HashMap系列二:hash计算
转载于:https://zhuanlan.zhihu.com/p/458305988
前提要点
我们知道Hash函数是寻址查询的,理论上能实现O(1)的查找(由于hash冲突的存在,实际上jdk1.8开始最坏情况查询复杂度为O(logn))。而在jdk中,这个地址其实就是数组的索引,我们通过hash值得到数组的索引,可以快速插入和查找一个数。比如下图的K1的hashCode为115,我们通过取余操作,115%16(数组大小)=3,得到地址3,将其放入数组arr[3]中。
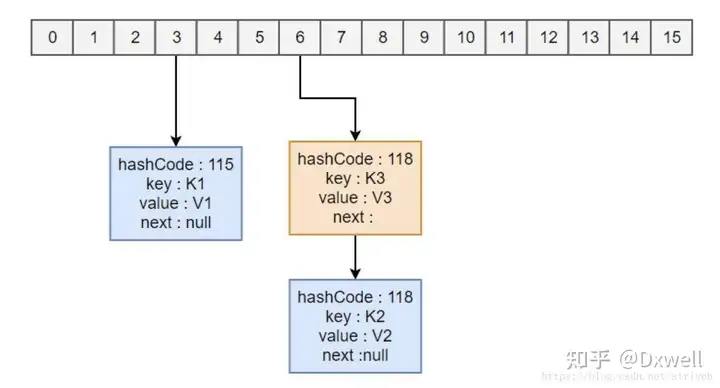
为了提高运算效率,HashMap作者想将取余操作替换成位运算,当使用位运算来求余数的时候,除数也就是数组的size必须为2的幂次方时才行
这里稍微解释一下原因,我们平常求余数怎么求,比如11%4,我们会通过11 / 4 = 2 ···3,商为2,剩余的就是余数3,那么同样对于二进制(下面用斜体表示二进制),11的二进制为1011,4是2的二次方,那么11除以4,相当于被除数11右移两位,商为1011右移两位为10就是2,被移掉的最后两位就是11,即余数为3。
换句话说,如果一个数除以2的N次方求余,那么我们就是要得到最后这个数最后N位二进制的值
因为size为二的幂次方,size-1的二进制一定为111···11这种全是1的数,这样进行与操作就能提取到后N位,所以位运算取余公式是 hash & (size - 1)
如果不想理解上面的数学方法,你要知道两点,第一,使用位运算取余必须保证table数组的size为二的幂次方,第二,位运算取余公式是 hash & (size - 1)
原因
hash值其实是一个int类型,二进制位为32位,而HashMap的table数组初始化size为16,取余操作为hashCode & 15 ==> hashCode & 1111 。这将会存在一个巨大的问题,1111只会与hashCode的低四位进行与操作,也就是hashCode的高位其实并没有参与运算,会导很多hash值不同而高位有区别的数,最后算出来的索引都是一样的
举个例子,我假设hashCode为1111110001,那么`1111110001 & 1111 = 0001`,高位发生变化时`1011110001 & 1111 = 0001`,`1001110001 & 1111 = 0001`,也就是说在高位发生变化时,你最后算出来的索引都一样了,这样就会导致很多数据都被放到一个数组里面了,造成性能退化。
为了避免这种情况,HashMap将高16位与低16位进行异或,这样可以保证高位的数据也参与到与运算中来,以增大索引的散列程度,让数据分布得更为均匀 (个人觉得很多博客说的减小哈希碰撞是错误的说法,因为hash碰撞指的是两个hashCode相同,这里显然不是)
为什么用异或,不用 & 或者 | 操作,因为异或可以保证两个数值的特性,&运算使得结果向0靠近, |运算使得结果向1靠近
结论
主要原因是保留高16位与低16位的特性,增大散列程度
本文来自博客园,作者:蓝迷梦,转载请注明原文链接:https://www.cnblogs.com/hewei-blogs/articles/17387953.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号