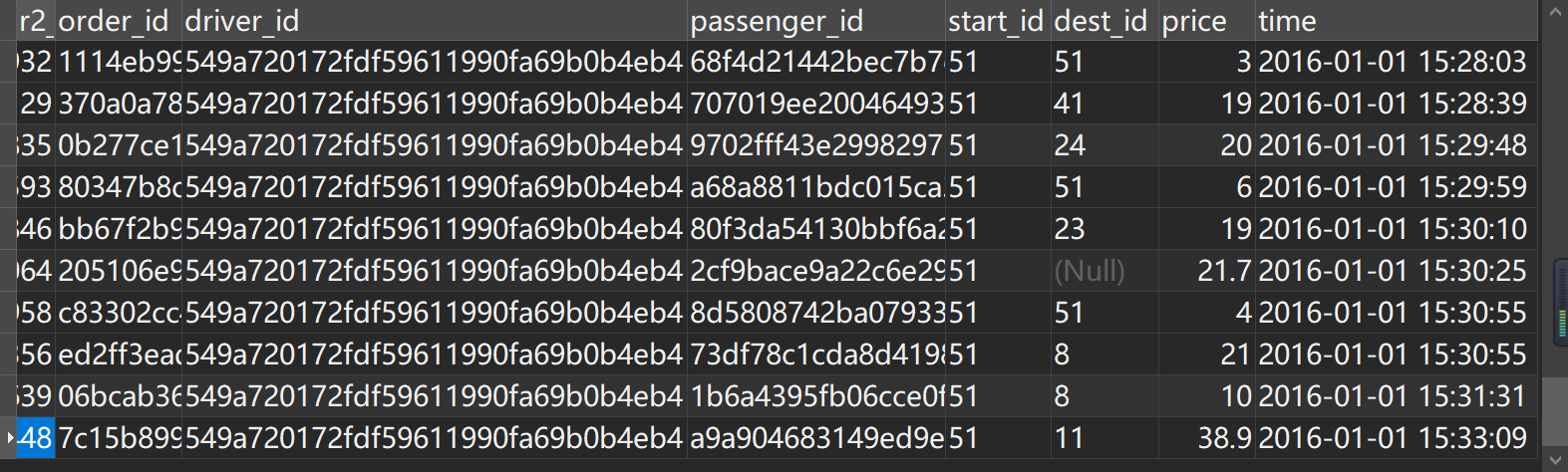
select
count(distinct start_id) as start_id_n
,count(distinct dest_id) as dest_id_n
,count(distinct order_id) as order_id_n
,min(time)
,max(time)
from order_data_02
where r2_id>0
and driver_id ='549a720172fdf59611990fa69b0b4eb4'
and time<'2026-02-01 00:00:00'
order by time;

司机 driver_id ='549a720172fdf59611990fa69b0b4eb4' 在1月1日15:05-15:33期间合计接单数52,接单地2个,目的地12个,平均每分钟1.9单,接单频率异常,剔除处理。
#筛查1小时内接单10次以上的司机
select
driver_id
,date_format(time,'%Y-%m-%d %H') as '时'
,count(order_id) as '小时接单数'
from order_data_02
where r2_id>0
and driver_id<>'NULL'
and time<'2026-02-01'
group by 1,2 having count(order_id) >10
order by 3 desc
limit 100;
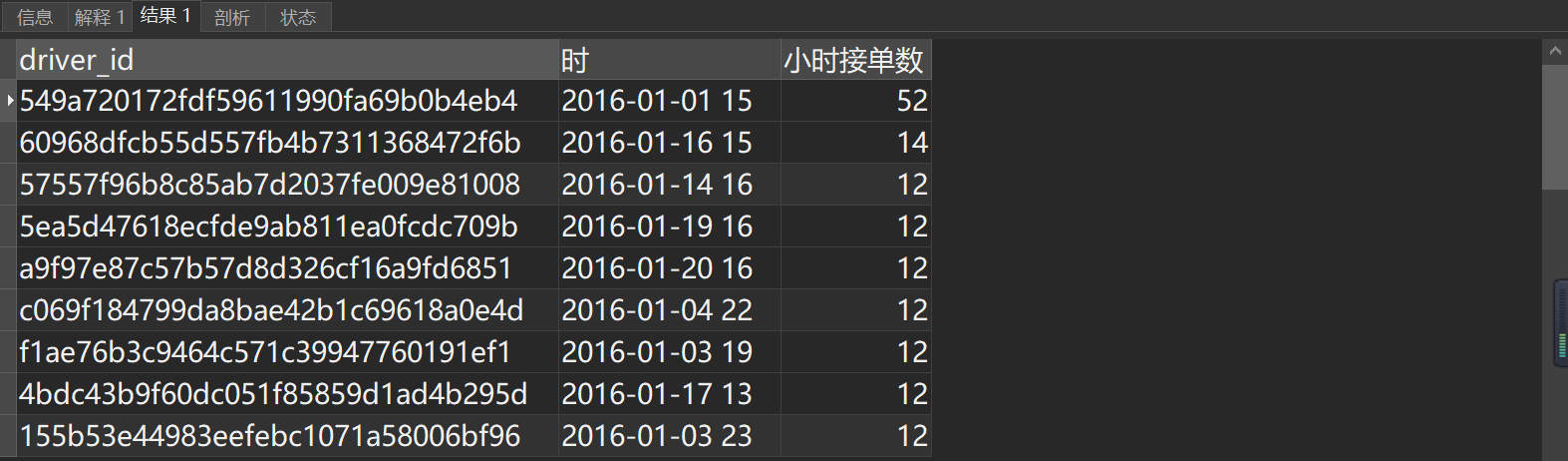
共21条记录,因无法判断业务类型(专车/拼车/顺风车)及订单状态(取消/完成),对其他订单均保留处理。
标记状态(订单状态order_status,乘客id状态pid_status),删除异常司机id数据。
#标记状态,order_status和pid_status -- driver_id='NULL' 为未应答; -- passenger_id= '56018323b921dd2c5444f98fb45509de' 为乘客id异常 drop table if exists order_data; create table order_data as( select * ,case when driver_id='NULL' then '未应答' else '已接单' end as order_status ,case when passenger_id= '56018323b921dd2c5444f98fb45509de' then '乘客id异常' else '正常' end as pid_status from order_data_02 where r2_id>0 and time<'2026-02-01 00:00:00' ); #删除driver_id ='549a720172fdf59611990fa69b0b4eb4'数据 delete from order_data where driver_id ='549a720172fdf59611990fa69b0b4eb4';
#查看新表结构
desc order_data
五、解决问题
5.1 运营情况?
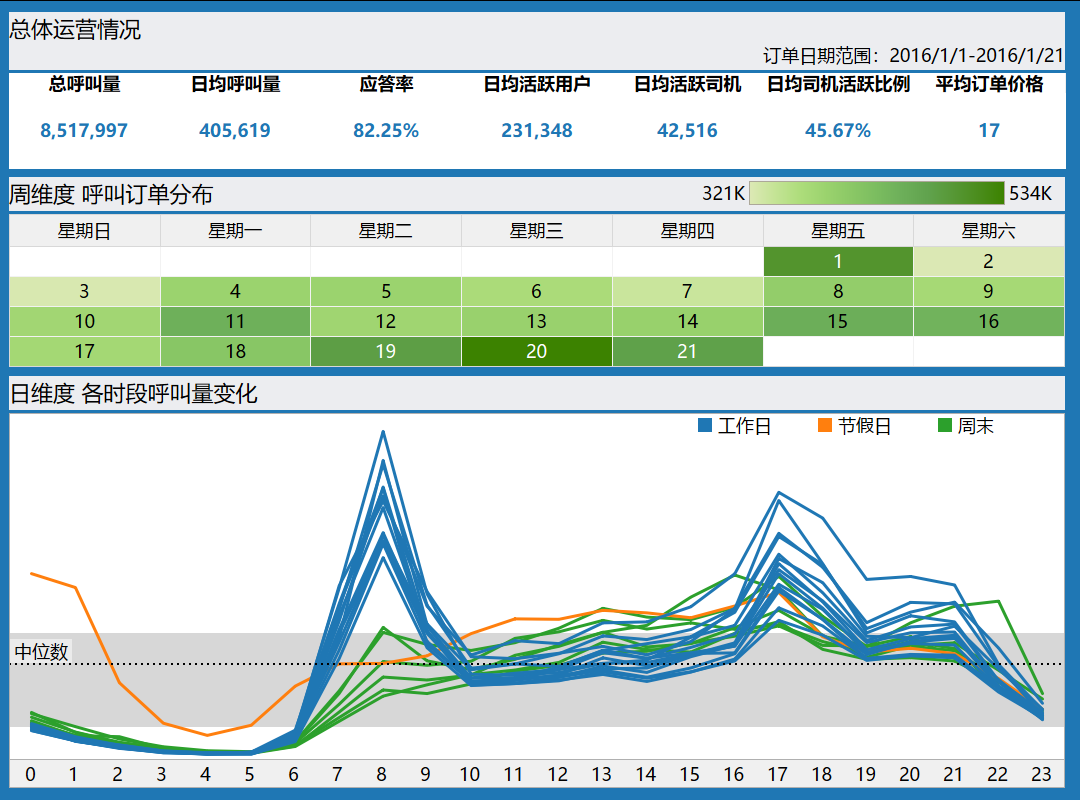
- 总体运营情况:2016年1月1日-1月21日M市总呼叫订单约851.8W,日均呼叫订单约40.5W,应答率82.25%,日均活跃用户23.1W,日均司机活跃比例45.67%,平均订单价格17元;
- 周维度:基于M市三周呼叫量分布看,总呼叫量星期一至星期日无明显周期性规律变化;1月1日、1月19日-1月21日呼叫量较高,工作日1月7日呼叫量最低;
- 日维度:工作日早高峰主要在早上 [7:00,9:00] ,晚高峰主要在 [17:00,19:00) ,休息时间[23:00,7:00);周末[8:00,18:00) 呼叫量逐渐增加,但增长速度相对较慢;元旦凌晨[00:00,2:00]仍为呼叫高峰,而后在早上6时开始呈现增长趋势,并在下午17时达到一个相对较高的水平。早高峰呼叫量工作日整体高于周末和节假日;10时-16时的呼叫量:节假日>周末>工作日,可能因休息日出行需求增加。
5.2 高峰期供需匹配?
5.2.1 工作日与非工作日呼叫、应答情况?
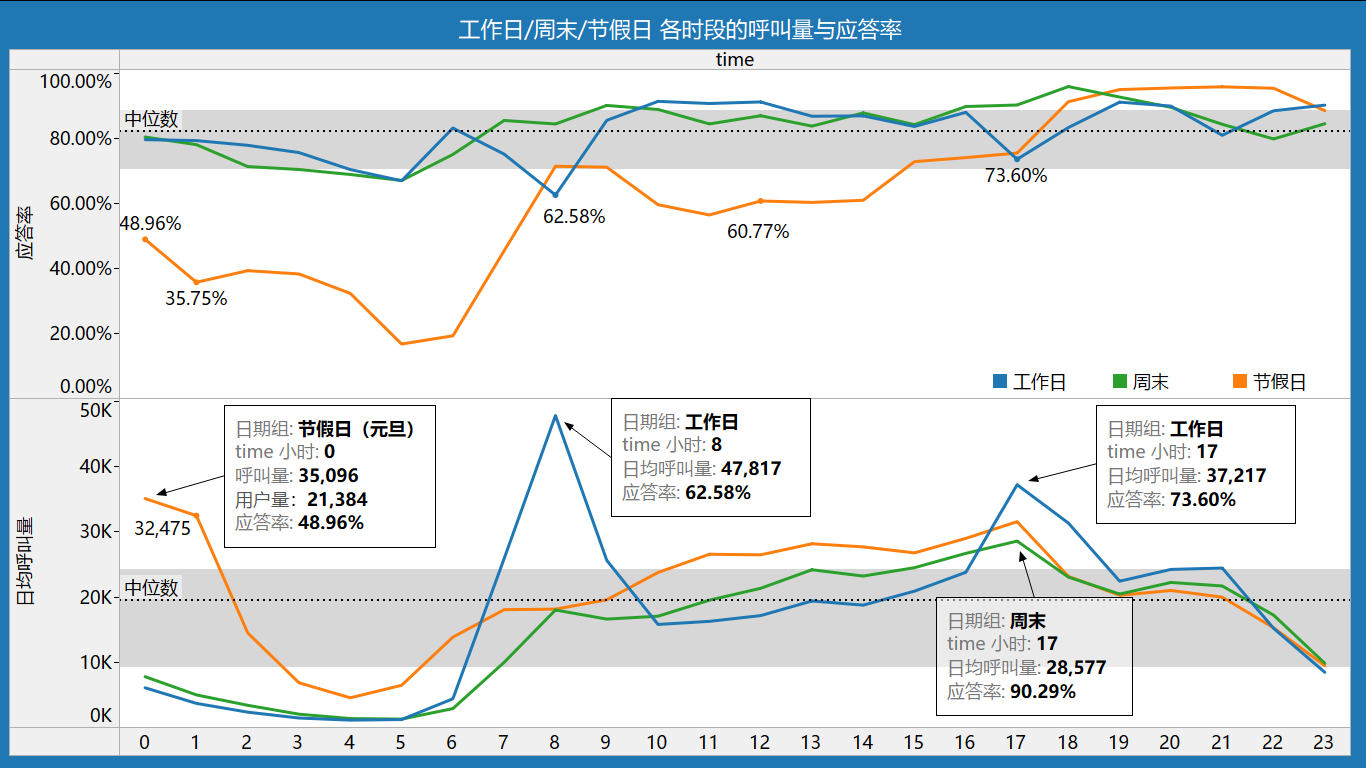
从呼叫、应答率看,
- 工作日和节假日高峰期应答率均很低。
- 工作日8时日均呼叫量4.8W,应答率62.58%;17时日均呼叫量3.7W,应答率73.60%;
- 节假日0时和1时,呼叫量约是周末同时段的4倍,分别为3.5W和3.2W,而应答率分别为48.96%和35.75%;11时至17时呼叫量较周末略涨,但应答率仅在60%-70%上下波动。
可见,工作日早高峰和晚高峰供需紧张,节假日供需尤其紧张。
5.2.2 呼叫高峰期低应答率分析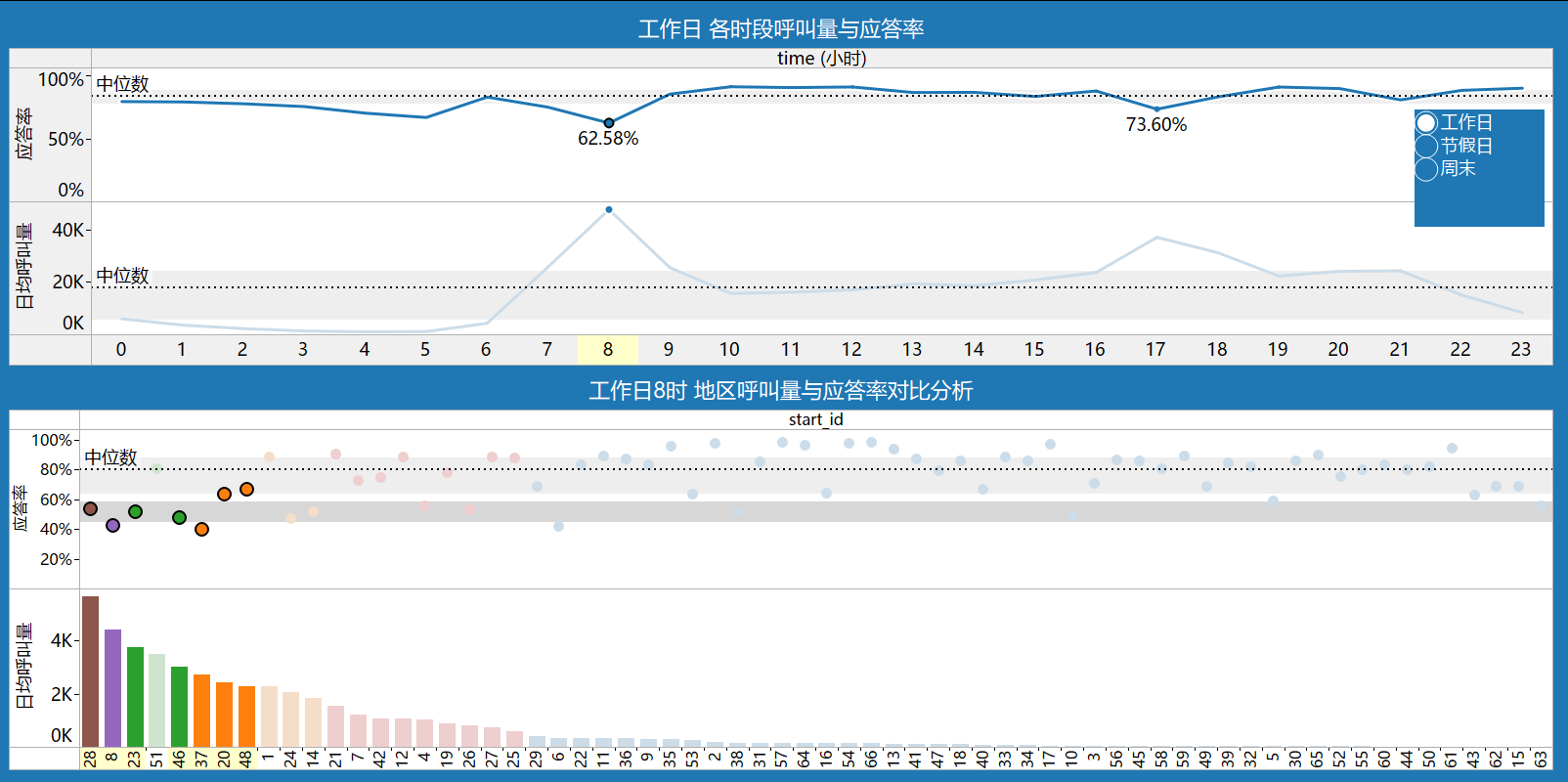
工作日8时高峰,低应答地区id:28,8,23,46,37,20,48。
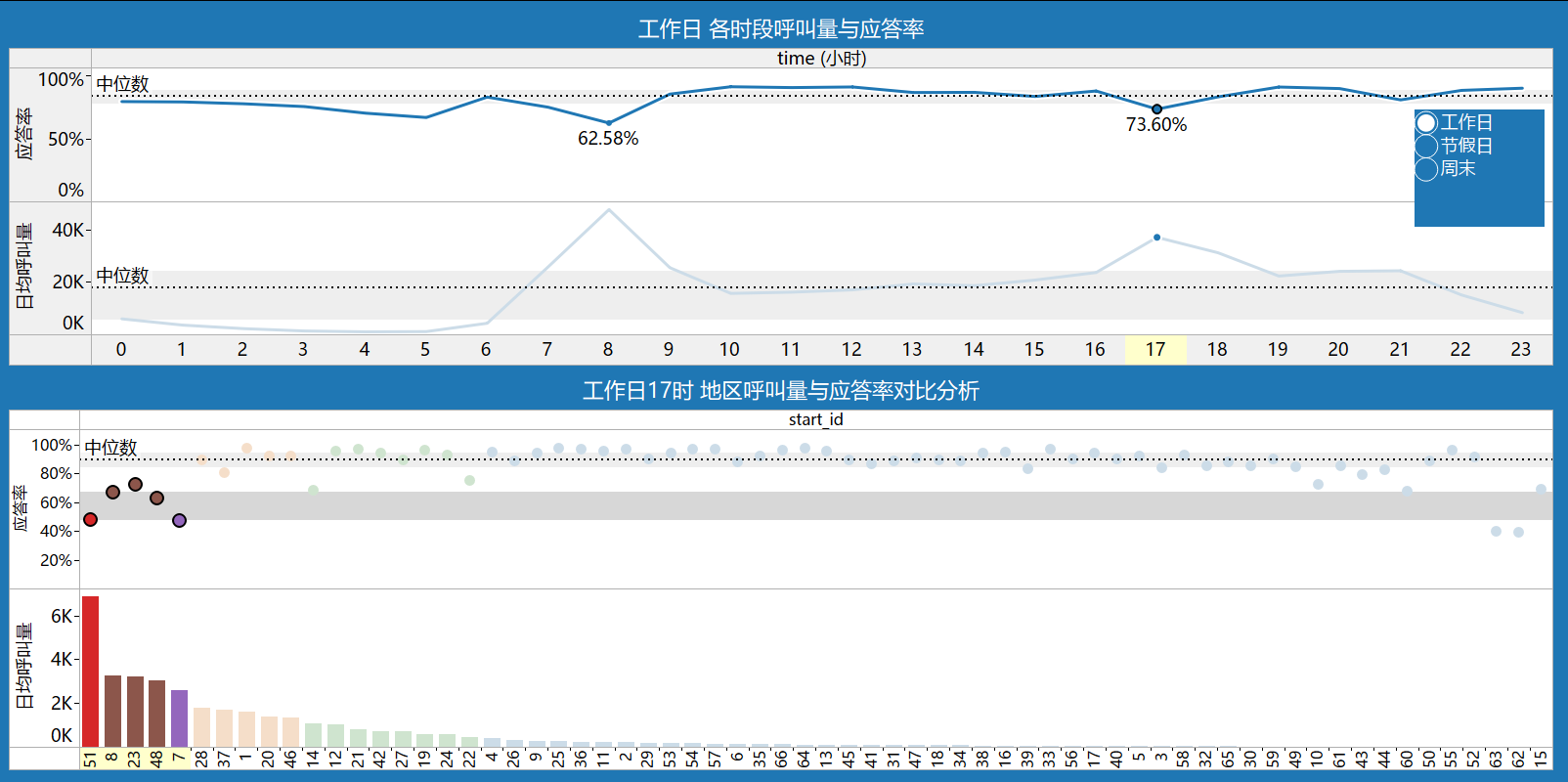
工作日下午17时高峰,低应答地区id:51,8,23,48,7。
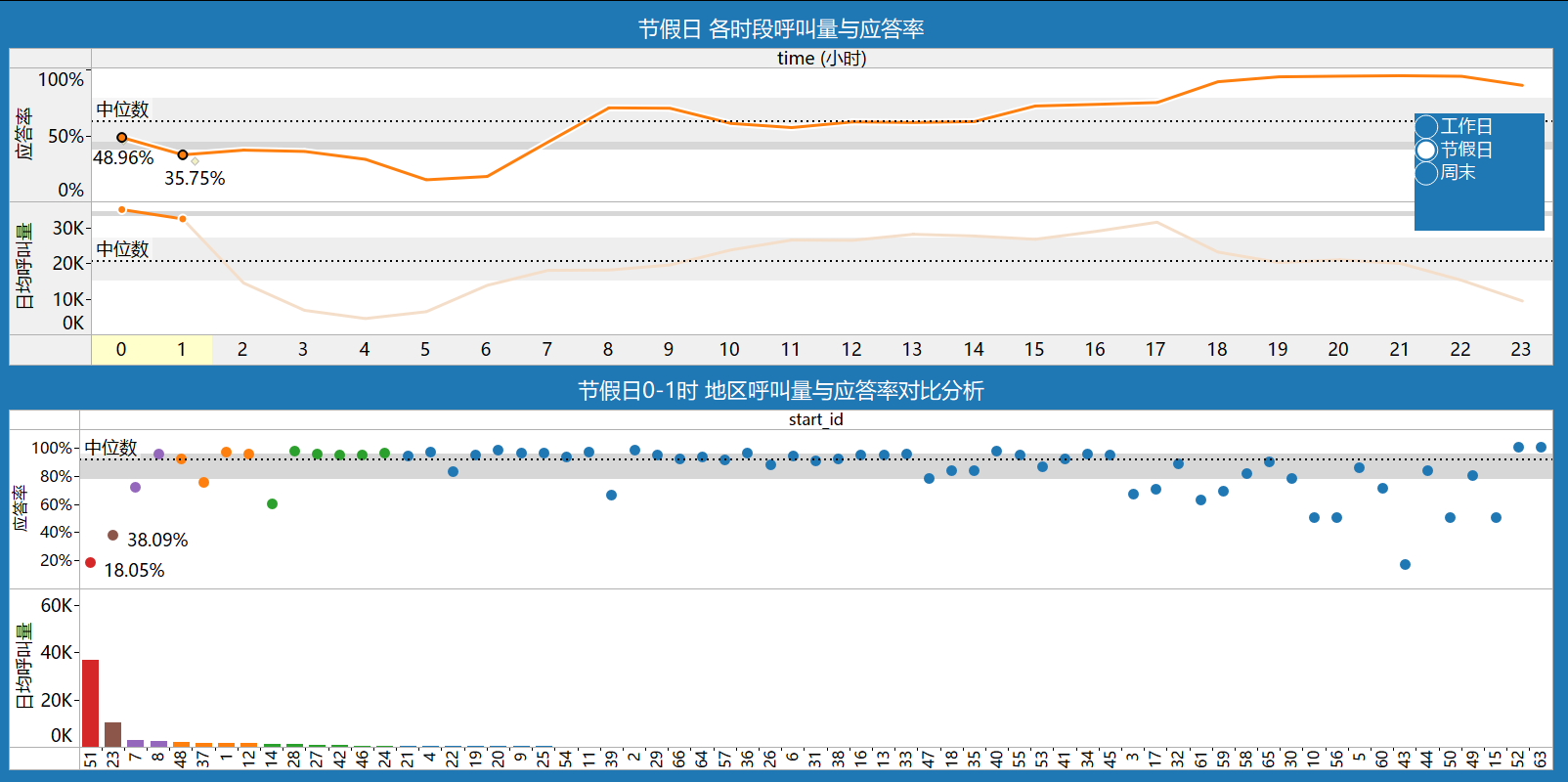
节假日(元旦)凌晨0时和1时,订单井喷式爆增约为非节假日的4倍,低应答地区id:51,23。
高峰低应答的可能原因:
- 司机供给不足:地区内司机数量是否满足高峰期的需求量,是否需要进一步增加司机资源;
- 需求过于集中:地区内的乘客需求是否过于集中,导致司机无法及时应答所有呼叫;
- 恶劣天气、道路拥堵或交通限制:特定区域的道路拥堵、施工或交通限制是否导致司机难以及时到达乘客位置;
- 司机积极性或服务质量:地区的司机是否存在较低的接单积极性或服务质量问题,导致应答率不高。
高峰低应答应对策略:
-
加强司机激励措施:在高峰热点地区设置更具吸引力的司机激励政策,如提高佣金比例、给予额外奖励,以吸引司机前往高需求区域提供服务;
-
动态调价:根据实时需求和供应情况,采用动态调价机制,调整订单价格以提高司机的积极性和应答率。较高的订单费用可能激发司机在高峰期间接收订单,满足用户需求。
- 消息推送和提醒:在高峰期前,通过App推送或短信提醒用户高峰期交通拥堵的情况,同时提供拼车乘客额外的优惠券、积分等激励措施,鼓励乘客选择拼车服务,分散高峰需求;
- 优先派单设置:根据呼叫需求情况实时动态调整司机派单范围及范围内的订单优先级,以减少乘客等待时间、增加服务效率;
-
预测和调配:通过准确预测高峰期的需求量和地点分布,提前调配更多司机资源,以提高应答率;
- 热点区司机招募:根据热点图数据加强该地区的司机招募、营销策略等方面,提高运营效率和供需平衡。
5.2.3 地区各时段供需分析
要进行聚类分析的输入
| 中心 | ||||||||
| 群集 | 项数 | 呼叫量 | ||||||
| 低呼叫量地区 | 53 | 1834.9 | ||||||
| 中等呼叫量地区 | 10 | 17323.0 | ||||||
| 高呼叫量地区 | 3 | 45046.0 | ||||||
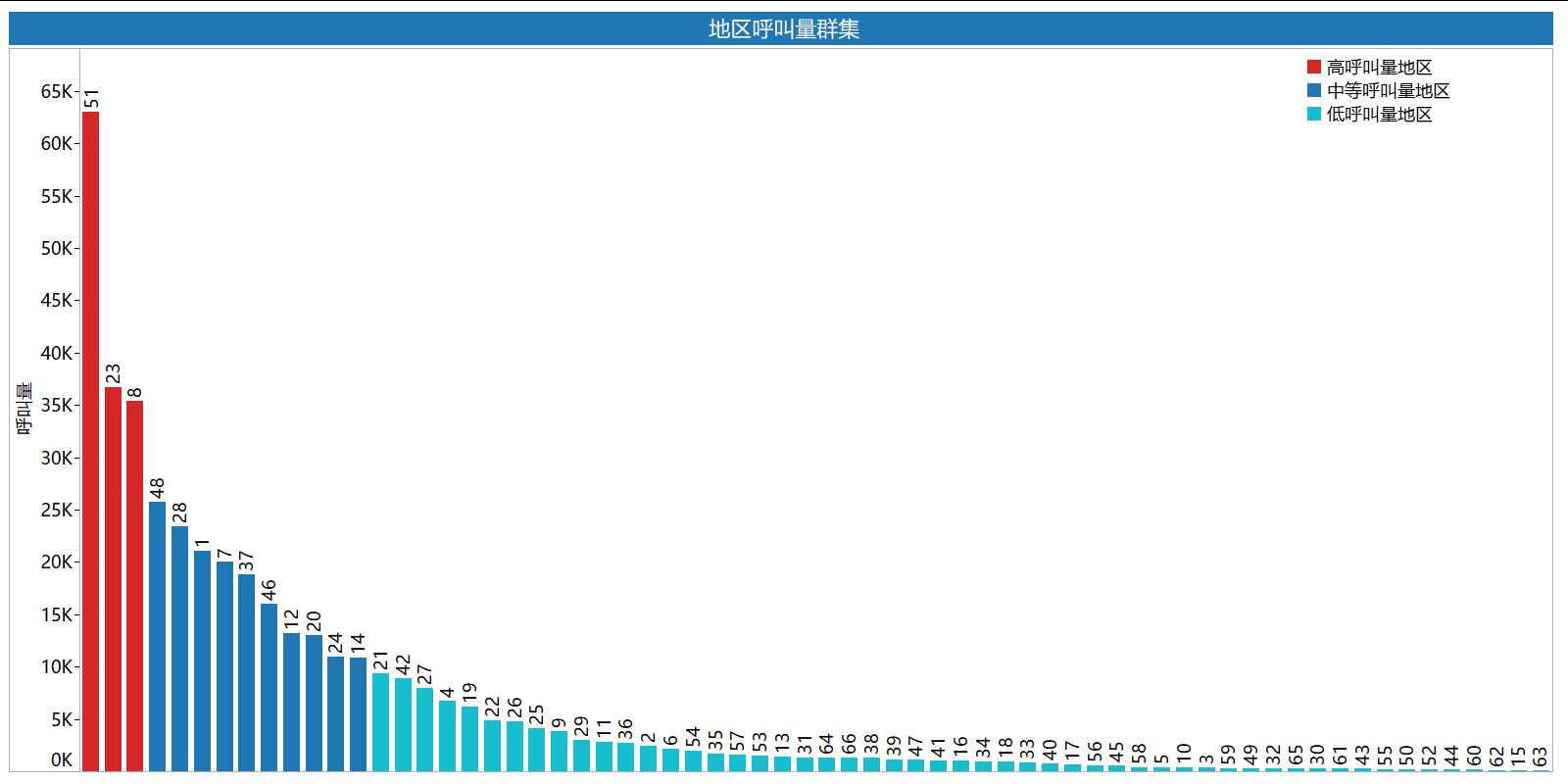
依据呼叫量对地区进行分群:
- 高呼叫量地区id:51 > 23 > 8;
- 中等呼叫量地区id:48 > 28 > 1 > 7 > 37 > 46 > 12 > 20 > 24 > 14;
- 低呼叫量地区id:21 > 42 > 27 > 4 >19 >22 > 26 > 25 > 9 >29 >11.....
1)工作日(高、中高呼叫量)地区各时段呼叫量和应答率
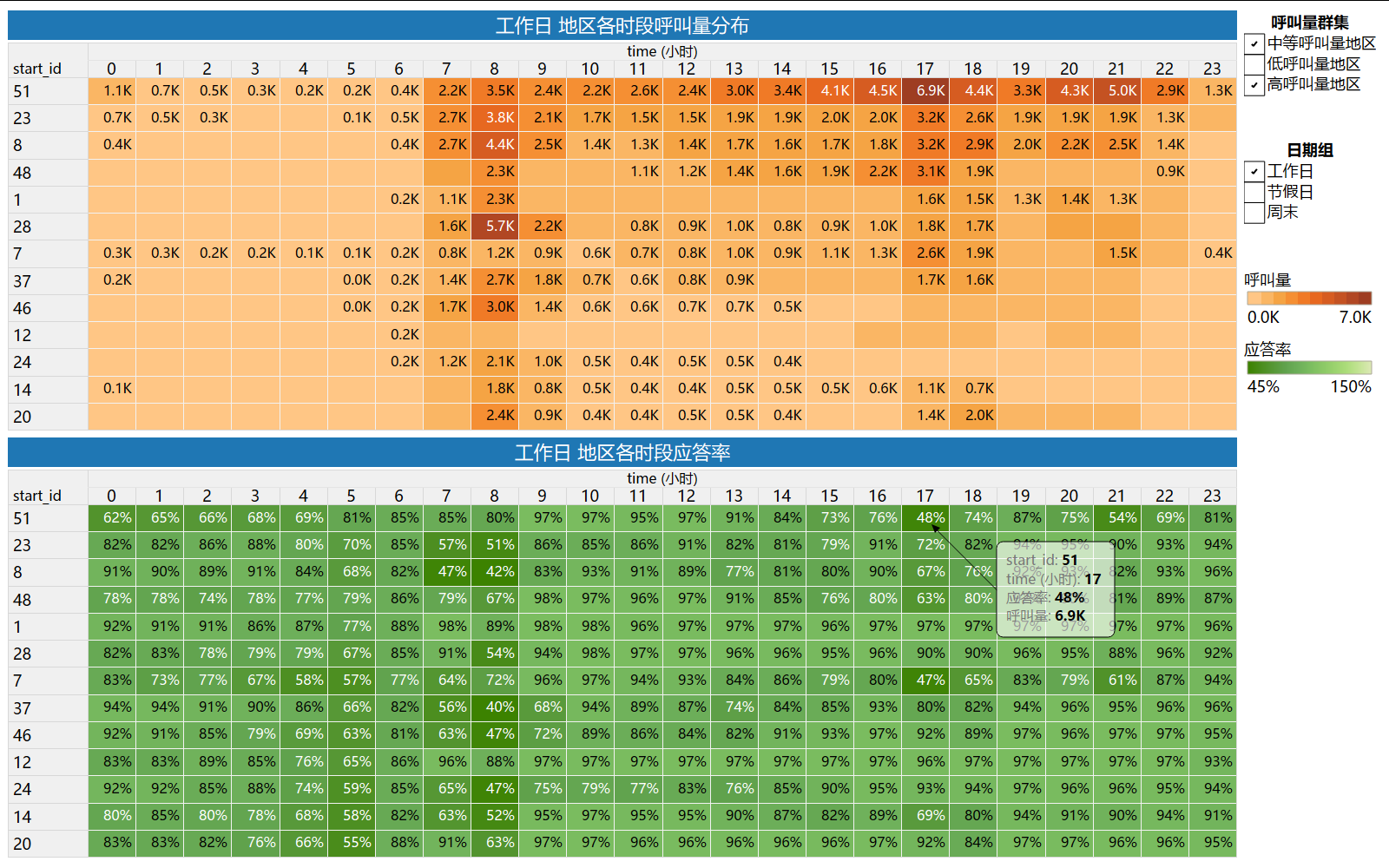
工作日供需紧张,需重点补充运力的地区时段:
- 地区id 51 :[15时,18时],[20时,22时];
- 地区id 23 :[7时,8时],17时;
- 地区id 8 :[7时,8时],[17时,18时];
- 地区id 48 :[7时,8时],[15时,18时];
- 地区id 1 :无;
- 地区id 28 :8时;
- 地区id 7 :[7时,8时],15时,[17时,18时],[20时,21时];
- 地区id 37 :[7时,9时],13时;
- 地区id 46 :[7时,9时];
- 地区id 12 :无;
- 地区id 24 :[7时,9时];
- 地区id 14 :[7时,8时],17时;
- 地区id 20 :8时。
综上所述,工作日运力紧张主要出现在上下班(上下学)高峰期[7时,9时]和[17时,18时],部分地区(id51,id48,id7)下午高峰则从15时开始至18时,夜间[20时,22时]在地区id51和地区id7仍为出行或下班高峰,对于这些地区和时段,可以加大运力供应,提高司机和用户的满意度,同时加强线路覆盖和优惠刺激。
2) 节假日(高、中高呼叫量)地区各时段呼叫量和应答率
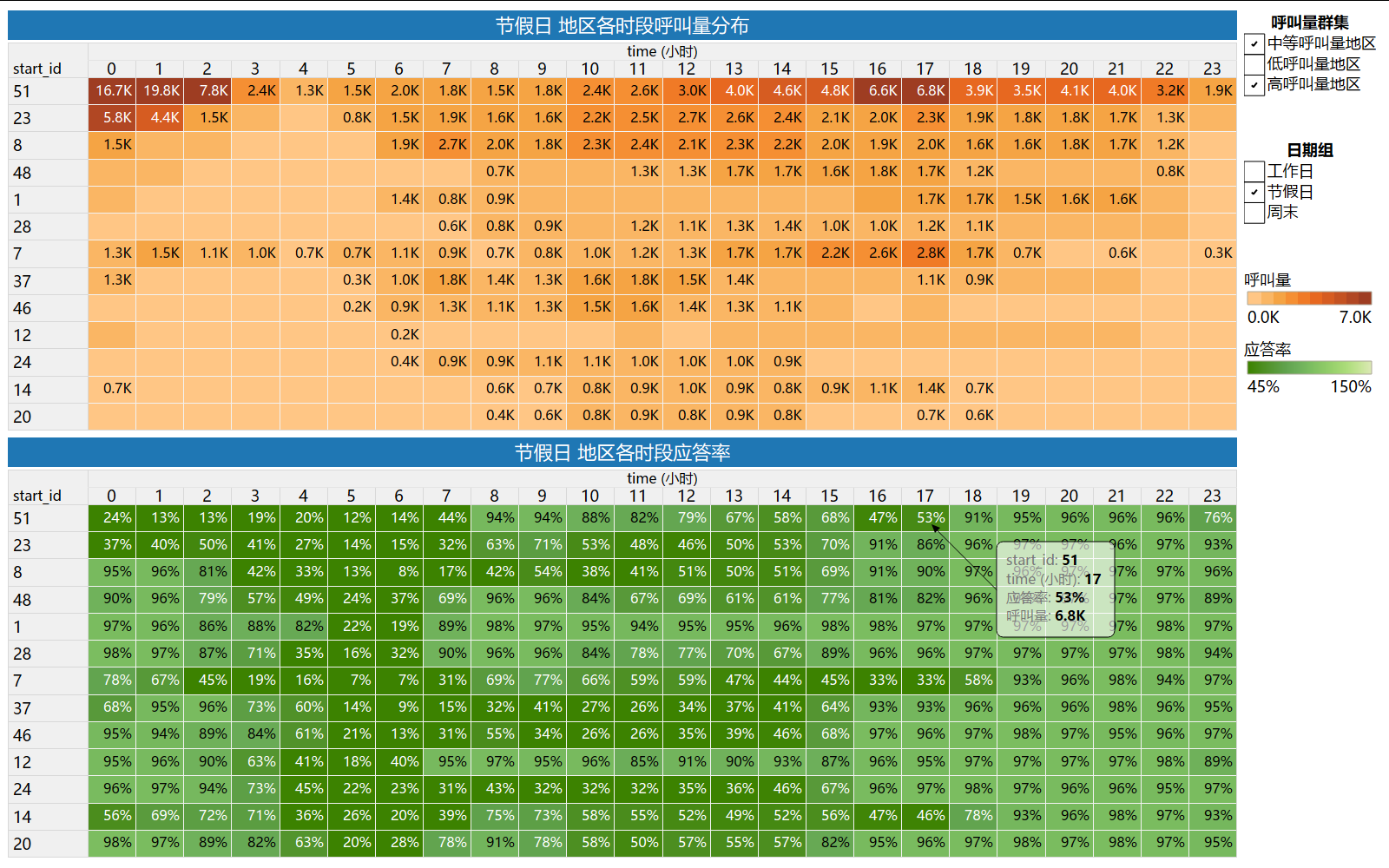
节假日(元旦)供需紧张,需重点补充运力的地区时段:
- 地区id 51 :[0时,7时],[12时,17时],23时;
- 地区id 23 :[0时,2时],[6时,15时];
- 地区id 8 :[6时,15时];
- 地区id 48 :[11时,14时];
- 地区id 1 :6时;
- 地区id 28 :[11时,14时];
- 地区id 7 :[0时,18时];
- 地区id 37 :0时,[6时,15时];
- 地区id 46 :[6时,15时];
- 地区id 12 :无;
- 地区id 24 :[7时,15时];
- 地区id 14 :[8时,18时];
- 地区id 20 :[9时,14时]。
节假日是旅游和出行的高峰期,建议提前安排人员调度,增加投放车辆的数量,确保运力充足,同时加强对热门景点周边和休闲场所的供应,做好线路规划,提高派单效率,满足用户需求。
3) 周末(高、中高呼叫量)地区各时段呼叫量和应答率
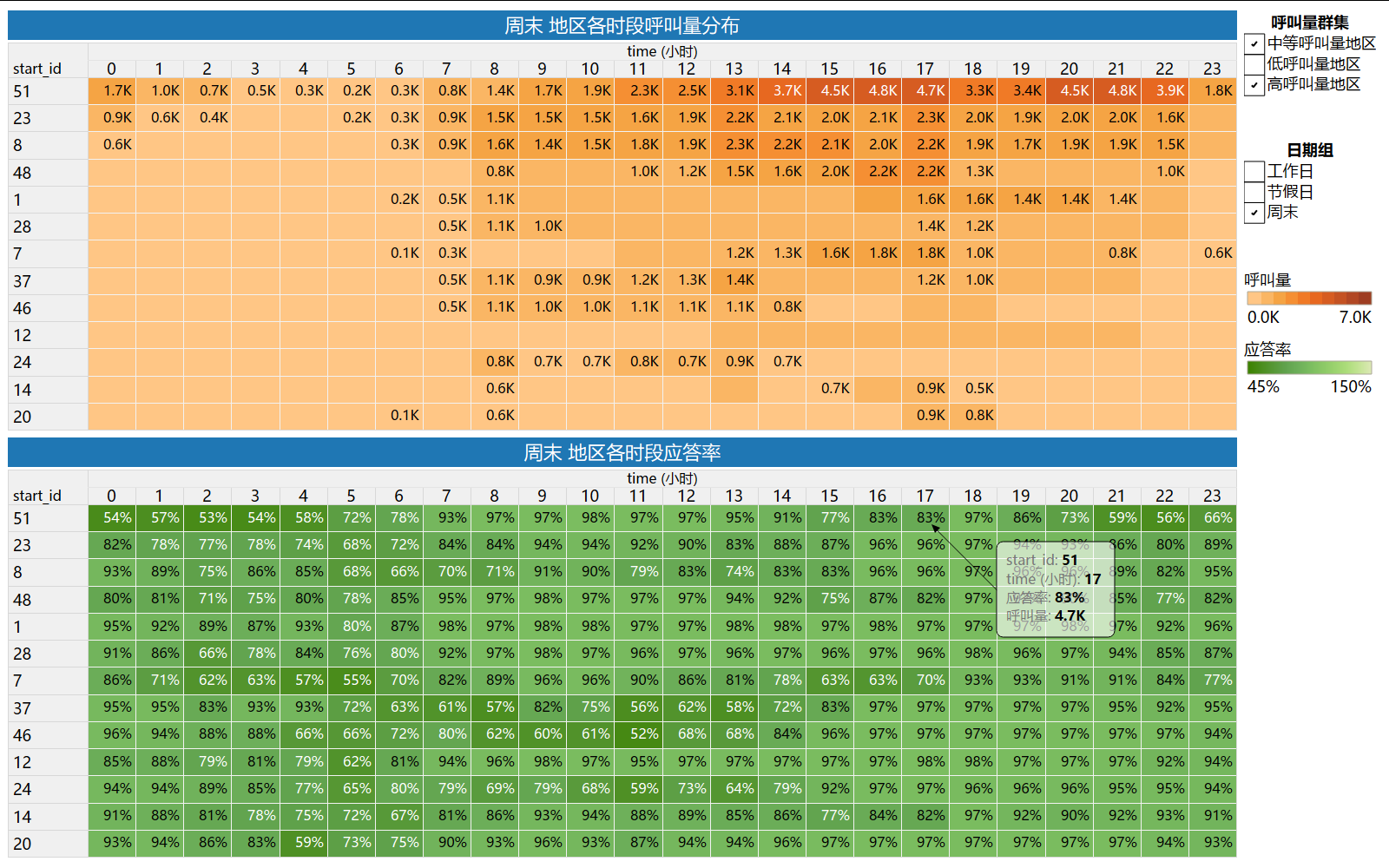
周末供需紧张,需重点补充运力的地区时段:
- 地区id 51 :[0时,1时],15时,[20时,23时];
- 地区id 23 :无;
- 地区id 8 :[7时,8时],11时,13时;
- 地区id 48 :15时,22时;
- 地区id 1 :无;
- 地区id 28 :无;
- 地区id 7 :[14时,17时],23时;
- 地区id 37 :8时,[10时,14时];
- 地区id 46 :[8时,13时];
- 地区id 12 :无;
- 地区id 24 :[7时,14时];
- 地区id 14 :15时;
- 地区id 20 :无。
周末建议加强对商业区和热门餐饮、娱乐场所的覆盖,如地区id51在周末[20时,1时]可能是夜生活和娱乐高峰期,建议加大投放车辆的数量,并与相关场所展开合作,提供特定的接送服务,以提升用户体验和满意度。
5.3 地区未来7天单量预测
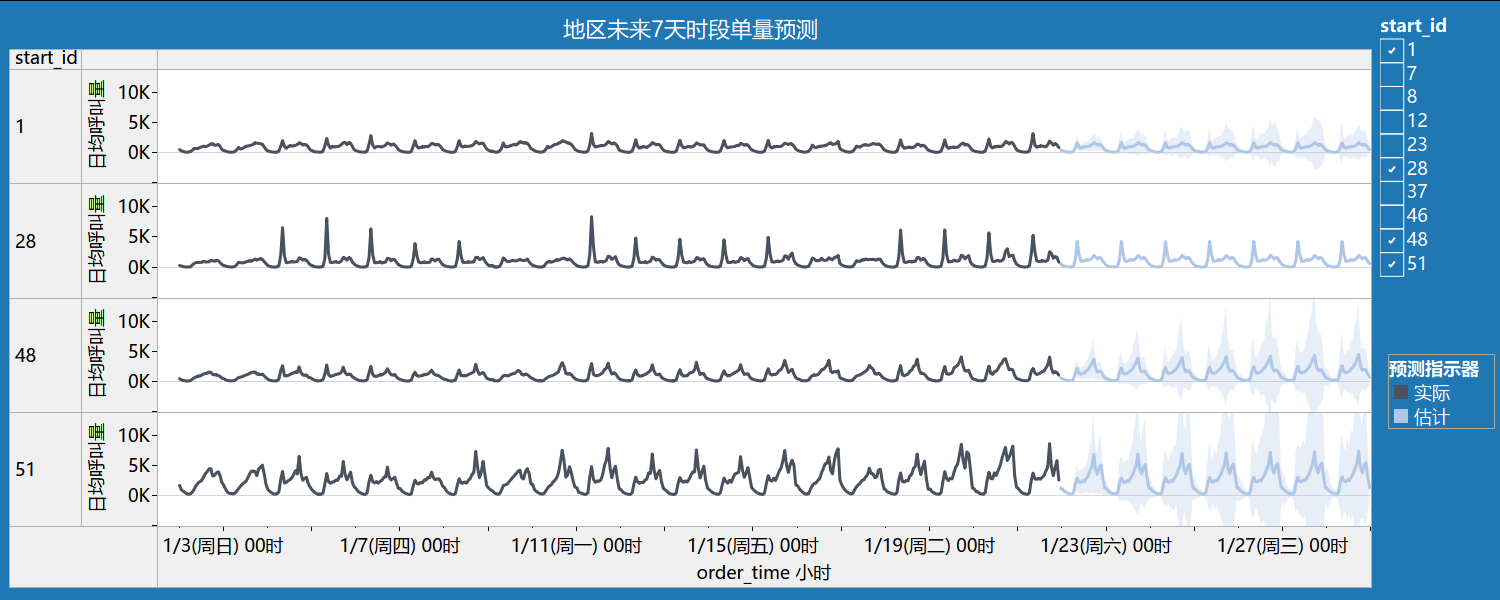
用于创建预测的选项
| 时间系列: | order_time 小时 |
| 度量: | 日均呼叫量 |
| 向前预测: | 169 小时 (2016年1月21日 下午11 – 2016年1月28日 下午11) |
| 预测依据: | 2016年1月9日 下午9 – 2016年1月21日 下午10 |
| 忽略最后: | 1 小时 (2016年1月21日 下午11) |
| 季节模式: | 24 小时周期 |
预测结果
| 行 | 初始 | 从初始值更改 | 季节影响 | 贡献 | |||||||
| start_id | 2016年1月21日 下午11 | 2016年1月21日 下午11 – 2016年1月28日 下午11 | 高 | 低 | 趋势 | 季节 | 质量 | ||||
| 1 | 443 | ± | 140 | -6 | 2016年1月28日 上午8 | 2 | 2016年1月28日 上午4 | 0 | 95.8% | 4.2% | 好 |
| 28 | 601 | ± | 291 | -1 | 2016年1月28日 上午8 | 4 | 2016年1月28日 上午4 | 0 | 13.4% | 86.6% | 确定 |
| 48 | 581 | ± | 190 | 131 | 2016年1月28日 下午5 | 3 | 2016年1月28日 上午3 | 0 | 100.0% | 0.0% | 确定 |
| 51 | 1,182 | ± | 421 | 110 | 2016年1月28日 下午5 | 3 | 2016年1月28日 上午5 | 0 | 100.0% | 0.0% | 确定 |
通过对地区id为1、28、48、51的地区进行的预测结果,发现tableau预测存在一定局性性,其季节模式(周期性)仅考虑24小时,未体现7天周期性,实际周末时段与工作日时段出行高峰期不同(周六和周日早高峰单量实际较工作日有所减少),故不具备参考价值。
解决思路:再剔除元旦数据的基础上,把工作日和周末单独提取出来,重命名日期使其连续,再分别预测。
5.3.1 高呼叫量地区工作日订单预测
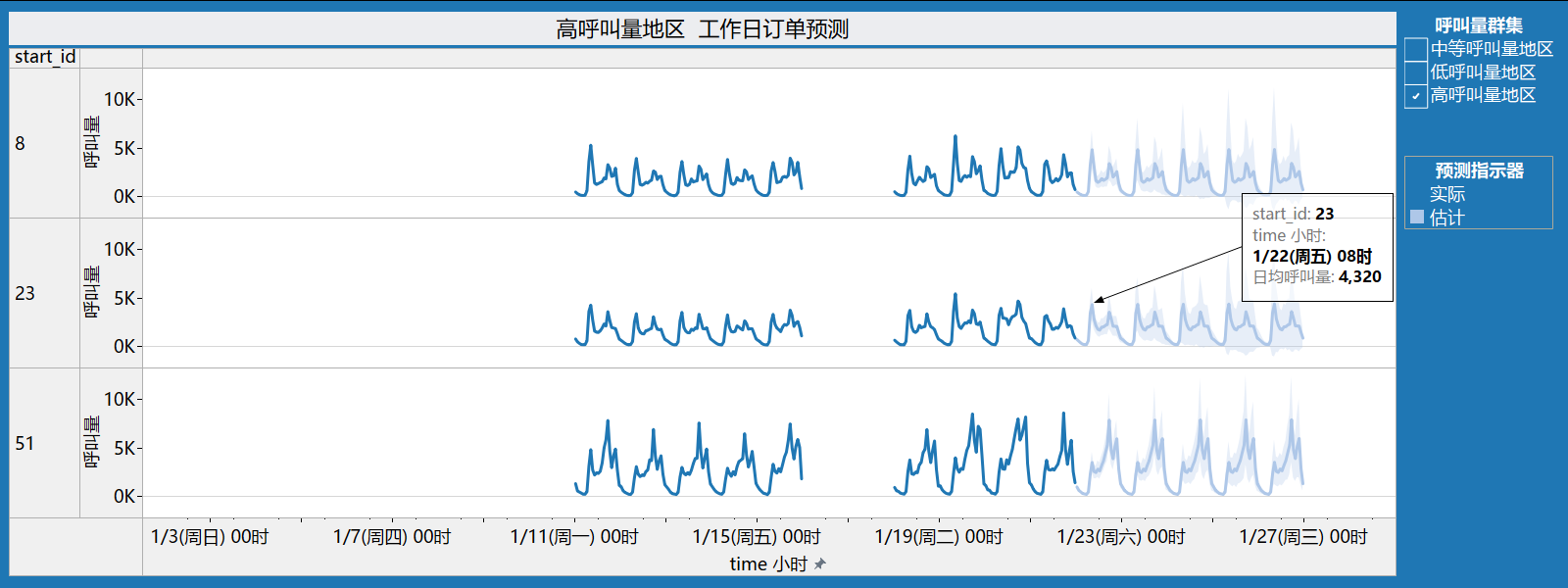
用于创建预测的选项
| 时间序列: | time 小时 |
| 度量: | 日均呼叫量 |
| 向前预测: | 120 小时 (1/22 00时 – 1/26 23时) |
| 预测依据: | 1/11 00时 – 1/21 23时 |
| 忽略最后: | 未忽略任何周期 |
| 季节模式: | 24 小时周期 |
日均呼叫量
| 行总和 | 初始 | 从初始值更改 | 季节影响 | 贡献 | |||||||
| start_id | 1/22 00时 | 1/22 00时 – 1/26 23时 | 高 | 低 | 趋势 | 季节 | 质量 | ||||
| 8 | 448 | ± | 107 | 218 | 1/26 08时 | 3 | 1/26 04时 | 0 | 96.3% | 3.7% | 良好 |
| 23 | 691 | ± | 157 | 142 | 1/26 08时 | 3 | 1/26 04时 | 0 | 99.6% | 0.4% | 良好 |
| 51 | 952 | ± | 245 | 328 | 1/26 17时 | 3 | 1/26 05时 | 0 | 97.7% | 2.3% | 良好 |
工作日(1/22,1/25-1/28)高呼叫量地区单量预测和质量评估:
- 地区id为8的呼叫量预计增加218;
- 地区id为23的呼叫量预计增加142;
- 地区id为51的呼叫量预计增加328;
预测质量评估为良好,表明预测模型对于这些渠道的预测结果可靠。
5.3.2 中等呼叫量地区工作日订单预测
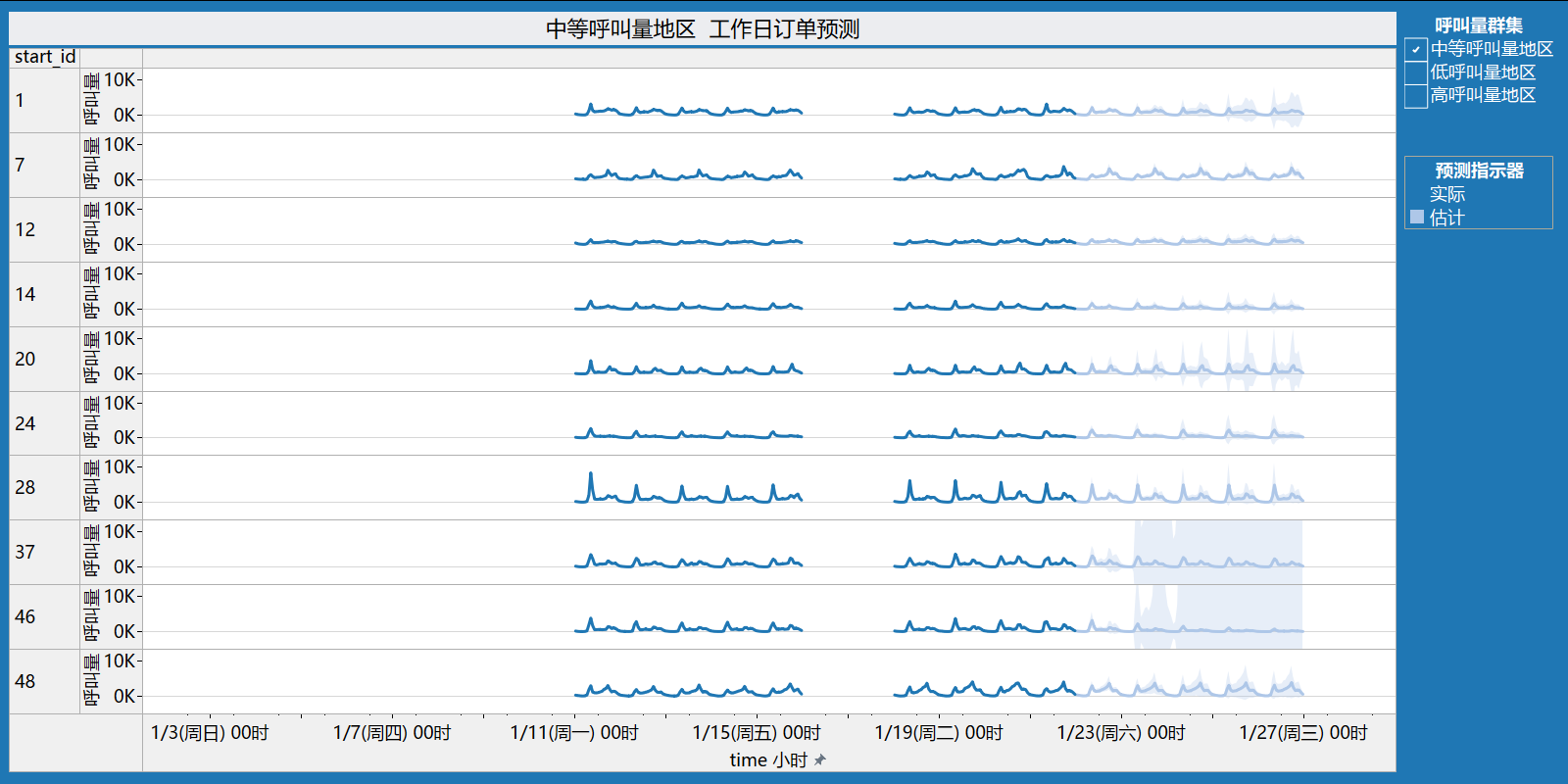
| 时间序列: | time 小时 |
| 度量: | 呼叫量 |
| 向前预测: | 120 小时 (1/22(周五) 00时 – 1/26(周二) 23时) |
| 预测依据: | 1/11(周一) 00时 – 1/21(周四) 23时 |
| 忽略最后: | 未忽略任何周期 |
| 季节模式: | 24 小时周期 |
呼叫量
| 行总和 | 初始 | 从初始值更改 | 季节影响 | 贡献 | |||||||
| start_id | 1/22(周五) 00时 | 1/22(周五) 00时 – 1/26(周二) 23时 | 高 | 低 | 趋势 | 季节 | 质量 | ||||
| 1 | 256 | ± | 56 | 84 | 1/26(周二) 08时 | 3 | 1/26(周二) 04时 | 0 | 100.0% | 0.0% | 良好 |
| 7 | 337 | ± | 110 | 148 | 1/26(周二) 17时 | 3 | 1/26(周二) 05时 | 0 | 99.9% | 0.1% | 良好 |
| 12 | 373 | ± | 75 | 158 | 1/26(周二) 08时 | 2 | 1/26(周二) 04时 | 0 | 99.9% | 0.1% | 良好 |
| 14 | 87 | ± | 29 | 51 | 1/26(周二) 08时 | 4 | 1/26(周二) 03时 | 0 | 98.0% | 2.0% | 良好 |
| 20 | 146 | ± | 72 | 140 | 1/26(周二) 08时 | 4 | 1/26(周二) 04时 | 0 | 98.3% | 1.7% | 良好 |
| 24 | 147 | ± | 47 | 78 | 1/26(周二) 08时 | 4 | 1/26(周二) 04时 | 0 | 0.2% | 99.8% | 良好 |
| 28 | 256 | ± | 73 | 181 | 1/26(周二) 08时 | 4 | 1/26(周二) 04时 | 0 | 98.7% | 1.3% | 良好 |
| 37 | 187 | ± | 66 | 40 | 1/26(周二) 08时 | 3 | 1/26(周二) 04时 | 0 | 100.0% | 0.0% | 良好 |
| 46 | 158 | ± | 59 | -118 | 1/26(周二) 08时 | 4 | 1/26(周二) 04时 | 0 | 100.0% | 0.0% | 良好 |
| 48 | 409 | ± | 99 | 163 | 1/26(周二) 17时 | 3 | 1/26(周二) 03时 | 0 | 99.9% | 0.1% | 良好 |
工作日(1/22,1/25-1/28)中等呼叫量地区的单量预测和质量评估:
- 地区id为1的呼叫量预计增加84;
- 地区id为7的呼叫量预计增加148;
- 地区id为12的呼叫量预计增加158;
- 地区id为14的呼叫量预计增加51;
- 地区id为20的呼叫量预计增加140;
- 地区id为24的呼叫量预计增加78;
- 地区id为28的呼叫量预计增加181;
- 地区id为37的呼叫量预计增加40;
- 地区id为46的呼叫量预计下降118;
- 地区id为48的呼叫量预计增加163;
预测质量评估为良好,表明预测模型对于这些地区的预测结果可靠。
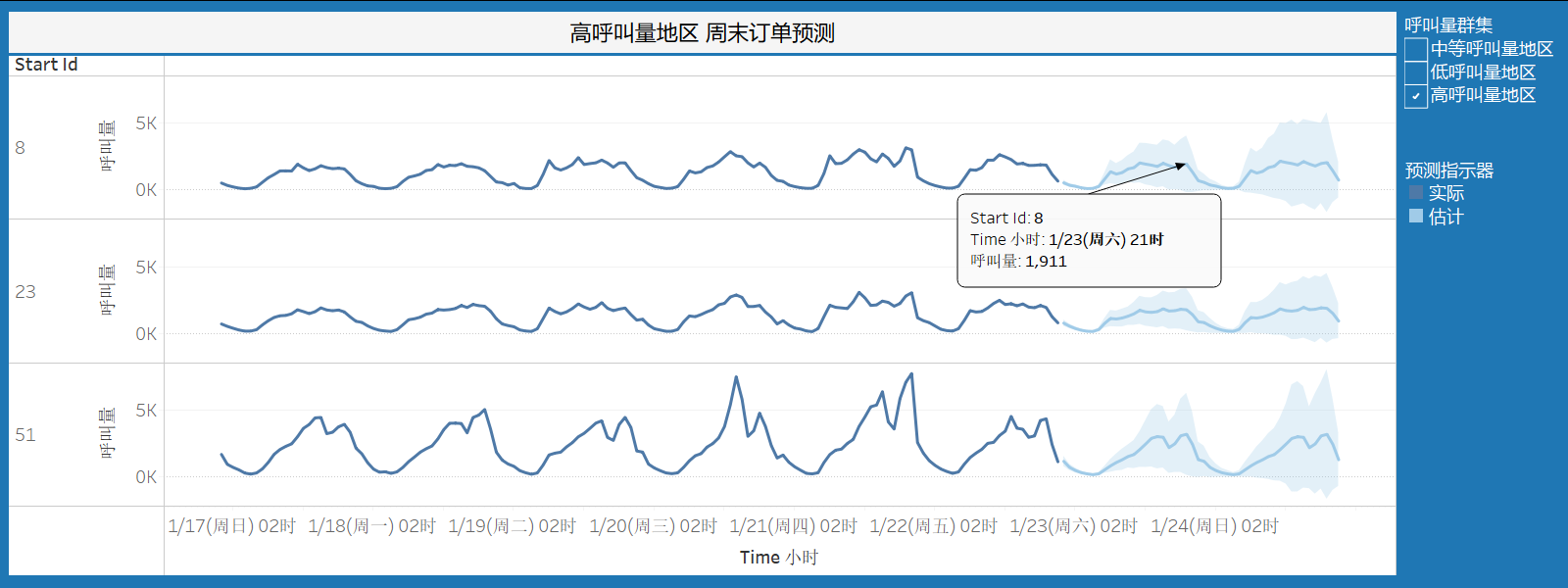
5.3.3 高呼叫量地区周末订单预测


create table order_weekend as( select order_id ,start_id ,time from order_data where date_format(time,'%w') in (0,6) ) update order_weekend set time = replace(time,'2016-01-17','2016-01-22'); update order_weekend set time = replace(time,'2016-01-16','2016-01-21'); update order_weekend set time = replace(time,'2016-01-10','2016-01-20'); update order_weekend set time = replace(time,'2016-01-09','2016-01-19'); update order_weekend set time = replace(time,'2016-01-03','2016-01-18'); update order_weekend set time = replace(time,'2016-01-02','2016-01-17');
| 时间序列: | Time 小时 |
| 度量: | 呼叫量 |
| 向前预测: | 48 小时 (1/23(周六) 00时 – 1/24(周日) 23时) |
| 预测依据: | 1/17(周日) 00时 – 1/22(周五) 23时 |
| 忽略最后: | 未忽略任何周期 |
| 季节模式: | 24 小时周期 |
呼叫量
| 行总和 | 初始 | 从初始值更改 | 季节影响 | 贡献 | |||||||
| Start Id | 1/23(周六) 00时 | 1/23(周六) 00时 – 1/24(周日) 23时 | 高 | 低 | 趋势 | 季节 | 质量 | ||||
| 8 | 511 | ± | 191 | 201 | 1/24(周日) 13时 | 2 | 1/24(周日) 04时 | 0 | 100.0% | 0.0% | 确定 |
| 23 | 771 | ± | 236 | 153 | 1/24(周日) 17时 | 2 | 1/24(周日) 05时 | 0 | 100.0% | 0.0% | 确定 |
| 51 | 1,163 | ± | 382 | 119 | 1/24(周日) 21时 | 2 | 1/24(周日) 05时 | 0 | 94.4% | 5.6% | 确定 |
周末(1/23-1/24)高呼叫量地区单量预测和质量评估:
- 地区id为8的呼叫量预计增加201;
- 地区id为23的呼叫量预计增加153;
- 地区id为51的呼叫量预计增加119;
预测质量评估为确定,表明预测模型对于这些地区的预测结果较为可靠。
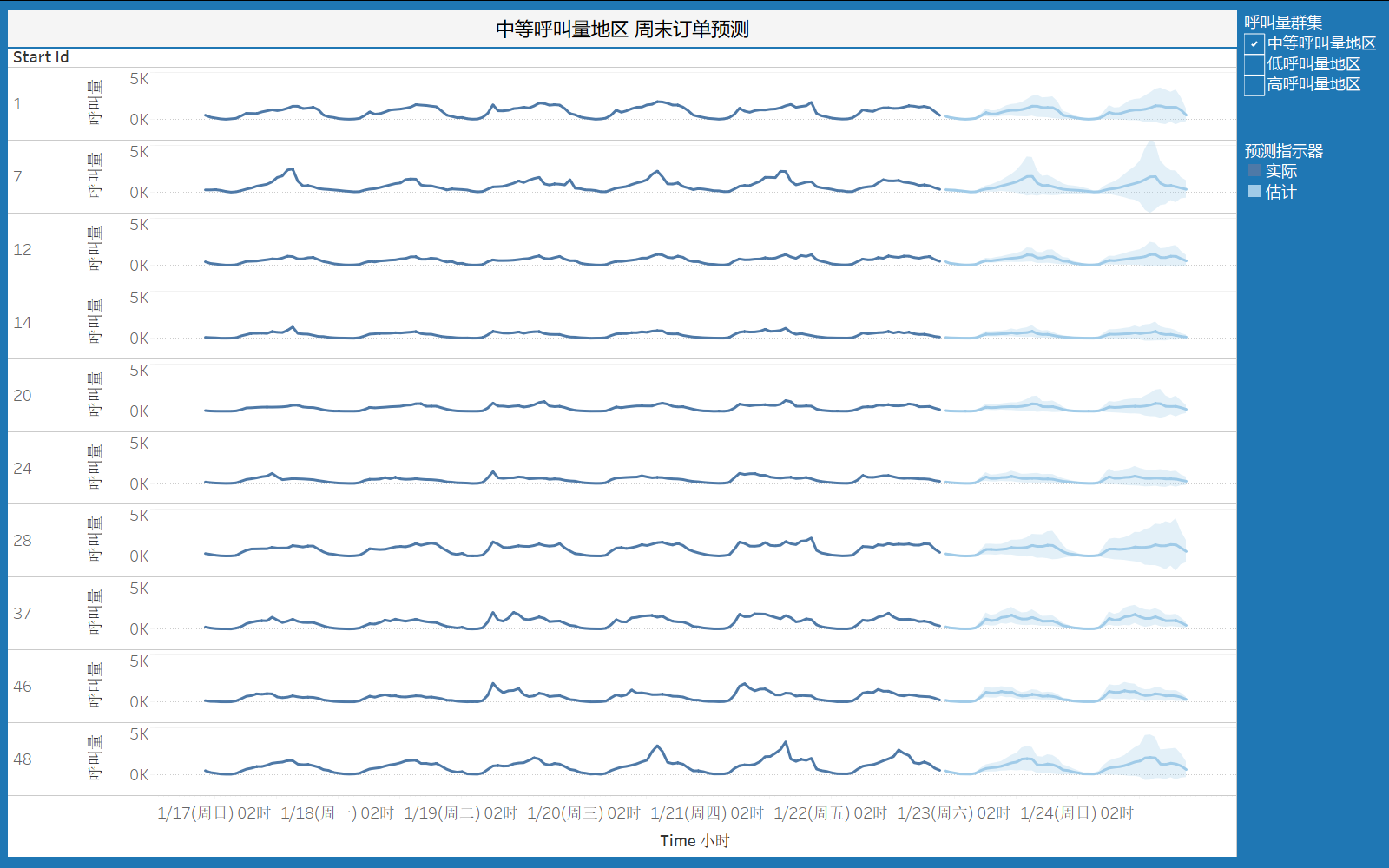
5.3.4 中等呼叫量地区周末订单预测
用于创建预测的选项
| 时间序列: | Time 小时 |
| 度量: | 呼叫量 |
| 向前预测: | 48 小时 (1/23(周六) 00时 – 1/24(周日) 23时) |
| 预测依据: | 1/17(周日) 00时 – 1/22(周五) 23时 |
| 忽略最后: | 未忽略任何周期 |
| 季节模式: | 24 小时周期 |
呼叫量
| 行总和 | 初始 | 从初始值更改 | 季节影响 | 贡献 | |||||||
| Start Id | 1/23(周六) 00时 | 1/23(周六) 00时 – 1/24(周日) 23时 | 高 | 低 | 趋势 | 季节 | 质量 | ||||
| 1 | 372 | ± | 115 | 108 | 1/24(周日) 17时 | 2 | 1/24(周日) 04时 | 0 | 99.8% | 0.2% | 确定 |
| 7 | 304 | ± | 145 | 40 | 1/24(周日) 17时 | 3 | 1/24(周日) 05时 | 0 | 99.0% | 1.0% | 确定 |
| 12 | 423 | ± | 116 | 69 | 1/24(周日) 16时 | 2 | 1/24(周日) 04时 | 0 | 99.9% | 0.1% | 良好 |
| 14 | 107 | ± | 37 | 32 | 1/24(周日) 17时 | 2 | 1/24(周日) 05时 | 0 | 93.5% | 6.5% | 确定 |
| 20 | 83 | ± | 34 | 121 | 1/24(周日) 17时 | 2 | 1/24(周日) 05时 | 0 | 99.6% | 0.4% | 确定 |
| 24 | 186 | ± | 67 | 71 | 1/24(周日) 13时 | 2 | 1/24(周日) 04时 | 0 | 99.2% | 0.8% | 确定 |
| 28 | 261 | ± | 112 | 256 | 1/24(周日) 20时 | 2 | 1/24(周日) 04时 | 0 | 99.9% | 0.1% | 确定 |
| 37 | 256 | ± | 147 | 151 | 1/24(周日) 13时 | 2 | 1/24(周日) 04时 | 0 | 99.9% | 0.1% | 确定 |
| 46 | 202 | ± | 91 | 78 | 1/24(周日) 11时 | 2 | 1/24(周日) 04时 | 0 | 99.9% | 0.1% | 确定 |
| 48 | 446 | ± | 139 | 136 | 1/24(周日) 16时 | 2 | 1/24(周日) 05时 | 0 | 100.0% | 0.0% | 确定 |
周末(1/23-1/24)中等呼叫量地区单量预测和质量评估:
- 地区id为1的呼叫量预计增加108;
- 地区id为7的呼叫量预计增加40;
- 地区id为12的呼叫量预计增加69;
- 地区id为14的呼叫量预计增加32;
- 地区id为20的呼叫量预计增加121;
- 地区id为24的呼叫量预计增加71;
- 地区id为28的呼叫量预计增加256;
- 地区id为37的呼叫量预计增加151;
- 地区id为46的呼叫量预计增加78;
- 地区id为48的呼叫量预计增加136;
预测质量评估为确定,表明预测模型对于这些地区的预测结果较为可靠。
5.3.5 未来7天高呼叫量地区各时段单量预测表:

5.4 客户价值分析(乘客)
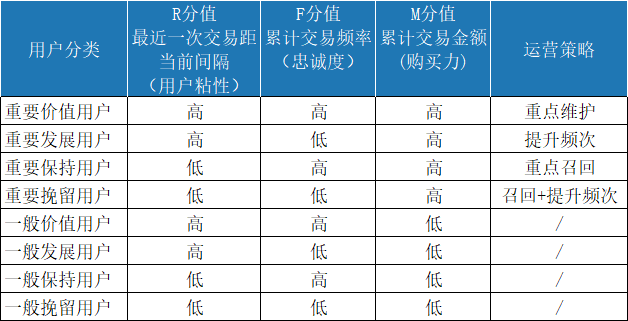
5.4.1 RFM用户价值分类依据(分成8类是否有意义,多?)
5.4.2 各类型用户占比及其消费贡献占比、各类型用户清单
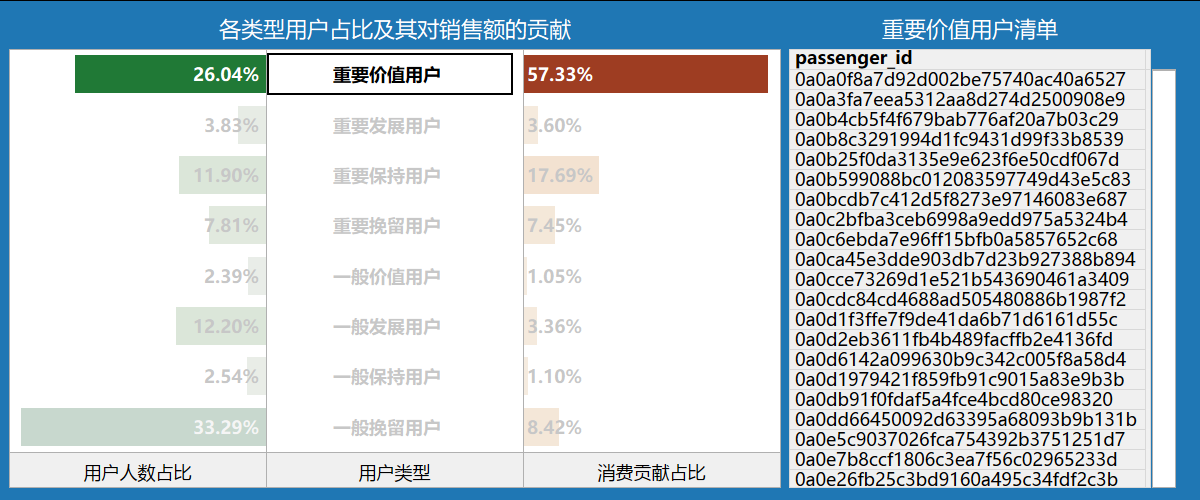
• 重要价值客户:用户占比26.04%,消费贡献占比57.33%。
他们近期有使用网约车服务,使用频率高且消费金额大。对于这些用户,可以提供定制化的服务或特别回馈奖励,进一步增加他们的忠诚度。如VIP会员专属优惠(合作酒店/航空公司/景点门票优惠)、高峰期优先约车服务,快速通道、积分兑换、包月优惠卡等。
• 重要发展客户:用户占比3.83%,消费贡献占比3.60%。
近期客户,消费金额高,但使用频率相对较低。可以考虑设定使用频率奖励计划,让用户在多次使用后获得更大的回报,如累计一定次数后提供免单券或特殊折扣。

• 重要保持客户:用户占比11.90%,消费贡献占比17.69%。
最近没有消费的客户,但过往消费频率高、消费金额大。可以通过提供优惠券奖励计划、特别回馈活动或其他具有价值的信息内容,吸引用户重新关注和使用平台。例如,提供打折券、积分奖励或免费乘车券等,作为再次使用平台的奖励。同时保持与这些用户的沟通,并定期向他们发送有关平台更新、新功能、活动和特别优惠的信息。
• 重要挽留客户:用户占比7.81%,消费贡献占比7.45%。
消费金额大,但消费频率低,且最近没有消费的用户。设计召回策略,通过限时特惠活动或通知提醒吸引他们重新使用网约车服务。如折扣日、特别优惠时段、短信提醒用户账户中的积分即将过期,或者推送特殊活动和服务更新等,保持用户对平台的关注并提醒他们再次使用;可与影响力较大的社交媒体人物、博主合作,通过他们的推荐和评价,增加平台的曝光度和可信度。
• 其他4类一般的用户,其运营的时间、成本在重要的基础上,力度相对有所减少即可。
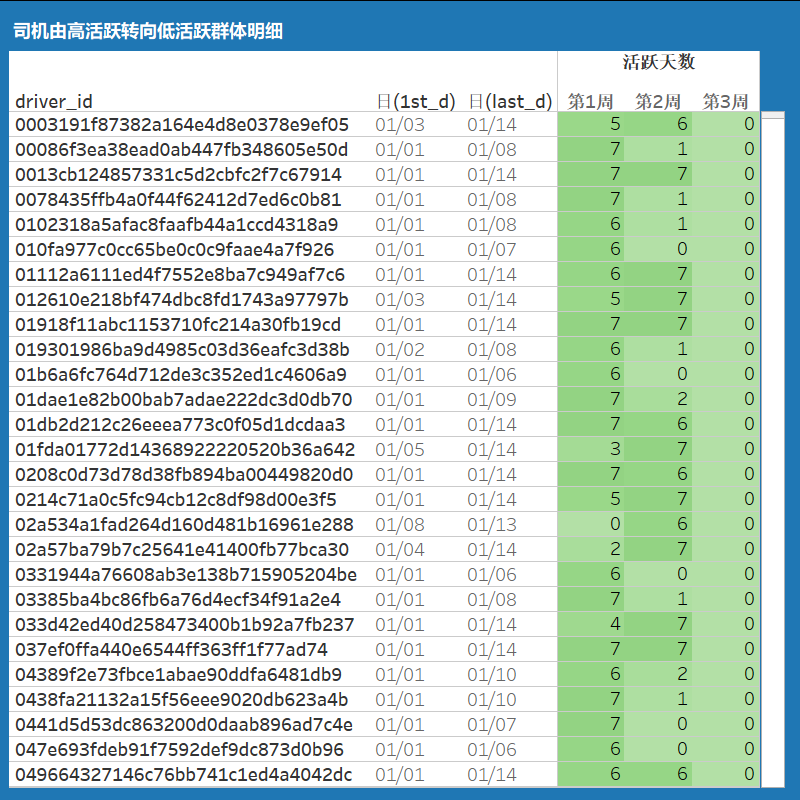
5.5 司、乘 高向低活跃监控
- 活跃司机转向沉默司机群体:周活跃(上线)至少6天降至3天以下
策略措施:
1)了解司机需求:针对不同类型的司机,建立不同的激励机制,以满足其需求。例如,对于经验丰富的高活跃司机,可以设立更高的单量奖励,对于新司机,可以提供更多的订单、低保等福利,鼓励其逐步提高活跃度;
2)提高收入和福利待遇:设立高收益保底、重点加价区域、促销优惠等激励措施,提高司机收入,增加其上线时间和活跃度。同时,提供充足的保险、医疗等福利待遇,让司机感受到公司的关爱和支持;
3)优化派单算法:通过大数据分析和算法模型,实现高效匹配订单和司机,提高派单成功率和效率,降低司机空驶率,提高其效益和满意度;
4)加强培训和沟通:定期开展培训和交流活动,提高司机服务意识和技能,加强对司机的沟通和关注,及时解决其遇到的问题和不满意情况,增强其对公司的归属感和忠诚度;
5)优惠购买车辆和维护服务:为司机提供优惠购买车辆和维护服务,帮助其降低运营成本,提高收益;
6)合理管理和评估:建立科学的管理和评估机制,不断监测和调整司机活跃度,对低活跃司机进行分类管理和跟进,及时采取激励措施和调整策略,激发其在线时长和活跃度,提高其满意度和归属感,从而实现司机和平台共赢的目标。
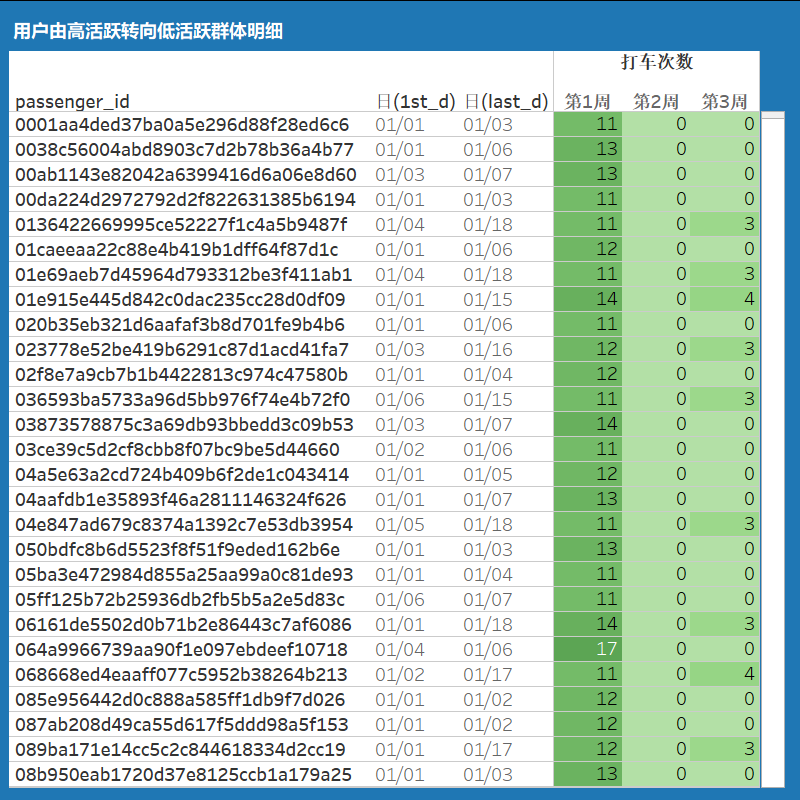
- 高频用户转向低频用户的群体:周打车10次以上降至5次以下
策略措施:
1)个性化推送和优惠:基于用户历史订单和偏好数据,进行智能分析,向用户提供个性化的推送内容和专属优惠券。这可以激发用户重新使用平台,并提供与他们兴趣相关的服务;
2)活动和促销活动:定期开展有吸引力的活动和促销活动,如免费券、折扣券、积分奖励等,以吸引用户重新使用平台。同时,这些活动也能增加用户对平台的参与度和互动性;
3)用户反馈和改进:建立用户反馈机制,积极听取用户意见和建议,并快速响应和解决问题,提高用户对平台的信任感和满意度;
4)客户关怀和忠诚计划:针对低活跃用户群体,开展客户关怀和忠诚计划,如定期发送问候短信、抽送礼品卡活动、提供专属福利等,让用户感受到被重视和关心,提高用户活跃度,实现用户运营和增长的目标。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号