

动手数据分析-泰坦尼克案例(数据重构)
复习:在前面我们已经学习了Pandas基础,第二章我们开始进入数据分析的业务部分,在第二章第一节的内容中,我们学习了数据的清洗,这一部分十分重要,只有数据变得相对干净,我们之后对数据的分析才可以更有力。而这一节,我们要做的是数据重构,数据重构依旧属于数据理解(准备)的范围。
# 导入基本库
import numpy as np
import pandas as pd
2.4 数据的合并

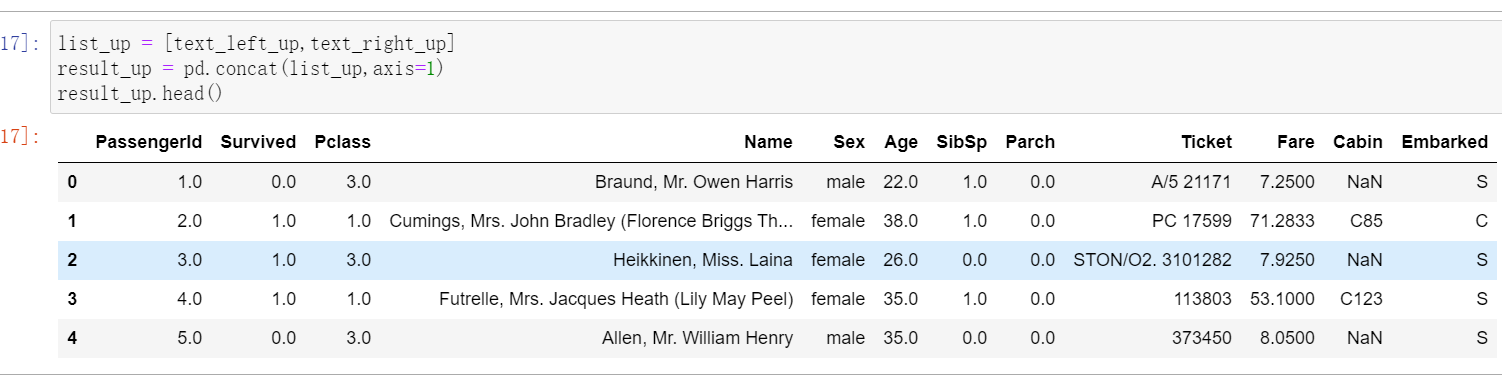
2.4.2:任务二:使用concat方法:将数据train-left-up.csv和train-right-up.csv横向合并为一张表,并保存这张表为result_up
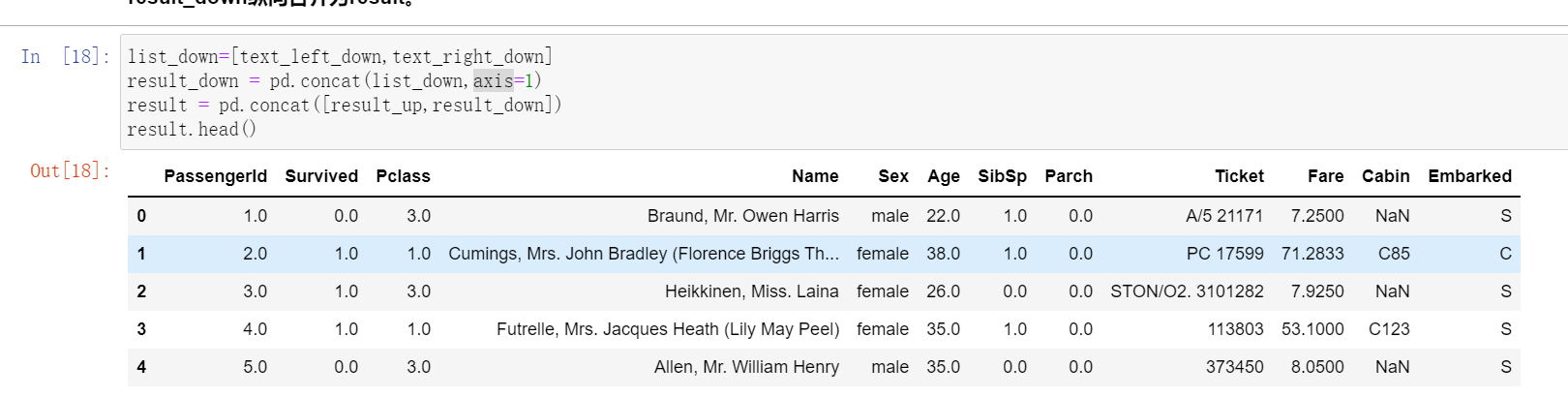
2.4.3 任务三:使用concat方法:将train-left-down和train-right-down横向合并为一张表,并保存这张表为result_down。然后将上边的result_up和result_down纵向合并为result。
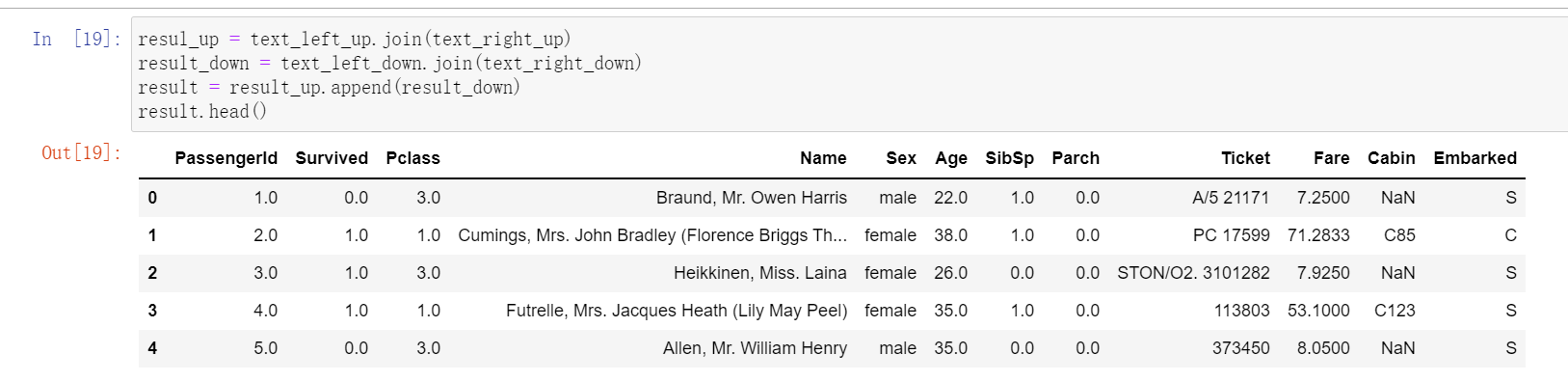
2.4.4 任务四:使用DataFrame自带的方法join方法和append:完成任务二和任务三的任务
2.4.5 任务五:使用Panads的merge方法和DataFrame的append方法:完成任务二和任务三的任务

【思考】对比merge、join以及concat的方法的不同以及相同。思考一下在任务四和任务五的情况下,为什么都要求使用DataFrame的append方法,如何只要求使用merge或者join可不可以完成任务四和任务五呢?
merge: 使用merge合并时,两个数据集的合并条件是类型须一致。默认是内连接,也可以按照需求选择outer,left,right等外连接方式,与sql的join相似;
concat: 合并两个数据集,可在行或者列上合并(用axis调节,默认axis=0)
join: 索引上的合并,是增加列而不是增加行,当合并的数据表列名字相同,通过lsuffix='', rsuffix='' 区分相同列名的列
2.5 换一种角度看数据
2.5.1 任务一:将我们的数据变为Series类型的数据
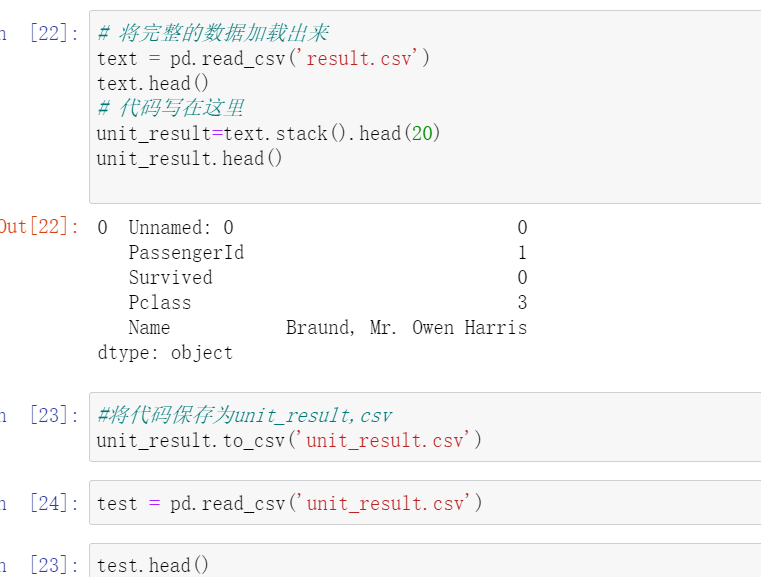
stack函数是干什么的?
在用pandas进行数据重排时,经常用到stack和unstack两个函数。stack的意思是堆叠,堆积,unstack即“不要堆叠”,
常见的数据的层次化结构有两种,一种是表格,一种是“花括号”,表格在行列方向上均有索引(类似于DataFrame),花括号结构只有“列方向”上的索引(类似于层次化的Series),结构更加偏向于堆叠(Series-stack,方便记忆)。stack函数会将数据从”表格结构“变成”花括号结构“,即将其行索引变成列索引,反之,unstack函数将数据从”花括号结构“变成”表格结构“,即要将其中一层的列索引变成行索引。
2.6 数据运用
2.6.1 任务一:通过《Python for Data Analysis》P303、Google or Baidu来学习了解GroupBy机制
将数据根据某个(多个)字段划分为不同的群体(group)进行分析
2.4.2:任务二:计算泰坦尼克号男性与女性的平均票价
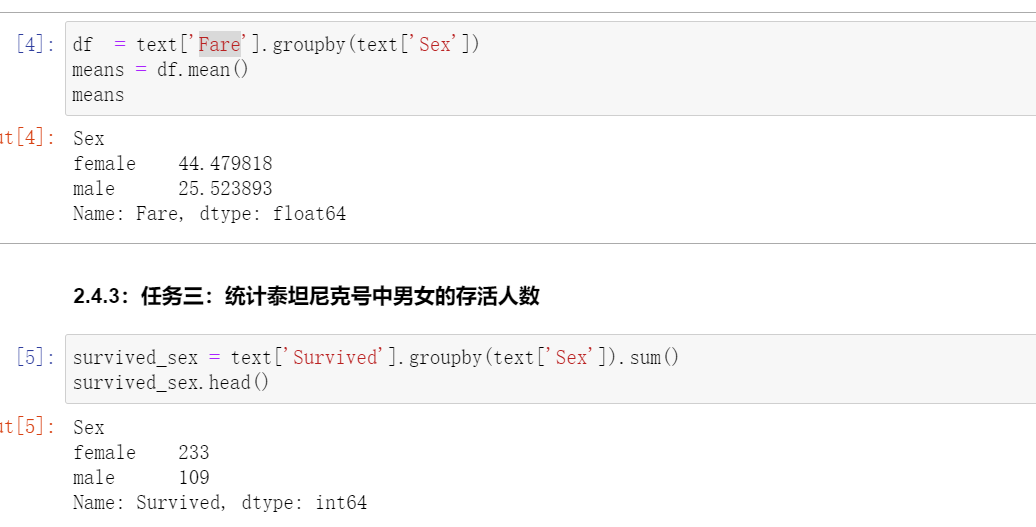

【思考】从任务二到任务三中,这些运算可以通过agg()函数来同时计算。并且可以使用rename函数修改列名。你可以按照提示写出这个过程吗?

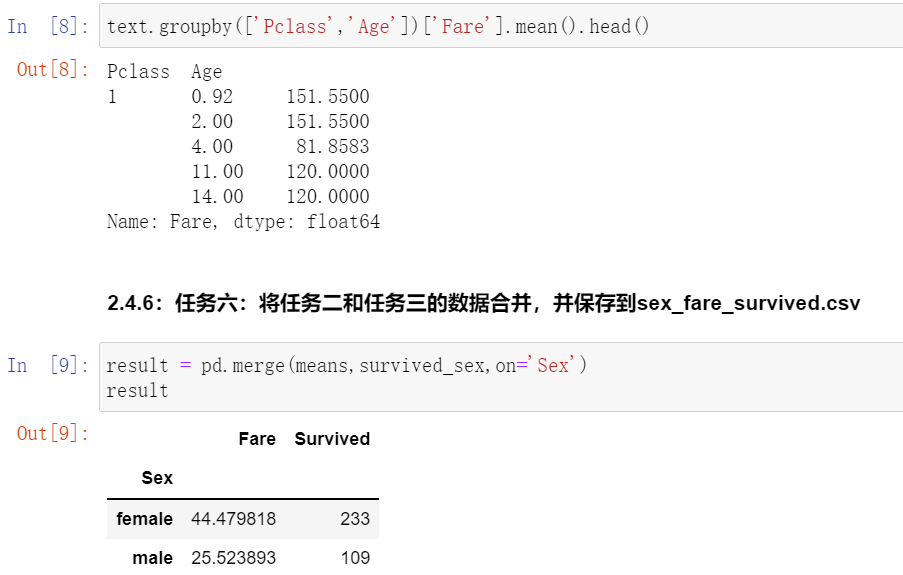
2.4.5:任务五:统计在不同等级的票中的不同年龄的船票花费的平均值
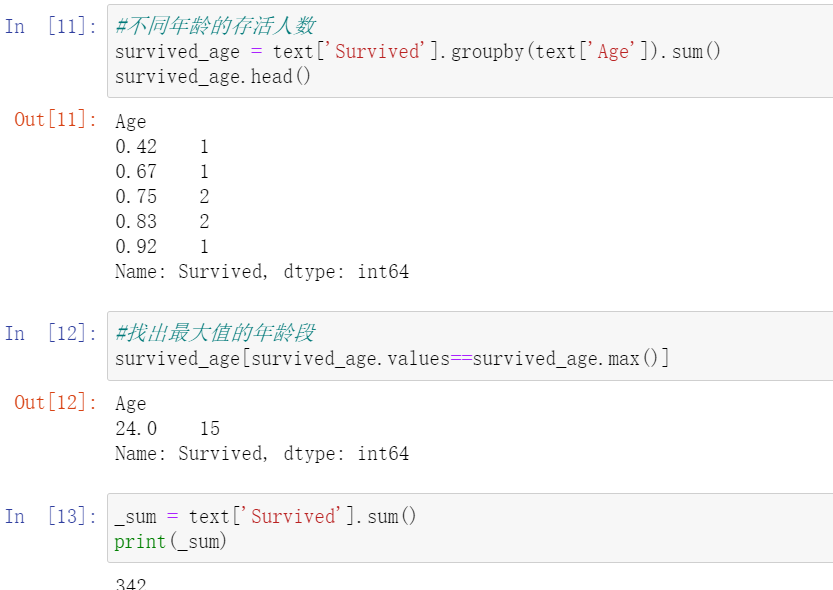
2.4.7:任务七:得出不同年龄的总的存活人数,然后找出存活人数的最高的年龄,最后计算存活人数最高的存活率(存活人数/总人数)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号