
卷积神经网络 --- 预训练模型
预训练模型简介
预训练模型是一个已经在大型数据集训练好的网络,当用于训练的数据集足够大时,模型学到的底层特征可以迁移到新的问题中。
特征提取
原理
特征提取是从预训练模型中,将提取到的有用特征输入到一个新的分类器中,从头开始训练。用于图像分类的卷积神经网络包含两个部分:第一个部分是卷积层和池化层,第二部分是密集连接分类器。第一部分又叫做卷积基。特征提取要做的就是把训练好的卷积基和一个新的分类器组合起来,让卷积基冻结,只训练分类器部分,具体过程如下图所示:
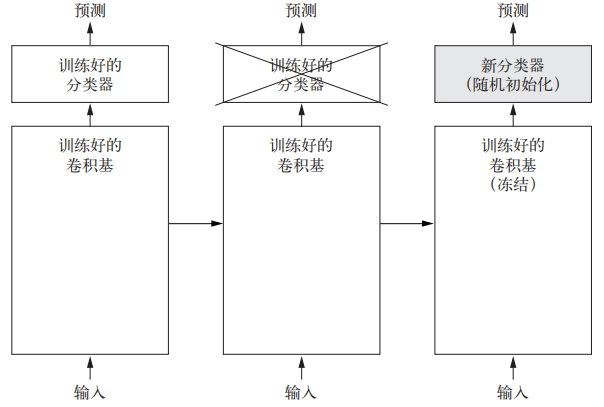
图1 特征提取示意图
应用方法
1.VGG16实例化
# VGG16实例化
from keras.applications import VGG16 # 导入已经训练好的VGG16
# VGG16与CNN的区别在于卷积层的增加
conv_base = VGG16(weights='imagenet',# 指定模型初始化的权重检查点
include_top=False,# 不包含密集连接分类器
input_shape=(150, 150, 3))# 输入到网络中的张量的形状
2.提取特征
# 使用预训练的卷积基提取特征
import os
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
base_dir = '/Users/fchollet/Downloads/cats_and_dogs_small'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
datagen = ImageDataGenerator(rescale=1./255)
batch_size = 20
def extract_features(directory, sample_count):
features = np.zeros(shape=(sample_count, 4, 4, 512))# 创建一个特征张量形状相同的数组用来存放
labels = np.zeros(shape=(sample_count))# 存放标签
generator = datagen.flow_from_directory(# 使用生成器不断生成符合要求的训练数据
directory,
target_size=(150, 150),
batch_size=batch_size,
class_mode='binary')
i = 0
for inputs_batch, labels_batch in generator:
features_batch = conv_base.predict(inputs_batch)# 提取卷积基中特征张量
features[i * batch_size : (i + 1) * batch_size] = features_batch#将提取到特征放到numpy数组中
labels[i * batch_size : (i + 1) * batch_size] = labels_batch#将提取到的标签放到numpy数组中
i += 1
if i * batch_size >= sample_count:
# Note that since generators yield data indefinitely in a loop,
# we must `break` after every image has been seen once.
break
return features, labels
train_features, train_labels = extract_features(train_dir, 2000)#提取特征
validation_features, validation_labels = extract_features(validation_dir, 1000)
test_features, test_labels = extract_features(test_dir, 1000)
3.定义并训练分类器
from keras import models
from keras import layers
from keras import optimizers
model = models.Sequential()# 搭建全连接层
model.add(layers.Dense(256, activation='relu', input_dim=4 * 4 * 512))
model.add(layers.Dropout(0.5))# dropout 防止过拟合
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer=optimizers.RMSprop(lr=2e-5),# 优化器
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(train_features, train_labels,# 训练模型(使用预训练特征提取后的模型)
epochs=30,# 训练轮次
batch_size=20,# 每次拿入20个单位进模型训练
validation_data=(validation_features, validation_labels))# 放入提取到的特征和标签
模型微调
原理
模型微调在特征提取的基础上,做了更进一步的改进。它将卷积基的顶部较为抽象的层解冻,并将解冻后的几层和新增加的部分联合训练。具体过程如下图所示:
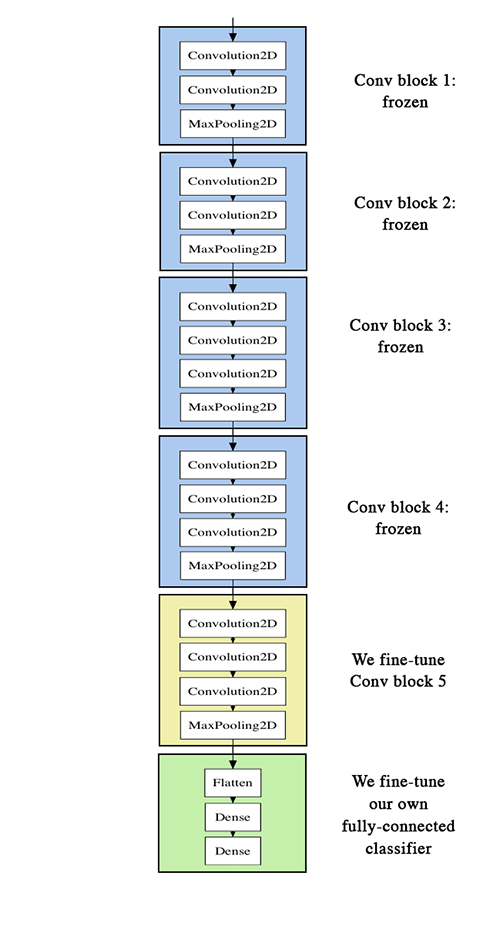
图2 模型微调
应用方法
1.冻结某些层
conv_base.trainable = True # 解冻卷积基所有层,相当于一个初始状态
set_trainable = False # 冻结其中部分层,但为什么要这样做?
for layer in conv_base.layers:# 如果不是第五层的卷积层全部冻结
if layer.name == 'block5_conv1':
set_trainable = True# 解冻第五层卷积层
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
2.微调模型
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-5),
metrics=['acc'])# 编译模型,准备训练
# 为什么要编译:只有先编译,才能是多卷积基的操作生效
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
posted on 2020-10-03 20:42 Heretic0224 阅读(1447) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号