

sft微调
o小数据集(<10k样本):3-10个epoch
o中等数据集(10k-100k样本):2-5个epoch
o大数据集(>100k样本):1-3个epoch
加验证集(val_size=0.1)实时监测
3.如何评估结果?
①缺乏验证集
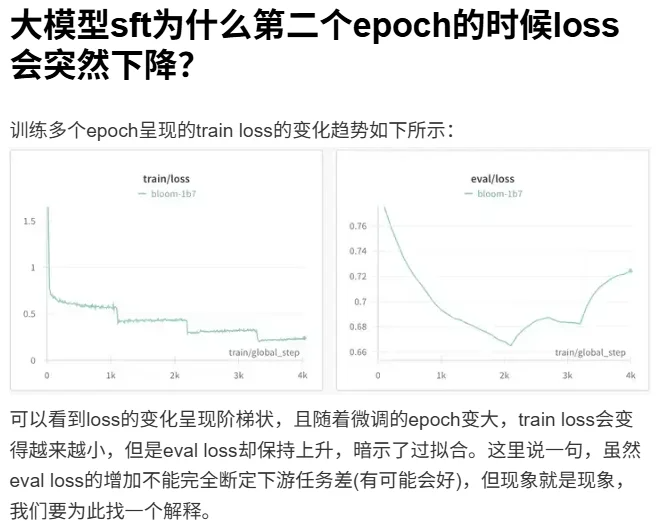
本次前期整体微调中缺乏验证集,无法生成验证集评估。这意味着:
无法判断模型是否过拟合
·不知道模型在未见数据上的泛化能力
·训练效果缺乏客观评估基准
②Loss
整体的LOSS都比较高,但第一次训练改变认知的结果从chat的表现来看已经达到了预期效果。
为啥???
为什么Ioss过高,但通过chat的表现发现训练出来的模型自我认知已经修改,达到了预期效果?
DeepSeek总结:Loss高说明模型为改变原有认知付出了代价,学习过程不轻松;而聊天表现好证明这种改变在行
为层面已经成功。两者的不一致恰好说明了微调的有效性和损失函数作为代理目标的局限性。
这一点目前还存疑,有待专业知识学完后再来解答。
Epoch:
·数据少→减少epoch,防止过拟合
·数据多→可以增加epoch,但通常不需要太多
标准范围:
。小数据集(<10k样本):3-10个epoch
中等数据集(10k-100k样本):2-5个epoch
。大数据集(>100k样本):1-3个epoch
Learning Rate
从小学习率开始训练调整
基于模型大小调整:
三。7B/13B模型:1e-4到5e-4
o30B+模型:5e-5到2e-4
o小参数模型(<1B):5e-4到1e-3
基于任务复杂度:
。简单适配(风格迁移):较高学习率(3e-4八5e-4)
。复杂推理任务:较低学习率(1e-4八3e-4)
、
兰斯田·士奎当灰(。4.4。A)
显存需求分解(Memory Breakdown)
显存不仅仅用于存储模型权重,在训练过程中,优化器状态和梯度占据了绝大部分空
间。对于P参数量的模型,混合精度训练(Mixed Precision)的静态显存消耗通常
遵循以下经验公式:
Mtotal≈P.(4 bytes
weights 4 bytes
gradients
12 bytes optimizer )Mactivation
具体到7B模型(P=7×10°),基础显存需求如下:
模型权重(Weights):约14GB(FP16)
梯度(Gradients):约14GB(FP16)
优化器状态(Optimizer States):约84GB(AdamW:需维护FP32权重副本、动量和方差)
仅静态内容就需约
112GB
显存,这已经超过了单张NVIDIA A100(80GB)的物理上
限。因此,必须使用
DeepSpeed ZeRO等技术进行显存分片。
全量微调答案更相似,为啥还说全量更容易灾难遗忘啊?
SeanLau
会影响其他领域回答精度
回复 SeanLau : 好奇一下,其他领域不是不关注吗?那疑问了是不是也没所谓?还是说存在其他风险呢?
回复 step-by-step : 看你想怎么用模型吧,有的时候完全不需要其他领域的能力就可以不关心灾难性遗忘
💡显存开销 = 固定开销 + 动态开销
1️⃣ 固定开销(必占!)
- 模型参数:2N(N=参数量,FP16占2字节)
- 优化器状态:4N(AdamW存2个动量值)
👉 合计:6N(7B模型→ 42GB)
2️⃣ 动态开销(二选一最大值)
- 方案A:梯度+优化器中间态 → 4N(7B→28GB)
- 方案B:激活值 → (4.6894×10⁻⁴×N + 1.8494×10⁶)×B×L×2
- 显存杀手:B(batch size)和L(序列长度)越大越炸!
📊实战计算示例(7B模型)
- 设定:batch_size=1,sequence_length=2048
- 动态显存:max(28GB, ~20GB)=28GB
- 总计:42+28=70GB
- 血泪警告:实际需预留30%余量!→ 至少100GB显存!💥
✅省显存技巧
1. 激活值压缩:用梯度检查点(Gradient Checkpointing)
2. 优化器换血:尝试Adafactor等低内存优化器
3. 序列长度:按数据分布裁剪(如95%样本≤1800→设2048)
4. 混合精度训练:FP16+动态缩放救大命!
resource 充足的话,7b+qlora<<7b+lora=7b fullpara<32b+qlora<<32b+lora<=32b fullpara,仅供参考
首先咱们得明确一点,SFT阶段引入幻觉的根本原因是什么?
其实核心就两个字:数据。很多团队在做监督微调时,急着上量,结果数据质量参差不齐,模型学到的不是
准确的知识映射,而是一堆似是而非的pattern。你想啊,如果训练数据本身就包含事实性错误、逻辑矛
盾,或者答案跟问题压根对不上,模型能学好才怪。
所以第一个关键点就是数据质量管控。首先是数据清洗这一步,你得建立一套严格的审核机制。比如对
于事实类问题,答案必须有可验证的来源;对于推理类任务,逻辑链条要完整;对于生成类任务,内容不能自
相矛盾。很多公司会引入多轮人工审核,甚至用模型来做第一轮筛选,把明显有问题的数据先过滤掉。
然后是数据多样性的问题。这个特别容易被忽视。如果你的训练数据都集中在某几个领域,或者某种特
定的问答格式,模型在遇到新场景时就容易瞎编。所以我们要刻意构造多样化的场景,包括不同领域、不
同难度、不同问答风格的样本。有些团队还会专门加入一些"我不知道"类型的样本,让模型学会在不确
定时承认无知,而不是硬凑答案。
在大语言模型(LLM)场景中,知识
蒸馏已不再局限于logits对齐,而是扩展
为对中间表示、推理过程(Chain-of-Th
ought)以及偏好与策略(RLHF/RLAIF)的整体迁移。
alpha过大:alpha控制着LoRA适配器对原模
型输出的影响权重。如果alpha设置得远超常规
(比如r=8,alpha=128),相当于在模型的输出
层强行施加一个巨大的偏置,这种“硬植入”的
方式极易破坏原有的语义空间。
对于训练数据量来说过高了。对于LoRA,我会
计算“可训练参数数量/训练样本数”这个比
值。如果这个比值过高(例如用了=64,却只有
1000条数据),就给了模型过强的记忆能力而非
泛化能力。
建立控体系:我会使用Weights&Biases:或
TensorBoard来可视化训练过程。我不仅会监控
oSS,还会监控:学习率(确认调度器是否按预
期工作)、梯度范数(观察梯度是否稳定)、参
数分布(观察LoRA权重的分布变化,判断模型
是否在正常学习)。
大batchsize计算会快一些,但是结果往往不如小batchsize 小的会过拟合 看起来更好 大的才是过拟合,太准了,小的是随机性最强
个人理解batch_size小的时候随机性大,有利于跳出尖锐的谷区,但是模型收敛较慢并且容易炸掉;大batch_size会使每一个batch的分布更接近实际的全局分布,模型收敛更快更稳定,但是有时候会找到尖锐的谷区。。
尖锐的local minimum的坏处是,往往最终的参数在训练样本中表现出极低的loss,在现实中却会因为取样时微小的样本分布平移而导致真实loss在周围的高原上。因此宽大平坦的minimum往往是训练所要追求的目标
大模型微调,训练多少epoch才合适?
忘掉固定的epoch数
大模型微调跟传统深度学习完全不一样。大模型已经在海量数据上预训练过了,微调只是让它适应你的特定任务。我的经验是,大模型微调通常只需要1到5个epoch。数据量大的话1到2个epoch就够了,数据量小的话可能需要3到5个。如果你训练超过10个epoch,那八成是哪里出问题了。
具体多少epoch合适,取决于你的数据规模。我之前做过一个项目,数据集有5万条,训练1个epoch效果就很不错。另一个项目只有2千条数据,训练了3个epoch才达到满意的效果。
看验证集loss是王道
判断训练够了没有,最直接的方法就是看验证集的loss。我的做法是每个epoch结束或者每隔几百步就在验证集上跑一次,记录下loss值。如果验证集loss不再下降甚至开始上升,那就说明模型开始过拟合了,该停了。
我现在做微调都会用early stopping策略。设置一个patience参数,比如3或者5,意思是如果验证集loss连续3次或5次没有改善,就自动停止训练。HuggingFace的Trainer已经内置了这个功能,直接用就行。
数据质量比epoch数重要
很多同学纠结epoch数,其实真正影响微调效果的是数据质量。我见过有人用几千条垃圾数据训练10个epoch,效果还不如用几百条高质量数据训练2个epoch。
我的建议是微调之前先花时间清洗数据,把低质量的样本剔除掉,把格式统一好。还有就是数据的多样性,如果你的任务是问答系统,数据集里要覆盖各种类型的问题,不能都是同一种模式。
学习率要匹配epoch数
Epoch数和学习率是配套的。如果你只训练1到2个epoch,学习率要设置得高一点,比如5e-5到1e-4。如果训练3到5个epoch,学习率就要降下来,2e-5到5e-5比较合适。
还有个技巧是用warmup。我一般会设置warmup steps为总训练steps的10%,让学习率从0慢慢升到目标值,然后再线性衰减,训练曲线会很平滑。
不同任务不同策略
做指令微调和做特定任务微调,epoch数的选择也不一样。指令微调数据量通常比较大,1到2个epoch就够。特定任务微调数据量相对小一些,可能需要3到5个epoch。
用LoRA这种参数高效微调方法,可以适当多训几轮。因为LoRA只训练一小部分参数,相比全量微调更不容易过拟合。我用LoRA微调的时候通常会训练3到5个epoch。
#深度学习#算法改进#发文#跑通#复现#一对一指导#大模型#调参#python#强化学习
大模型微调,训练多少epoch才合适?
数据量决定基础轮数
数据量10万条左右,一般2到3个epoch就够了,2到5万条数据建议4到5个epoch。数据量特别少的情况,比如几百条数据,可以适当增大epoch让模型充分收敛 。
我去年带师弟做垂直领域微调,他只有800条高质量对话数据,一开始只跑了3个epoch,模型根本没学明白。后来调到10个epoch配合早停策略,效果才起来。epoch过小容易欠拟合,epoch过大容易过拟合,推荐设置2到10个epoch。
用早停策略自动刹车
早停法的核心思想是监控验证集上的性能,一旦发现验证集损失不再下降甚至开始上升时就停止训练。你可以把总epoch设大一点比如20轮,然后设置patience参数。
patience参数表示验证集损失在若干个epoch内没有改进时才停止训练。我一般设置patience为3到5。比如你设patience为3,那验证集loss连续3个epoch都没降,训练就自动停了。这样既不用担心训练不够,也不怕过拟合。
观察loss曲线
训练过程中一定要用TensorBoard画loss曲线。观察验证集准确率变化,当它不再提高时就可以终止训练。
还有个技巧是看训练集和验证集loss的差距。如果训练集loss已经很低比如0.1,但验证集还在1.5,说明模型记住训练数据了但泛化不行,这时候继续加epoch只会让过拟合更严重。
不同微调方法要调整
使用LoRA的peft训练方式时可以适当增大学习率,相应的epoch也可以调整。较小的学习率一般需要更多的epochs。我用LoRA微调Qwen模型的时候,学习率设5e-4,跑5个epoch就够了。但全参数微调的话,学习率降到1e-5,可能需要跑8到10个epoch。
强化学习训练时间太长,模型可能利用奖励模型的漏洞生成奇怪的输出。所以RLHF阶段epoch不要设太多,一般1到3个epoch配合动态奖励就行。
比较实用的配置方案
小数据集500条以下:epoch设10到15,patience设5,学习率5e-5
中等数据集5000到50000条:epoch设5到8,patience设3,学习率1e-4
大数据集10万条以上:epoch设2到3,patience设2,学习率5e-5
小数据量场景选择LoRA或QLoRA有助于防止过拟合。把数据质量搞好,配合早停和验证集监控,大部分情况下3到5个epoch就能训出不错的模型。
#深度学习 #复现 #大模型 #算法改进#创新点#python#一对一指导#模型优化#调参#发文
PART 04
多机多卡要“变快”,前提条件是什么?
在工程实践中,有一个非常明确的结论:多机多卡
并不会自动带来线性加速。
真正能看到明显加速的场景,通常具备几个特征:
单step计算时间足够长
7/10
通信时间在总时间中占比可控
算力规模的增长,与训练负载是“匹配”的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号