

补交02 03 04 05 06 07 08
02 环境搭建
1、安装Linux操作系统
2、安装关系型数据库MySQL
3、安装大数据处理框架Hadoop,查看IP



03 Linux与Hadoop操作实验
cd命令:切换目录
切换到目录 /usr/local

去到目前的上层目录

回到自己的主文件夹

ls命令:查看文件与目录
查看目录/usr下所有的文件

mkdir命令:新建新目录
进入/tmp目录,创建一个名为a的目录,并查看有多少目录存在
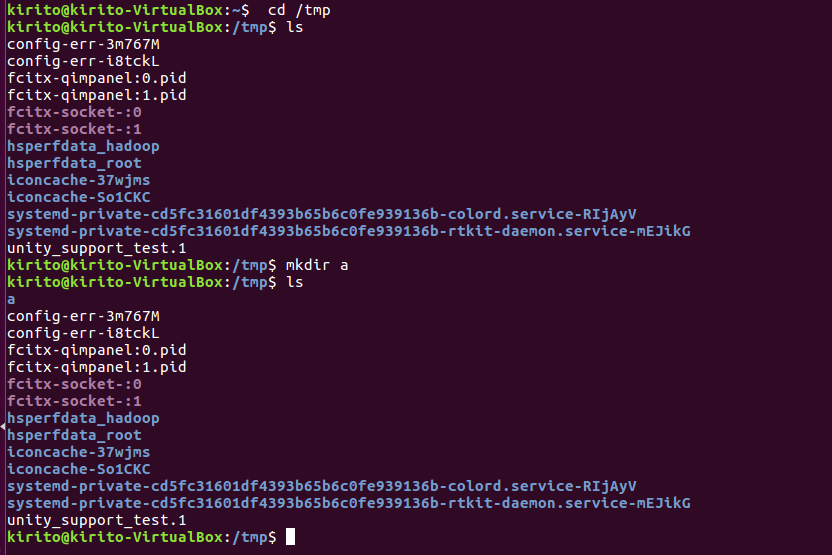
创建目录a1/a2/a3/a4

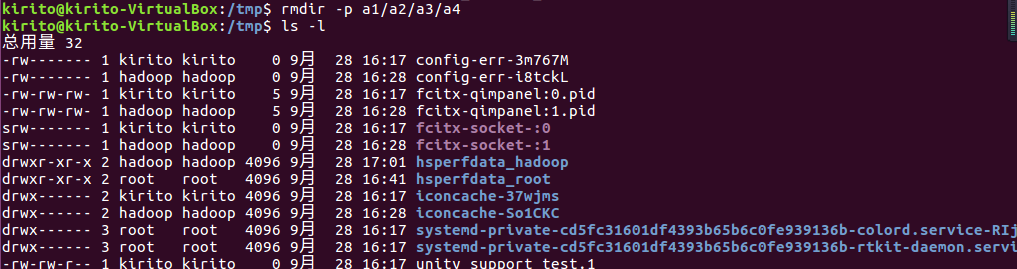
rmdir命令:删除空的目录
将上例创建的目录a(/tmp下面)删除
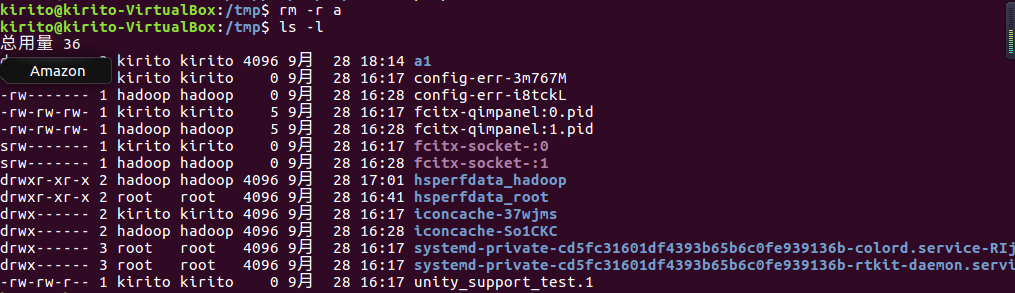
删除目录a1/a2/a3/a4,查看有多少目录存在
cp命令:复制文件或目录
将主文件夹下的.bashrc复制到/usr下,命名为bashr
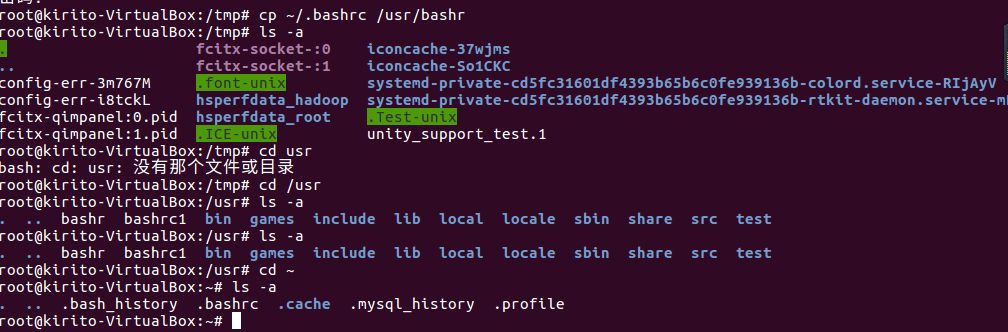
在/tmp下新建目录test,再复制这个目录内容到/usr
cd

mv命令:移动文件与目录,或更名
将上例文件bashrc1移动到目录/usr/test
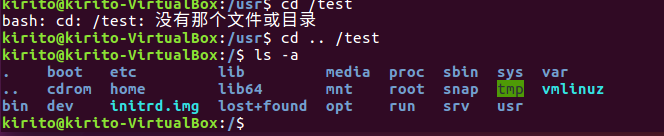
将上例test目录重命名为test2

rm命令:移除文件或目录
将上例复制的bashrc1文件删除

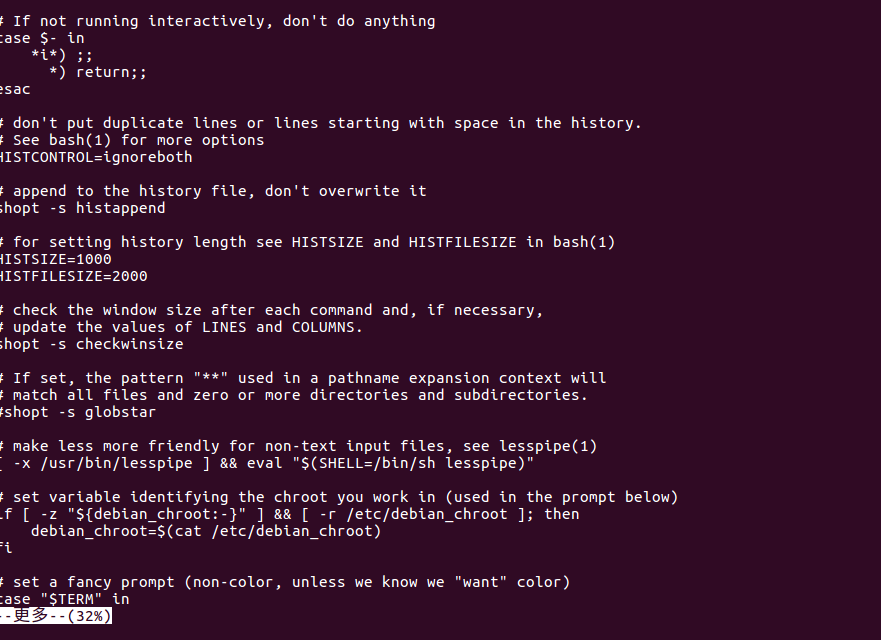
cat命令:查看文件内容
查看主文件夹下的.bashrc文件内容

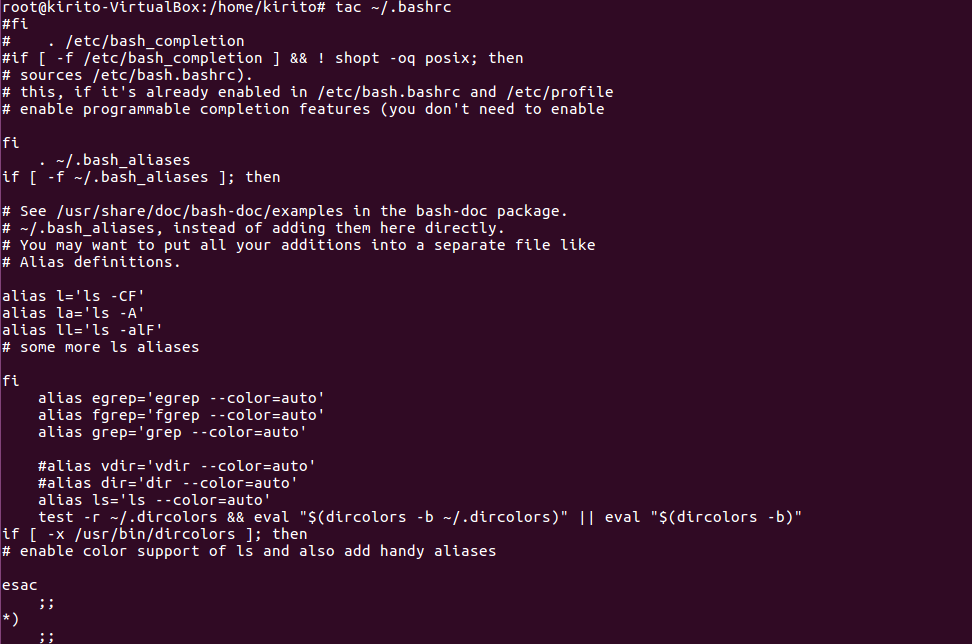
tac命令:反向列示
(16)反向查看主文件夹下.bashrc文件内容
more命令:一页一页翻动查看
(17)翻页查看主文件夹下.bashrc文件内容
head命令:取出前面几行
(18)查看主文件夹下.bashrc文件内容前20行
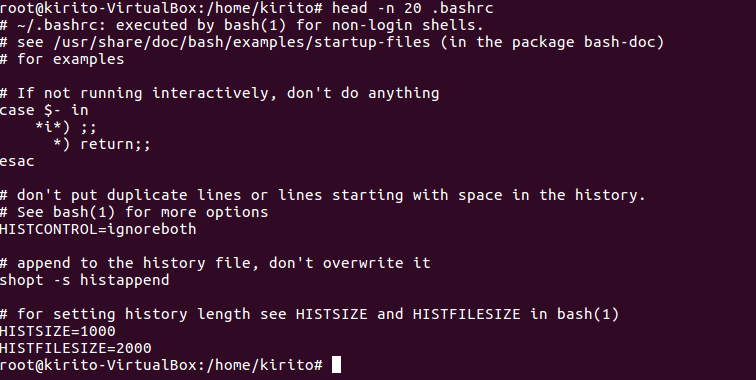
(19)查看主文件夹下.bashrc文件内容,后面50行不显示,只显示前面几行

04 Hadoop思想与原理
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。Hadoop起源于Apache Nutch项目,始于2002年,是Apache Lucene的子项目之一 。2004年,Google在“操作系统设计与实现”(Operating System Design and Implementation,OSDI)会议上公开发表了题为MapReduce:Simplified Data Processing on Large Clusters(Mapreduce:简化大规模集群上的数据处理)的论文之后,受到启发的Doug Cutting等人开始尝试实现MapReduce计算框架,并将它与NDFS(Nutch Distributed File System)结合,用以支持Nutch引擎的主要算法 [ 。由于NDFS和MapReduce在Nutch引擎中有着良好的应用,所以它们于2006年2月被分离出来,成为一套完整而独立的软件,并被命名为Hadoop。到了2008年年初,hadoop已成为Apache的顶级项目,包含众多子项目,被应用到包括Yahoo在内的很多互联网公司。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
Google与Hadoop的关系:
第一篇论文:GFS
2003年谷歌发表了 “The Google File System(谷歌文件系统,简称GFS)”的论文,GFS的架构能够满足在网页爬取和索引过程中产生的超大文件的存储需求。于是,在2004年Nutch团队开始做GFS的开源版本实现,也就 是Nutch分布式文件系统(NDFS)。
第二篇论文:MapReduce
2004年谷歌发表了“MapReduce:Simplified Data Processing on Large Cluster(大型集群的数据简化处理)”的论文。2005年,Nutch团队在Nutch上实现了MapReduce。
2006年2月,Nutch开发人员将NDFS和MapReduce移除Nutch形成一个独立的项目,命名为Hadoop。这个名字不是缩写,是生造出来的。
第三篇:BigTable
2006年谷歌发表了“BigTable:A Distributed Storage System for Structured Data(一个结构化数据的分布式存储系统)”的论文。Powerset公司根据BigTable的思想,发起了HBase,即Hadoop Database。
2008年1月,Hadoop成为Apache的顶级项目。背后主要的公司为雅虎,主要用Hadoop来支撑雅虎的搜索引擎系统。
2013年 Hadoop 2.0发布
2017年 Hadoop 3.0 发布
在Hadoop1.x时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大。
在Hadoop2.x时代,增加了Yarn。Yarn只负责资源的调度,MapReduce只负责运算。
Hadoop3.x在组成上没有变化。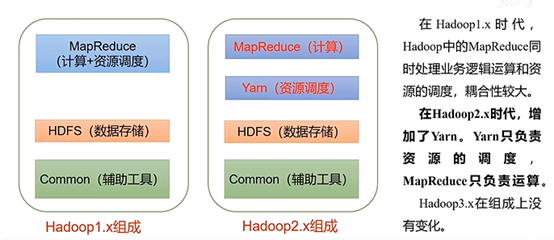
(1)Hadoop 1.0
Hadoop 1.0即第一代Hadoop,由分布式存储系统HDFS和分布式计算框架MapReduce组成,其中,HDFS由一个NameNode和多个DataNode组成,MapReduce由一个JobTracker和多个TaskTracker组成。
Hadoop1.X对应Hadoop版本为Apache Hadoop 0.20.x、1.x、0.21.X、0.22.x和CDH3。
hadoop1.0需要解决的几个问题:
1:单点故障问题,HDFS和MapReduce都是Master-Slave的结构,但是Master节点都是单点,一旦出现故障,那么集群就不能正常运行。
2:HDFS存储海量数据是按照Block来存储的,整个存储只有一种格式,企业存储受限,企业的数据非常多样,存储起来容易造成资源的浪费。
当namenode所在机器的内存不够时,集群不能正常工作。
3:MapReduce进行离线的批处理,处理速度慢,以Map和Reduce进程的方式来运行,一般是晚间来进行计算,MapReduce集群资源利用率低。
(2)Hadoop 2.0
Hadoop 2.0即第二代Hadoop,为克服Hadoop 1.0中HDFS和MapReduce存在的各种问题而提出的。针对Hadoop 1.0中的单NameNode制约HDFS的扩展性问题,提出了HDFS Federation,它让多个NameNode分管不同的目录进而实现访问隔离和横向扩展,同时它彻底解决了NameNode 单点故障问题;针对Hadoop 1.0中的MapReduce在扩展性和多框架支持等方面的不足,它将JobTracker中的资源管理和作业控制功能分开,分别由组件ResourceManager和ApplicationMaster实现。其中,ResourceManager负责所有应用程序的资源分配,而ApplicationMaster仅负责管理一个应用程序,进而诞生了全新的通用资源管理框架YARN。基于YARN,用户可以运行各种类型的应用程序(不再像1.0那样仅局限于MapReduce一类应用),从离线计算的MapReduce到在线计算(流式处理)的Storm等。
Hadoop 2.0对应Hadoop版本为Apache Hadoop 0.23.x、2.x和CDH4。
1. Hadoop 3.0简介
Hadoop 2.0是基于JDK 1.7开发的,而JDK 1.7在2015年4月已停止更新,这直接迫使Hadoop社区基于JDK 1.8重新发布一个新的Hadoop版本,而这正是hadoop 3.0。
Hadoop 3.0的alpha版已经在今年夏天发布,预计GA版本11月或12月发布。
Hadoop 3.0中引入了一些重要的功能和优化,包括HDFS 可擦除编码、多Namenode支持、MR Native Task优化、YARN基于cgroup的内存和磁盘IO隔离、YARN container resizing等。
2. Hadoop 3.0新特性
Apache hadoop 项目组最新消息,hadoop3.x以后将会调整方案架构,将Mapreduce 基于内存+io+磁盘,共同处理数据。
其实最大改变的是hdfs,hdfs 通过最近black块计算,根据最近计算原则,本地black块,加入到内存,先计算,通过IO,共享内存计算区域,最后快速形成计算结果。
Hadoop 3.0在功能和性能方面,对hadoop内核进行了多项重大改进,主要包括:
2.1 Hadoop Common
(1)精简Hadoop内核,包括剔除过期的API和实现,将默认组件实现替换成最高效的实现(比如将FileOutputCommitter缺省实现换为v2版本,废除hftp转由webhdfs替代,移除Hadoop子实现序列化库org.apache.hadoop.Records。
(2)Classpath isolation以防止不同版本jar包冲突,比如google Guava在混合使用Hadoop、HBase和Spark时,很容易产生冲突。(3)Shell脚本重构。 Hadoop 3.0对Hadoop的管理脚本进行了重构,修复了大量bug,增加了新特性,支持动态命令等。
2.2 Hadoop HDFS
(1)HDFS支持数据的擦除编码,这使得HDFS在不降低可靠性的前提下,节省一半存储空间。 (2)多NameNode支持,即支持一个集群中,一个active、多个standby namenode部署方式。注:多ResourceManager特性在hadoop 2.0中已经支持。
2.3 Hadoop MapReduce
(1)Tasknative优化。为MapReduce增加了C/C++的map output collector实现(包括Spill,Sort和IFile等),通过作业级别参数调整就可切换到该实现上。对于shuffle密集型应用,其性能可提高约30%。 (2)MapReduce内存参数自动推断。在Hadoop 2.0中,为MapReduce作业设置内存参数非常繁琐,涉及到两个参数:mapreduce.{map,reduce}.memory.mb和mapreduce.{map,reduce}.java.opts,一旦设置不合理,则会使得内存资源浪费严重,比如将前者设置为4096MB,但后者却是“-Xmx2g”,则剩余2g实际上无法让java heap使用到。
2.4 Hadoop YARN
(1)基于cgroup的内存隔离和IO Disk隔离(2)用curator实现RM leader选举
(3)containerresizing(4)Timelineserver next generation
3. Hadoop3.0 总结
Hadoop 3.0的alpha版已经在今年夏天发布,预计GA版本11月或12月发布。Hadoop 3.0中引入了一些重要的功能和优化,包括HDFS 可擦除编码、Namenode支持、MR Native Task优化、YARN基于cgroup的内存和磁盘IO隔离、YARN container resizing等。
05 HDFS Java API应用实例
一、在Ubuntu系统中安装和配置Eclipse
二、利用hadoop 的java api,向HDFS写一个文件。写入内容含自己的姓名学号信息。

三、从HDFS读取一个文件的内容并显示。

06 HBase 安装与伪分布式配置
启动HDFS,启动Hbase
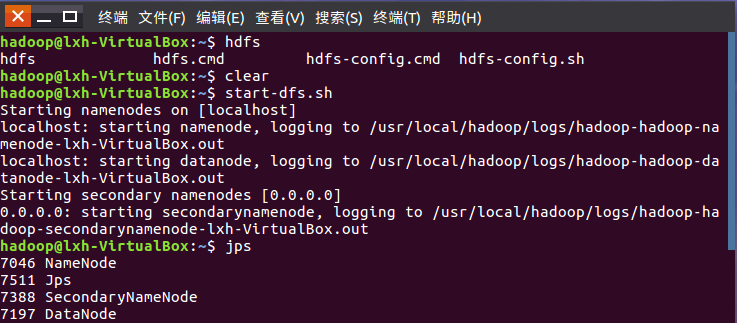
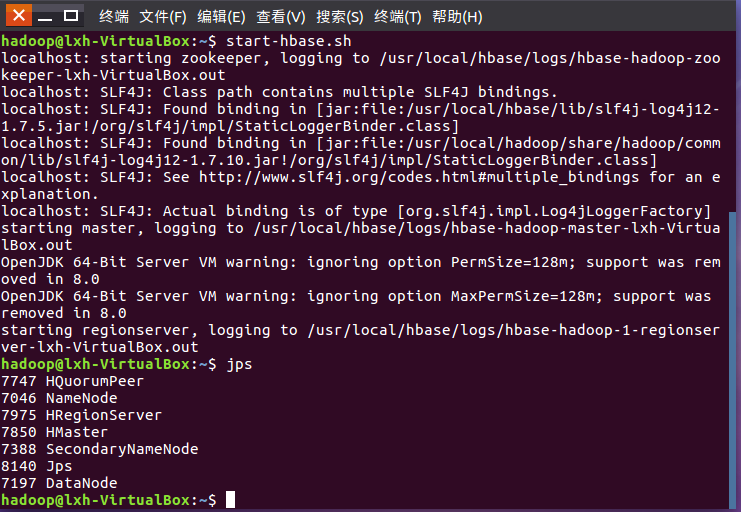
进入shell界面
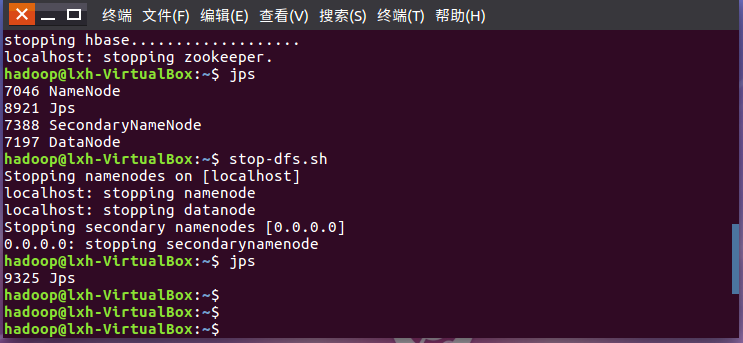
停止Hbase,停止HDFS运行
07 HBase操作
1.理解HBase表模型及四维坐标:行键、列族、列限定符和时间戳
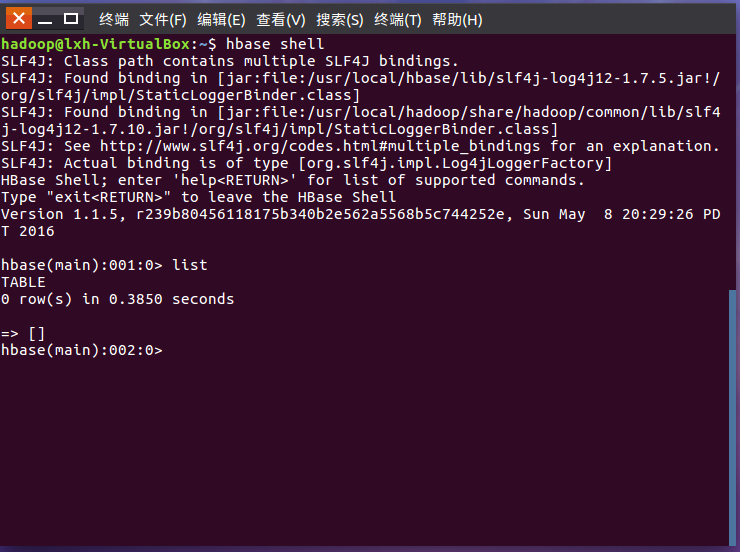
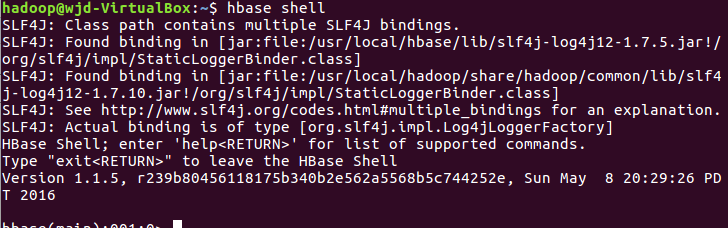
2.启动HDFS,启动HBase,进入HBaseShell命令行
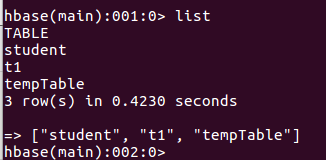
3.列出HBase中所有的表信息list
4.创建表create
5.查看表详情desc
6.插入数据put
7.查看表数据scan




08 分布式计算MapReduce--词频统计
WordCount程序任务:
|
程序 |
WordCount |
|
输入 |
一个包含大量单词的文本文件 |
|
输出 |
文件中每个单词及其出现次数(频数), 并按照单词字母顺序排序, 每个单词和其频数占一行,单词和频数之间有间隔 |
1.用你最熟悉的编程环境,编写非分布式的词频统计程序。
- 读文件
- 分词(text.split列表)
- 按单词统计(字典,key单词,value次数)
- 排序(list.sort列表)
- 输出
![]()
![]()
![]()
在Ubuntu中实现运行。
- 准备txt文件
- 编写py文件
- python3运行py文件分析txt文件。
![]()
2.用MapReduce实现词频统计
-
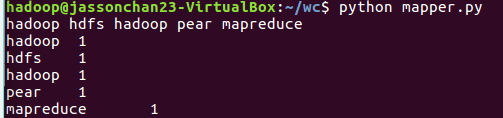
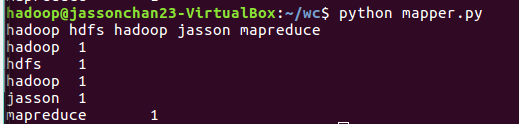
2.1编写Map函数
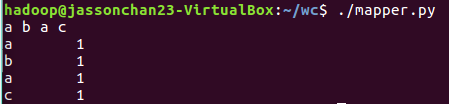
- 编写mapper.py
- 授予可运行权限
- 本地测试mapper.py
![]()
![]()
![]()
![]()
-
2.2编写Reduce函数
- 编写reducer.py
- 授予可运行权限
- 本地测试reducer.py
![]()
![]()
![]()
![]()
![]()
![]()












 浙公网安备 33010602011771号
浙公网安备 33010602011771号