

动手数据分析-泰坦尼克案例(数据清洗及特征处理)
2.1 缺失值观察与处理
(1)请查看每个特征缺失值个数

df[df.Age.isna()]
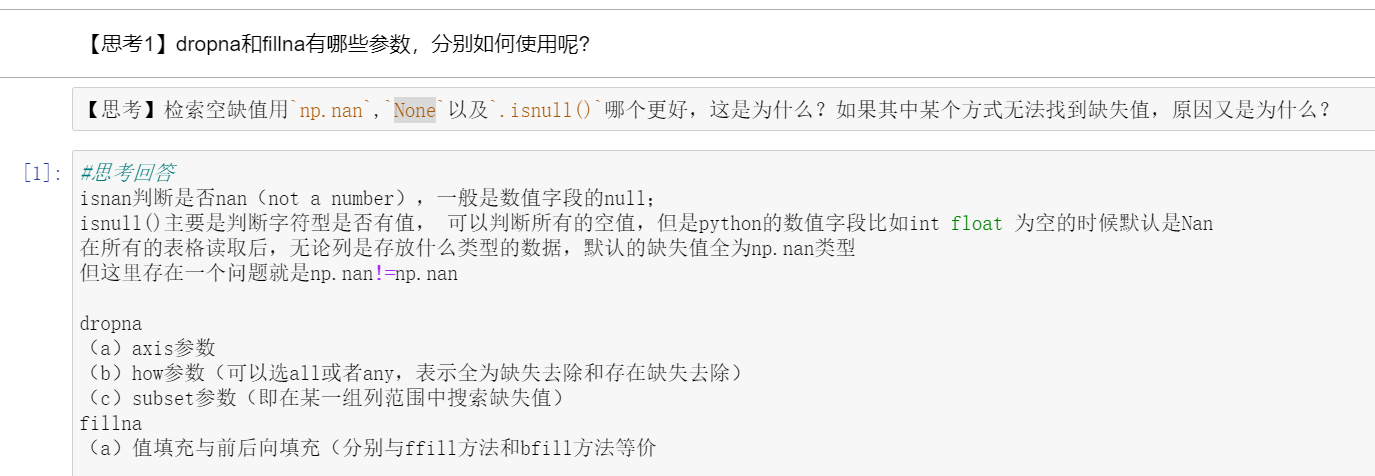
(2)缺失值处理方法

填充方法:



思考:
2.2 重复值观察与处理
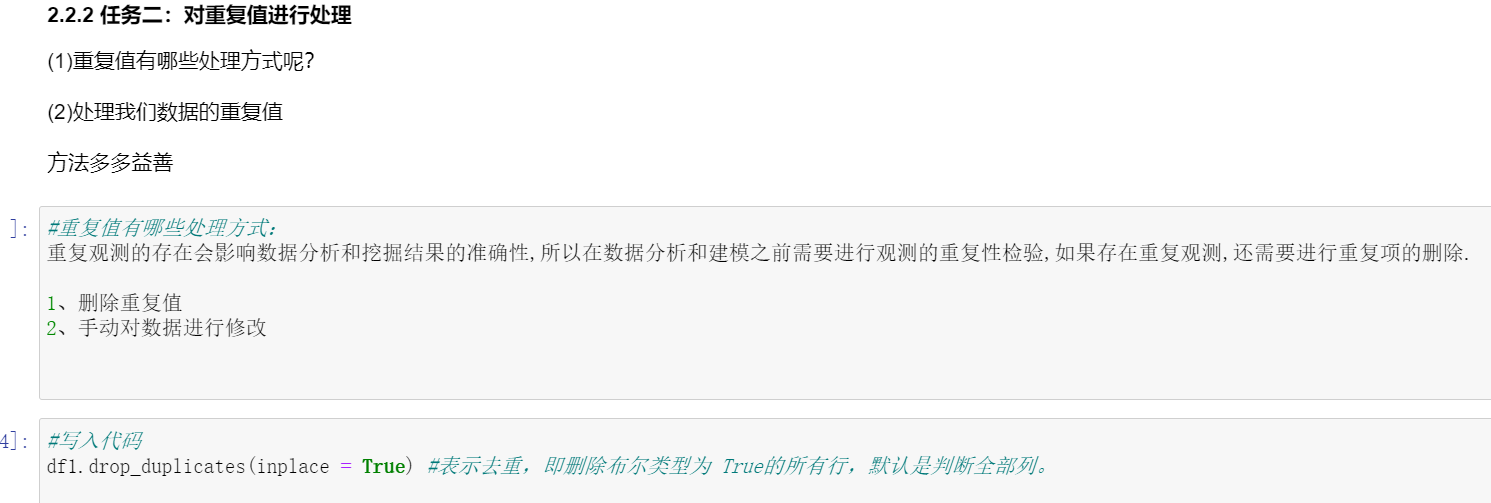
由于这样那样的原因,数据中会不会存在重复值呢,如果存在要怎样处理呢

2.3 特征观察与处理
我们对特征进行一下观察,可以把特征大概分为两大类:
数值型特征:Survived ,Pclass, Age ,SibSp, Parch, Fare,其中Survived, Pclass为离散型数值特征,Age,SibSp, Parch, Fare为连续型数值特征
文本型特征:Name, Sex, Cabin,Embarked, Ticket,其中Sex, Cabin, Embarked, Ticket为类别型文本特征,数值型特征一般可以直接用于模型的训练,但有时候为了模型的稳定性及鲁棒性会对连续变量进行离散化。文本型特征往往需要转换成数值型特征才能用于建模分析。
2.3.1 任务一:对年龄进行分箱(离散化)处理
(1) 分箱操作是什么?
(2) 将连续变量Age平均分箱成5个年龄段,并分别用类别变量12345表示
(3) 将连续变量Age划分为[0,5) [5,15) [15,30) [30,50) [50,80)五个年龄段,并分别用类别变量12345表示
(4) 将连续变量Age按10% 30% 50% 70% 90%五个年龄段,并用分类变量12345表示


2.3.2 任务二:对文本变量进行转换
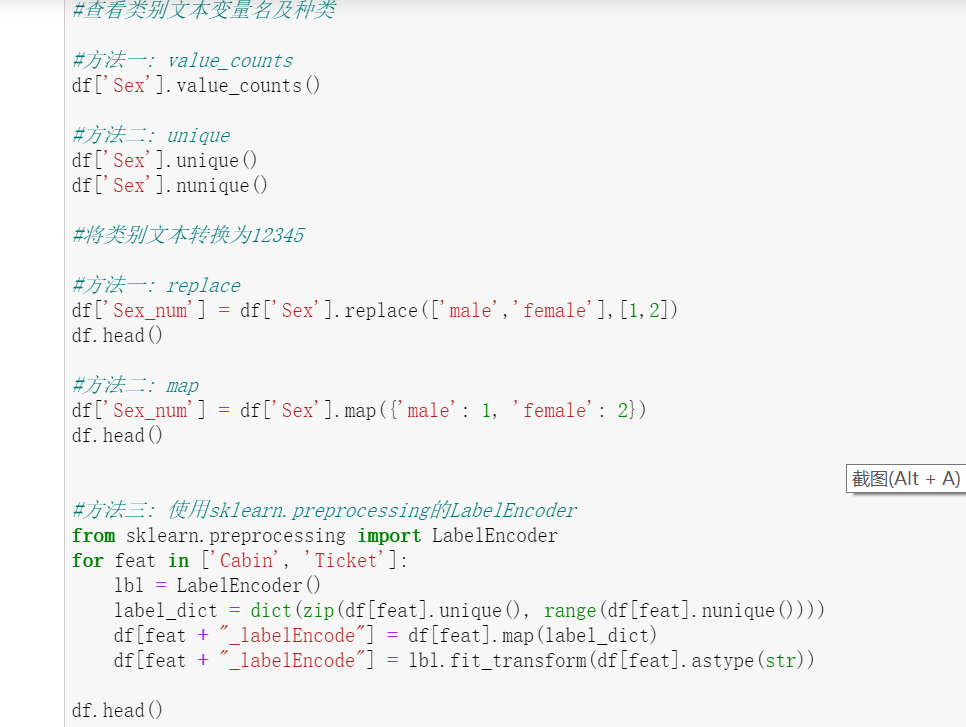
(1) 查看文本变量名及种类
(2) 将文本变量Sex, Cabin ,Embarked用数值变量12345表示
(3) 将文本变量Sex, Cabin, Embarked用one-hot编码表示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号