
数据采集与融合技术实践1
1. 任务一
任务要求
用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息。
实现思路
通过观察,我发现我需要的数据保存在<tbody></tbody>里的每个<tr></tr>里
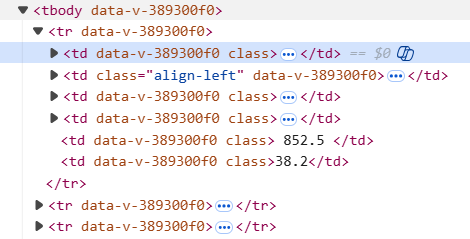
其中,每个<tr></tr>块保存一个学校的数据,而排名,学校名称,所在地区,院校类型,院校评分分别保存在<tr></tr>块中第0,2,3,4个<td></td>块里。因此,我首先提取tbody获取主体数据,接着使用find_all函数将每个tr保存成一个列表,接着遍历列表,获取每个tr块中td的数据并输出。
代码展示
from bs4 import BeautifulSoup
import re
import urllib.request
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
response = urllib.request.urlopen(url)
data = response.read()
# 字节解码成字符串
html = data.decode()
soup = BeautifulSoup(html, "html.parser")
# 在 soup 中找到表格主体 <tbody> 节点
tbody = soup.find("tbody")
# 在 <tbody> 中找到所有行 <tr>
rows = tbody.find_all("tr")
print("排名 学校名称 省市 学校类型 总分")
print("----------------------------------------")
# 遍历每一行,每行是一个数据
for row in rows:
# 取出该行的所有的 <td>
cols = row.find_all("td")
# 使用 .text 获取文本,并用 strip 去掉首尾的空白
rank = cols[0].text.strip()
name_raw = cols[1].get_text(strip=True)
# 截取学校名称
name = re.findall(r"[\u4e00-\u9fa5]+大学", name_raw)
name = name[0]
# 截取省份
province = cols[2].text.strip()
# 截取院校类型
category = cols[3].text.strip()
# 截取分数
score = cols[4].text.strip()
print(rank + " " + name + " " + province + " " + category + " " + score)
输出结果
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2 | 北京大学 | 北京 | 综合 | 746.7 |
| 3 | 浙江大学 | 浙江 | 综合 | 649.2 |
| 4 | 上海交通大学 | 上海 | 综合 | 625.9 |
| 5 | 南京大学 | 江苏 | 综合 | 566.1 |
| 6 | 复旦大学 | 上海 | 综合 | 556.7 |
| 7 | 中国科学技术大学 | 安徽 | 理工 | 526.4 |
| 8 | 华中科技大学 | 湖北 | 综合 | 497.7 |
| 9 | 武汉大学 | 湖北 | 综合 | 488.0 |
| 10 | 中山大学 | 广东 | 综合 | 457.2 |
| 11 | 西安交通大学 | 陕西 | 综合 | 452.5 |
| 12 | 哈尔滨工业大学 | 黑龙江 | 理工 | 450.2 |
| 13 | 北京航空航天大学 | 北京 | 理工 | 445.1 |
| 14 | 北京师范大学 | 北京 | 师范 | 440.9 |
| 15 | 同济大学 | 上海 | 理工 | 439.0 |
| 16 | 四川大学 | 四川 | 综合 | 435.7 |
| 17 | 东南大学 | 江苏 | 综合 | 432.7 |
| 18 | 中国人民大学 | 北京 | 综合 | 409.7 |
| 19 | 南开大学 | 天津 | 综合 | 402.1 |
| 20 | 北京理工大学 | 北京 | 理工 | 395.6 |
| 21 | 天津大学 | 天津 | 理工 | 390.3 |
| 22 | 山东大学 | 山东 | 综合 | 387.9 |
| 23 | 厦门大学 | 福建 | 综合 | 383.3 |
| 24 | 吉林大学 | 吉林 | 综合 | 379.5 |
| 25 | 华南理工大学 | 广东 | 理工 | 379.4 |
| 26 | 中南大学 | 湖南 | 综合 | 378.6 |
| 27 | 大连理工大学 | 辽宁 | 理工 | 365.1 |
| 28 | 西北工业大学 | 陕西 | 理工 | 359.6 |
| 29 | 华东师范大学 | 上海 | 师范 | 358.0 |
| 30 | 中国农业大学 | 北京 | 农业 | 351.5 |
实验心得
通过这次实验,我学到了如何系统地完成一个网页数据爬取任务。首先,我学会了在爬虫前使用浏览器的开发者工具分析网页结构,确定数据所在的标签层级;其次,我掌握了 BeautifulSoup 的基本用法。学会了find,find_all等函数的使用。此外,我也认识到网页编码、标签不规则、数据缺失等问题会影响爬取结果,因此编写爬虫代码时要加入异常处理和数据清洗步骤。
2. 任务二
任务要求
用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格
实现思路
我选择了当当网(https://search.dangdang.com/?key=%CA%E9%B0%FC&act=input)作为爬取对象,在开始写代码之前,我先保存了一份html文件到电脑上查看,通过观察,我发现关于商品和价格的数据主要保存在<ul class="bigimg cloth_shoplist" ...>...</ul>里面的<li>...</li>块里,每个li块存储一个商品的数据

我使用了<ul class="bigimg cloth_shoplist"[^>]*>(.*?)</ul>正则表达式来提取信息,其中[^>]*可以捕获任意长度的非>字符,而(.*?)可以捕获<ul>...</ul>之间的所有内容,这里便是我所需要的数据存储的地方,并且我设置了re.S来使(.*?\)可以捕获多行的内容。在捕获完后,我使用re.find_all将所有<li>...</li>块切出来,用到的正则表达式为<li\b[^>]*>(.*?)</li>,”\b”用来保证切出<li ...>的字块。在切完后,我将数据保存到列表,并对列表遍历,用正则表达式<p class="name"[^>]*>.*?<a title="([^"]+)"和<span class="price_n"[^>]*>\s*(?:¥|¥)?\s*([0-9.]+)分别获取到商品的名称和价格。(?:¥|¥)?用来匹配可能遇到的货币符号,([0-9.]+)则是捕获组,用来捕获价格。最后,保存获取到的名称与价格为列表并输出
代码展示
import re
import requests
url="https://search.dangdang.com/?key=%CA%E9%B0%FC&SearchFromTop=1&catalog="
#发起GET请求
r=requests.get(url,headers={"User-Agent": "Mozilla/5.0"})
html=r.text
#<ul class="bigimg cloth_shoplist"...>...</ul>切出来,并设置re.S使得可以跨行匹配
m=re.search(r'<ul class="bigimg cloth_shoplist"[^>]*>(.*?)</ul>',html,re.S)
#取第1个分组
part=m.group(1)
#在该片段内找所有 li 块,捕获每个 li 的内部HTML
lis=re.findall(r'<li\b[^>]*>(.*?)</li>',part,re.S)
i=0#商品编号
for li in lis:
#商品名称
name=""
#在li内定位商品名所在的<p class="name"...>,取a的title
m1=re.search(r'<p class="name"[^>]*>.*?<a title="([^"]+)"',li,re.S)
name=m1.group(1).strip()
#商品价格
price=""
#在li内定位商品名所在的<span class="price_n"...>,并且兼容¥或¥
mp=re.search(r'<span class="price_n"[^>]*>\s*(?:¥|¥)?\s*([0-9.]+)',li,re.S)
price=mp.group(1).strip()
#输出
if name and price:
i+=1
print(f"{i}. {name} {price}")
输出结果
| 序号 | 商品名称 | 价格 |
|---|---|---|
| 1 | 新款儿童书包 男生小学生女童包一到六年级 减负护脊双肩包大容量 | 70.50 |
| 2 | 书包男女生 1-6年级大容量新款小学生耐磨透气书包儿童双肩包小学生男女孩双肩书包 | 99.80 |
| 3 | 小学生英伦风书包男6-12岁轻便大容量女童书包儿童双肩包6xn | 120.00 |
| 4 | 双肩包男商务背包户外旅行休闲男款笔记本电脑包时尚学生书包中学wrj | 148.00 |
| 5 | 新款儿童休闲书包轻便透气中小学男生大容量双肩背包7xt | 117.00 |
| 6 | 儿童书包一到三年级女小学生男童男孩轻护脊减负女童背包bl6 | 149.80 |
| 7 | 新版 加厚 中国地图・世界地图书包版(学生版 mini多功能地图 桌垫 鼠标垫)中学小学生地理学习23.5*32.5厘米 | 3.40 |
| 8 | 桌面速查-中国地图 世界地图 书包版 学生专用版 加厚 尺寸32.4*23.5厘米 地理学习、家庭 | 1.70 |
| 9 | 中国地图世界地图 桌面速查 书包版 学生专用 地理学习 历史年表 中国地形 世界地形 政区地图折叠地图 学生地理学习 | 11.70 |
| 10 | 中华古诗文经典诵读(全19册)北大版海淀小红书 套书包含:诵读本14册+导读1册+素养训练1册+北大logo摘抄笔记本1 | 92.40 |
| 11 | 小世界童书馆 真的要守住一年级的书包:入学前一定要养成的好习惯 | 22.50 |
| 12 | 桌面速查中国地图+世界地图 学生专用 书包版套装 赠水擦笔 | 5.90 |
| 13 | 【星球款】世界3D凹凸地形立体地图 书包款(16开) 0.29*0.2(米) | 6.00 |
| 14 | 花田小学的属鼠班5-小书包里的秘密(全彩美绘注音) | 14.30 |
| 15 | 我的小小单词书(走进大自然)全套书包含六大主题,内容涉及吃、穿、住、行、娱乐、休闲等日常生活的方方面面,通过生活场景再现 | 7.70 |
| 16 | 沈石溪画本(新版)・虎女蒲公英 本书包含了《虎女蒲公英》《猎狐》两个短篇动物小说 | 11.20 |
| 17 | 书包里的秘密 | 8.70 |
| 18 | 藏在书包里的玫瑰 | 28.70 |
| 19 | 我和米粒系列―书包里的猫 | 9.20 |
| 20 | 书包里的魔法师之二:会飞的滑板(你的书包里藏了什么?快打开来,参加布小丁和萌宠龙猪小七的奇幻之旅!) | 9.90 |
| 21 | 宝葫芦的秘密 百年百部精装典藏版 3-4年级阅读拓展书目,本书包含《大林和小林》 | 15.60 |
| 22 | 装进书包的秘密 | 14.00 |
| 23 | 大书包和大力士(一年级二班) | 10.90 |
| 24 | 书包里的电话号码(一年级二班) | 10.90 |
| 25 | 月光岛 少儿科普名人名著・典藏版 本书包含《月光岛》《马小哈奇遇记》两部科幻小说 | 13.50 |
| 26 | 全新修订 中国地图 高清彩印展开0.87米*0.58米 袋装折叠方便携带 学生教室家用商务办公室地图贴图 | 2.20 |
| 27 | 启发童话小巴士桥梁书(第二辑 ,全5册 )幽默童话故事绘本书 书包去远足 电饭锅参加运动会 冰箱放暑假 吸尘器去钓鱼 暖 | 42.70 |
| 28 | 全新修订 世界地图 高清彩印展开0.87米*0.58米 袋装折叠方便携带 学生教室家用商务办公室地图贴图 | 2.20 |
| 29 | 藏在书包里的玫瑰:青春期男孩女孩专属读本,真诚修订第二版 | 17.10 |
| 30 | 全新修订 中国地图+世界地图 升级版 0.87米*0.58米(袋装 学生教室家用商务办公室地图 袋装) | 4.30 |
| 31 | 双肩包女士2018新款韩版百搭潮背包包软皮休闲时尚旅行大容量书包 | 69.00 |
| 32 | 双肩包女2019新款牛津布小背包韩版潮女士尼龙百搭时尚帆布书包包 | 79.90 |
| 33 | 中国地图 1.06米*0.76米(袋装 学生教室家用商务办公室地图 袋装) | 4.30 |
| 34 | 沈石溪画本(新版)・第七条猎狗,涤荡心灵的动物故事 壮美宏阔的生命画卷 | 11.20 |
| 35 | 全新修订 中国地图+世界地图 升级版 1.06米*0.76米(袋装 学生教室家用商务办公室地图 袋装) | 8.60 |
| 36 | 宝宝认动物-宝宝认世界 牧场里有鸡、鸭、鹅、牛、羊、猪;沙漠里有跳鼠、蝎子、沙鸡、大耳狐……全书包括几百种动物,赠60个 | 4.00 |
| 37 | 雷锋的故事注音版彩图正版书包邮儿童版一二三年级小学生课外阅读语文雷峰书籍日记6-7-8-10岁阅读的课外书 | 5.50 |
| 38 | 世界地图 1.06米*0.76米(袋装 学生教室家用商务办公室地图 袋装) | 4.30 |
| 39 | 亲子旅行科普绘本(3-6岁)・小小背包客游北京 | 5.00 |
| 40 | 谜语(宝宝咿呀学说话)大图大字我爱读系列彩图注音版儿童睡前故事书3-6岁幼儿早教语言启蒙绘本一二年级课外阅读拼音睡前读物 | 6.70 |
| 41 | 欧洲民间故事:聪明的牧羊人 五年级上册课外阅读(中小学生课外阅读指导丛书)无障碍阅读 快乐读书吧5上适合小学生课外阅读书 | 7.59 |
| 42 | 共和国70年儿童文学短篇精选集・永远天真,永远爱(平装) | 7.70 |
| 43 | 好的孤独(畅销书作家陈果代表作《好的孤独》新版归来,内容全新升级,陈果亲笔校订,增加全新人生感悟) | 27.80 |
| 44 | 彷徨(鲁迅作品 单行本) | 13.20 |
| 45 | 墨点英文字帖小学生英语提高卷面分意大利斜体英语单词字母描红本 | 6.30 |
| 46 | 【正版 】羊皮卷 正版书包邮 大全集 创业办事职场经商成功励志书籍畅销书排行榜青春励志人生哲学墨菲定律人性的弱点心灵鸡汤 | 7.80 |
| 47 | 二十四节气故事注音版彩图正版书包邮语文一二年级课外书写给儿童的二十四节气的故事这就是24节气绘本 | 7.80 |
| 48 | 中华人民共和国民营经济促进法(实用版) | 7.60 |
| 49 | 格列佛游记正版书包邮原版 乔纳森 世界文学名著 小学生初中生版课外阅读 四五六年级九年级语文 格列夫游记ys | 8.00 |
| 50 | 有声伴读汤姆叔叔的小屋 斯托夫人正版书包邮原著世界文学名著五六年级小学生课外阅读 汤姆大叔的小屋新 | 8.00 |
| 51 | 雾都孤儿 正版书包邮狄更斯五六年级小学生课外阅读 班主任书目人民文学全集 世界名著小说辽海出版社ys | 8.00 |
| 52 | 佛说雨宝陀罗尼经简体注音版弘化常诵佛经读诵本经书结缘书包邮 任选备注 | 5.00 |
| 53 | 欧亨利短篇小说集正版书包邮 小说选中学生初中生高中生课外精选阅读 麦琪的礼物后一片叶子警察与赞美诗ys | 8.00 |
| 54 | 大卫.科波菲尔正版书包邮狄更斯原著高中生课外 世界文学名著中文版中小学生课外 ys | 8.00 |
| 55 | 一个背包客的光影六城记 | 8.60 |
| 56 | 墨点字帖 提高卷面分正楷初中语文中考提分模拟楷书描红字帖精选中考试题练字 | 6.30 |
| 57 | 书包里的秘密 李迪 著 一个关于奉献与坚守的故事 《枪从背后打来》的最新演绎;经典再现 作家出版社 | 8.80 |
| 58 | 海底两万里注音版正版书包邮彩图小学生课外阅读小学版一二三年级5-6-7-8岁语文书目儿童文学名著 | 8.80 |
| 59 | 爱丽丝漫游奇境记彩图注音版正版书包邮梦游仙境一年级二年级小学生课外书6-7-8-10岁儿童课外阅读少儿故事 | 8.80 |
| 60 | 小鹿斑比/小鹿班比注音版正版书包邮彩图儿童版带拼音的童话故事书小学生课外阅读 一二三四年级班主任 | 8.80 |
实验心得
在本次实验中,我遇到了反爬系统,对此,我的方法是只爬取一次网页,并把他保存下来,随后对保存了的网页进行分析,这样,我就可以避免过于频繁发送请求而被反爬。同时这次任务中用到了较为复杂的正则表达式,锻炼了我写正则表达式的能力。
3. 任务三
任务要求
爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG、JPG或PNG格式图片文件
实现思路
福大的网页设置较为抽象,第一页为 https://news.fzu.edu.cn/yxfd.htm,第二页为 https://news.fzu.edu.cn/yxfd/5.htm 第三页为 https://news.fzu.edu.cn/yxfd/4.htm 依次递减,故在设置存放所有页的 url 时需要特殊设置。

设置完毕后,对每个页面用 requests 抓取 html,并且遍历所有 img 标签,对每个图片,优先取 src,没有就取 data-src,再用 urllib.parse.urljoin 补成绝对 URL,并去掉查询参数后用正则判断是否为目标图片类型,最后用 requests 下载图片二进制写入目录。
代码展示
import os
import re
import requests
from bs4 import BeautifulSoup
import urllib
#需要爬取的列表(该网站第一页为https://news.fzu.edu.cn/yxfd.htm,后几页为https://news.fzu.edu.cn/yxfd/(1~5).htm
pages=[f"https://news.fzu.edu.cn/yxfd/{i}.htm" for i in range(0,6)]
pages.append(f"https://news.fzu.edu.cn/yxfd.htm")
#设置保存目录
if not os.path.exists("imgs"):
os.makedirs("imgs")
#设置搜索的图片后缀
pat=re.compile(r"\.(jpg|jpeg|png)$",re.I)
seen=set()
i=0
for url in pages:
#发请求拿HTML
resp=requests.get(url,headers={"User-Agent":"Mozilla/5.0"})
resp.encoding=resp.apparent_encoding
html=resp.text
#解析页面
soup=BeautifulSoup(html,"html.parser")
imgs=soup.find_all("img")
for img in imgs:
#获取src
src=img.get("src") or img.get("data-src")
img_url=urllib.parse.urljoin(url, src)
#去掉查询参数再判断后缀
img_url_split=img_url.split("?",1)
url_for_check=img_url_split[0]
if not pat.search(url_for_check):
continue
# 去重
if img_url in seen:
continue
seen.add(img_url)
#给文件命名
url_for_check_split=url_for_check.split("/")
name=url_for_check_split[-1]
if not pat.search(name):
name=f"img_{i}.jpg"
#下载图片并保存
r2=requests.get(img_url,headers={"User-Agent":"Mozilla/5.0"})
with open(os.path.join("imgs",name),"wb") as f:
f.write(r2.content)
i+=1
print(f"已下载: {name}")
print("共保存", i, "张图片")
输出结果
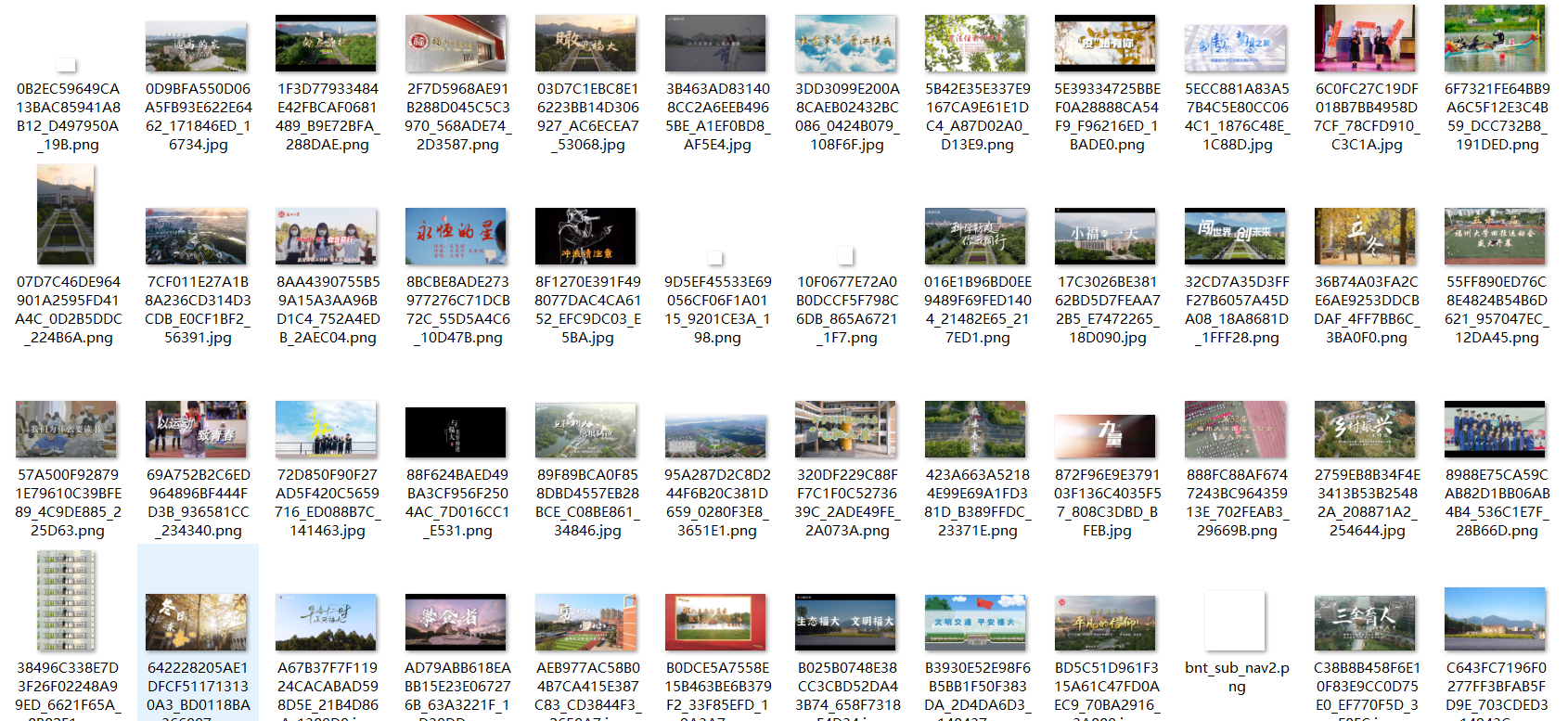
实验心得
这个任务是下载图片,我学会了怎么读取图片链接并且拼接成绝对路径。同时通过这次实验,我掌握了多页网页图片爬取的通用流程,理解了如何应对分页规律不统一、图片属性不一致等问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号