
数据采集与融合技术实践3
数据采集与融合技术实践3
任务一
实验要求
指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施,我的学号是132301146,所以我的总页数应该控制在46页之内(一般达不到),下载的图片量最多为146张。
实验思路
这次任务分成了单线程和多线程模式,用到的方法略有不同。
单线程模式
单线程模式下,我从中国天气网首页开始,用一个队列 to_visit 存待访问网址,用 visited 记录已经访问过的页面,按类似 BFS 的方式一页一页爬,限制最多 46 页。每访问一页就用 requests 把 HTML 拿下来,然后再用 BeautifulSoup 解析出所有链接继续扩展爬取范围,同时找出页面里的所有 img 标签,把图片的 src 拼成完整 URL。用一个 downloaded_imgs 集合给图片链接去重,保证同一张图片只下载一次,然后按顺序把最多 146 张图片保存到本地的叫作 images 的文件夹里。但是这样做的话,程序的运行时间会比较就,因为照片是一张一张爬的。
多线程模式
多线程模式下,我先只做“收集链接”的工作,同样从起始页开始遍历页面,用 BeautifulSoup 找出所有图片 URL,利用 collected_set 去重,把不重复的图片地址依次放进 image_urls 列表中,直到收集到 146 张或者页面上限。收集完后,再开启多线程下载:为每个图片 URL 创建一个线程,调用 urllib.request.urlretrieve 把图片保存到本地,并用 join() 等所有线程结束,这样就实现了图片的并发下载,提高了整体下载效率。根据后面测试,比单线程快了将近10倍。
代码和图片
任务要求指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施,我的学号是132301146,所以我的总页数应该控制在46页之内(一般达不到),下载的图片量最多为146张。
单线程方法:
1.进入一个页面,并抓取所有图片并马上下载。
这是中国气象网站的部分数据,其中,我们可以发现,其主要的图片链接保存在<img>块中:
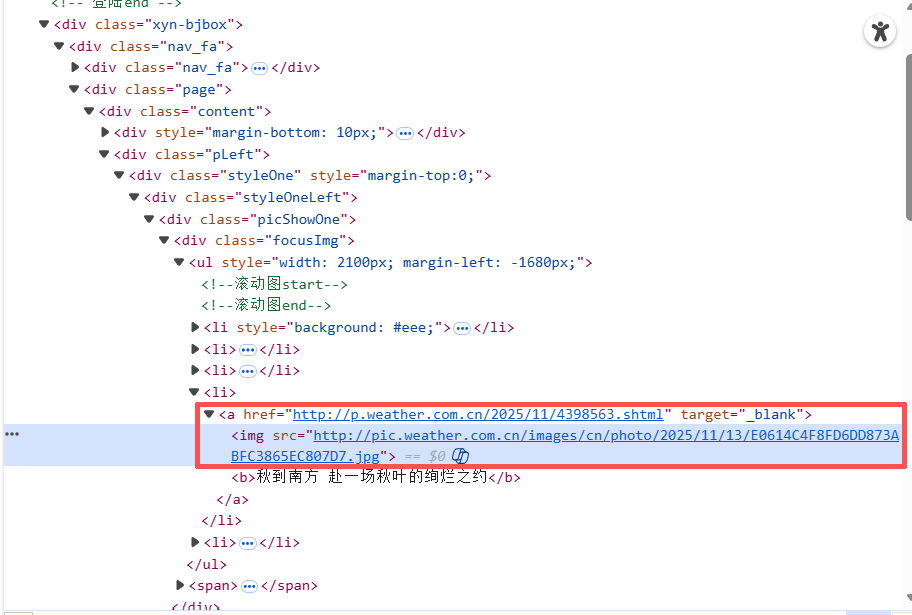
因此,我使用soup.find_all("img")方法,获得所有<img>块,并下载其中内容。
相关代码展示:
for img in soup.find_all("img"):
if img_cnt>=max_images:
break
src=img.get("src")
if not src:
continue
img_url=urljoin(url,src)
if not img_url.startswith("http"):
continue
#这里的downloaded_imgs为已经下载过的链接的集合,如果这个链接已经下过,就跳过
if img_url in downloaded_imgs:
continue
downloaded_imgs.add(img_url)
img_cnt+=1
print("第",img_cnt, "张图片:",img_url)
try:
ir=requests.get(img_url,headers=headers,timeout=10)
except:
continue
#下载图片,并将其格式全部转为jpg
if ir.status_code==200:
file_path=os.path.join(image_dir, f"single_{img_cnt:03d}.jpg")
with open(file_path, "wb") as f:
f.write(ir.content)
2.收集页面中的链接,并加入待访问队列。
一张页面一般不会有146张图片,所以我们要多找几个页面爬取,我以主页面为出发点,爬取主页面中的链接并访问,如此递归
我们可以发现,url数据存在<a>块的herf中:
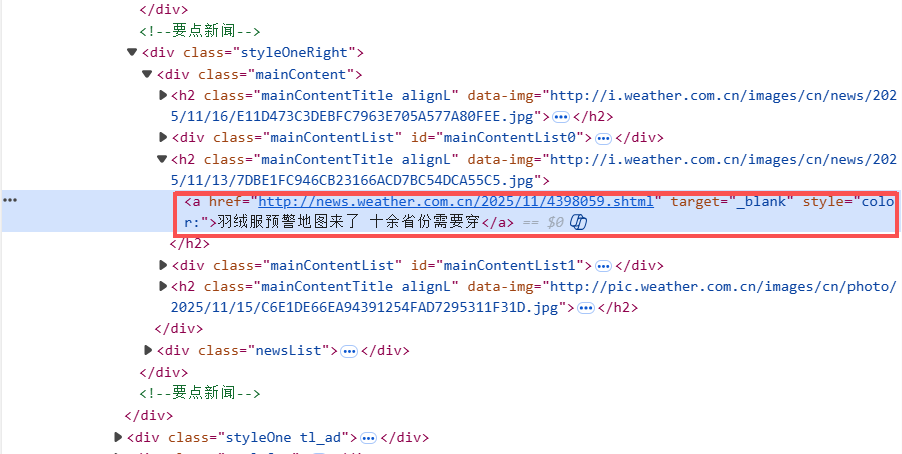
因此,我使用soup.find_all("a")和a.get("href")来提取url
相关代码展示:
#加入新的页面链接
for a in soup.find_all("a"):
href=a.get("href")
#没有就跳过
if not href:
continue
new_url=urljoin(url, href)
if "weather.com.cn" in new_url and new_url.startswith("http"):
#保证链接不重,防止环状结构
if new_url not in visited and new_url not in to_visit:
to_visit.append(new_url)
部分结果图片展示:
images文件夹:
终端:
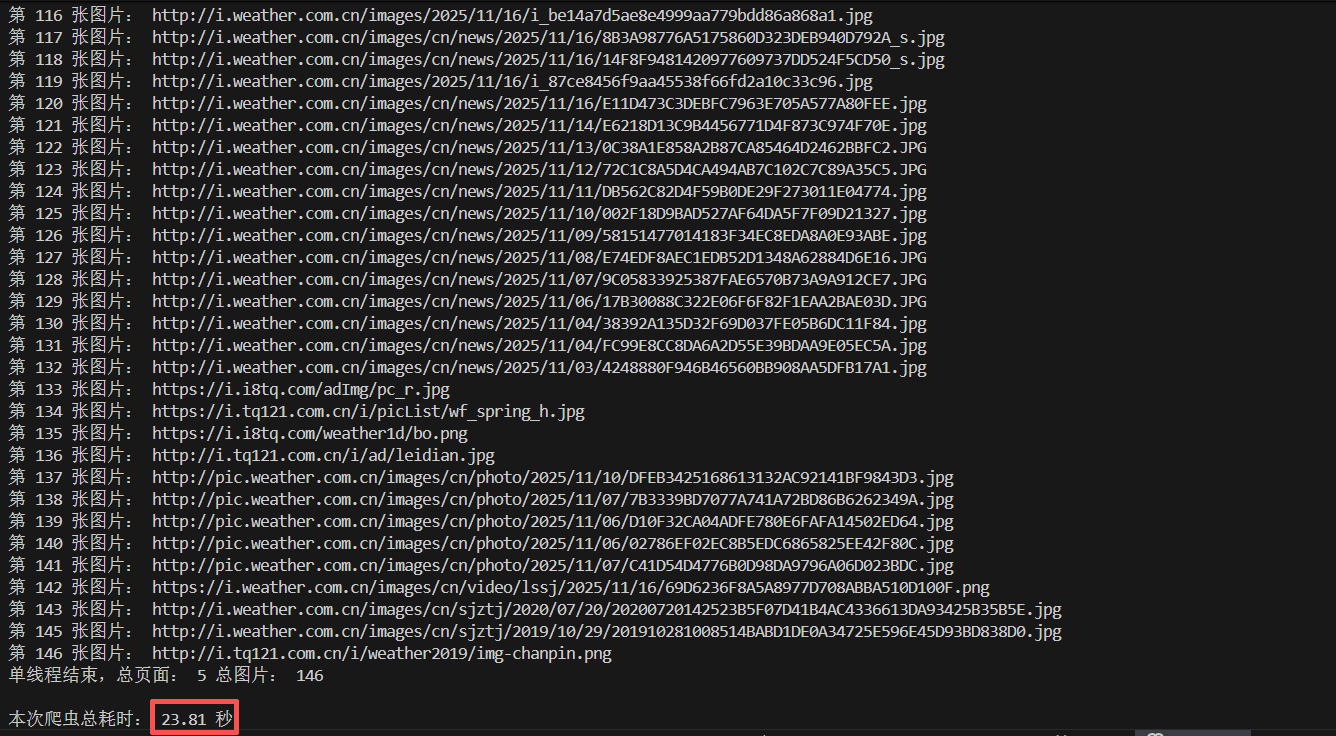
可见,146张图片的爬取耗时是23.81秒,速度较慢,这是因为单线程方法是一张一张地爬取图片,速率较低。
多线程方法:
1.先遍历页面,仅负责收集图片URL,但是并不下载图片
这里的代码和单线程差不多,唯一不同就是先不下载图片,只是收集图片的url存入集合中并去重。故不重复展示代码
2.使用threading.Thread启动多个线程并发下载
收集完146张图片的url后,使用threading.Thread并发下载图片:
相关代码展示:
#多线程下载
threads=[]
idx=0
for img_url in image_urls:
idx+=1
file_path=os.path.join(image_dir, f"multi_{idx:03d}.jpg")
print("准备下载:", img_url)
t=threading.Thread(target=urllib.request.urlretrieve, args=(img_url, file_path))
t.start()
threads.append(t)
for t in threads:
t.join()
结果截图:
images文件夹:
终端:
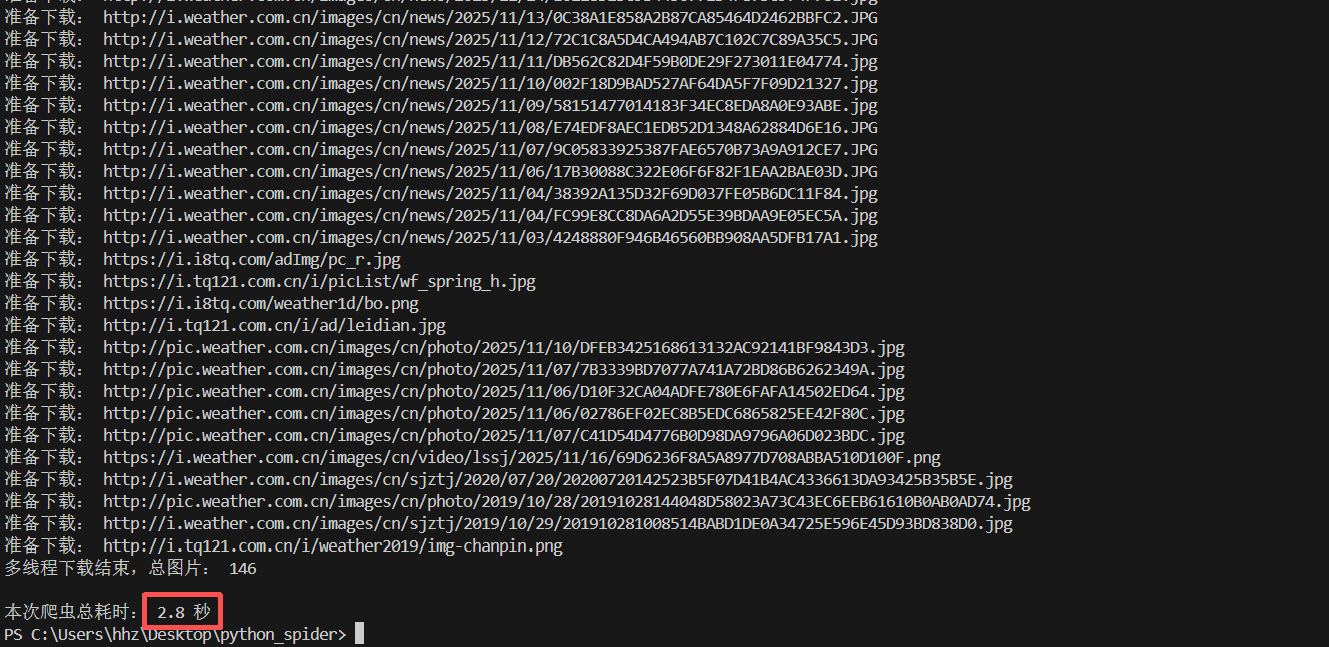
可见这次只用了2.8秒就下载完了146张图片,速度明显加快,这是因为多线程是并行下载图片,效率较高。
作业心得
通过这次作业,我完整实现了从爬取页面到解析HTML到提取图片到保存文件的完整数据采集流程,感觉收获非常大。在单线程模式里,我能比较清楚地看到爬虫的执行顺序,但速度确实慢;在多线程模式中,我真正体会到了并发带来的效率提升。尤其是在图片较多的情况下,多线程的下载速度可以说是成倍增长。同时我也意识到了爬虫开发中需要注意的几个关键点,比如url和图片链接需要去重,在一开始的时候,由于我没考虑到去重限制,导致爬了很多相同的照片进来,同时也会在几个网页链接之间来回打转,后面我设置了一个集合来去除相同照片和链接后,就不会一直爬同样的图片和链接了。
任务二
任务要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
实验思路
本次实验的思路是用 Scrapy + Xpath + MySQL 完成东方财富网股票数据的自动爬取和入库。先在 items.py 里定义 StockSpiderItem,把股票代码、名称、最新价等字段都写成 Item 属性;然后在 pipelines.py 中用 pymysql 连接 MySQL,准备好插入语句,让后面 yield 出来的数据都能直接写进表。爬虫文件 eastmoney_spider.py 里,在 start_requests 中按页数循环拼接东方财富网的接口 URL 发送请求,在 parse 中先用 Selector + xpath("string(.)") 取出整段 JSON 字符串,再用 json.loads 解析,遍历 diff 列表,把每只股票的各个字段填进 StockSpiderItem,最后用 yield item 交给 Pipeline 入库。这样就完成了“接口请求 → Xpath 提取 JSON → 解析字段 → 写入 MySQL”的完整流程。
代码和图片
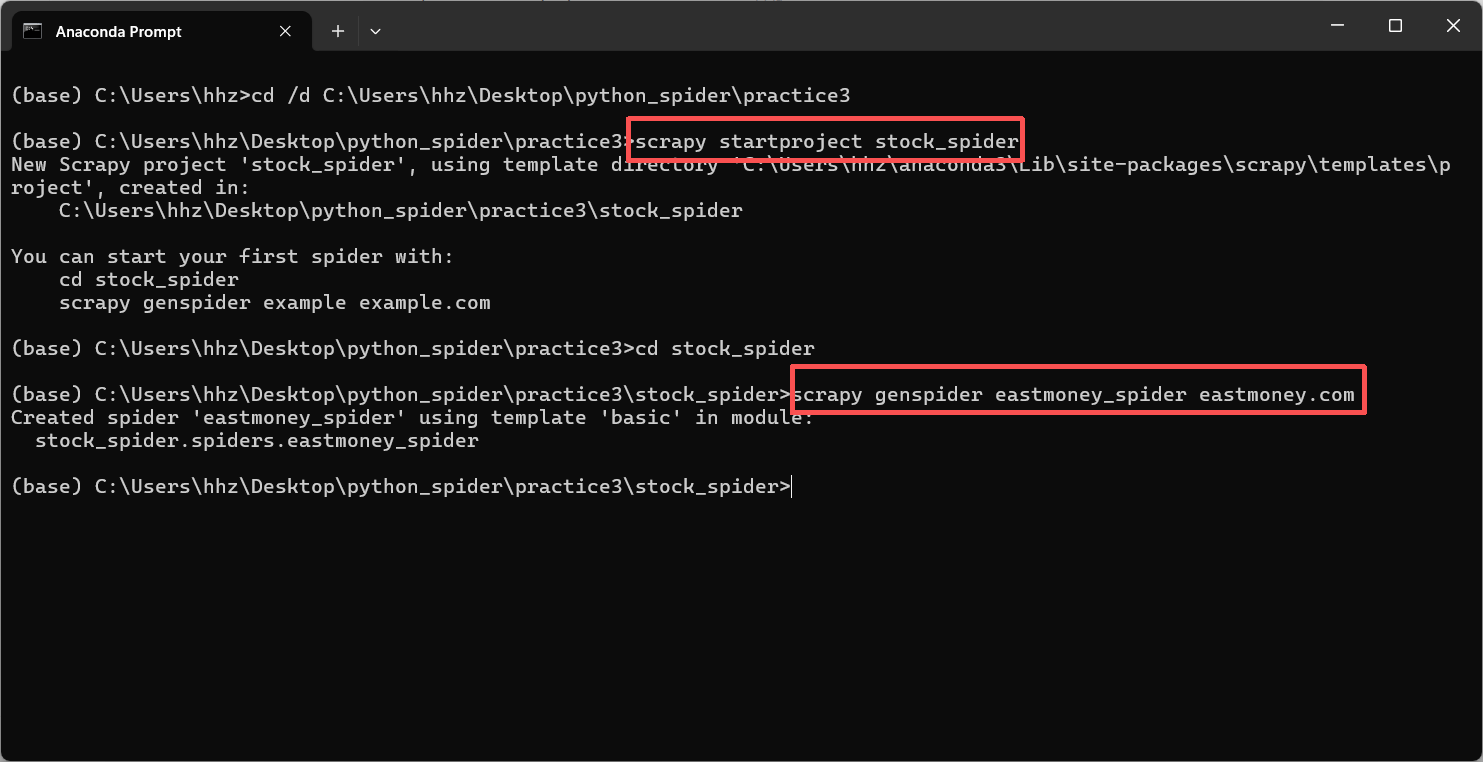
首先,在终端创建scrapy项目stock_spider
接着,修改items.py里面的代码
改成如下形式:
import scrapy
class StockSpiderItem(scrapy.Item):
# 股票代码
bStockNo=scrapy.Field()#股票名称
bStockName=scrapy.Field()#最新报价
bNewPrice=scrapy.Field()#涨跌幅
bChangeRate=scrapy.Field()#涨跌额
bChangeAmt=scrapy.Field()#成交量
bVolume=scrapy.Field()#成交额
bTurnover=scrapy.Field()#振幅
bAmplitude=scrapy.Field()#最高
bHigh=scrapy.Field()#最低
bLow=scrapy.Field()#今开
bOpenToday=scrapy.Field()#昨收
bCloseYesterday=scrapy.Field()
接着修改pipeline.py的代码,让其在爬虫开始时链接数据库
self.conn=pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
db=self.dbname,
charset='utf8mb4'
)
self.cursor = self.conn.cursor()
print("已连接 MySQL 数据库")
并设置插入语句
sql = """
INSERT INTO {table}
(bStockNo, bStockName, bNewPrice, bChangeRate, bChangeAmt,
bVolume, bAmplitude, bHigh, bLow, bOpenToday, bCloseYesterday)
VALUES (%s, %s, %ss, %s, %s, %s, %s, %s, %s, %s, %s)
""".format(table=self.table)
然后,修改settings.py中的配置,设置头部等信息。
最后编写eastmoney_spider.py脚本
对于网站的解析和上一次实践博客中的大致相同,网站结构为
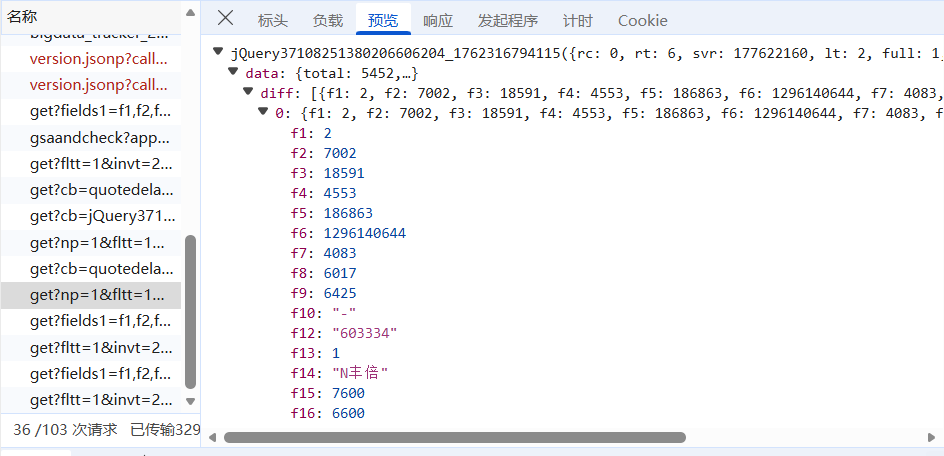
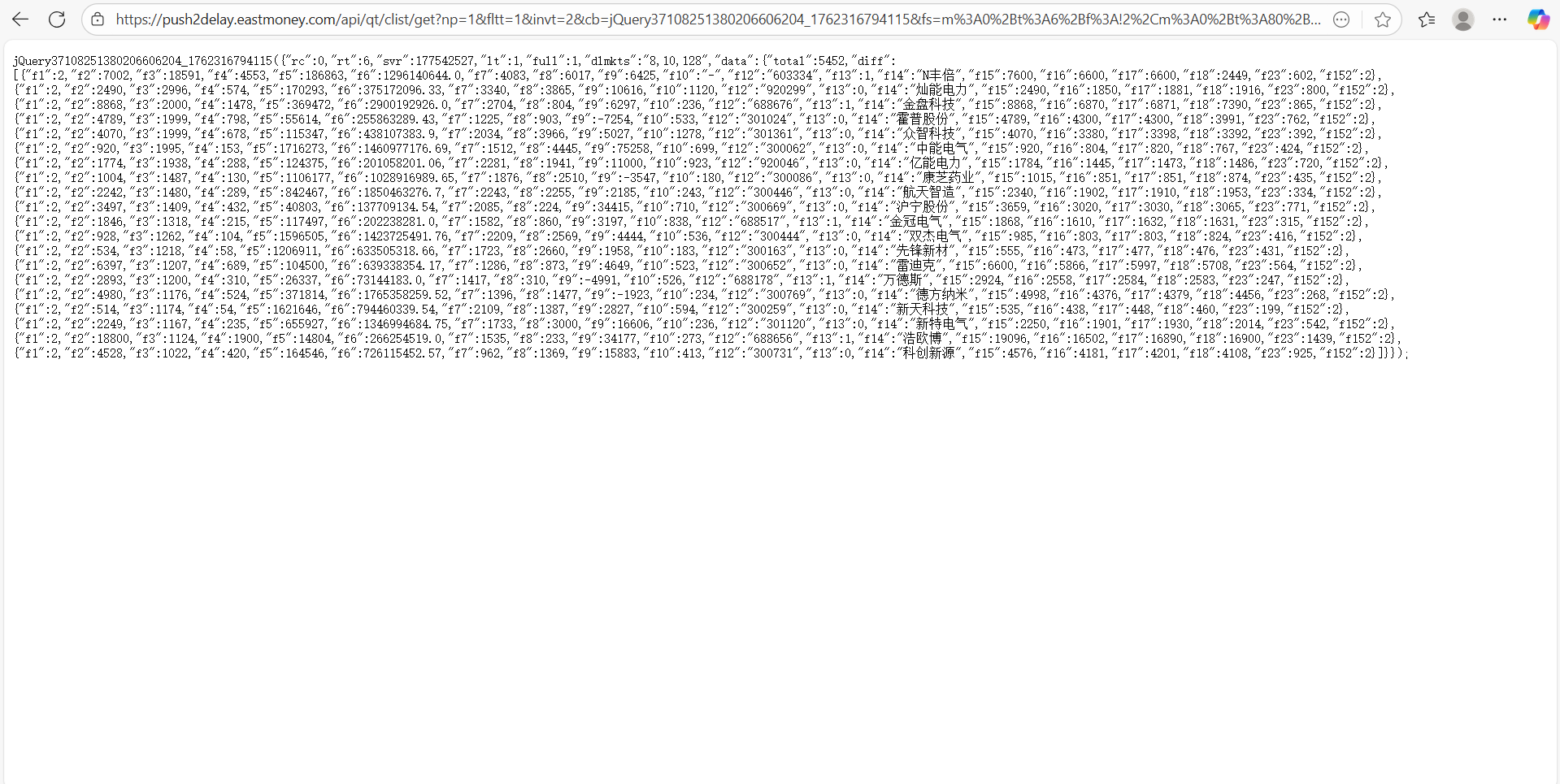
关于解析提取数据方面,本次实验用 Xpath 取出整个响应体内容,再用再用 json.loads 把这个字符串解析成 Python 字典,并且在提取数据后,程序会将每只股票的数据填充到item里,最后用yield item将数据交给Scrapy的Pipeline
相关代码:
Xpath部分:
sel=Selector(text=response.text)
#用xpath取出文本
json_text=sel.xpath("string(.)").get()
try:
data=json.loads(json_text)
except Exception as e:
print("解析出错:", e)
item部分:
for d in diff_list:
item=StockSpiderItem()
item["bStockNo"]=d.get("f12")
item["bStockName"]=d.get("f14")
item["bNewPrice"]=d.get("f2")
item["bChangeRate"]=d.get("f3")
item["bChangeAmt"]=d.get("f4")
item["bVolume"]=d.get("f5")
item["bTurnover"]=d.get("f6")
item["bAmplitude"]=d.get("f7")
item["bHigh"]=d.get("f15")
item["bLow"]=d.get("f16")
item["bOpenToday"]=d.get("f17")
item["bCloseYesterday"]=d.get("f18")
最后,提前在mysql中建好表,并在stock_spider路径下运行scrapy crawl eastmoney_spider开始爬取数据
结果截图:
终端:
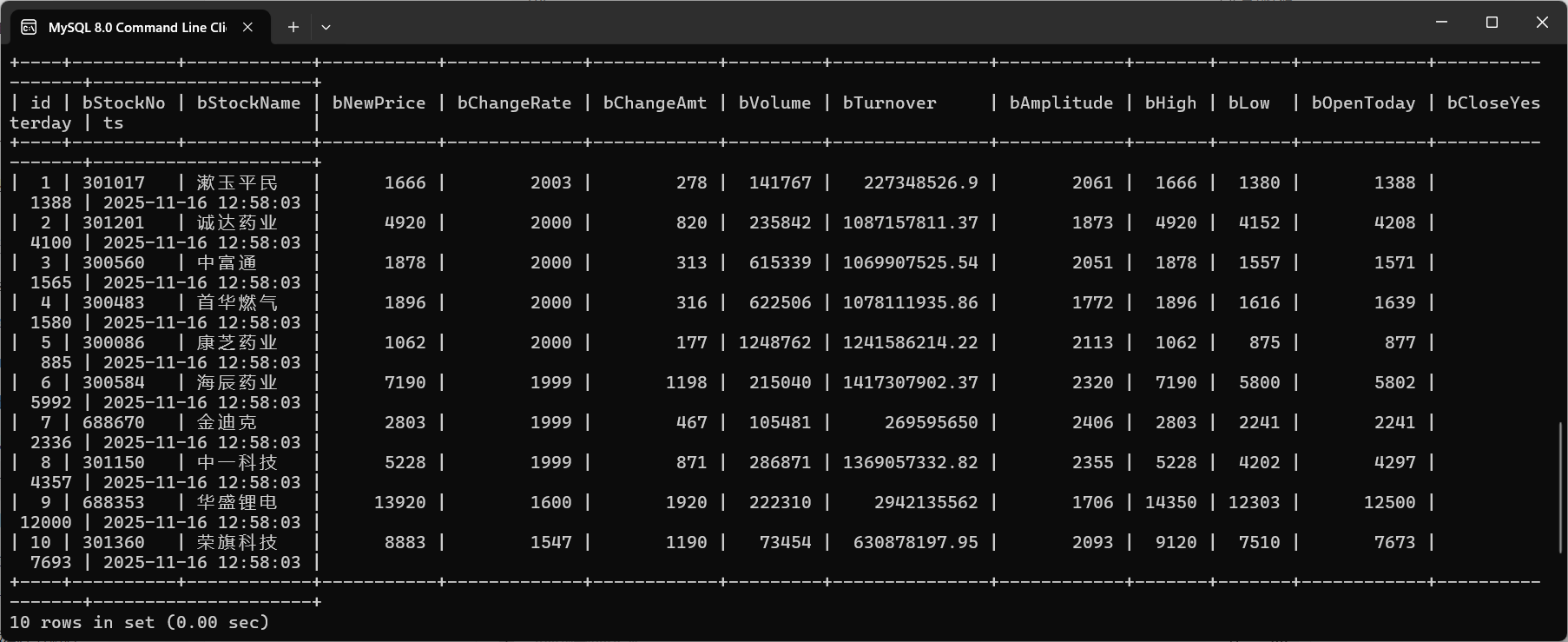
sql查询结果:
作业心得
这次实验主要使用Scrapy+Xpath+MySQL来完成东方财富网股票数据的爬取。整个过程让我熟悉了Scrapy的基本结构,包括Spider用来发送请求、Xpath用来提取数据、Pipeline负责把数据保存到 MySQL中。相比之前用requests的方式,Scrapy的流程更清晰,也更适合做规模化的爬虫。在编写实验代码时,我遇到了一些问题,比如数据库连接失败、数据表不存在、Xpath取值为空等,因为我刚的时候开始直接用 response.text 去 json.loads,发现有时候会解析失败,或者 data.get("diff") 为空。后来改成先用sel = Selector(text=response.text),再json_text = sel.xpath("string(.)").get(),最后json.loads(json_text)解决了问题
任务三
任务要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。这里,我选择的目标网站是中国银行网(https://www.boc.cn/sourcedb/whpj/)
实验思路
本次实验的思路是用 Scrapy + Xpath + MySQL 爬取中国银行外汇牌价数据。先观察网页结构,发现每条外汇记录都在表格的 里,对应的各个字段在一行中的多个 里,所以在 parse 中先用 //table//tr 取出所有行,跳过表头,再用 ./td/text() 拿到每一行的单元格内容,按下标把货币名称和各类买入价、卖出价以及发布时间对应起来。数值字段通过 to_float 做一下转换,清洗掉空值或“-”,最后把这些数据封装进 BocFxItem,用 yield item 交给 Pipeline 写入 MySQL,这样就完成了从网页表格到数据库的自动化采集。
代码和图片
首先,观察网站结构:
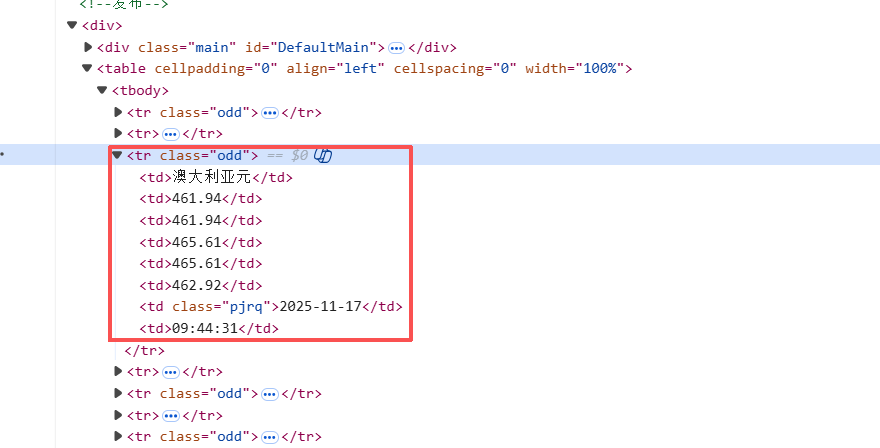
由图片可知,每一组外汇数据储存在一个个<tr>块里,而每个<tr>块里又会有一组<td>储存具体数值
因此我先用 Xpath 找到整张外汇牌价表的每一行,然后对于每一行,用 Xpath 取出所有单元格文本,其中,货币名称,现汇买入价,现钞买入价,现汇卖出价,现钞卖出价,发布时间分别对应第0,1,2,3,4,6个<td>块,在爬取完数据之后,把数据组装成item,通过pipline存储到数据库里。
相关代码展示:
rows=response.xpath("//table//tr")
#第一行通常是表头,跳过
for tr in rows[1:]:
tds=tr.xpath("./td/text()").getall()
#有些tr可能是空行,这种就不要了
if len(tds) < 7:
continue
currency=tds[0].strip()
tbp=tds[1].strip()
cbp=tds[2].strip()
tsp=tds[3].strip()
csp=tds[4].strip()
time_str=tds[6].strip()
if not currency:
continue
item=BocFxItem()
item["Currency"]=currency
item["TBP"]=self.to_float(tbp)
item["CBP"]=self.to_float(cbp)
item["TSP"]=self.to_float(tsp)
item["CSP"]=self.to_float(csp)
item["Time"]=time_str
print("抓到:", item["Currency"], item["TBP"], item["CBP"], item["Time"])
yield item
步骤和任务2差不多。
结果展示:
终端:
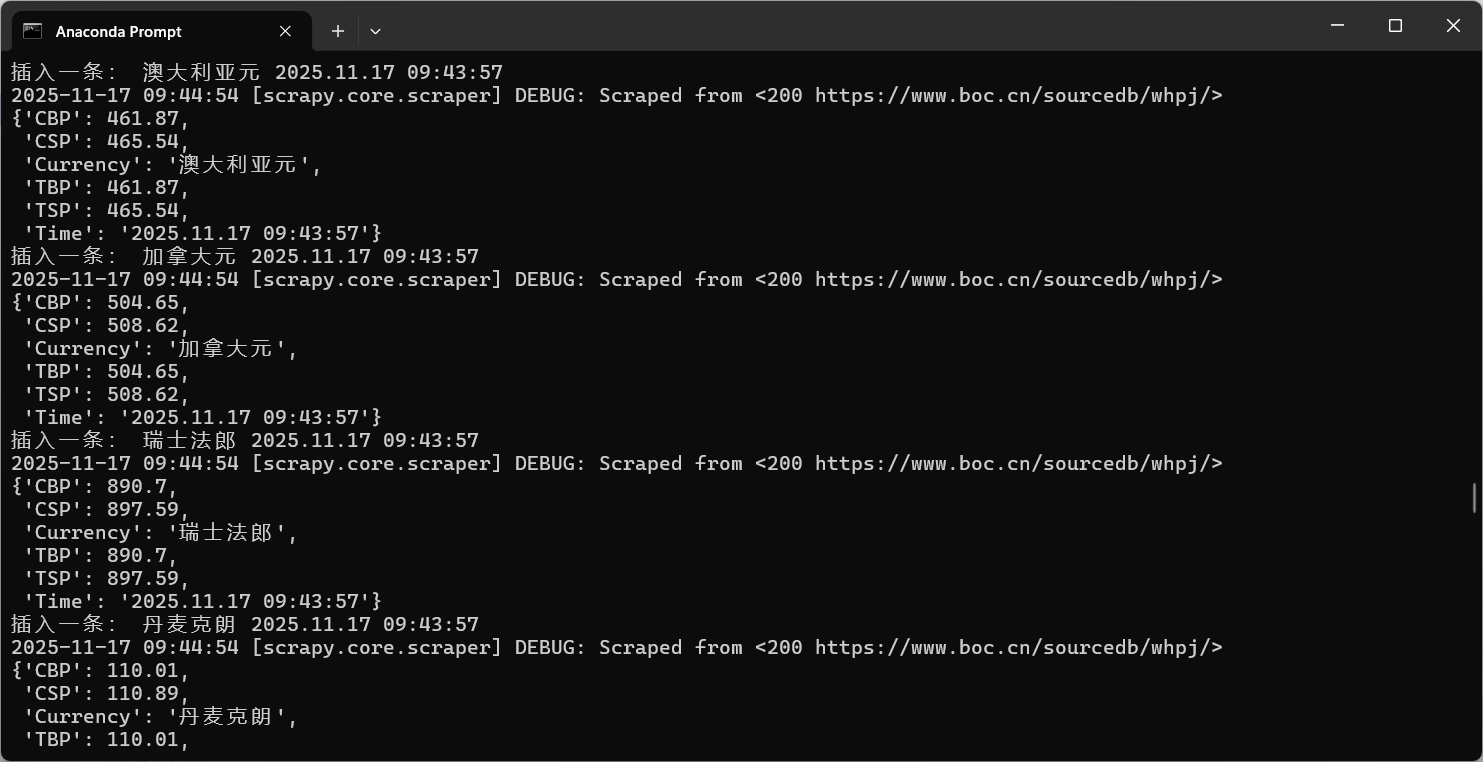
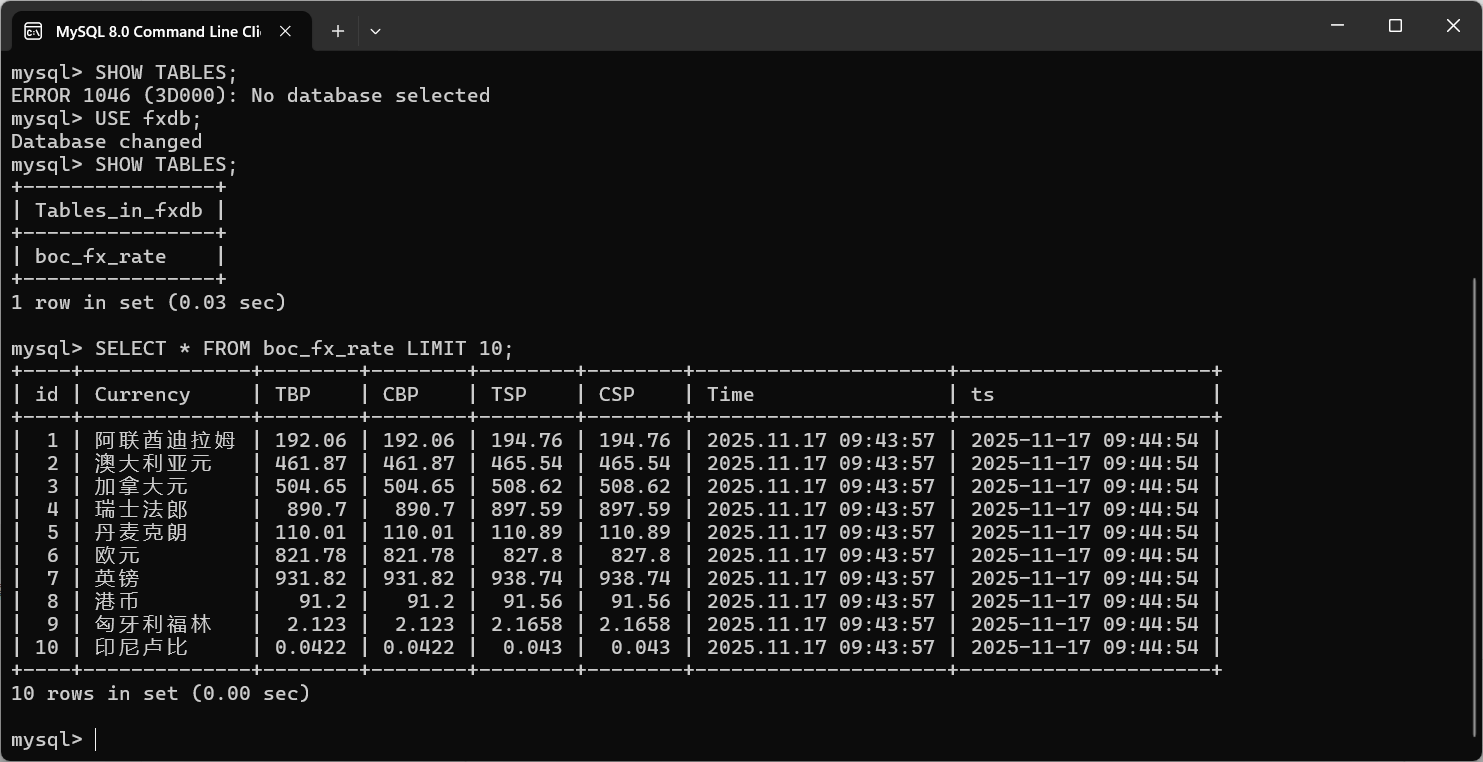
数据库:
作业心得
这次实验我遇到了一些问题,不过解决以后也感觉收获颇丰,一开始我只是照着网页看见一堆 <table><tr><td>,但用 Xpath 的时候总是选不准,要么把表头也算进去,要么把空行也爬进来,导致 tds 长度不够、代码直接报错。后来我在循环里加了 rows[1:] 跳过表头,又对 len(tds) < 7 和货币名称是否为空做了判断,这样就把无效行过滤掉了。还有一个问题是汇率字段里有时候是空串或者“-”,一转 float 就异常,我就单独写了一个 to_float 函数,先判断是不是空或者“-”,是的话就返回 None,否则再转成浮点数。处理完这些坑之后,把数据封装成 BocFxItem,交给 Pipeline 写入 MySQL,终端输出和数据库查询都正常,感觉自己对 Scrapy + Xpath + MySQL 这一整套流程比之前清晰多了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号