
pytorch深度学习实战:线性模型上的学习
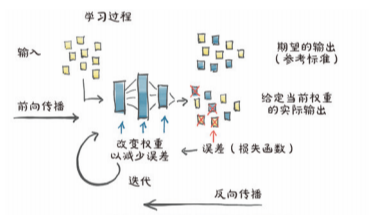 学习就是参数估计!本文首先通过人工方法,写出更新参数的具体步骤(第一节)。接着,将人工求导和人工更新参数的地方替换为自动方法(第二、三节)。本文的第四节介绍了分割数据集的必要性,并在第五节提出了分割数据集的具体方法。第六节展示了具体的实验结果和本文的最终代码。
学习就是参数估计!本文首先通过人工方法,写出更新参数的具体步骤(第一节)。接着,将人工求导和人工更新参数的地方替换为自动方法(第二、三节)。本文的第四节介绍了分割数据集的必要性,并在第五节提出了分割数据集的具体方法。第六节展示了具体的实验结果和本文的最终代码。
实践目标:找出摄氏度和华氏度的转换(线性关系)
提供数据如下:
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0] # 摄氏度
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4] # 华氏度
一、学习的机制
1.1 学习就是参数估计
单轮训练的核心步骤:
- 前向传播:根据当前参数计算模型输出(计算预测值)
- 计算损失:根据模型输出和真实标签计算损失(计算预测值与真实值的误差)
- 反向传播:每个参数的损失导数(梯度),即(根据误差计算参数更新方向,沿着梯度下降的方向更新)
- 更新参数:根据梯度和学习率更新参数(沿着更新方向以指定大小更新参数)
def training_loop(n_epochs, learning_rate, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
w, b = params
t_p = model(t_u, w, b) # 前向传播,计算预测值
loss = loss_fn(t_p, t_c) # 计算损失,计算预测值与实际值的误差
grad = grad_fn(t_u, t_c, t_p, w, b) # 反向传播,计算梯度
params = params - learning_rate * grad # 沿梯度的反方向更新参数
print('Epoch %d, Loss %f' % (epoch, float(loss)))
return params
1.1.1 前向传播: 计算预测值
# 模型
def model(t_u, w, b):
return w * t_u + b
1.1.2 计算损失: 计算预测值与真实值的误差
# 损失
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
return squared_diffs.mean()
1.1.3 反向传播: 根据误差计算参数更新方向
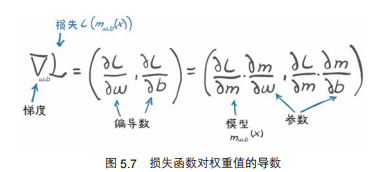
梯度下降的核心:
梯度方向是损失增长最快的方向,所以沿着梯度的反方向调节参数,才能减小损失。
# 损失函数的导数
def dloss_fn(t_p, t_c):
dsq_diffs = 2 * (t_p - t_c) / t_p.size(0)
return dsq_diffs
# 模型的导数
def dmodel_dw(t_u, w, b):
return t_u
def dmodel_db(t_u, w, b):
return 1.0
# 循环训梯度函数
def grad_fn(t_u, t_c, t_p, w, b):
dloss_dtp = dloss_fn(t_p, t_c)
dloss_dw = dloss_dtp * dmodel_dw(t_u, w, b) # 链式求导,(dL/dtp) * (dtp/dw)
dloss_db = dloss_dtp * dmodel_db(t_u, w, b)
return torch.stack([dloss_dw.mean(), dloss_db.mean()])
1.1.4 更新参数: 沿着更新方向以指定大小更新参数
learning_rate:学习率
- 表示参数变化对损失的影响:(1)变化多少?(2)当参数变化,损失⬆️还是⬇️?
- 太大,参数更新不稳定,参数的值开始来回波动,训练崩溃;太小,参数更新缓慢。
params = params - learning_rate * grad
1.2 归一化输入: 确保学习率对所有参数的更新都起作用
我们可以看到,在第 1 个迭代周期,权重的梯度大约是偏置梯度的 50 倍。这意味着权重和
偏置存在于不同的比例空间中,在这种情况下,如果学习率足够大,能够有效更新其中一个参数,
那么对于另一个参数来说,学习率就会变得不稳定,而一个只适合于另一个参数的学习率也不足
以有意义地改变前者。这意味着我们无法更新参数,除非我们改变模型的公式。每个参数可以有
各自的学习率,但是对于有很多参数的模型,这太麻烦了,我们不喜欢这种“保姆式”的方式。
可以用一种更简单的方法来控制一切:改变输入,这样梯度就不会有太大的不同。粗略地
说,我们可以确保输入的范围不会偏离−1.0~1.0 太远。在我们的例子中,我们可以通过简单地
将 t_u 乘 0.1 得到一个足够接近的结果
1.3 完整代码
点击查看代码
'''
用传统方法训练华氏度和摄氏度的转换函数
'''
import torch
# -----------------------------------------------------------------------
# 原始数据
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)
t_un = 0.1 * t_u # 归一化处理
# -----------------------------------------------------------------------
# 模型
def model(t_u, w, b):
return w * t_u + b
# 损失
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
return squared_diffs.mean()
# 模型的导数
def dmodel_dw(t_u, w, b):
return t_u
def dmodel_db(t_u, w, b):
return 1.0
# 损失函数的导数
def dloss_fn(t_p, t_c):
dsq_diffs = 2 * (t_p - t_c) / t_p.size(0)
return dsq_diffs
# 循环训梯度函数
def grad_fn(t_u, t_c, t_p, w, b):
dloss_dtp = dloss_fn(t_p, t_c)
dloss_dw = dloss_dtp * dmodel_dw(t_u, w, b) # 链式求导,(dL/dtp) * (dtp/dw)
dloss_db = dloss_dtp * dmodel_db(t_u, w, b)
return torch.stack([dloss_dw.mean(), dloss_db.mean()])
# 循环训练
# 单论训练的核心步骤:
# 1. 前向传播:根据当前参数计算模型输出
# 2. 计算损失:根据模型输出和真实标签计算损失
# 3. 反向传播:计算损失对参数的梯度
# 4. 更新参数:根据梯度和学习率更新参数
def training_loop(n_epochs, learning_rate, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
w, b = params
t_p = model(t_u, w, b)
loss = loss_fn(t_p, t_c)
grad = grad_fn(t_u, t_c, t_p, w, b)
params = params - learning_rate * grad
print('Epoch %d, Loss %f' % (epoch, float(loss)))
return params
# -----------------------------------------------------------------------
# # 1
# # 模型参数初始化
# w = torch.ones(())
# b = torch.zeros(())
# t_p = model(t_u, w, b)
# loss = loss_fn(t_p, t_c)
# # 变化率近似,求导数
# delta = 0.1
# loss_rate_of_w = \
# (loss_fn(model(t_u, w + delta, b), t_c) \
# - loss_fn(model(t_u, w - delta, b), t_c)) / (2.0 * delta)
# loss_rate_of_b = \
# (loss_fn(model(t_u, w, b + delta), t_c) \
# - loss_fn(model(t_u, w, b - delta), t_c)) / (2.0 * delta)
# # 沿梯度方向更新
# learning_rate = 1e-2
# w = w - learning_rate * loss_rate_of_w
# b = b - learning_rate * loss_rate_of_b
# print(w,b) # tensor(-44.1730) tensor(-0.8260)
# -----------------------------------------------------------------------
# # 2
# # 通过链式求导法则,通过公式求导数
# params = training_loop(
# n_epochs = 10000,
# learning_rate = 1e-4,
# params = torch.tensor([1.0, 0.0]),
# t_u = t_u,
# t_c = t_c)
# print(params)
# # Epoch 10000, Loss 28.292824
# # tensor([ 0.2370, -0.2866])
# # 未归一化,学习率对部分参数起作用,损失最终停滞不前。
# -----------------------------------------------------------------------
# 3
# 归一化:将输入都保持在-1.0~1.0之间,确保学习率对每个参数都起作用
params = training_loop(
n_epochs = 10000,
learning_rate = 1e-2,
params = torch.tensor([1.0, 0.0]),
t_u = t_un,
t_c = t_c)
print(params)
# Epoch 100000, Loss 2.927648
# tensor([ 5.3666, -17.2985])
# -----------------------------------------------------------------------
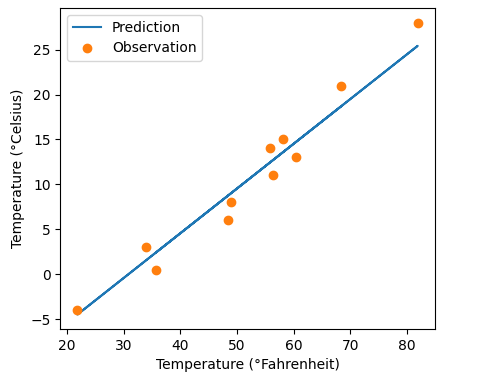
# 可视化数据
import matplotlib.pyplot as plt
t_p = model(t_un, *params)
# fig = plt.figure(dpi = 600)
plt.plot(t_u.numpy(), t_p.detach().numpy())
plt.plot(t_u.numpy(), t_c.numpy(), 'o')
plt.xlabel('Temperature (°Fahrenheit)')
plt.ylabel('Temperature (°Celsius)')
plt.legend(['Prediction', 'Observation'])
plt.show()
二、自动求导
人工计算链式求导费事费力,pytorch为我们提供了自动求导工具。
对第上一节代码进行修改如下,右边是修改后的代码:


另外的,因为不需要人工求导了,也可以删除所有人工求导的代码。

2.1 自动求导核心代码
def training_loop(n_epochs, learning_rate, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
if params.grad is not None: # <--清空上一循环的梯度,避免梯度累加
params.grad.zero_()
t_p = model(t_u, *params)
loss = loss_fn(t_p, t_c)
loss.backward() # <-- 自动求导
with torch.no_grad(): # <-- 在不更新梯度时,关闭梯度计算,减少额外开销
params -= learning_rate * params.grad # <--必须用-=,不能用=,否则会创建新的没有grid的params,到时训练失败
print('Epoch %d, Loss %f' % (epoch, float(loss)))
return params
params = training_loop(
n_epochs = 10000,
learning_rate = 1e-2,
params = torch.tensor([1.0, 0.0], requires_grad = True), # <--导数的值自动填充params的grad属性
t_u = t_un,
t_c = t_c)
2.2 完整代码
点击查看代码
'''
用传统方法训练华氏度和摄氏度的转换函数
自动求导
'''
import torch
# -----------------------------------------------------------------------
# 原始数据
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)
t_un = 0.1 * t_u # 归一化处理
# -----------------------------------------------------------------------
# 模型
def model(t_u, w, b):
return w * t_u + b
# 损失
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
return squared_diffs.mean()
# 循环训练
def training_loop(n_epochs, learning_rate, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
if params.grad is not None:
params.grad.zero_()
t_p = model(t_u, *params)
loss = loss_fn(t_p, t_c)
loss.backward()
with torch.no_grad():
params -= learning_rate * params.grad
print('Epoch %d, Loss %f' % (epoch, float(loss)))
return params
# -----------------------------------------------------------------------
params = training_loop(
n_epochs = 10000,
learning_rate = 1e-2,
params = torch.tensor([1.0, 0.0], requires_grad = True),
t_u = t_un,
t_c = t_c)
print(params)
# Epoch 100000, Loss 2.927648
# tensor([ 5.3666, -17.2985])
# -----------------------------------------------------------------------
# 可视化数据
import matplotlib.pyplot as plt
t_p = model(t_un, *params)
# fig = plt.figure(dpi = 600)
plt.plot(t_u.numpy(), t_p.detach().numpy())
plt.plot(t_u.numpy(), t_c.numpy(), 'o')
plt.xlabel('Temperature (°Fahrenheit)')
plt.ylabel('Temperature (°Celsius)')
plt.legend(['Prediction', 'Observation'])
plt.show()
三、优化器
3.1 优化器:自动更新参数
使用pytorch提供的优化器,实现自动更新参数
继续将第二节的代码修改如下:
即,将手动更新参数:
with torch.no_grad():
params -= learning_rate * params.grad
更改为torch的优化器,以自动优化参数,具体如下:
# 优化器
params = torch.tensor([1.0, 0.0], requires_grad = True)
learning_rate = 1e-2
optimizer = optim.SGD([params], lr = learning_rate)
# 循环训练
def training_loop(n_epochs, optimizer, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
t_p = model(t_u, *params)
loss = loss_fn(t_p, t_c)
optimizer.zero_grad() # 将上一步的梯度清零
loss.backward()
optimizer.step() # 自动更新参数
print('Epoch %d, Loss %f' % (epoch, float(loss)))
return params
# -----------------------------------------------------------------------
params = training_loop(
n_epochs = 10000,
optimizer = optimizer,
params = params,
t_u = t_un,
t_c = t_c)
3.2 完整代码
点击查看代码
'''
用传统方法训练华氏度和摄氏度的转换函数
优化器
'''
import torch
import torch.optim as optim
# -----------------------------------------------------------------------
# 原始数据
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)
t_un = 0.1 * t_u # 归一化处理
# -----------------------------------------------------------------------
# 模型
def model(t_u, w, b):
return w * t_u + b
# 损失
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
return squared_diffs.mean()
# 优化器
params = torch.tensor([1.0, 0.0], requires_grad = True)
learning_rate = 1e-2
optimizer = optim.SGD([params], lr = learning_rate)
# 循环训练
def training_loop(n_epochs, optimizer, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
t_p = model(t_u, *params)
loss = loss_fn(t_p, t_c)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Epoch %d, Loss %f' % (epoch, float(loss)))
return params
# -----------------------------------------------------------------------
params = training_loop(
n_epochs = 10000,
optimizer = optimizer,
params = params,
t_u = t_un,
t_c = t_c)
print(params)
# Epoch 100000, Loss 2.927648
# tensor([ 5.3666, -17.2985])
# -----------------------------------------------------------------------
# 可视化数据
import matplotlib.pyplot as plt
t_p = model(t_un, *params)
# fig = plt.figure(dpi = 600)
plt.plot(t_u.numpy(), t_p.detach().numpy())
plt.plot(t_u.numpy(), t_c.numpy(), 'o')
plt.xlabel('Temperature (°Fahrenheit)')
plt.ylabel('Temperature (°Celsius)')
plt.legend(['Prediction', 'Observation'])
plt.show()
四、欠拟合和过拟合
本节不涉及具体代码,仅记录相关概念,引出第五节。
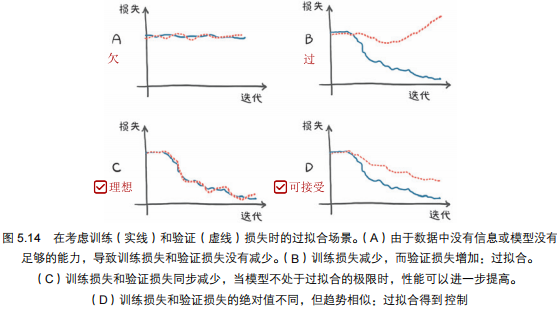
4.1 何为欠拟合?
4.1.1 表现:
- 训练损失一直未减少
4.1.2 解决办法?
- 模型相对数据来说太简单。增加神经元数量和模型参数;
- 数据无意义,如用气压计测量温度。
4.2 何为过拟合?
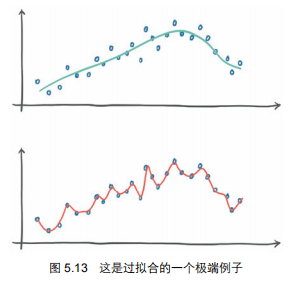
4.2.1 表现:
- 训练损失低:在训练数据上表现极好;
- 验证损失高:但是在新数据上表现糟糕。
4.2.2 解决办法?
- 保证足够数据;
- 在损失函数中添加惩罚项。以降低模型的成本,使其表现更平稳、变化更缓慢(直到某一点);
- 在输入样本中添加噪声。人为地在训练数据样本之间创建新的数据点,并迫使模型也试图拟合这些数据点;
- 简化模型。
我们有一些很好的折衷方法。一方面,我们需要模型有足够的能力来拟合训练集。另一方面,我们需要避免模型过拟合。因此,为神经网络模型选择合适的参数的过程分为 2 步:增大参数直到拟合,然后缩小参数直到停止过拟合。
五、分割数据集:训练集 + 验证集
相对第四节,本节代码变化如下:


为了观察训练的情况(避免欠拟合、过拟合等问题),我们需要将数据集分割,使用方法randperm。
添加分割数据集的代码:
# 分割数据集
n_samples = t_u.shape[0]
n_val = int(0.2 * n_samples)
shuffled_indices = torch.randperm(n_samples)
train_indices = shuffled_indices[:-n_val]
val_indices = shuffled_indices[-n_val:]
train_t_u = t_u[train_indices]
train_t_c = t_c[train_indices]
val_t_u = t_u[val_indices]
val_t_c = t_c[val_indices]
train_t_un = 0.1 * train_t_u # 归一化
val_t_un = 0.1 * val_t_u
在训练中验证训练效果:
# 循环训练
def training_loop(n_epochs, optimizer, params, train_t_u, train_t_c, val_t_u, val_t_c):
for epoch in range(1, n_epochs + 1):
train_t_p = model(train_t_u, *params)
train_loss = loss_fn(train_t_p, train_t_c)
with torch.no_grad(): # 关闭验证集的求导,避免不必要的开销
val_t_p = model(val_t_u, *params)
val_loss = loss_fn(val_t_p, val_t_c)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
if epoch <=3 or epoch % 500 == 0:
print('Epoch %d, Train Loss %f.4, Val Loss %f.4' % (epoch, float(train_loss), float(val_loss)))
return params
# -----------------------------------------------------------------------
params = training_loop(
n_epochs = 10000,
optimizer = optimizer,
params = params,
train_t_u = train_t_un,
train_t_c = train_t_c,
val_t_u = val_t_un,
val_t_c = val_t_c)
print(params)
六、本文最终代码和实验结果
6.1 实验结果
Epoch 1, Train Loss 53.571865.4, Val Loss 200.930481.4
Epoch 2, Train Loss 25.937567.4, Val Loss 122.372032.4
Epoch 3, Train Loss 20.557310.4, Val Loss 97.630035.4
Epoch 500, Train Loss 7.375591.4, Val Loss 33.852039.4
Epoch 1000, Train Loss 4.119481.4, Val Loss 16.841705.4
Epoch 1500, Train Loss 3.238195.4, Val Loss 10.319435.4
Epoch 2000, Train Loss 2.999669.4, Val Loss 7.556142.4
Epoch 2500, Train Loss 2.935114.4, Val Loss 6.289055.4
Epoch 3000, Train Loss 2.917640.4, Val Loss 5.675989.4
Epoch 3500, Train Loss 2.912910.4, Val Loss 5.369528.4
Epoch 4000, Train Loss 2.911628.4, Val Loss 5.213466.4
tensor([ 4.9739, -15.3188], requires_grad=True)
6.2 代码
点击查看代码
'''
用传统方法训练华氏度和摄氏度的转换函数
分割数据集:训练+验证
'''
import torch
import torch.optim as optim
# -----------------------------------------------------------------------
# 原始数据
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)
t_un = 0.1 * t_u # 归一化处理
# -----------------------------------------------------------------------
# 分割数据集
n_samples = t_u.shape[0]
n_val = int(0.2 * n_samples)
shuffled_indices = torch.randperm(n_samples)
train_indices = shuffled_indices[:-n_val]
val_indices = shuffled_indices[-n_val:]
train_t_u = t_u[train_indices]
train_t_c = t_c[train_indices]
val_t_u = t_u[val_indices]
val_t_c = t_c[val_indices]
train_t_un = 0.1 * train_t_u # 归一化
val_t_un = 0.1 * val_t_u
# -----------------------------------------------------------------------
# 模型
def model(t_u, w, b):
return w * t_u + b
# 损失
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
return squared_diffs.mean()
# 优化器
params = torch.tensor([1.0, 0.0], requires_grad = True)
learning_rate = 1e-2
optimizer = optim.SGD([params], lr = learning_rate)
# 循环训练
def training_loop(n_epochs, optimizer, params, train_t_u, train_t_c, val_t_u, val_t_c):
for epoch in range(1, n_epochs + 1):
train_t_p = model(train_t_u, *params)
train_loss = loss_fn(train_t_p, train_t_c)
with torch.no_grad(): # 关闭验证集的求导,避免不必要的开销
val_t_p = model(val_t_u, *params)
val_loss = loss_fn(val_t_p, val_t_c)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
if epoch <=3 or epoch % 500 == 0:
print('Epoch %d, Train Loss %f.4, Val Loss %f.4' % (epoch, float(train_loss), float(val_loss)))
return params
# -----------------------------------------------------------------------
params = training_loop(
n_epochs = 10000,
optimizer = optimizer,
params = params,
train_t_u = train_t_un,
train_t_c = train_t_c,
val_t_u = val_t_un,
val_t_c = val_t_c)
print(params)
# Epoch 100000, Loss 2.927648
# tensor([ 5.3666, -17.2985])
# -----------------------------------------------------------------------
# 可视化数据
import matplotlib.pyplot as plt
t_p = model(t_un, *params)
# fig = plt.figure(dpi = 600)
plt.plot(t_u.numpy(), t_p.detach().numpy())
plt.plot(t_u.numpy(), t_c.numpy(), 'o')
plt.xlabel('Temperature (°Fahrenheit)')
plt.ylabel('Temperature (°Celsius)')
plt.legend(['Prediction', 'Observation'])
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号