内存管理(-)
内存碎片
程序的内存往往不是紧凑连续排布的,而是存在着许多碎片。我们根据碎片产生的原因把碎片分为内部碎片和外部碎片两种类型:
(1) 内部碎片:系统分配的内存大于实际所需的内存(由于对齐机制);
(2) 外部碎片:不断分配回收不同大小的内存,由于内存分布散乱,较大内存无法分配;
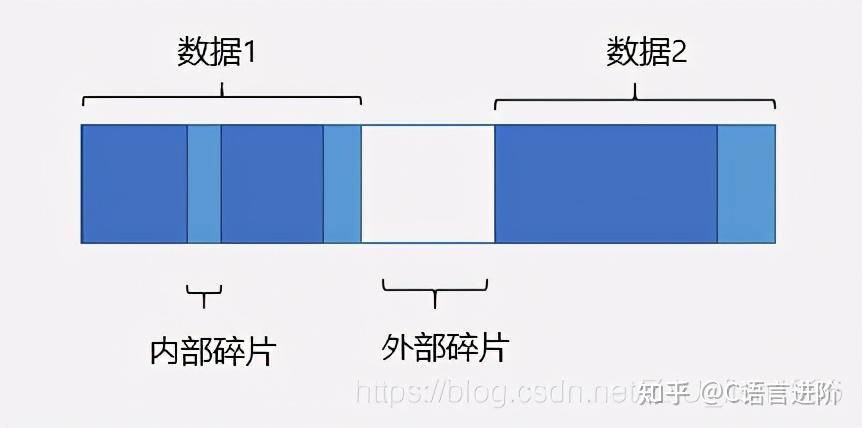
内部碎片和外部碎片
内存对齐
对于基础类型,如float, double, int, char等,它们的大小和内存占用是一致的。而对于结构体而言,如果我们取得其sizeof的结果,会发现这个值有可能会大于结构体内所有成员大小的总和,这是由于结构体内部成员进行了内存对齐。
为什么要进行内存对齐
① 内存对齐使数据读取更高效
在硬件设计上,数据读取的处理器只能从地址为k的倍数的内存处开始读取数据。这种读取方式相当于将内存分为了多个"块“,假设内存可以从任意位置开始存放的话,数据很可能会被分散到多个“块”中,处理分散在多个块中的数据需要移除首尾不需要的字节,再进行合并,非常耗时。
为了提高数据读取的效率,程序分配的内存并不是连续存储的,而是按首地址为k的倍数的方式存储;这样就可以一次性读取数据,而不需要额外的操作。

读取非对齐内存的过程示例
② 在某些平台下,不进行内存对齐会崩溃
内存对齐的规则
定义有效对齐值(alignment)为结构体中 最宽成员 和 编译器/用户指定对齐值 中较小的那个。
(1) 结构体起始地址为有效对齐值的整数倍
(2) 结构体总大小为有效对齐值的整数倍
(3) 结构体第一个成员偏移值为0,之后成员的偏移值为 min(有效对齐值, 自身大小) 的整数倍
相当于每个成员要进行对齐,并且整个结构体也需要进行对齐。
示例
struct A
{
int i;
char c1;
char c2;
};
int main()
{
cout << sizeof(A) << endl; // 有效对齐值为4, output : 8
return 0;
}
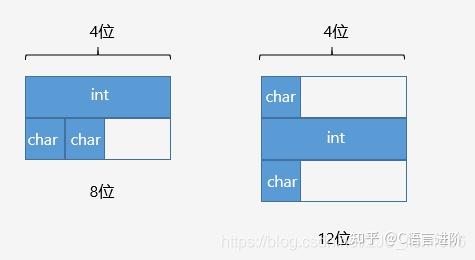
内存排布示例
高速缓存
一般来说CPU以超高速运行,而内存速度慢于CPU,硬盘速度慢于内存。
当我们把数据加载内存后,要对数据进行一定操作时,会将数据从内存载入CPU寄存器。考虑到CPU读/写主内存速度较慢,处理器使用了高速的缓存(Cache),作为内存到CPU中间的媒介。
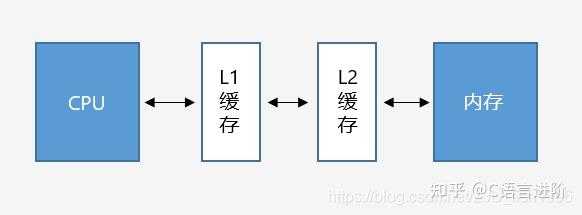
L1缓存和L2缓存
引入L1和L2缓存后,CPU和内存之间的将无法进行直接的数据交互,而是需要经过两级缓存(目前也已出现L3缓存)。
① CPU请求数据:如果数据已经在缓存中,则直接从缓存载入寄存器;如果数据不在缓存中(缓存命中失败),则需要从内存读取,并将内存载入缓存中。
② CPU写入数据:有两种方案,(1) 写入到缓存时同步写入内存(write through cache) (2) 仅写入到缓存中,有必要时再写入内存(write-back)
为了提高程序性能,则需要尽可能避免缓存命中失败。一般而言,遵循尽可能地集中连续访问内存,减少”跳变“访问的原则(locality of reference)。这里其实隐含了两个意思,一个是内存空间上要尽可能连续,另外一个是访问时序上要尽可能连续。像节点式的数据结构的遍历就会差于内存连续性的容器。
分配与管理机制
到目前为止,我们对内存的概念有了初步的了解,也掌握了一些基本的语法。接下来我们要讨论如何进行有效的内存管理。
设计高效的内存分配器通常会考虑到以下几点:
① 尽可能减少内存碎片,提高内存利用率
② 尽可能提高内存的访问局部性
③ 设计在不同场合上适用的内存分配器
④ 考虑到内存对齐


 浙公网安备 33010602011771号
浙公网安备 33010602011771号