小土堆pytorch学习——P15-DataLoader使用
DataLoader Link:https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader

Q:What does the figure mean?
A:连接数据集和样本,并提供给定数据集的可迭代形式。DataLoader支持以(单进程/多进程)、自定义加载顺序、可选的自动批处理(排序)和内存固定的映射方式和迭代方式的数据集
看参数
DataLoader众多参数皆有默认值,除dataset外,它需要给定数据集。
batch_size——每次从数据集中取多少样本进行处理
shuffle——再次载入数据集时,是否要打乱顺序,因为数据集可能不是读取一次
num_workers——决定是单线程还是多线程处理
drop_last——在tensorboard中显示,是否要显示最后的不规则图形的那次
sampler
batch_sampler
example
import torchvision
from tensorboardX import SummaryWriter
from torch.utils.data import DataLoader
test_data = torchvision.datasets.CIFAR10(root = "hymenoptera_data/val/CIFAR10" , train = False
,transform= torchvision.transforms.ToTensor())
test_loader = DataLoader(
dataset = test_data , batch_size = 64 ,
shuffle = True , num_workers = 0 ,
drop_last = False
)
#通过该类的getitem,可知它返回一个img , target
img,target = test_data[0]
#测试数据集中第一张图片以及target
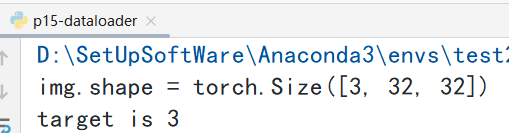
print(f"img.shape = {img.shape}")
print(f"target is {target}")
运行结果👇
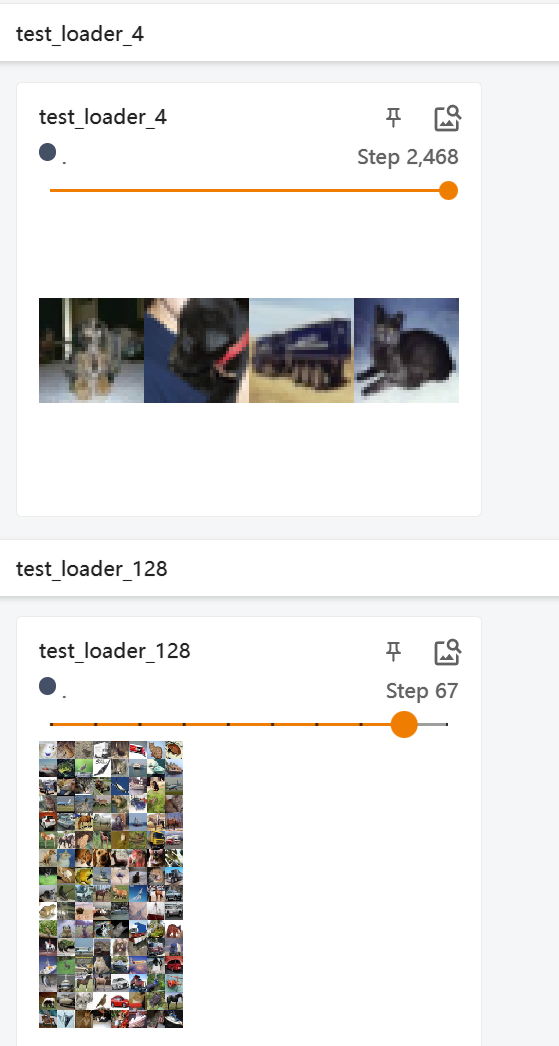
载入tensorboard中,先是对batch_size进行调整,有128和4的调整。
test_loader = DataLoader(
dataset = test_data , batch_size =4 ,
shuffle = True , num_workers = 0 ,
drop_last = False
)
for data in test_loader:
imgs , targets = data
writer.add_images("test_loader_4" , imgs,step)
step = step+1
test_loader = DataLoader(
dataset = test_data , batch_size = 128 ,
shuffle = True , num_workers = 0 ,
drop_last = False
)
for data in test_loader:
imgs , targets = data
writer.add_images("test_loader_128" , imgs,step)
step = step+1
writer.close()
打开tensorboard展示如下👇
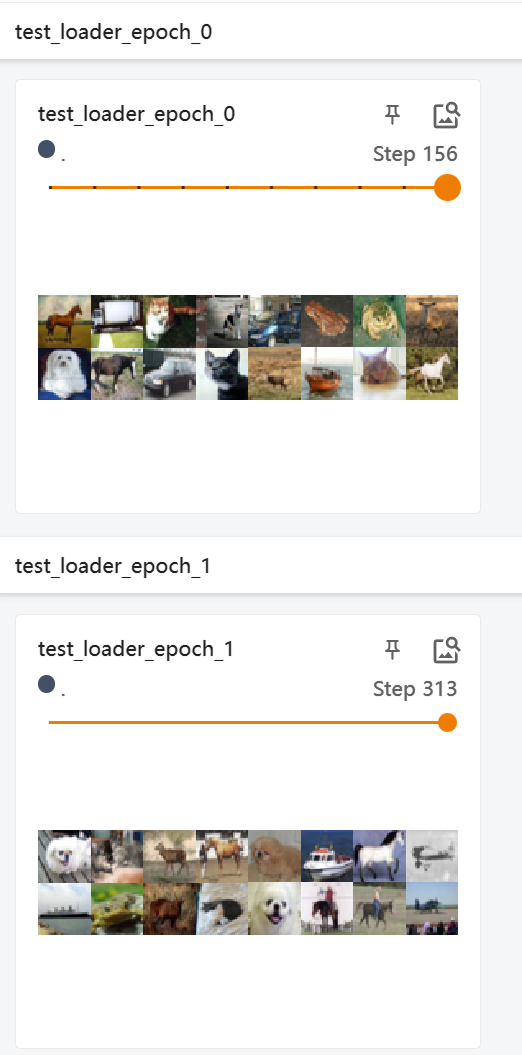
有对shffle的调整,为True或False。下图是batch_size调整为64时,打乱顺序的结果。
test_loader = DataLoader(
dataset = test_data , batch_size = 64 ,
shuffle = True , num_workers = 0 ,
drop_last = False
)
for epoch in range(2):
print(f"epoch = {epoch}")
for data in test_loader:
imgs,targets = data
writer.add_images(f"test_loader_epoch_{epoch}",
imgs, step)
step+=1
writer.close()
打开tensorboard展示如下👇
数据集中的dateset中有getitem方法,DataLoader中没有。getitem方法返回img,target,当dataloader(batch_size=4)时,相当于把dataset中img0,1,2,3打包,target0,1,2,3打包,作为dataloader中的返回值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号