

Goroutine的深入浅出
一、Go中的堆和栈
1.1 堆和栈是什么
堆(Heap)是用户主动请求而划分出来的内存区域,它由起始地址开始,从低位(地址)向高位(地址)增长。Heap 的一个重要特点就是不会自动消失,必须手动释放,或者由垃圾回收机制来回收。
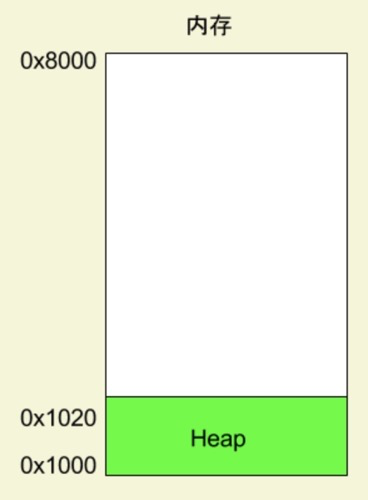
栈(stack) 是由于函数运行而临时占用的内存区域。从高位(地址)向低位(地址)分配。程序每调用一个函数,就会在栈的内存里面建立一个帧,这个函数所有的内部变量都保存在这个帧里面,比如,内存区域的结束地址是0x8000,第一帧假定是16字节,那么下一次分配的地址就会从0x7FF0开始;第二帧假定需要64字节,那么地址就会移动到0x7FB0。该函数执行结束后,该帧就会被回收,释放所有的内部变量,不再占用空间。
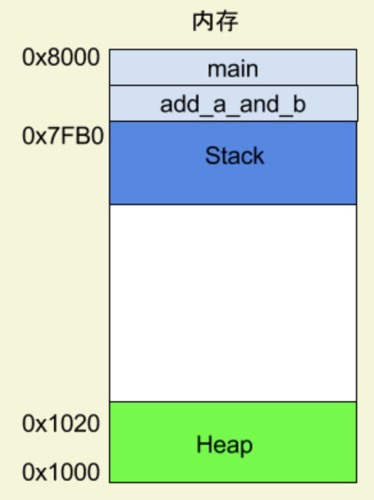
stack 的特点就是,最晚入栈的帧最早出栈(因为最内层的函数调用,最先结束运行),这就叫做"后进先出"的数据结构。每一次函数执行结束,就自动释放一个帧,所有函数执行结束,整个 Stack 就都释放了。一般来说,每个线程分配一个stack,每个进程分配一个heap,也就是说,stack是线程独占的,heap是线程共用的。
1.2 变量分配在栈还是堆?
堆区(heap) — 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。
栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
全局变量:一直常驻在内存中直到程序的结束,然后被系统垃圾回收。
局部变量: 在函数中定于的变量,每次执行的时候就创建一个新的实体,一直生存到没有使用(例如没有外部指针指向它,函数退出的时候没有路径访问到这个变量),这个时候它占用的空间就会被回收。
下面代码定义了函数的参数m0,局部变量m1,m2,m3,m4,m5,返回了局部变量m3:
package main
func foo(m0 int) *int {
var m1 int = 11
var m2 int = 12
var m3 int = 13
var m4 int = 14
var m5 int = 15
println(&m0, &m1, &m2, &m3, &m4, &m5)
return &m3
}
func main() {
m := foo(100)
println(*m)
}

查看调试信息,可以看出m3是分配在heap(堆)中,其他变量则是在stack(栈)中;虽然m3是局部变量,但是m3的指针被其他区域引用,当函数结束,此时m3并不会被释放,而是将局部变量m3申请在堆上。
二、进程、线程和协程
2.1 进程
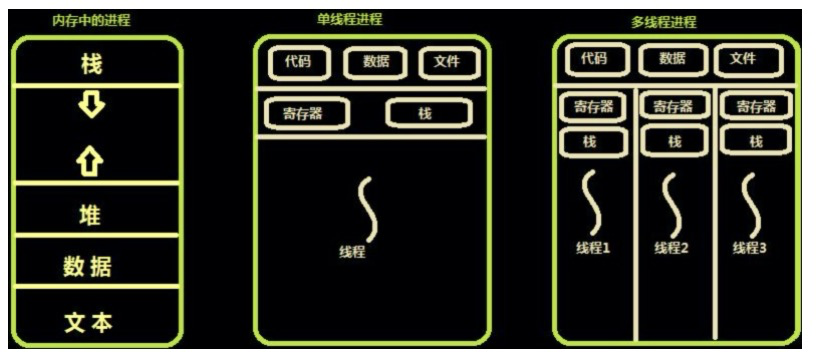
进程,直观点说,保存在硬盘上的程序运行以后,会在内存空间里形成一个独立的内存体,这个内存体有自己独立的地址空间,有自己的堆,上级挂靠单位是操作系统。操作系统会以进程为单位,分配系统资源(CPU时间片、内存等资源),进程是资源分配的最小单位。
2.2 线程
线程,有时被称为轻量级进程,是操作系统调度(CPU调度)执行的最小单位。和其它本进程的线程共享地址空间,拥有自己独立的栈和共享的堆,共享堆,不共享栈。
2.3 协程
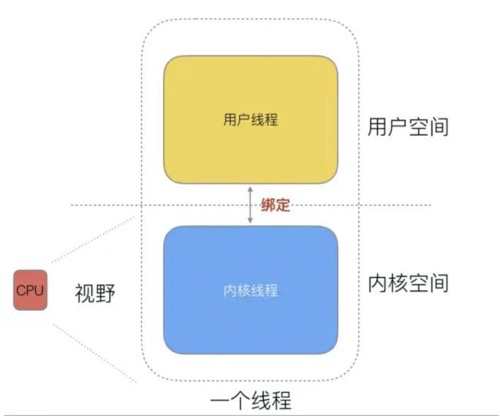
协程(用户线程),是一种比线程更加轻量级的存在,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。
三、Go语言的协程Goroutine
3.1 GMP模型
M:结构是Machine,系统线程,它由操作系统管理,goroutine就是跑在M之上的;
P:结构是Processor,处理器(上下文环境),调度G到M上,其维护了一个goroutine队列,即runqueue;
G:是goroutine实现的核心结构,它包含了栈,指令指针,一个go routine单元。
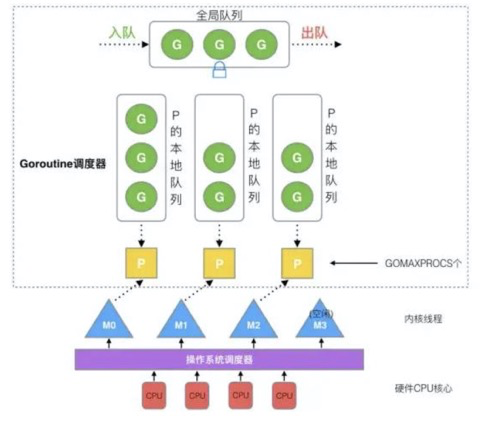
3.2 调度器策略
1、每一个Goroutine都是通过P分配到内核线程,然后通过OS调度器把内核线程分配到CPU的核上执行;
2、一个P只能绑定一个M,P会维护一个本地队列,如果本地队列满了,就会变把当前一半队列的G移动到全局队列;
3、G是按照队列的方式通过P分配到内核线程(一个内核线程只能运行一个G),内核线程分配到CPU是抢占式的;
4、P队列为空时,M也会尝试从全局队列拿一批G放到P的本地队列,或从其他P的本地队列偷一半放到自己P的本地队列。
5、在Go中,当G1在内核线程上占用CPU 10ms后,M上运行的G1会切换为G0,G0负责调度时协程的切换,从P中的本地队列取下一个G到线程上执行,G1将放回本地队列。
M0是启动程序后的编号为0的主线程,M0负责执行初始化操作和启动第一个G, 在之后M0就和其他的M一样了。
G0是每次启动一个M都会第一个创建的gourtine,G0仅用于负责调度的G,G0不指向任何可执行的函数, 每个M都会有一个自己的G0。
3.3 调度遇到阻塞的情况
Goroutine阻塞一般有:系统调用(syscall),网络IO,协程挂起,执行计算四种;
系统调用(syscall):G会阻塞内核线程M,此时M运行着G先跟P分离,P寻找其他空闲的M进行绑定;等G的系统调用完成后,G将重新分配到全局队列,M也会继续寻找绑定空闲的P;
网络IO:网络轮询器(NetPoller)来处理网络请求和 IO 操作的问题,其后台通过 kqueue(MacOS),epoll(Linux)或 iocp(Windows)来实现 IO 多路复用。不会导致M被阻塞,仅阻塞G;
协程挂起:当G遇到channel阻塞,sleep等阻塞后,G将挂起,不阻塞M,挂起完成过后才会放到队列里面,等待P的分配;
执行计算:当G遇到执行程序比较长时,超过10ms后会让出CPU执行权,回到队列等待,不阻塞M。
3.4 GODEBUG调度分析
1、使用sleep阻塞协程:
package main
import (
"fmt"
"runtime"
"time"
)
func init() {
runtime.GOMAXPROCS(4)
num := runtime.NumCPU()
fmt.Printf("cpu num :%v\n", num)
}
func main() {
for i := 1; i <= 10; i++ {
go func(i int) {
time.Sleep(10 * time.Second)
fmt.Printf("i = %v,end\n", i)
}(i)
}
for {
}
}
执行结果:
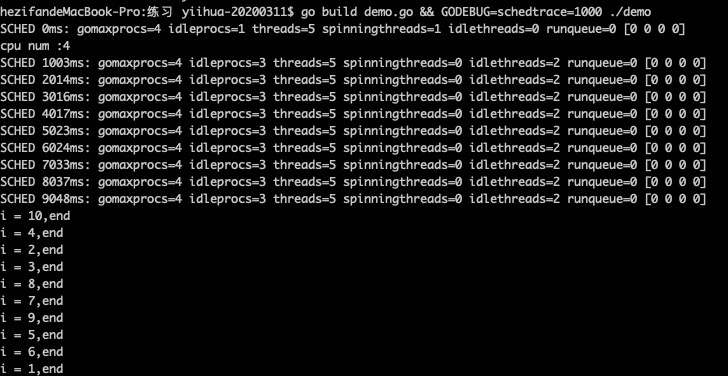
gomaxprocs: P的数量,本例有4个P, 因为默认的P的属性是和cpu核心数量默认一致,当然也可以通过GOMAXPROCS来设置;
idleprocs:处于idle状态的P的数量,上图数值为3,所以有一个P绑定的M在执行G,因为main函数有个死循环;
threads:os threads/M的数量,包含scheduler使用的m数量,加上runtime自用的类似sysmon这样的thread的数量;
spinningthreads:处于自旋状态的os thread数量;
idlethread: 处于idle状态的os thread的数量;
runqueue=0:Scheduler全局队列中G的数量;
[0 0 0 0]:分别为4个P的local queue中的G的数量。
总结:当所有G遇到sleep挂起时,G不会放在队列上,不阻塞;因为main函数有个死循环,队列也没有可用G,故执行main函数的G一直在M上执行;
1、使用紧密计算阻塞协程:
package main
import (
"fmt"
"runtime"
"time"
)
func init() {
runtime.GOMAXPROCS(4)
num := runtime.NumCPU()
fmt.Printf("cpu num :%v\n", num)
}
func main() {
for i := 1; i <= 10; i++ {
go func(i int) {
for j := 0; j <= 2999999999; j++ {
}
fmt.Printf("i = %v,end\n", i)
}(i)
}
for {
}
}
执行结果:
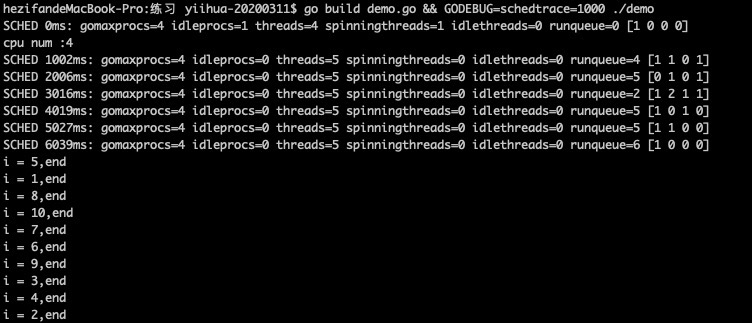
总结:当每个G执行时间长的时候,超过10ms后会让出CPU执行权,回到队列等待,不阻塞M。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号