

Memory Mapping and DMA [LDD3 15]
Table of Contents
15.1. Memory Management in Linux
15.1.2. Physical Addresses and Pages
15.1.4. The Memory Map and Struct Page
15.1.6.1 The vm_area_struct structure
15.1.7. The Process Memory Map
15.2. The mmap Device Operation
15.2.2. A Simple Implementation
15.2.4. Mapping Memory with nopage
15.2.5. Remapping Specific I/O Regions
15.2.6.1 Remapping RAM with the nopage method
15.2.7. Remapping Kernel Virtual Addresses
15.4.1. Overview of a DMA Data Transfer
15.4.2. Allocating the DMA Buffer
15.4.2.1 Do-it-yourself allocation
15.4.4.1 Dealing with difficult hardware
15.4.4.3 Setting up coherent DMA mappings
15.4.4.5 Setting up streaming DMA mappings
15.4.4.6 Single-page streaming mappings
15.4.4.7 Scatter/gather mappings
15.4.4.8 PCI double-address cycle mappings
15.4.4.9 A simple PCI DMA example
15.4.5.1 Registering DMA usage
15.4.5.2 Talking to the DMA controller
本章的内容分为三节:
1, mmap的实现,也就是把device memory map到user process里,这样可以提高performance。
2, kernel driver如何访问user space的page。
3, DMA,也就是device直接访问system memory。
15.1. Memory Management in Linux
15.1.1. Address Types
Linux kernel中有很多的地址类型,主要分为两类:虚拟地址,物理地址。在用户程序中看到的地址都是虚拟地址,和硬件使用的物理地址不同,虚拟地址并不直接对应物理地址,需要中转,采用虚拟地址的机制,可以让程序使用比物理地址多得多的内存。
kernel中的地址类型其实还需要细分,虚拟地址包括几种类型如下:
User virtual addresses
user space programmer看到的地址就是用户态虚拟地址,一般是32bit或者64bit,取决于当前的硬件架构,每个进程都有自己的虚拟地址空间。
Physical addresses
在处理器和系统内存之间,使用的就是物理地址。物理地址也分为32bit或者64bit,即便32bit系统,在某些条件下也能使用很大的物理内存。
Bus addresses
在外设总线和物理内存之间,使用的就是bus address。通常和CPU使用的物理地址相同,但是如果有IOMMU,就不一样了。IOMMU会把物理地址做一个map,拿到的地址就是bus address,device可以通过这个bus address做DMA。
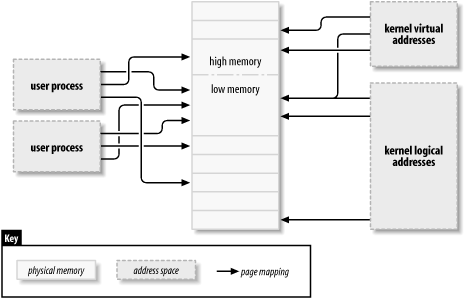
Kernel logical addresses
这个就是kernel自己的normal地址空间,一般会把物理内存map成normal地址空间,并且可以当作物理地址空间来使用,某些架构上,kernel的逻辑地址和物理地址差一个offset,逻辑地址通常使用硬件相关的native pointer,指针能访问多少memory,逻辑地址空间就能支持多少memory,通常这个pointer是一个unsigned long或者void *类型,因此如果在32bit系统上,就可能访问不了大的内存地址。kmalloc返回的就是逻辑地址。
Kernel virtual addresses
kernel虚拟地址和逻辑地址有些类似,都是最终map到物理地址,区别在于虚拟地址对应的物理地址可能不是连续的,不是一一映射。逻辑地址是虚拟地址的子集,即所有的逻辑地址都是虚拟地址,但不是所有的虚拟地址都是逻辑地址。例如,vmalloc和kmap返回的就是虚拟地址,它对应的物理内存可能不是连续的,kmalloc返回的地址就是逻辑地址,它分出来的page都是连续的。虚拟地址通常使用指针变量来存储。
如果你有一个逻辑地址,可以通过__pa()获取到它对应的物理地址;物理地址也可以通过__va()获取它的逻辑地址,但只限于low memory page,不能用于high-memory page。
在kernel的函数中,不同的接口可能需要不同的地址类型,这个需要自己特别注意。
15.1.2. Physical Addresses and Pages
kernel中的物理内存,都是按照page来管理,每一个page都是PAGE_SIZE这么大,PAGE_SIZE具体的值取决与硬件架构,一般是4096 byte。无论虚拟地址(逻辑地址?)还是物理地址,地址的组成都分成了两个部分:PFN(page frame number)和offset,假设先的PAGE_SIZE是4096byte,那么低12bit就是作为page中的offset,如果把这低12bit向右移出去,得到的值就是PFN。获取pfn的操作在kernel中很常见,具体移出去多少bit,取决于PAGE_SHIFT这个值。
15.1.3. High and Low Memory
kernel的虚拟地址和逻辑地址的区别在大容量物理内存的32位机器上笔记明显,理论上讲,32位机器上可以寻址4G的地址空间,但是因为kernel设置虚拟地址的方式,实际值比4G要小。
按照默认设置,32位的机器上,4G的地址空间划分为user space和kernel space,user space占用了3G的虚拟地址空间,kernel space占用1G的虚拟地址空间。在kernel 1G的地址空间里,除了kernel的code、data等占用的空间之外,能够map出来使用的地址空间不到1G。kernel里,如果没有对应的虚拟地址,kernel是无法访问这段memory的,因此kernel实际能够访问的内存实际上是1G减掉kernel code等自己占用的部分,也就是不到1G。如果是大容量的内存,就会导致很多的物理地址不能map到kernel的地址空间,从而不能使用。后来CPU中添加了feature,添加了内存扩展特性,从而使得CPU可以访问到超过4G的内存。但是kernel中的逻辑地址仍然有这个限制,只能map优先的物理内存,超过这部分的memory称为high memory,而kernel map过能直接访问的memory就是low memory,也就是在kernel中直接就存在逻辑地址。这里对high、low memory又做了定义:
Low memroy
kernel中可以使用的物理内存,这部分内存在kernel中有逻辑地址相对应,被称为low memory。
High memory
这部分内存在kernel中不存在直接能够访问的逻辑地址,因为地址范围超过了kernel的虚拟地址空间反问,被称为high memory。
kernel中low memory和hight memory的分界线在1G memory以下的某个位置。
15.1.4. The Memory Map and Struct Page
因为历史原因,kernel一直使用逻辑地址来访问物理内存中的page,因此对于hight memory,这种访问就有问题了,因为high memory在kernel中没有能直接访问的逻辑地址。因此kernel中对page的访问越来越多的使用struct page这个结构体,这个结构体中的成员有:
atomic_t count;
page的reference counter,如果变成了0,就被放入free page list。
void *virtual;
如果这个page被map过,记录的就是map后得到的虚拟地址,否则就是NULL。low memory通常都是被map过的,high memory通常没有被map。这个成员在有些架构上没有,因为他们有更好的计算虚拟地址的方法。
unsigned long flags;
用于描述page的属性和状态,比如PG_locked,说明page在memory中已经被lock;PG_reserved,说明page已经被reserve,kernel的内存管理不应该再touch这个page。
kernel中使用struct page的数组来管理物理内存,有些系统上只有一个数组mem_map,有些架构的系统上,比如NUMA,因为有大量不连续的物理内存,那就可能需要多个page 数组来管理这些内存。幸运的是,driver只需要使用struct page即可,不需要关心这个page从哪里来的。kernel提供了一些函数,可以方便的根据page获取virtual address:
#include <linux/mm.h>
#include <linux/highmem.h>
#include <asm/kmap_types.h>
//根据逻辑地址获取对应的page结构体,如果kaddr是从vmalloc或者high memory过来的,这个不能用。
struct page *virt_to_page(void *kaddr);
//根据pfn,获取它对应的page 结构体。
struct page *pfn_to_page(int pfn);
//返回这个page对应的kernel虚拟地址。如果是high memory,需要事先map过才行。一般不用,而是用kmap。
void *page_address(struct page *page);
#include <linux/highmem.h>
//kmap返回这个page对应的虚拟地址,如果是low memory,直接就是逻辑地址
//如果是high memory并且没有map过,kernel就会给它在专用的space里做一次map,然后返回虚拟地址。
//kmap对同一个page有reference counter,所以要和kunmap配对调用。
void *kmap(struct page *page);
void kunmap(struct page *page);
//是kmap的高性能版本,有些架构上会reserver一些专用的slots(PTE),给atomic用。
//参数type用来表明需要哪个slot,driver能够使用的slot一般是KM_USER0和KM_USR1(如果是在user space的系统调用),以及KM_IRQ0和KM_IRQ1(interrupt handler)。
//调用atomic的driver code必须是atomic的,不能sleep。
void *kmap_atomic(struct page *page, enum km_type type);
void kunmap_atomic(void *addr, enum km_type type);15.1.5. Page Tables
kernel中既然使用了虚拟地址,必然存在某种机制,可以通过虚拟地址得到物理地址,这个机制就是page table,page table也许是多级数据结构来实现,并且包含一些对应的flag。device driver的很多操作可能都会涉及page table,但是kernel已经做了封装,driver不需要和page table直接打交道,这里也不再赘述。
15.1.6. Virtual Memory Areas
virtual memory area (VMA)是kernel中的结构体,用于区分和管理进程地址空间中的不同区域。一个VMA中代表了一类有相同访问权限或者底层对应了同一个object的连续虚拟地址空间,大概类似于segment的概念。一个进程地址空间中通常包含以下几个部分:
1, 存储程序代码的区域。
2, 存放数据的区域,通常有多个,比如已经初始化的变量数据,还有未初始化的数据变量,以及程序的stack等。
3, 活动中的memory mapping的一个区域。
通过/proc/<pid/maps>可以看到这个进程虚拟地址空间的状态,读取maps,打印出来的东西有几个部分:
start-end perm offset major:minor inode image
看个例子:
# cat /proc/1/maps look at init
08048000-0804e000 r-xp 00000000 03:01 64652 /sbin/init text
0804e000-0804f000 rw-p 00006000 03:01 64652 /sbin/init data
0804f000-08053000 rwxp 00000000 00:00 0 zero-mapped BSS
40000000-40015000 r-xp 00000000 03:01 96278 /lib/ld-2.3.2.so text
40015000-40016000 rw-p 00014000 03:01 96278 /lib/ld-2.3.2.so data
40016000-40017000 rw-p 00000000 00:00 0 BSS for ld.so
42000000-4212e000 r-xp 00000000 03:01 80290 /lib/tls/libc-2.3.2.so text
4212e000-42131000 rw-p 0012e000 03:01 80290 /lib/tls/libc-2.3.2.so data
42131000-42133000 rw-p 00000000 00:00 0 BSS for libc
bffff000-c0000000 rwxp 00000000 00:00 0 Stack segment
ffffe000-fffff000 ---p 00000000 00:00 0 vsyscall page
# rsh wolf cat /proc/self/maps #### x86-64 (trimmed)
00400000-00405000 r-xp 00000000 03:01 1596291 /bin/cat text
00504000-00505000 rw-p 00004000 03:01 1596291 /bin/cat data
00505000-00526000 rwxp 00505000 00:00 0 bss
3252200000-3252214000 r-xp 00000000 03:01 1237890 /lib64/ld-2.3.3.so
3252300000-3252301000 r--p 00100000 03:01 1237890 /lib64/ld-2.3.3.so
3252301000-3252302000 rw-p 00101000 03:01 1237890 /lib64/ld-2.3.3.so
7fbfffe000-7fc0000000 rw-p 7fbfffe000 00:00 0 stack
ffffffffff600000-ffffffffffe00000 ---p 00000000 00:00 0 vsyscall除了image,其他每一列在kernel的struct vm_area_struct中都有对应的成员变量(除了image name):
start
end
这个memory area的start和end虚拟地址。
perm
这个memory area对应的读写或者执行权限,表示进程针对虚拟地址对应的page所能做的操作。最后的字符要么是p,表示private,要么是s,表示shared。
offset
表示当前的VMA,在这个被map的file中的起始offset,offset为0意味着VMA的start对应了file的start。
major
minor
代表了device的major/minor number,这个device就是使用了这个被map的file的device。
inode
被map的文件对应的inode。
image
被map的文件的文件名,通常是可执行文件。
15.1.6.1 The vm_area_struct structure
当用户态进程调用了mmap去map device memory的时候,kernel就会给它创建一个新的vm_area_struct结构体。底层的device driver需要实现mmap,mmap的功能其实就是帮助kernel初始化这个VMA。
下面我们就看一下vm_area_struct这个结构体里的成员变量,其中有些可能会被device driver用到。要注意的是vm_area_struct里有一些成员变量kernel用来存储VMA的list或者树形结构,因此这个结构体不能在device driver中创建,而是由kernel自己创建。其中,比较重要的member有:
unsigned long vm_start;
unsigned long vm_end;
这个VMA的start和end,也就是/proc/pid/maps里看到的start和end。
struct file *vm_file;
如果area有关联的 file,指向它。
unsigned long vm_pgoff;
被map的file的offset,按照page来算的,不是byte。当file后者device memory被map的时候,这个就是第一个被map的page的位置。
unsigned long vm_flags;
用来描述这个vma的flags。最重要的两个flag是VM_IO和VM_RESERVED。VM_IO表示这个vma是用来做I/O的memroy map,在做core dump的时候会跳过这个vma。VM_RESERVED告诉kernel不要把vma swap出去,在大部分device的map中都会设置这个flag。
struct vm_operations_struct *vm_ops;
kernel用来操作这个vma一系列函数。说明vma在kernel中也是类似于struct file的object(对应一系列的callback,类似于面向对象)。
void *vm_private_data;
driver用来存储自己的私有数据。
下面是vm_operations_struct中的callback:
void (*open)(struct vm_area_struct *vma);
当这个vma有新的reference时(比如fork),kernel会调用实现这个VMA的subsystem的open callback,用来对vma做一些初始化。如果这个vma第一次create是通过mmap产生的,open就不会被调用,而是去调用driver实现的mmap。
void (*close)(struct vm_area_struct *vma);
当vma被destroy的时候,kernel会调用vma的close callback。要注意的是,vma本身没有记reference count,process只会调用一次open和close。
struct page *(*nopage)(struct vm_area_struct *vma, unsigned long address, int *type);
当进程试图访问一个在有效的vma里面,但是当前不在memory里的page时,kernel会调用nopage这个callback。如果这个page是被swap到了别的存储设备,nopage会把这个page再swap进来,并返回struct page的指针。如果nopage callback是NULL,kernel会分配一个空的page。
int (*populate)(struct vm_area_struct *vm, unsigned long address, unsigned long len, pgprot_t prot, unsigned long pgoff, int nonblock);
当user 访问memory,kernel可以提前发生fault,driver一般不实现。(没太理解)
The Process Memory Map
kernel中的每一个进程,个别kernel thread除外,都会有一个结构体struct mm_struct,这个mm_struct中记录了很多和memory相关的数据结构,比如virtual memory area list,page tables,以及其他的一些bitmask,mmap的semaphore,page table的spinlock。这个mm_struct会记在task里面,因此在kernel中,可以通过current->mm来访问。这个mm_struct是可以share的,比如线程就会和别的线程共享进程地址空间。
15.1.7. The Process Memory Map
kernel 内存管理的最后一个是process memory map数据结构,这个数据结构把进程相关的其他数据结构都组合到一起,系统中的每个进程(除了kernel自己的一些helper thread)都有一个struct mm_struct数据结构,这个数据结构里记录了进程的vma,page tables,以及一些其他的bit mask,一个semaphore(mmap_sema),一个spinlock(page_table_lock)。mm_struct的指针就在task里面(也就current里,current->mm),driver可以通过current->mm来访问这个struct mm_struct,需要注意的是,mm_struct这个东西可以在多个process之间share,线程共享进程的虚拟地址空间就是通过这个做到的。
15.2. The mmap Device Operation
通过mmap,user space可以直接访问device的memory。书上以Xorg为例,获取它的maps:
cat /proc/731/maps
000a0000-000c0000 rwxs 000a0000 03:01 282652 /dev/mem
000f0000-00100000 r-xs 000f0000 03:01 282652 /dev/mem
00400000-005c0000 r-xp 00000000 03:01 1366927 /usr/X11R6/bin/Xorg
006bf000-006f7000 rw-p 001bf000 03:01 1366927 /usr/X11R6/bin/Xorg
2a95828000-2a958a8000 rw-s fcc00000 03:01 282652 /dev/mem
2a958a8000-2a9d8a8000 rw-s e8000000 03:01 282652 /dev/mem
...有个/dev/mem,Xorg map了四次,第一个offset是0xa0000,其实是ISA DMA memory之后的一段,是在ISA hole中的一段标准的video RAM。后面的两个/dev/mem,offset非常大,地址已经超过了RAM的地址,这是从video adapter直接map出来的device memory。在/proc/iomem中也能看到这段memory:
000a0000-000bffff : Video RAM area
000c0000-000ccfff : Video ROM
000d1000-000d1fff : Adapter ROM
000f0000-000fffff : System ROM
d7f00000-f7efffff : PCI Bus #01
e8000000-efffffff : 0000:01:00.0
fc700000-fccfffff : PCI Bus #01
fcc00000-fcc0ffff : 0000:01:00.0所谓的map device,其实就是将user space的一段virtual address对应到device的memory,当user space通过这个虚拟地址读写时,就是在读写device的memory。对于X这种类型的应用程序而言,直接能够访问video card的memory无疑可以获得较高的performance。
并不是所有的device都能支持mmap,比如串口设备或者其他流设备;另一个限制是mmap的memory size是以page为单位,kernel管理虚拟地址也是按照page为单位,这样的话mmap的内存大小就是page size的整数倍,而且对应物理地址的起始地址也应该是page size的整数倍。
这种限制对于driver来说并不是问题,因为底层硬件的工作方式对上层的driver来说是不透明的,也就说driver应该知道硬件的一些要求,比如page alignment等等。
mmap的好处,除了上面看到的Xorg这个例子,还有一个例子是PCI设备,PCI设备可以把自己的register space通过mmap的方式暴露给user space,从而在user space就可以直接操作PCI的寄存器,比ioctl的方式要方便和快捷。
mmap这个callback位于file_operations里面,当mmap系统调用发生的时候被kernel调用。但是drive要实现的这个mmap callback函数原型和user mode相比有较大不同,因为kernel在调用driver的mmap之前自己要做一些事情。
用户态的函数原型:mmap (caddr_t addr, size_t len, int prot, int flags, int fd, off_t offset)
driver要实现的mmap:int (*mmap) (struct file *filp, struct vm_area_struct *vma);
单看这个driver实现的callback,filp就是被open的file pointer,vma就是kernel为这次mmap分配的虚拟地址空间,可见kernel在调用mmap之前已经做了很多事情,driver需要做的就是为这个虚拟地址创建的page table entry,并且在必要的时候更新新的vma->vm_ops。
kernel提供了两种更新page table的方式:remap_pfn_range,可以一次性做完一个range的page table;或者通过之前提到过的nopage这个callback一个一个去做。下面分别看这两种方式。
15.2.1. Using remap_pfn_range
使用remap_pfn_range,可以一次性把一个range的physical memory和虚拟地址绑定,driver可以使用两个接口中的一个:
int remap_pfn_range(struct vm_area_struct *vma,
unsigned long virt_addr, unsigned long pfn,
unsigned long size, pgprot_t prot);
int io_remap_page_range(struct vm_area_struct *vma,
unsigned long virt_addr, unsigned long phys_addr,
unsigned long size, pgprot_t prot);这两个函数都是成功返回0,出错返回error value。下面看一下他们的参数:
vma
和device的物理内存对应的vma,后续就把其中的虚拟地址和device的物理内存绑定。
virt_addr
用户态虚拟地址首地址,也就是remap后用户态虚拟地址的开始位置,范围是virt_addr到virt_addr+size。
pfn
要被remap的物理内存的page frame number,其实就是物理地址。这个值就存储在vma->vm_pgoff,所以driver调用这个函数的时候直接用这个值就好。被map出去的物理内存的范围是(pfn << PAGE_SHIFT)到(pfn << PAGE_SHIFT) + size。
size
被map的内存大小,以byte为单位。
prot
这个vma的权限保护位,记录在vma->vm_page_prot,driver调用这个函数时用这个值就好。
remap_pfn_range和io_remap_page_range这两个函数是类似的,他们需要使用的大部分参数都在vma里,直接拿来用就可以了。为什么有两个函数实现同样的功能?如果按照标准用法,remap_pfn_range适用于物理内存在system RAM上的场景;io_remap_page_range适用于物理内存在I/O region的场景;然而在绝大部分架构上,这两个函数做的事情是一样的,除了在SPARC架构上。如果需要更好的移植性,则应该按照标准的做法,根据自己的场景选择合适的接口。
这里还讨论了另外一个问题,就是cache,一般来说,访问device memory的时候CPU不会做cache,这些设置应该由BIOS在开机的时候处理好。不过仍然可以通过vma的权限保护位来控制这一行为,只是这种方式成否凑效是跟CPU的实现相关的。
15.2.2. A Simple Implementation
如果driver需要一个简单的,线性映射的device memory给用户态程序访问,这里有一个简单的例子:
static int simple_remap_mmap(struct file *filp, struct vm_area_struct *vma)
{
if (remap_pfn_range(vma, vma->vm_start, vm->vm_pgoff,
vma->vm_end - vma->vm_start,vma->vm_page_prot))
return -EAGAIN;
vma->vm_ops = &simple_remap_vm_ops;
simple_vma_open(vma);
return 0;
}可以看到,这里实现的mmap callback直接调用了remap_pfn_range,用的参数都是直接从vma里取。
15.2.3. Adding VMA Operations
vma中记录了一个struct vm_operations_struct,这个里面存储的是针对这个vma可以做的操作,比如open/close等,通常driver只需要实现open/close即可。open这个callback被调用的时机是,当进程fork了一个子进程,或者这个VMA增加了一个新的reference counter;当VMA被close的时候,close函数会被调用。open和close是由kernel调用的,并且已经做了很多事情,driver之所以可以实现这个callback,是让driver有机会在open/close的时候做一些自己的事情。这里是一个简单的例子:
void simple_vma_open(struct vm_area_struct *vma)
{
printk(KERN_NOTICE "Simple VMA open, virt %lx, phys %lx\n",
vma->vm_start, vma->vm_pgoff << PAGE_SHIFT);
}
void simple_vma_close(struct vm_area_struct *vma)
{
printk(KERN_NOTICE "Simple VMA close.\n");
}
static struct vm_operations_struct simple_remap_vm_ops = {
.open = simple_vma_open,
.close = simple_vma_close,
};
vma->vm_ops = &simple_remap_vm_ops;
//显示调用open,触发open函数的调用。
simple_vma_open(vma);上面的例子中,driver实现了自己的open和close vma ops,并设给了vma,然后主动调用了一次open来触发open callback调用。
15.2.4. Mapping Memory with nopage
通常remap_pfn_range能够满足driver的绝大部分需求,然而一小部分的需求还是无法满足,因此kernel提供了另外一种方式来map物理内存——nopage callback。
在mremap这个系统调用中就会用到nopage callback,user space在此之前已经map过了meomry,通过mremap可以增大或者减小map的size,如果是减小,kernel会自己把多出来的page处理掉,不会通知driver;如果是要增大map的size,那就需要通过nopage这个callback通知driver,让driver再多map一些page出来。因此,如果driver需要支持mremap,就必须实现nopage这个callback。原型:
struct page *(*nopage)(struct vm_area_struct *vma, unsigned long address, int *type);当用户态程序访问了VMA中的一个page,但是这个page又没有在memory中时,driver的nopage函数就会被调用,参数address就是引起page fault的用户态虚拟地址,并且round down到page的整数倍address。nopage这个函数最终找到这个page,并且返回struct page指针,在返回之前,需要对这个page进行reference count加1操作,通过这个接口来完成:
get_page(struct page *pageptr);
当unmap的时候,再把这个page的ref减掉。kernel对page的管理需要使用它的reference counter,只要conter不为0,就说明有人再使用这个page,一旦reference counter变为0,就说没有人再使用这个page,它就会被kernel放到free list中去。当一个VMA被unmap时,它里面包含的所有page的reference couter都会被减1,如果driver之前没有处理好page的reference counter,这里就会出现问题。参数type如果不为NULL,记录的就是page fault的类型,对于device driver来说,这个值拿到的一直是VM_FAULT_MINOR。
看一个nopage的例子,当使用nopage的方式时,mmap要做的事情就很少了:
static int simple_nopage_mmap(struct file *filp, struct vm_area_struct *vma)
{
unsigned long offset = vma->vm_pgoff << PAGE_SHIFT;
if (offset >= _ _pa(high_memory) || (filp->f_flags & O_SYNC))
vma->vm_flags |= VM_IO;
vma->vm_flags |= VM_RESERVED;
vma->vm_ops = &simple_nopage_vm_ops;
simple_vma_open(vma);
return 0;
}mmap里做的主要事情就是设置了新的vm_ops,nopage callback会把对应的page map出来,然后返回page的指针:
struct page *simple_vma_nopage(struct vm_area_struct *vma, unsigned long address, int *type)
{
struct page *pageptr;
unsigned long offset = vma->vm_pgoff << PAGE_SHIFT;
unsigned long physaddr = address - vma->vm_start + offset;
unsigned long pageframe = physaddr >> PAGE_SHIFT;
if (!pfn_valid(pageframe))
return NOPAGE_SIGBUS;
pageptr = pfn_to_page(pageframe);
get_page(pageptr);
if (type)
*type = VM_FAULT_MINOR;
return pageptr;
}这里simple_vma_nopage只是操作main memory,vma中已经记好了对应的physical address,也就是pfn,我们nopage这里只需要把pfn转换成对应的page结构体指针,然后加上page的引用计数,就可以return了。注意,这里需要对送过来的pfn做invalid检查——pfn_valid,如果超出了memory range,直接返回NOPAGE_SIGBUS。
如果因为某些原因(比如请求的地址超出了device的memory region),不能返回一个正常的page指针,就返回NOPAGE_SIGBUS,如果memory不够,也可以返回NOPAGE_OOM。
注意,上面的例子可以用于ISA memory region,但是不适用于PCI设备的memory region,PCI memory map的地址在system memory以上,在system memory map的地址里没有对应的entry,因此没有page结构体与他对应,这种情况下,必须使用remap_pfn_range。
如果driver没有实现nopage这个callback,kernel在remap的时候返回一个fill 0的page出去,而且是copy-on-write的page,也就说如果用户态只是读,就会发现读到的都是0;如果写,就会分配一个page出来,然后写进去,这种机制经常可执行程序中的BSS使用。
15.2.5. Remapping Specific I/O Regions
很多时候driver只是需要把外设的一部分memory range map出去,而不是整个device memory,可以通过指定offset的方式来实现。这里有一个例子,device memory的起始地址是simple_region_start(page align),要map的内存大小是simple_region_size。
unsigned long off = vma->vm_pgoff << PAGE_SHIFT;
unsigned long physical = simple_region_start + off;
unsigned long vsize = vma->vm_end - vma->vm_start;
unsigned long psize = simple_region_size - off;
if (vsize > psize)
return -EINVAL; /* spans too high */
remap_pfn_range(vma, vma_>vm_start, physical, vsize, vma->vm_page_prot);除了计算offset,这个code还引入了一个check,如果发现user space想要map的内存大小超过了设备的物理内存,就返回EINVAL。在上面的code中,psize表示从指定的off开始,剩余的device memory大小,vsize是user space请求map的内存大小,如果user space请求的内存大小超过了device memory可用的,请求就会被拒绝。
要 注意的是,如果user space调用mremap来扩展它的map address space,就有可能导致它请求的size超过了device可用的,如果driver没有定义nopage函数,driver甚至不会知道这种事情的发生,user space的map会拿到一个zero的page,不过这种行为可能不是driver期望看到的。一个最简单的方式,是实现一个简单的nopage callback:
struct page *simple_nopage(struct vm_area_struct *vma,
unsigned long address, int *type);
{ return NOPAGE_SIGBUS; /* send a SIGBUS */}nopage这个callback,只有在user space访问了有效VMA里的虚拟地址,并且kernel发现虚拟地址没有对应真正的page table entry才会被调用。如果我们之前调用了remap_pfn_range来map整个device memory,那就不可能发生这种情况,因此只需要简单的返回NOPAGE_SIGBUS就足够了,因为这种访问一定是不正常的访问。当然,正常的driver应该检查导致page fault的地址是否在device的region范围之内,如果是,应该做remap。再次强调,nopage这个callback不适用于PCI设备。
15.2.6. Remapping RAM
使用remap_pfn_range来map物理内存有一个限制——它只允许map被reserve的物理内存或者系统物理内存之外的内存,而从kernel直接取到的page不能被remap,比如通过get_free_page获取到的page就不允许通过remap_pfn_range map做remap,如果driver这么做了,结果就是user space的vma map到了一个zero的page,从user space看,读写都能工作,只是不是期望的行为。对于大多数device driver而言,不会碰到这个问题,因为device driver只会map自己device的memory,不会map system的RAM。不过kernel也可以remap system的RAM,但是只能使用nopage这种方式。
15.2.6.1 Remapping RAM with the nopage method
直接看例子就明白了,就是利用virt_to_page通过kmalloc获取到的逻辑地址拿到它对应的page结构体。
int scullp_mmap(struct file *filp, struct vm_area_struct *vma)
{
struct inode *inode = filp->f_dentry->d_inode;
/* refuse to map if order is not 0 */
if (scullp_devices[iminor(inode)].order)
return -ENODEV;
/* don't do anything here: "nopage" will fill the holes */
vma->vm_ops = &scullp_vm_ops;
vma->vm_flags |= VM_RESERVED;
vma->vm_private_data = filp->private_data;
scullp_vma_open(vma);
return 0;
}
void scullp_vma_open(struct vm_area_struct *vma)
{
struct scullp_dev *dev = vma->vm_private_data;
dev->vmas++;
}
void scullp_vma_close(struct vm_area_struct *vma)
{
struct scullp_dev *dev = vma->vm_private_data;
dev->vmas--;
}
//大部分工作都是nopage这个callback在做。
struct page *scullp_vma_nopage(struct vm_area_struct *vma, unsigned long address, int *type)
{
unsigned long offset;
struct scullp_dev *ptr, *dev = vma->vm_private_data;
struct page *page = NOPAGE_SIGBUS;
void *pageptr = NULL; /* default to "missing" */
down(&dev->sem);
offset = (address - vma->vm_start) + (vma->vm_pgoff << PAGE_SHIFT);
if (offset >= dev->size)
goto out; /* out of range */
/*
* Now retrieve the scullp device from the list,then the page.
* If the device has holes, the process receives a SIGBUS when
* accessing the hole.
*/
offset >>= PAGE_SHIFT; /* offset is a number of pages */
for (ptr = dev; ptr && offset >= dev->qset;) {
ptr = ptr->next;
offset -= dev->qset;
}
if (ptr && ptr->data)
pageptr = ptr->data[offset];
if (!pageptr)
goto out; /* hole or end-of-file */
page = virt_to_page(pageptr);
/* got it, now increment the count */
get_page(page);
if (type)
*type = VM_FAULT_MINOR;
out:
up(&dev->sem);
return page;
}15.2.7. Remapping Kernel Virtual Addresses
通过vmalloc分出来的虚拟内存也可以remap给user 用,通过vmalloc_to_page来实现。
/*
* After scullv lookup, "page" is now the address of the page
* needed by the current process. Since it's a vmalloc address,
* turn it into a struct page.
*/
page = vmalloc_to_page(pageptr);
/* got it, now increment the count */
get_page(page);
if (type)
*type = VM_FAULT_MINOR;
out:
up(&dev->sem);
return page;虽然可以把vmalloc拿到的虚拟地址remap给user space用,但是ioremap这个函数返回的虚拟地址不可以再remap给user space用,而应该直接使用remap_pfn_range。
15.3. Performing Direct I/O
系统中大部分的I/O操作都会有buffer,使用buffer的好处在于用户态程序可以会device分隔开,用户态程序读写内存不会被device block住,从而获得更好的性能。但是在某些情况下,直接操作device memory,不经过buffer可以获得更高的performance,尤其是传输的数据比较多比较大的时候。
有些情况下使用direct I/O,返回会适得其反,因为配置direct I/O,需要处理fault,以及user page,这部分工作需要开销,结果就是还不如使用buffer的I/O更好。比如说用户态程序再把自己的I/O buffer的内存通过direct I/O写到device memory之前,这个I/O buffer是不能再被使用的,因此这个写就必须是同步的操作,直到data全部写到device才会返回,每次写都会block用户态程序,performance也会变差。
按照LDD3的说法,char device driver一般没有必要实现direct I/O操作。
kernel提供的direct I/O的主要接口是:
int get_user_pages(struct task_struct *tsk,
struct mm_struct *mm,
unsigned long start,
int len,
int write,
int force,
struct page **pages,
struct vm_area_struct **vmas);
tsk
指向执行I/O的task,目的是告诉kernel,当发生了page fault时,是负责处理。这个参数一般设置为current。
mm
指向虚拟内存管理的数据结构,其中包含了当前操作需要用到的VMA。一般设置为current->mm。
start
len
start是user page的start address(page align),len是内存大小(page number)。
write
force
如果write不是0,说明需要往user page里写(对user space来说要做读操作),force是告诉get_user_page在操作的时候override掉指定page的保护位,driver一般不设置force。
pages
vmas
这两个是output参数,如果get_user_page操作成功,pages里就是获取到的struct page list,vmas指向关联的vma list,这两个都是至少len长度的两个数组类型,以容纳len个数据结构。
get_user_pages是底层内存管理接口,在调用get_user_pages之前,要求driver获取mm的seamphore,例子如下:
down_read(¤t->mm->mmap_sem);
result = get_user_pages(current, current->mm, ...);
up_read(¤t->mm->mmap_sem);返回值是成功map的page的个数,有可能会被要求的小,但肯定不是0。函数返回以后,kernel就拿到了一个page array指针,这个指针指向了user space的buffer list,这个page数组指针不能在kernel中直接访问,需要先做kmap或者kmap_atomic,拿到虚拟地址以后才能访问。很多device对于direct IO操作,最后都是用来做DMA,device的DMA很多支持scatter/gather list,通过这个user space的buffer list可以很容易的组合成scatter/gather,然后做DMA使用,后面用到的时候再说。
在direct I/O完成以后,也就是driver使用完了这些user page,需要driver自己release。如果driver修改了这些page,在release之前要告诉kernel,kernel就会把修改的内容写回到memroy里面。怎么告诉kernel呢?调用SetPageDirty:
<linux/page-flags.h>
void SetPageDirty(struct page *page);
//driver调用:先check page是否在memory map的reserve 部分,如果不在才设为dirty。
if (! PageReserved(page))
SetPageDirty(page);
//无论user page是否被修改,在driver使用以后,必须调用这个release:
void page_cache_release(struct page *page);15.3.1. Asynchronous I/O
device driver中用的不多,所以这里也不讲了。
15.4. Direct Memory Access
Direct memory access,也就是DMA,指的是外设不通过CPU,直接读写主内存。不经过CPU,可以省掉很多的延迟,从而显著提高performance。
15.4.1. Overview of a DMA Data Transfer
在讲编程细节之前,先看一下DMA是如何发生的,以DMA的read为例。
DMA的读有两个触发条件:上层的application需要从设备读取数据;也就是设备需要向memory中写数据,一般是从hardware来了数据等。在第一个场景下,DMA的执行过程为:
1. 当用户态进程调用了read时,driver首选分配一个DMA buffer,再通知hardware,让它把数据放入这个DMA buffer,与此同时,发起read的process被sleep,等待硬件写数据完成;
2. hardware向DMA buffer中写数据,完成以后,产生中断;
3. interrupt handler拿到了数据,识别并处理中断,唤醒sleep的process,告诉它数据准备好了。
第二个场景下,是异步DMA read的方式,没有用户态进程调用read,硬件产生的新数据只能放入driver自己的DMA buffer,等以后用户态进程调用了read时,再把这些数据送给用户态进程。DMA的执行过程为:
1. 硬件产生中断,通知有新的数据产生;
2. interrupt hanlder处理中断,分配一个DMA buffer,告诉硬件往DMA buffer里写数据;
3. 硬件把数据写入指定的DMA buffer,写完以后产生中断;
4. interrupt handler 分发新的数据,并唤醒任何可能等待的process。
这种异步的DMA在网卡驱动中较为常见,driver内部使用circular buffer(DMA ring buffer)来管理,每次有新的数据到达,就会放到DMA ring buffer里,然后执行interrupt handler,把数据给kernel之后然后就会添加一个新的DMA ring buffer。
以上讲的DMA都是中断驱动,虽然也可以通过polling的方式做DMA,但是这种同步的DMA方式可能显著降低performance,因此not make sense。DMA buffer是一些特殊的buffer,专门用来做DMA,许多device driver在初始化的时候把DMA buffer分配出来使用,直到shutdown才会释放。
15.4.2. Allocating the DMA Buffer
使用DMA buffer有一个问题要注意,如果buffer的大小超过一个page,那么这些pages必须是连续的物理内存,因为ISA或者PCI总线使用的是物理内存。另一个要注意的问题是DMA buffer的分配,可以在bootup的时候,也可以在runtime的时候,对于module driver来说,只能是runtime的时候分DMA buffer,分配buffer的时候要从合适的zone里分配,因为不是所有zone里的物理内存都可以做DMA,比如high memory可能在某些架构或者外设上做DMA使用。
现代绝大多数外设都支持32bit寻址,因此从kernel分配的normal memory都是可以做DMA用的,不过某些PCI设备可能没有完全按照PCI的标准来做,所以不能支持32bit寻址,要看具体的设备;像ISA设备,也只能支持24bit寻址。对于有这种限制的外设,在使用kmalloc或者get_free_pages来分配memory时,应当在gfp mask中设置GFP_DMA,这样kernel就会从外设能够寻址的24bit地址空间内分配内存。不过,你也可以使用kernel提供的DMA layer来workaround这个地址空间受限的问题。
15.4.2.1 Do-it-yourself allocation
driver可以从kernel的memory management中分配内存,也可以通过reserve的方式来分配。随着kernel的运行,内存的碎片会增多,如果module driver分配大量连续内存,就存在失败的可能。为了避免这个问题,driver可以在系统bootup的时候reserve memory出来,通过在启动参数中设置mem=255M,可以把从255M开始的物理内存reserve出来,driver如果需要使用就map出来:
dmabuf = ioremap (0xFF00000 /* 255M */, 0x100000 /* 1M */);总之,分配大量连续的物理内存做DMA,并不是一个好主意,如果有这个需求,考虑一下device是否支持scatter/gather,如果是,应该分配离散的page,然后组合到一起作为外设的DMA buffer,使用scatter/gather是最好的方式。
15.4.3. Bus Addresses
使用DMA的device driver,driver内部使用虚拟地址,而外设则直接使用物理地址。然而这种描述并不精确,外设使用的地址是总线地址,并不是物理地址,尽管ISA和PCI使用的总线地址和物理地址相同,但是在某些平台并不是这样。有些总线接口是通过bridge circuitry相连接,I/O地址会被map到不同的物理地址,而有些系统上可以把离散的page map成连续的地址给外设bus。
为了解决上述的问题,kernel在最底层提供了一些具有移植性的函数,不过这些函数不推荐使用,因为只在某些具有简单I/O架构的系统上可以使用:
unsigned long virt_to_bus(volatile void *address);
void *bus_to_virt(unsigned long address);上面的函数只是在kernel的逻辑地址和总线地址之间做了转换,如果中间涉及到IOMMU或者bounce buffer,这种方式就无法工作,正确的方式是使用kernel提供的DMA layer。
15.4.4. The Generic DMA Layer
笼统的说,DMA就是分配buffer,把buffer的bus地址告诉外设,外设通过buffer的bus地址读写RAM。虽然逻辑看上去很简单,但是要想写出正确,安全访问DMA的driver有很大难度:不同的系统对cache一致性的处理方式不同,driver如果不考虑cache,就会导致memory corrupt;不同的硬件对DMA的支持方式不一样的,有的简单一些,有的非常复杂;不是所有的系统都能够在所有的memory上做DMA。比较幸运的是,kernel提供了DMA layer,DMA layer与架构和总线都保持独立,可以帮助driver实现DMA。这些DMA layer的接口要使用struct device,这个struct device就是kernel的设备模型中,最底层的device表示,driver可以在bus相关的device中找到这个底层的device,比如在pci_device中或者usb_device中的dev成员,这个device就是DMA layer需要使用的。
15.4.4.1 Dealing with difficult hardware
再使用DMA之前,要做的第一步就要确认外设能支持多少bit的地址寻址,这关系到如何使用DMA,如果使用的DMA buffer地址超过了外设能够寻址的范围,那就无法做DMA。默认情况下,kernel认为外设都可以在32bit地址空间内做DMA,如果外设因为某些限制不能访问全部的32bit地址空间,driver需要告诉kernel外设的访问能力:
int dma_set_mask(struct device *dev, u64 mask);如果外设支持24bit地址的DMA,mask就设置为0xffffff。如果返回非零值,说明可以在24bit地址内做DMA,否则就不可以,例子:
if (dma_set_mask (dev, 0xffffff))
card->use_dma = 1;
else {
card->use_dma = 0;
/* We'll have to live without DMA */
printk (KERN_WARN, "mydev: DMA not supported\n");
}因为kernel默认外设支持32bit寻址,如果device支持32bit,就没必要调用这个函数。
15.4.4.2 DMA mappings
DMA mapping,就是分配一个DMA buffer并且生成一个外设可以访问的地址。虽然可以通过virt_to_bus获取buffer的地址,但是不推荐这样做,第一个原因是很多的硬件平台有IOMMU,针对bus存在map register集合,IOMMU可以把离散的page变成连续的bus 地址,这样外设可以访问scatter,virt_to_bus在有IOMMU的这种情况下就不能使用。
并不是所有的架构上都有IOMMU,很x86上就没有(现在有了),写得好的driver不需要关心底层硬件中是否存在IOMMU设备。
由于kernel无法直接访问high memory,也没有high memory的page,所以如果通过high memory做DMA,需要借助bounce buffer,bounce buffer是device能够直接访问的memory,通过bounce buffer的中转(copy to/from),device可以间接实现high memory的DMA。使用bounce buffer无疑会导致performance降低,但是这也没得选。
DMA中另外一个重要的问题是cache coherency,因为做DMA的memory,CPU和Device都有可能去访问,就要做好cache一致性。DMA layer中引入了一个新的变量类型——dma_addr_t,用来表示做DMA的bus address,dma_addr_t唯一会被使用到的地方就是把它传递给其他的DMA layer routine,以及给外设,CPU如果直接访问这个bus address会有不可预料的错误。
在PCI core中区分了两类DMA mapping,依据是DMA buffer生命周期的长短:
1. Coherent DMA mappings
这种DMA map得到的buffer生命周期比较长,一般和driver自己的生命周期保持一致,coherent DMA buffer可以同时被CPU和device访问,而且会在coherent 的memory里面。coherent DMA buffer在kernel中比较少。
2. Streaming DMA mappings
这种方式得到的DMA buffer一般只是给单个操作使用,因此生命周期比较短。这个DMA buffer同一时间只能给一个人用,比如CPU或者外设。kernel中推荐优先使用streaming map的DMA buffer,原因有两个:
a,IOMMU针对bus有mapping register,每一个DMA map都会占用其中的一个或几个register。coherent dma mapping的生命周期很长,因此占用的map register就很久,即便可能没有用到。
b,很多架构对streaming dma可以做优化,coherent就很难优化。
这两个map的接口也是不同的。
15.4.4.3 Setting up coherent DMA mappings
先看coherent的,通过调用dma_alloc_coherent可以获得一个conherent map的DMA buffer:
void *dma_alloc_coherent(struct device *dev, size_t size,
dma_addr_t *dma_handle, int flag);
void dma_free_coherent(struct device *dev, size_t size,
void *vaddr, dma_addr_t dma_handle);
dma_alloc_coherent函数所做到事情有两个:分配dma buffer,分配DMA bus address。前两个参数是底层device,和要分配的DMA buffer的大小。返回值有两个,函数返回值void *是dma buffer的虚拟地址,可以被driver直接使用,参数里的dma_handle就是buffer的dma_addr_t,也就是dma bus address,flag就是gfp的flag,因为需要分配page,所以需要指定gfp mask,如果是普通的分配就是GFP_KERNEL,如果是atomic context,就设置为GFP_ATOMIC。当dma buffer不再使用的时候调用dma_free_coherent。
15.4.4.4 DMA pools
DMA pool可以用来分配size比较小的coherent DMA buffer。通过dma_alloc_coherent分配的dma buffer都是一个page以上,如果只需要size比较小的memory做DMA,可以使用DMA pool。
和之前的kmem cache用法类似,在使用DMA pool之前要创建DMA pool:
struct dma_pool *dma_pool_create(const char *name, struct device *dev,
size_t size, size_t align,
size_t allocation);
void dma_pool_destroy(struct dma_pool *pool);
void *dma_pool_alloc(struct dma_pool *pool, int mem_flags,
dma_addr_t *handle);
void dma_pool_free(struct dma_pool *pool, void *vaddr, dma_addr_t addr);dma_pool_create里,name是DMA pool的名字,方便debug;dev是底层device;size是从DMA pool中分配的DMA buffer的size;align是从DMA pool中分配的DMA buffer需要做的hardware align;allocation代表了不能跨越的boundary,如果不是0,就是限制分配的DMA buffer不要跨越allocation这个boundary,比如allocation是4096,就是说从DMA pool中分配的DMA buffer不能跨4096.
如果不再要DMA pool,就调用dma_pool_destroy把它destroy掉。在调用dma_pool_destroy之前,要保证DMA buffer都已经释放掉。
从DMA pool中分配DMA buffer,要调用dma_pool_alloc这个接口。pool代表之前dma_pool_create拿到的DMA pool;mem_flags是gfp mask;如果函数成功执行,就会返回固定大小的DMA buffer,大小就是dma_pool_create的时候指定的size。
如果DMA buffer不再使用,就调用dma_pool_free把它释放掉。
15.4.4.5 Setting up streaming DMA mappings
和coherent DMA mapping相比,streaming DMA mapping接口更加复杂,原因是多方便的:streaming map支持对已经分配的page进行DMA map,而且要处理没有被选中的address,在某些架构上,还支持scatter/gather。
在使用streaming DMA map之前,要告诉kernel这个DMA buffer的数据流向(enum dma_data_direction):
DMA_TO_DEVICE 写到device里面去(来自user space的write操作)
DMA_FROM_DEVICE 从device里面读出来(来自user space的read操作)
DMA_BIDIRECTIONAL 读写同时有
DMA_NONE debug用,如果操作了NONE的DMA,kernel会报panic
虽然可以一直设置DMA_BIDIRECTIONAL,但是performance不如正确的设置direction。
如果只是map/unmap单个buffer,可以使用接口:
dma_addr_t dma_map_single(struct device *dev, void *buffer, size_t size,
enum dma_data_direction direction);
void dma_unmap_single(struct device *dev, dma_addr_t dma_addr, size_t size,
enum dma_data_direction direction);
dma_map_single中,返回值是bus address,如果出错,返回0. 如果DMA做完了,就要调用dma_unmap_single,其中的size和direction必须和dma_map_single使用的一模一样。
有一些原则需要注意:
1. DMA buffer一定按照当时map用的direction来使用
2. 一旦map成功,这个buffer就归device所有,CPU不能再使用,只有做了unmap之后,DMA buffer才又归CPU所有,可以操作。
3. 如果DMA buffer正在做DMA,一定不能unmap。
关于2,可能会比较奇怪为什么DMA buffer在同一时间只能被device或者CPU访问,原因主要有两个:
a,如果需要map dma buffer,kernel要保证DMA buffer对应的CPU cache全部写到了memory,因此此时可能会有一次CPU cache的flush,driver在flush之后写到buffer的内容就没机会flush到memory里面去了。
b,第二情况和第一种有些类似。有些memory不能直接用来做DMA,某些架构上会通过bounce buffer的方式间接实现DMA的访问,比如当前是TO_DEVICE的,那么bounce buffer的操作会在map调用的时候把original buffer里的内容copy到bounce buffer中去,如果map了以后,driver还在操作original buffer,那么这部分操作是没有同步到bounce buffer中去的。考虑到bounce buffer的存在,就知道为什么不要随便设置DMA 的方向为同时读写了,因此会有两次bounce bufffer的copy。
如果driver(CPU)需要在不unmap的情况下使用DMA buffer,可以通过这个接口:
//首先通过这个接口获取DMA buffer给CPU用(在CPU开始使用之前)
void dma_sync_single_for_cpu(struct device *dev, dma_handle_t bus_addr,
size_t size, enum dma_data_direction direction);
//用完之后把DMA buffer返还给device(在device开始使用之前),一旦调用,CPU就不能再访问DMA buffer了
void dma_sync_single_for_device(struct device *dev, dma_handle_t bus_addr,
size_t size, enum dma_data_direction direction);
15.4.4.6 Single-page streaming mappings
如果你已经有了一个page指针,想把它用来做DMA,可以通过下面的接口:
dma_addr_t dma_map_page(struct device *dev, struct page *page,
unsigned long offset, size_t size,
enum dma_data_direction direction);
void dma_unmap_page(struct device *dev, dma_addr_t dma_address,
size_t size, enum dma_data_direction direction);
offset/size可以用来控制只对page中的一部分memory做map,但是不推荐这么做,因为有可能导致无法对齐cache line。
15.4.4.7 Scatter/gather mappings
scatter/gather是特殊类型的streaming DMA mapping,针对同时要map多个bufffer的情况。当然你可以采用每次map一个buffer的方式,但是kernel提供了更方便的办法。很多device都支持通过scatter list的方式一次DMA读写多个buffer,好处之一就是可以利用bus的DMA map registers,这样可以使得不连续的物理内存在外设看起来是连续的。要注意的是,除了scatter list的第一个和最后一个entry,其他entry的size需要和page size长度一样,否则不能使用scatter。(why?)
如果需要使用bounce buffer,就会把scatter list copy到一个大的buffer上去,因为反正要做copy。。
使用scatter/gather list的第一步就是创建scatter/gather的数组,并且填充必要的成员。scatter数据结构是架构相关的,但是都会包含如下三个成员:
struct page *page; 指向scatter/gather用到的buffer
unsigned int length; //buffer的length
unsigned int offset; //在page中的offset
driver需要填充scatterlist结构体里的这三个成员,然后调用:
int dma_map_sg(struct device *dev, struct scatterlist *sg, int nents,
enum dma_data_direction direction)
nents表示scatter数组的entry个数,返回值是map成功的DMA buffer的个数,可能小于nents。dma_map_sg函数中,会对scatterlist中的每一个page计算它的bus address,同时会合并相邻的page。如果当前的机器上有IOMMU,dma_map_sg也会设置IOMMU的mapping register,结果就是获得了一个在外设看起来连续的内存区域。
因为map成功以后,每一个buffer的地址和length可能都会发生变化,因此driver需要读取scatterlist中每一个buffer的bus地址和length,这些都记录在scatterlist entry里面,但是在结构体里的位置是不同的,为了移植性,kernel提供了接口:
//返回scatterlist entry的bus地址
dma_addr_t sg_dma_address(struct scatterlist *sg);
//返回scatterlist entry的length
unsigned int sg_dma_len(struct scatterlist *sg);
在map完成以后,需要unmap:
void dma_unmap_sg(struct device *dev, struct scatterlist *list, int nents, enum dma_data_direction direction);unmap的时候这个nents是map的时候传递给dma_map_sg的nents,不是map返回给你的值。
同样的,如果在map以后,CPU需要访问,就需要通过如下的接口先获取scatterlist的使用权,用完以后再把使用权释放:
void dma_sync_sg_for_cpu(struct device *dev, struct scatterlist *sg,
int nents, enum dma_data_direction direction);
void dma_sync_sg_for_device(struct device *dev, struct scatterlist *sg,
int nents, enum dma_data_direction direction);
15.4.4.8 PCI double-address cycle mappings
通常情况下,DMA layer都是support 32bit地址寻址,不过也支持64bit寻址——double-address cycle (DAC),普通的DMA layer并不支持DAC。如果某个外设支持非常大的high memory DMA,那就使用DAC,不过DAC只适用于PCI bus,别的不适用。
如果driver要支持DAC,首先应当设置这个mask:
int pci_dac_set_dma_mask(struct pci_dev *pdev, u64 mask);
如果函数返回0,说明device driver可以使用DAC。通过下面的接口来创建mapping:
dma64_addr_t pci_dac_page_to_dma(struct pci_dev *pdev, struct page *page,
unsigned long offset, int direction);
可以看到map的时候,buffer用struct page指针表示,因此DAC的map每次只能是一个page,而且必须是high memory或者没有被任何人使用的memory(不知道是不是这个意思);direction和DMA layer类似:PCI_DMA_TODEVICE, PCI_DMA_FROMDEVICE, 和 PCI_DMA_BIDIRECTIONAL。
pci_dac_page_to_dma没有占用external resource,使用完以后不需要释放。不过仍然遵守owner只有一个的原则,所以CPU访问前后要处理所有权的问题:
void pci_dac_dma_sync_single_for_cpu(struct pci_dev *pdev,
dma64_addr_t dma_addr,
size_t len,
int direction);
void pci_dac_dma_sync_single_for_device(struct pci_dev *pdev,
dma64_addr_t dma_addr,
size_t len,
int direction);
15.4.4.9 A simple PCI DMA example
这里就是一个简单的PCI DMA的例子:
int dad_transfer(struct dad_dev *dev, int write, void *buffer,
size_t count)
{
dma_addr_t bus_addr;
/* Map the buffer for DMA */
dev->dma_dir = (write ? DMA_TO_DEVICE : DMA_FROM_DEVICE);
dev->dma_size = count;
bus_addr = dma_map_single(&dev->pci_dev->dev, buffer, count,
dev->dma_dir);
dev->dma_addr = bus_addr;
/* Set up the device */
writeb(dev->registers.command, DAD_CMD_DISABLEDMA);
writeb(dev->registers.command, write ? DAD_CMD_WR : DAD_CMD_RD);
writel(dev->registers.addr, cpu_to_le32(bus_addr));
writel(dev->registers.len, cpu_to_le32(count));
/* Start the operation */
writeb(dev->registers.command, DAD_CMD_ENABLEDMA);
return 0;
}
void dad_interrupt(int irq, void *dev_id, struct pt_regs *regs)
{
struct dad_dev *dev = (struct dad_dev *) dev_id;
/* Make sure it's really our device interrupting */
/* Unmap the DMA buffer */
dma_unmap_single(dev->pci_dev->dev, dev->dma_addr,
dev->dma_size, dev->dma_dir);
/* Only now is it safe to access the buffer, copy to user, etc. */
...
}15.4.5. DMA for ISA Devices
略过


 浙公网安备 33010602011771号
浙公网安备 33010602011771号