正则表达式
什么是正则表达式:
一种匹配字符串的规则
计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
1. 给定的字符串是否符合正则表达式的过滤逻辑(称作“匹配”);
2. 可以通过正则表达式,从字符串中获取我们想要的特定部分。
正则表达式的特点是:
# 可以定制一个规则,
#1. 来确认某一个字符串是否符合规则
#2. 从大段的字符串中找到符合规则的内容
1. 灵活性、逻辑性和功能性非常强;
2. 可以迅速地用极简单的方式达到字符串的复杂控制。
3. 对于刚接触的人来说,比较晦涩难懂。
应用场合:
# 程序领域
# 1.登录注册页的表单验证 web开发 要求简单语法
# 2.爬虫
# 爬虫 把这个网页下载下来 从里面提取一些信息,找到我要的所有信息,做数据分析
# 3.自动化开发 日志分析由于正则表达式主要应用对象是文本,因此它在各种文本编辑器场合都有应用,小到著名编辑器EditPlus,大到Microsoft Word、Visual Studio等大型编辑器,都可以使用正则表达式来处理文本内容。
例如:
# 是不是qq号码 : 全数字 5位以上 12位一下,第一位不是零
# 是不是身份证号 : 18位/15位 第一位不是零 18位的最后一位可能是x或者数字
# 有一个文件
# 要你把这个文件中所有的手机号都摘取出来
# 正则表达式能做什么
元字符类:
\ 转义符, 表示转义 例如(.\ 表示真正意义上的点)
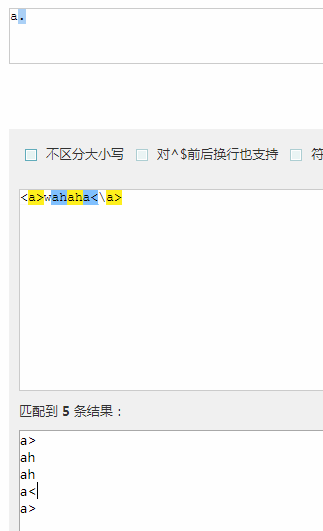
. 表示任意一个字符 匹配出了换行符之外的任意字符
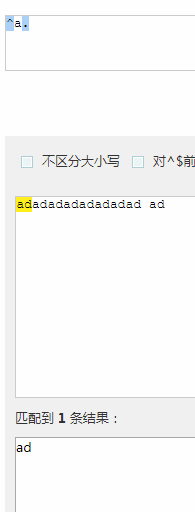
^a.的时候:
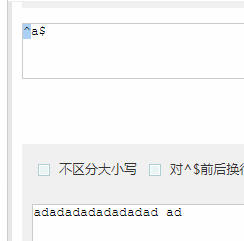
^a$的时候匹配不上字符:
+ 表示重复多次获这一次
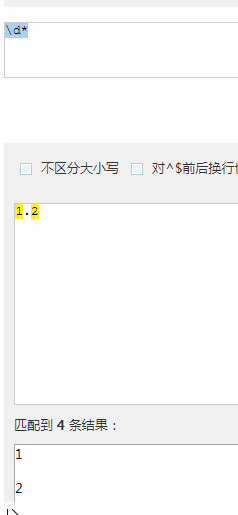
* 表示重复零次或者一次
? 表示重复零次或者一次
+ , * , ? 记忆顺序:
| 选择符号, 表示'或关系' , 例如: A|B , 匹配 A|B 如果两边你有重合部分则把
长的放前面
{} 定义量词
[] 定义字符串, 字符组 ===> [0-9] 表示0-9的数字范围
() 定义分组
^ 可以表示取反, 或匹配一行的开始
$ 匹配一行的结束
- 连字符
字符类:
\\ 匹配反斜杠\字符
\n 匹配换行符
\f 匹配一个换页符
\t 匹配一个水平制表符
\v 匹配一个垂直的制表符
\s(小写) 匹配一个空格符等价于[\t \n \r \f \v] (包括空格, 回车, TAB)
\S(大写) 匹配一个空格符, 等价于[^\s]
\d 匹配一个数字字符 == [0-9]
# \d{3} == \d{0,3} 表示每三个数字进行一次匹配
# \d\d{3} 表示每四个数字进行一次匹配,而不够四个字符的时候不进行匹配
# \d{3,} 表示至少是三个数字才进行匹配,但不管输入多少数字,都只匹配一次
# \d{1, 4} 表示出现最少出现一个数字, 最多出现四个数字就能进行一次匹配
# \d? ?表示只匹配一个字符或者零个字符. 在此处则就表示 无论如何都会匹配一次(在不输入的时候, 总是有一个开始字符,所以总会显示匹配一次.)
# \d\.?\d* 表示即可以匹配小数,也可以匹配整数.(此处的 . 被?转义,变成匹配0次,可有可无.)但是也能匹配1.
# \d\.?\d+ 表示至少是两位数, 1. 是不会匹配的.
# \d* 表示匹配0次或多次 就是在不输入字符的时候也能匹配,输入的时候也能匹配.但是除了数字意外的只显示匹配次数而没有结果.
例图:
\D 匹配一个非数字字符
\w 匹配任何语言的单词字符(如: 英文字母, 亚洲文字等)数字和
下划线(_)等字符.如果编译标志位ASCII,则只匹配[a-zA-Z0-9]
\W 等价于[^\w]
\b 匹配字符串的边界hello 边界为h和o \bh and o\b
[\d\D] = [\w\W] = [\s\S] 可以匹配所有字符

量词:
? 出现0次或一次
* 出现零次或多次
+ 出现一次或者多次
记忆方法:
此处1表示?, 1之后的无穷大为+ 两者组合为*
表示自 '李' 开始到无穷大的匹配, 只有一个'李'也是可以匹配的
李.+ : 表示至少是两位字符, 只有一个李是不会匹配的.(不包括换行)
# \d{1, 4} 表示出现最少出现一个数字, 最多出现四个数字就能进行一次匹配

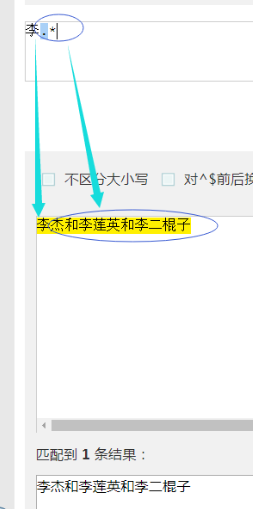
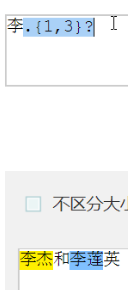
# 李.{1, 3} 表示出现最少出现一个字符, 最多出现三个字符就能进行一次匹配

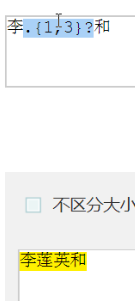
# 李.{1, 3}? 表示在能匹配上的情况下尽量少字符匹配. 此处就是李后面再跟一个字符
在能匹配上的情况下最大三个字符:
注意: ? 跟在元字符后面则就表示量词. 表示匹配一次或者0次
而在量词后面加? : *? ?? +? [最后的问号,对前面的量词起作用.] 则表示取消贪婪匹配(即,将贪婪匹配转为惰性匹配).

.*?X ===> 表示匹配任意字符, 直到找到一个X(在爬虫中会经常用到)
总结:
元字符接量词 在应用中默认为贪婪匹配
元字符量词? 表示惰性匹配
(量词只约束量词本身前面的一个元字符的出现次数 , 在往前的元字符不被约束)
(同理: ? 也只约束问号前面本身的量词或者元字符出现次数)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号