Spark编译和打包
Spark编译和打包
大多时候我们都会从Spark官方下载二进制包直接使用,但是在学习源码或者需要得到定制化的Spark版本,就需要自行编译和打包了。
下载源码
spark官网下载源码地址:点我
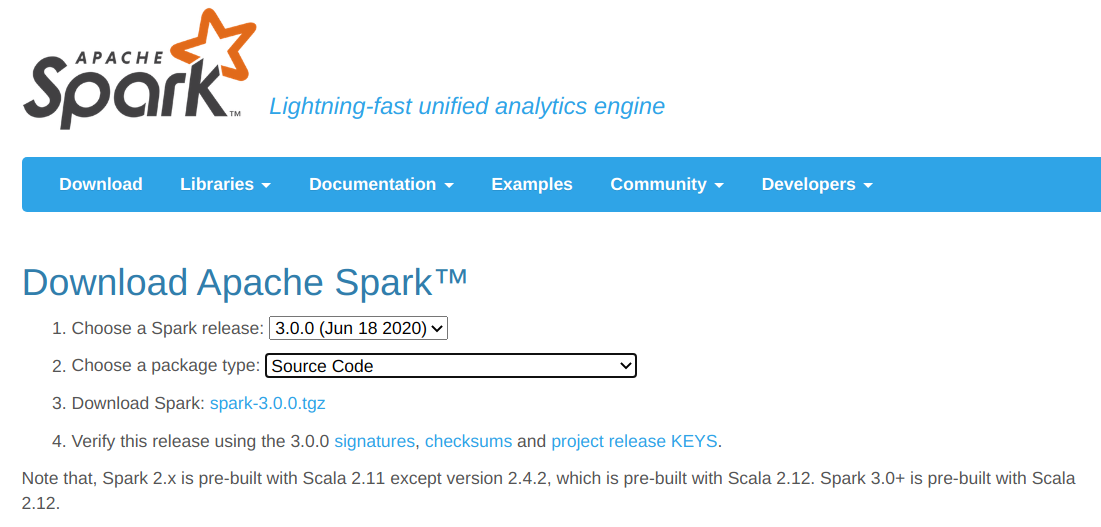
或者可以到github上下载release版本:点我
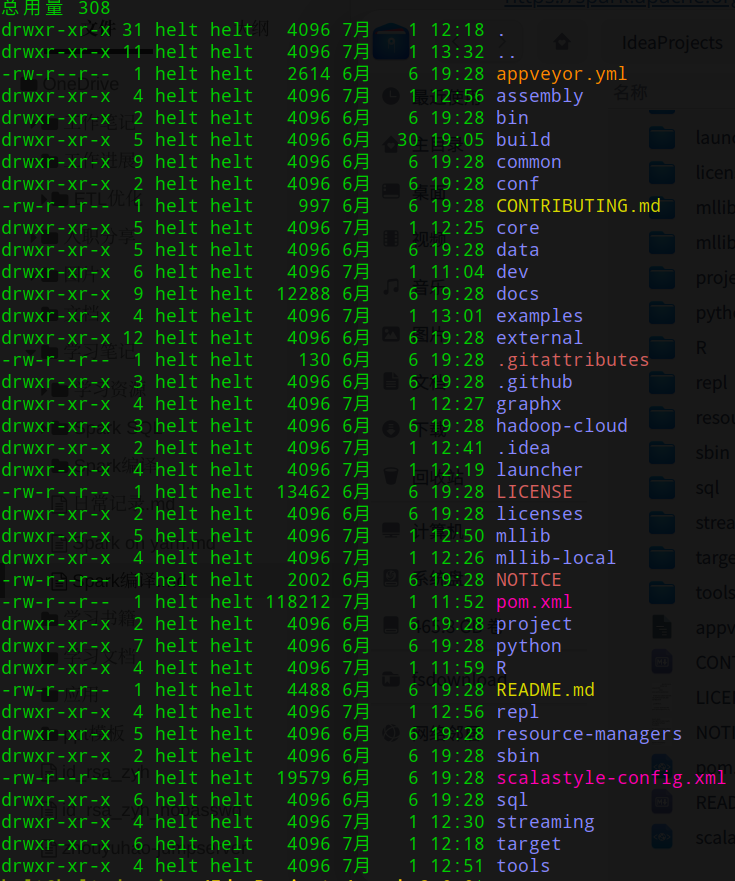
下载后解压并进入目录,目录结构如下
修改mvn仓库为阿里云地址
默认的仓库地址是谷歌的,国内访问有问题,因此修改成阿里云的,编辑项目根目录下的pom.xml文件,添加阿里云地址,需要添加2处。
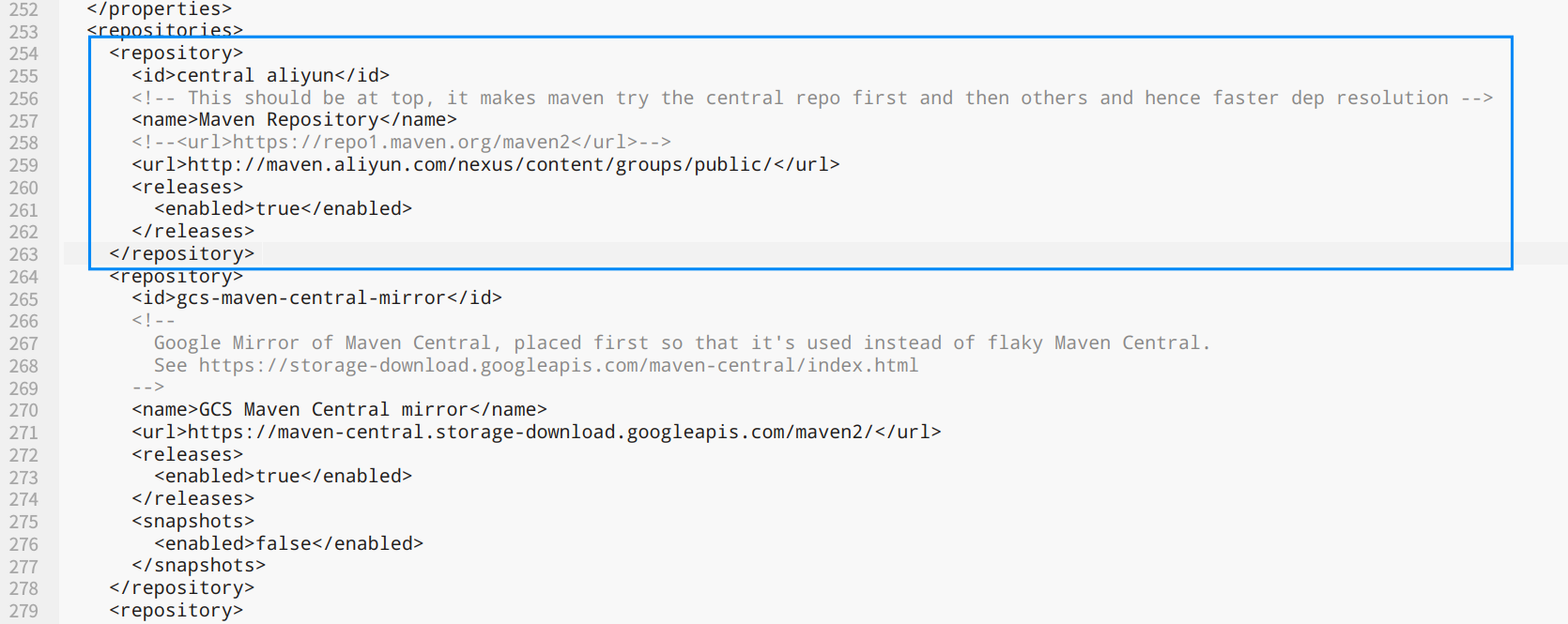
第一处为253行附近<repositories>标签(随着版本不同,位置可能上下浮动),将阿里云的地址添加到最前面
<repository>
<id>central aliyun</id>
<!-- This should be at top, it makes maven try the central repo first and then others and hence faster dep resolution -->
<name>Maven Repository</name>
<!--<url>https://repo1.maven.org/maven2</url>-->
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
</repository>
图示
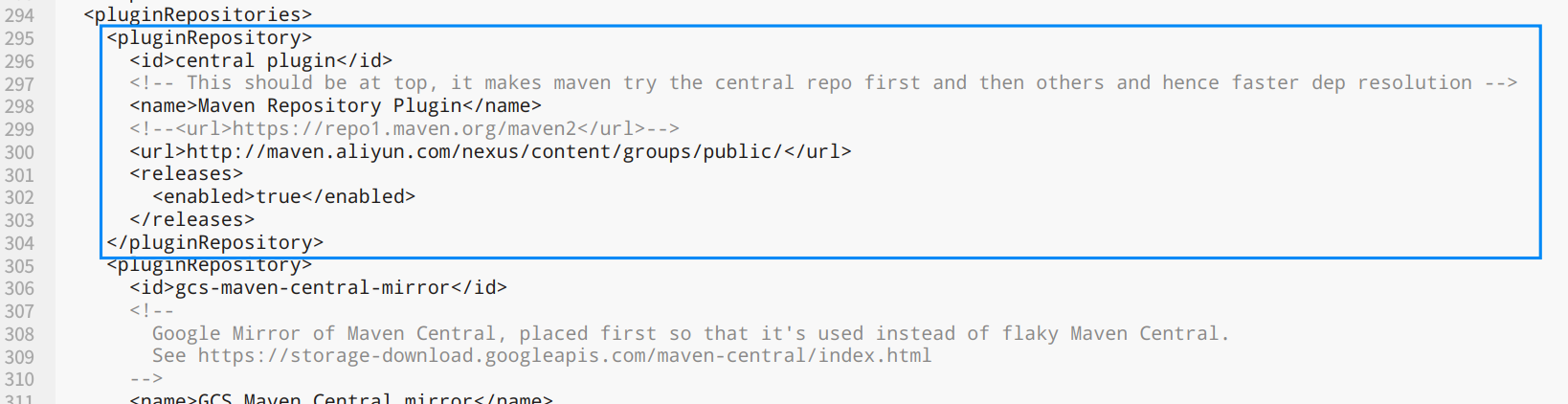
第二处为294行<pluginRepositories>标签,为插件的mvn地址
<pluginRepository>
<id>central plugin</id>
<!-- This should be at top, it makes maven try the central repo first and then others and hence faster dep resolution -->
<name>Maven Repository Plugin</name>
<!--<url>https://repo1.maven.org/maven2</url>-->
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
</pluginRepository>
图示
编译打包
官方build教程:点我
直接编译打包
Spark从build目录下附带了一个独立的Maven安装包,以简化源代码构建和部署的工作。该脚本将在build目录本身中本地自动下载和设置所有必要的构建要求(Maven,Scala和Zinc)。
如果是源码学习,或只是修改打包某个项目,可以直接在根目录下使用如下命令:
./build/mvn -DskipTests clean package
注意:这里会自动下载Zinc,可能网络不太好会下载很久,可以先ctrl+c打断下载,然后复制链接到浏览器下载,保存到bulid目录下覆盖没下完的文件,然后重新运行上面的命令来编译打包
打包可运行的发行版
如果需要打包一个和官网下到的一样的发行版,就需要使用dev下的make-distribution.sh脚本。
修改./dev/make-distribution.sh脚本,注释129行左右的四个变量,填写自己的版本,如果不填写,这里计算版本会特别特别慢。
因为Spark3.0官方发布的二进制版本自带的hive支持从1.2.1升级到2.3.7了,因此对于老版本的hive就不支持了,这也是为什么我们需要构建属于自己的Spark的原因,因此我们这里主要是修改hive的版本。
#VERSION=$("$MVN" help:evaluate -Dexpression=project.version $@ 2>/dev/null\
# | grep -v "INFO"\
# | grep -v "WARNING"\
# | tail -n 1)
#SCALA_VERSION=$("$MVN" help:evaluate -Dexpression=scala.binary.version $@ 2>/dev/null\
# | grep -v "INFO"\
# | grep -v "WARNING"\
# | tail -n 1)
#SPARK_HADOOP_VERSION=$("$MVN" help:evaluate -Dexpression=hadoop.version $@ 2>/dev/null\
# | grep -v "INFO"\
# | grep -v "WARNING"\
# | tail -n 1)
#SPARK_HIVE=$("$MVN" help:evaluate -Dexpression=project.activeProfiles -pl sql/hive $@ 2>/dev/null\
# | grep -v "INFO"\
# | grep -v "WARNING"\
# | fgrep --count "<id>hive</id>";\
# # Reset exit status to 0, otherwise the script stops here if the last grep finds nothing\
# # because we use "set -o pipefail"
# echo -n)
VERSION=3.0.0
SCALA_VERSION=2.12
SPARK_HADOOP_VERSION=2.7.4
SPARK_HIVE=1.2
注意:spark3.0已经不支持使用hadoop2.6,这里只能取用2.7以上的版本,否则编译不通过
增加mvn内存来加速构建
export MAVEN_OPTS="-Xms6g -Xmx6g -XX:+UseG1GC -XX:ReservedCodeCacheSize=2g"
建立可发行的版本
# 该处-P表示使用pom.xml中的id对应的配置,这里增加hive-1.2的配置
./dev/make-distribution.sh --name my-spark-3.0.0 --tgz -Phive-1.2 -Phive-thriftserver -Pyarn
完成后在项目根目录会得到如下文件:
spark-3.0.0-bin-my-spark-3.0.0.tgz
2020-10-27 更新
最新spark3.1.0分支已经无法支持传递-Phive-1.2来打包发行版,如果需要支持旧hive版本可能需要修改源码或者在使用时设置采用的hive版本和metastore相应的依赖包。
示例
bin/spark-shell --conf spark.sql.hive.metastore.version=1.2.2 --conf spark.sql.hive.metastore.jars=/user/hive_jars/*

 浙公网安备 33010602011771号
浙公网安备 33010602011771号