吴恩达《机器学习》课程总结(1)_绪论:初识机器学习
前言:开启大约二十天的机器学习时光,以吴恩达的机器学习课程为主线同时结合网上其他的资源进行学习,每天对学到的东西在博客上记录下来,以备复习。部分内容转载自这位博主:https://www.cnblogs.com/ys99/p/9223859.html
Q1:机器学习的定义?
(1)一种机器学习的定义:一个程序被认为能从经验E中学习,解决任务T,达到性能指标度量值P,当且仅当,有了经验E后,经过P评判,程序在处理T时的性能有所提升。
(2) 从广义上来说,机器学习是一种能够赋予机器学习的能力以此让它完成直接编程无法完成的功能的方法。但从实践的意义上来说,机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。(https://blog.csdn.net/lichengshan523689/article/details/80274173)
(3)机器学习算法主要分为监督学习和非监督学习。监督学习是我们将教计算机如何去完成任务,非监督学习是我们打算让计算机它自己去学习。此外还有强化学习和推荐系统等其他机器学习。
Q2:监督学习
(1)监督学习基本思想是我们数据集中的每个样本都有相应的“正确答案”(有标签)。再根据这些样本做出预测,像房子和肿瘤的例子。
(2)监督学习分为回归问题和分类问题,前者如房价的预测,将房价的一系列实数值看成是连续的,后者如肿瘤预测,分为良性和恶性两种类别,其取值看成是离散的。
回归问题:
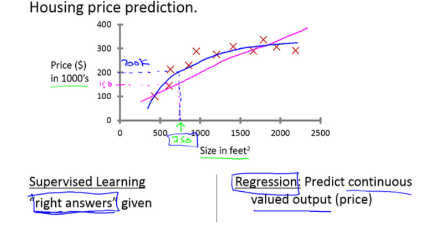
分类问题:
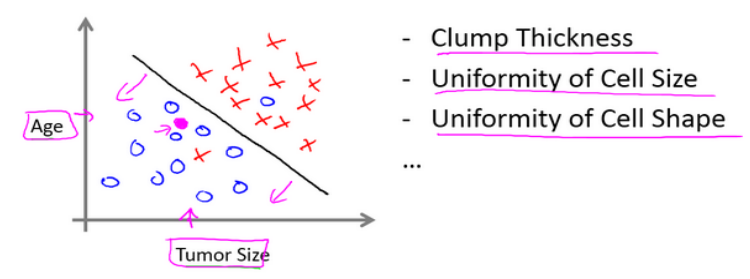
Q3:无监督学习
(1)无监督学习样本没有标签(“无正确答案”),无监督学习算法可能会把没有标签的数据分成不同的簇,这种算法较聚类算法。
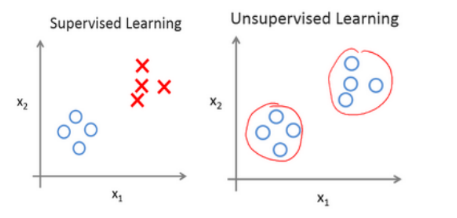
2)一些常见的聚类算法应用:新闻分类、基因学的理解应用、组织大型计算机集群、社交网络分析、市场分割、天文数据分析等。
Q5:需要掌握的词汇
Machine learning ---机器学习 Classification problem ---分类问题 Regression problem ---回归问题 Contionuous value ---连续值 Discrete values ---离散值 Supervised learning ---监督学习 unsupervised learning ---无监督学习 cluster ---簇

 浙公网安备 33010602011771号
浙公网安备 33010602011771号