
bp神经网络
output_nodes = 10 #输出层神经元个数
learning_rate = 0.3 #学习率为0.3
# 创建神经网络
n = NeuralNetwork(input_nodes, hidden_nodes, output_nodes, learning_rate)
#%%
#读取训练数据集 转化为列表
training_data_file = open(r"E:\1大二下课程\人工智能课程\代码和数据\第四章代码和数据\mnist_train.csv",'r')
training_data_list = training_data_file.readlines() #方法用于读取所有行,并返回列表
#print("training_data_list:",training_data_list)
training_data_file.close()
#%%
#训练次数
i = 2
for e in range(i):
#训练神经网络
for record in training_data_list:
all_values = record.split(',') #根据逗号,将文本数据进行拆分
#将文本字符串转化为实数,并创建这些数字的数组。
inputs = (np.asfarray(all_values[1:])/255.0 * 0.99) + 0.01
#创建用零填充的数组,数组的长度为output_nodes,加0.01解决了0输入造成的问题
targets = np.zeros(output_nodes) + 0.01 #10个元素都为0.01的数组
#使用目标标签,将正确元素设置为0.99
targets[int(all_values[0])] = 0.99#all_values[0]=='8'
n.train(inputs,targets)
pass
pass
#%%
test_data_file = open(r"E:\1大二下课程\人工智能课程\代码和数据\第四章代码和数据\mnist_test.csv",'r')
test_data_list = test_data_file.readlines()
test_data_file.close()
all_values = test_data_list[2].split(',') #第3条数据,首元素为1
# print(all_values)
# print(len(all_values))
# print(all_values[0]) #输出目标值
#%%
score = []
print("***************Test start!**********************")
for record in test_data_list:
#用逗号分割将数据进行拆分
all_values = record.split(',')
#正确的答案是第一个值
correct_values = int(all_values[0])
# print(correct_values,"是正确的期望值")
#做输入
inputs = (np.asfarray(all_values[1:])/255.0 * 0.99) + 0.01
#测试网络 作输入
outputs= n.query(inputs)#10行一列的矩阵
#找出输出的最大值的索引
label = np.argmax(outputs)
# print(label,"是网络的输出值\n")
#如果期望值和网络的输出值正确 则往score 数组里面加1 否则添加0
if(label == correct_values):
score.append(1)
else:
score.append(0)
pass
pass
print(outputs)
#%%
# print(score)
score_array = np.asfarray(score)
#%%
print("正确率是:",(score_array.sum()/score_array.size)*100,'%')
截图:
![]()
''
模型训练
'''
for j in range(1000):
error = []
for it in range(n): #训练集有n条记录
net_in = np.array([data_tr.iloc[it, 0], data_tr.iloc[it, 1], -1]) # 网络输入
real = data_tr.iloc[it, 2] #第it行第2列的值,也就是此记录的真实值
for i in range(4):
out_in[i] = sigmoid(sum(net_in * w_mid[:, i])) # 从输入到隐层的传输过程
res = sigmoid(sum(out_in * w_out)) # 预测值
error.append(abs(real-res))#第一条记录的误差
# print(it, '个样本的模型输出:', res, 'real:', real)
delta_w_out = yita*res*(1-res)*(real-res)*out_in # 输出层权值的修正量
delta_w_out[4] = -yita*res*(1-res)*(real-res) # 输出层阈值的修正量
w_out = w_out + delta_w_out # 更新,加上修正量
for i in range(4):
delta_w_mid[:, i] = yita*out_in[i]*(1-out_in[i])*w_out[i]*res*(1-res)*(real-res)*net_in # 中间层神经元的权值修正量
delta_w_mid[2, i] = -yita*out_in[i]*(1-out_in[i])*w_out[i]*res*(1-res)*(real-res) # 中间层神经元的阈值修正量,第2行是阈值
w_mid = w_mid + delta_w_mid # 更新,加上修正量
# error=[error1,error2,...,error500] np.mean(error):500条记录的平均误差
Err.append(np.mean(error))
print(w_mid,w_out)
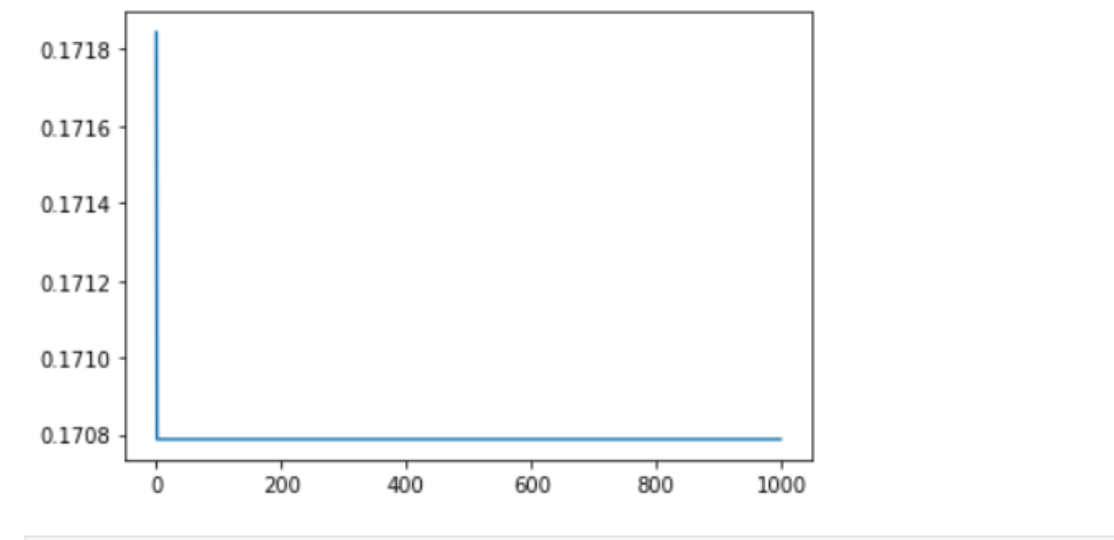
plt.plot(Err)#训练集上每一轮的平均误差,对训练集进行1000轮训练
plt.show()
plt.close()
截图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号