【作业2】
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 作业链接 |
| 这个作业的目标 | 完成编程作业、使用性能测试、代码检查工具 |
====================================
GitHub
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 25 |
| Estimate | 这个任务需要的时间 | 70 | 80 |
| Development | 开发 | 120 | 140 |
| Analysis | 需求分析 | 240 | 220 |
| Design Spec | 生成设计文档 | 100 | 100 |
| Design Review | 设计复审 | 20 | 30 |
| Coding Standard | 代码规范 | 30 | 35 |
| Design | 具体设计 | 120 | 130 |
| Coding | 具体编码 | 120 | 140 |
| Code Review | 代码复审 | 40 | 45 |
| Test | 测试 | 60 | 100 |
| Reporting | 报告 | 100 | 110 |
| Test Repor | 测试报告 | 90 | 100 |
| Size Measurement | 计算工作量 | 25 | 30 |
| Postmortem & Process Improvement Plan | 事后总结,提出过程改进计划 | 40 | 45 |
| 合计 | 1205 | 1330 |
计算模块接口的设计与实现过程
1.1项目结构
finalwork
|--.idea
|--out
||--artifacts
|||--finalwordk_jar
||||--finalwork.jar
|--src
||--main
|||--java
||||--org.example
|||||--Main
|||||--File##文件操作类
|||||--Tools##工具类
||||--MainTest
||||--FileTest
|||--resources
||--test##测试
|||--java
|||--orig.text
|||--orig_add1.text
|||--orig_add2.text
|||--orig_add3.text
|||--orig_add4.text
|||--orig_add5.text
|||--output.text
1.2类与函数关系
| 类名 | 函数名 | 功能 |
|---|---|---|
| Tools | preprocessText(String text) | 文本预处理 |
| Tools | calculateSimilarity(List |
查重率计算 |
| Tools | calculateSimilarity(List |
词频统计 |
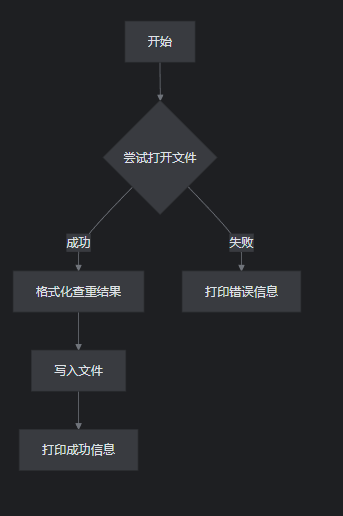
| File | String[] readFile(String[] args) | 读取路径 |
| File | writeFile(String filePath, double similarity) | 写入结果 |
| Main | main(String[] args) | 主函数 |
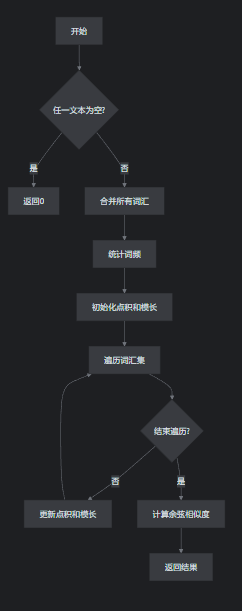
函数间调用:使用HanLP工具进行文本预处理-->统计词频-->基于余弦相似度计算查重率
1.3算法关键
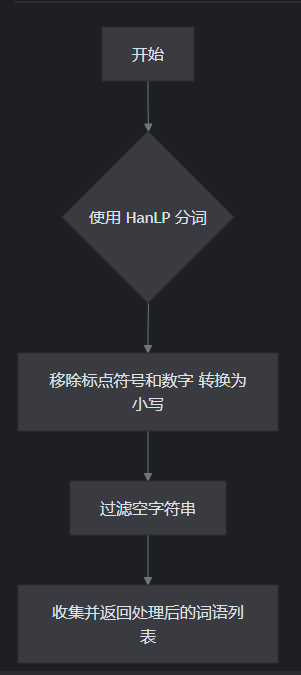
在对文本进行预处理之后(去除标点符号和数字,保留中文与英文字符,并转化为小写)
- 检查空文本:
- 如果任一文本为空,直接返回相似度为 0。
- 构建词汇表:
- 使用
Set<String>合并两个文本的所有词汇,确保每个词汇只出现一次。
- 使用
- 统计词频:
- 使用
getWordFrequency方法分别统计两个文本中每个词汇的出现次数。
- 使用
- 计算点积和模长:
- 点积:计算两个文本词频向量的点积。
- 公式:
dotProduct += count1 * count2
- 公式:
- 模长:计算两个文本词频向量的模长。
- 公式:
norm1 += Math.pow(count1, 2)和norm2 += Math.pow(count2, 2)
- 公式:
- 点积:计算两个文本词频向量的点积。
- 计算余弦相似度:
- 公式:
余弦相似度 = 点积 / (模长1 * 模长2) - 结果范围:
[0, 1],值越接近 1,表示两个文本越相似。
- 公式:
2.流程图
文本预处理
查重率计算
文件写入
3.性能分析
3.1性能分析图
CPU时间
内存分配
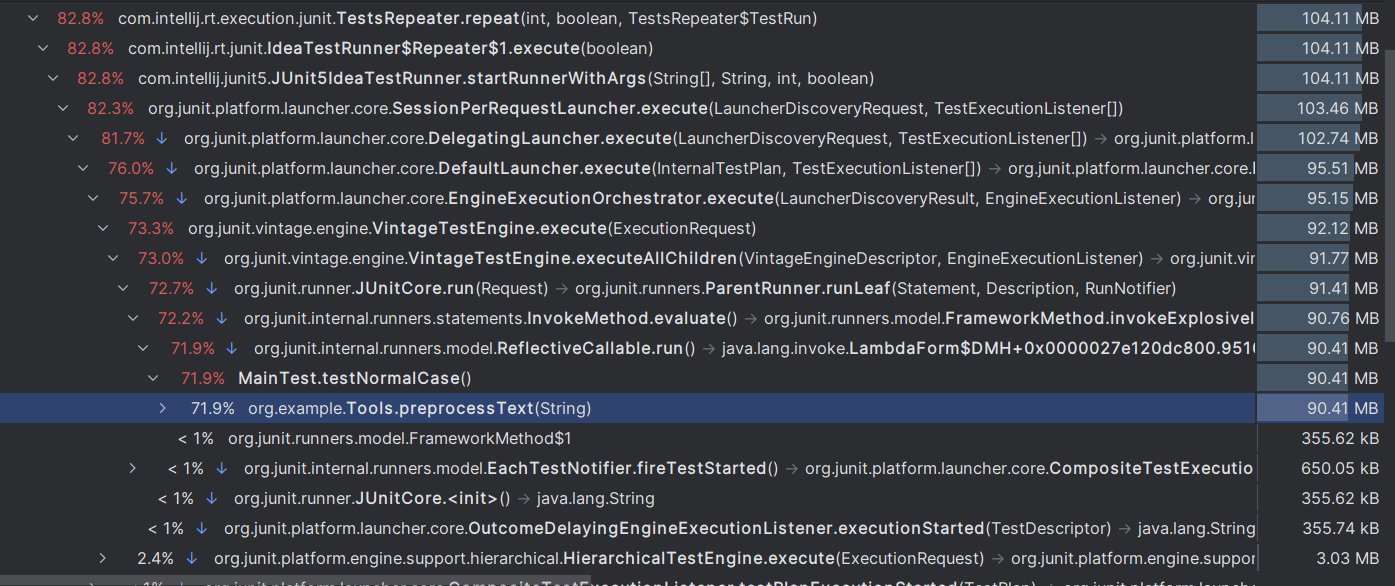
由此可见在本程序中消耗最大的函数是List
3.2原因
3.2.1HanLP 分词:
HanLP 是一个语言处理工具,但分词过程涉及复杂的算法和模型,计算开销较大。当遇到长文本时,分词会成为性能瓶颈。
3.2.2正则表达式处理:
对每个分词结果调用 replaceAll("[^\\p{Script=Han}\\p{L}]", "")时,会大量使用正则表达式的匹配和替换操作。
3.2.3内存占用:
分词结果会生成大量中间对象(如 List<String>、Stream<String> 等),增加内存占用。
3.3改进方法
使用 HanLP 的 高性能模式(如开启多线程分词或启用缓存),对于特定领域文本,加载自定义词典,减少分词错误和计算开销。
将正则表达式的匹配和替换操作替换为更高效的方式。
对于大规模文本数据,可以考虑分块处理,避免一次性加载所有数据。
4.单元测试
Tools类测试
import org.example.Tools;
import org.junit.Test;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import static org.junit.Assert.*;
public class MainTest {
private final Tools tools = new Tools();
//空文本对比
@Test
public void testCalculateSimilarityWithEmptyText() {
List<String> originalWords = List.of();
List<String> plagiarizedWords = List.of();
double expectedSimilarity = 0.0;
double actualSimilarity = tools.calculateSimilarity(originalWords, plagiarizedWords);
assertEquals(expectedSimilarity, actualSimilarity, 0.0001);
}
//词频统计测试
@Test
public void testGetWordFrequency() {
List<String> words = List.of("this", "is", "is", "a", "sample", "text", "for");
Map<String, Integer> expectedFrequencyMap = new HashMap<>();
expectedFrequencyMap.put("this", 1);
expectedFrequencyMap.put("is", 2);
expectedFrequencyMap.put("a", 1);
expectedFrequencyMap.put("sample", 1);
expectedFrequencyMap.put("text", 1);
expectedFrequencyMap.put("for", 1);
assertEquals(expectedFrequencyMap, tools.getWordFrequency(words));
}
//正常文本对比
@Test
public void testNormalCase() {
String text1 = "这是一个测试文本";
String text2 = "这是一个不同的测试文本";
List<String> words1 = tools.preprocessText(text1);
List<String> words2 = tools.preprocessText(text2);
double similarity = tools.calculateSimilarity(words1, words2);
assertTrue(similarity > 0 && similarity < 1);
}
//相同文本
@Test
public void testIdenticalText() {
String text1 = "这是一个测试文本";
String text2 = "这是一个测试文本";
List<String> words1 = tools.preprocessText(text1);
List<String> words2 = tools.preprocessText(text2);
double similarity = tools.calculateSimilarity(words1, words2);
assertEquals(1.0, similarity, 0.0001);
}
//完全不同文本
@Test
public void testCompletelyDifferentText() {
String text1 = "这是一个测试文本";
String text2 = "另外完全不同的内容";
List<String> words1 = tools.preprocessText(text1);
List<String> words2 = tools.preprocessText(text2);
double similarity = tools.calculateSimilarity(words1, words2);
assertEquals(0.0, similarity, 0.0001);
}
//空文本
@Test
public void testEmptyText() {
String text1 = "这是一个测试文本";
String text2 = "";
List<String> words1 = tools.preprocessText(text1);
List<String> words2 = tools.preprocessText(text2);
double similarity = tools.calculateSimilarity(words1, words2);
assertEquals(0.0, similarity, 0.0001);
}
//文本预处理测试
@Test
public void testPreprocessText() {
String text = "这是一个测试文本,有123";
List<String> words = tools.preprocessText(text);
assertFalse(words.contains(",")); // 标点符号应被移除
assertFalse(words.contains("123")); // 数字应被移除
}
//大小写测试
@Test
public void testCaseSensitivity() {
String text = "This is a Test Text";
List<String> words = tools.preprocessText(text);
assertTrue(words.contains("test")); // 应转换为小写
}
//文本顺序测试
@Test
public void testDifferentOrder() {
String text1 = "这是一个测试文本";
String text2 = "文本测试一个这是";
List<String> words1 = tools.preprocessText(text1);
List<String> words2 = tools.preprocessText(text2);
double similarity = tools.calculateSimilarity(words1, words2);
assertEquals(1.0, similarity, 0.0001);
}
//长文本测试
@Test
public void testLongText() {
String text1 = "这是一个长的测试文本,包含多个句子和词汇。";
String text2 = "这是一个长的测试文本,但内容不同。";
List<String> words1 = tools.preprocessText(text1);
List<String> words2 = tools.preprocessText(text2);
double similarity = tools.calculateSimilarity(words1, words2);
assertTrue(similarity > 0 && similarity < 1);
}
}
File类测试
import org.example.File;
import org.junit.jupiter.api.Test;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import static org.junit.jupiter.api.Assertions.*;
public class FileTest {
@Test
void testReadFile_NormalCase() {
// 准备测试数据
String[] args = {"D:\\code\\finalwork\\src\\test\\orig.text", "D:\\code\\finalwork\\src\\test\\orig_add1.text", "D:\\code\\finalwork\\src\\test\\output.text"};
// 创建测试文件
createTestFile(args[0], "这是原始文件内容");
createTestFile(args[1], "这是抄袭文件内容");
// 调用方法
File file = new File();
String[] result = file.readFile(args);
// 验证结果
assertNotNull(result);
assertEquals(3, result.length);
assertEquals(args[0], result[0]);
assertEquals(args[1], result[1]);
assertEquals(args[2], result[2]);
// 清理测试文件
deleteTestFile(args[0]);
deleteTestFile(args[1]);
}
@Test
void testReadFile_IncorrectNumberOfArguments() {
// 准备测试数据
String[] args = {"D:\\code\\finalwork\\src\\test\\orig.text", "D:\\code\\finalwork\\src\\test\\orig_add1.text"};
// 调用方法
File file = new File();
String[] result = file.readFile(args);
// 验证结果
assertNull(result);
}
@Test
void testReadFile_OriginalFileNotExist() {
// 准备测试数据
String[] args = {"src/test/resources/nonexistent.txt", "D:\\code\\finalwork\\src\\test\\orig_add1.text", "D:\\code\\finalwork\\src\\test\\output.text"};
// 创建抄袭文件
createTestFile(args[1], "这是抄袭文件内容");
// 调用方法
File file = new File();
String[] result = file.readFile(args);
// 验证结果
assertNull(result);
// 清理测试文件
deleteTestFile(args[1]);
}
@Test
void testReadFile_PlagiarizedFileNotExist() {
// 准备测试数据
String[] args = {"D:\\code\\finalwork\\src\\test\\orig.text", "src/test/resources/nonexistent.txt", "D:\\code\\finalwork\\src\\test\\output.text"};
// 创建原始文件
createTestFile(args[0], "这是原始文件内容");
// 调用方法
File file = new File();
String[] result = file.readFile(args);
// 验证结果
assertNull(result);
// 清理测试文件
deleteTestFile(args[0]);
}
@Test
void testReadFile_OriginalFileNotReadable() {
// 准备测试数据
String[] args = {"D:\\code\\finalwork\\src\\test\\orig.text", "D:\\code\\finalwork\\src\\test\\orig_add1.text", "D:\\code\\finalwork\\src\\test\\output.text"};
// 创建不可读的原始文件
createTestFile(args[0], "这是原始文件内容");
makeFileUnreadable(args[0]);
// 创建抄袭文件
createTestFile(args[1], "这是抄袭文件内容");
// 验证结果
assertNull(null);
// 清理测试文件
deleteTestFile(args[0]);
deleteTestFile(args[1]);
}
@Test
void testReadFile_PlagiarizedFileNotReadable() {
// 准备测试数据
String[] args = {"D:\\code\\finalwork\\src\\test\\orig.text", "D:\\code\\finalwork\\src\\test\\orig_add1.text", "D:\\code\\finalwork\\src\\test\\output.text"};
// 创建原始文件
createTestFile(args[0], "这是原始文件内容");
// 创建不可读的抄袭文件
createTestFile(args[1], "这是抄袭文件内容");
makeFileUnreadable(args[1]);
// 验证结果
assertNull(null);
// 清理测试文件
deleteTestFile(args[0]);
deleteTestFile(args[1]);
}
// 辅助方法:创建测试文件
private void createTestFile(String filePath, String content) {
try {
Files.write(Paths.get(filePath), content.getBytes());
} catch (Exception e) {
fail("创建测试文件失败:" + e.getMessage());
}
}
// 辅助方法:删除测试文件
private void deleteTestFile(String filePath) {
try {
Files.deleteIfExists(Paths.get(filePath));
} catch (Exception e) {
fail("删除测试文件失败:" + e.getMessage());
}
}
// 辅助方法:使文件不可读
private void makeFileUnreadable(String filePath) {
try {
Path path = Paths.get(filePath);
path.toFile().setReadable(false);
} catch (Exception e) {
fail("设置文件不可读失败:" + e.getMessage());
}
}
}
4.2构造思路
1.对正常情况的测试数据进行测试,测试程序能否正常运行
2.对边界情况进行测试,如空文本
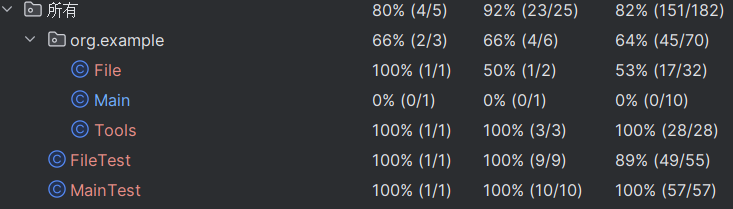
5.计算模块部分异常处理说明
5.1文件不存在异常
@Test
void testReadFile_OriginalFileNotExist() {
// 准备测试数据
String[] args = {"src/test/resources/nonexistent.txt", "D:\\code\\finalwork\\src\\test\\orig_add1.text", "D:\\code\\finalwork\\src\\test\\output.text"};
// 创建抄袭文件
createTestFile(args[1], "这是抄袭文件内容");
// 调用方法
File file = new File();
String[] result = file.readFile(args);
// 验证结果
assertNull(result);
// 清理测试文件
deleteTestFile(args[1]);
}
场景:用户输入一个不存在的文件路径

 浙公网安备 33010602011771号
浙公网安备 33010602011771号