
C程序的内存结构
【版权声明:本文为博主原创文章,未经博主允许不得转载】
==================================================================
运行环境:Ubuntu 18.04 LTS 64bit
Linux 4.15.0-34-generic x86_64 GNU/Linux
gcc-7.3.0
==================================================================
一、概述
一般情况下,一个可执行C程序在内存中主要包含5个区域,分别是代码段(text),数据段(data),BSS段,堆段(heap)和栈段(stack)。其中前三个段(text,data,bss)是程序编译完成就存在的,此时程序并未载入内存进行执行。后两个段(heap,stack)是程序被加载到内存中时,才存在的。下面分别介绍:
本文的参考示例代码(test.c)如下:
int gDataA = 10; int gDataB; const int gDataC = 20; int func(int x,int y,int z) { return (x + y + z + gDataC); } int main(void) { int x = 2; static int DataA = 4; gDataB = func(x,DataA,gDataA); DataA = gDataB - DataA; return 0; }
编译:gcc test.c -o test -O2 -fno-inline
二、代码段
代码段(text):就是C程序编译后的机器指令,也就是我们常见的汇编代码,汇编代码可以通过objdump查看,如下图所示:
# objdump - test > test.hex
# vi test.hex
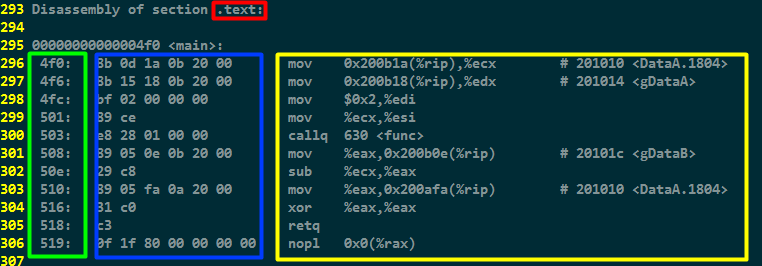
其中:
红框表示该段是text段;
绿框表示的是程序的虚拟地址;
蓝框表示的是text段的实际内容,也就是一些连续的二进制机器码;
黄框的汇编内容实际上并不存在于text段中,它只是objdump程序根据蓝框中机器码解析出来的汇编信息,提高可读性。
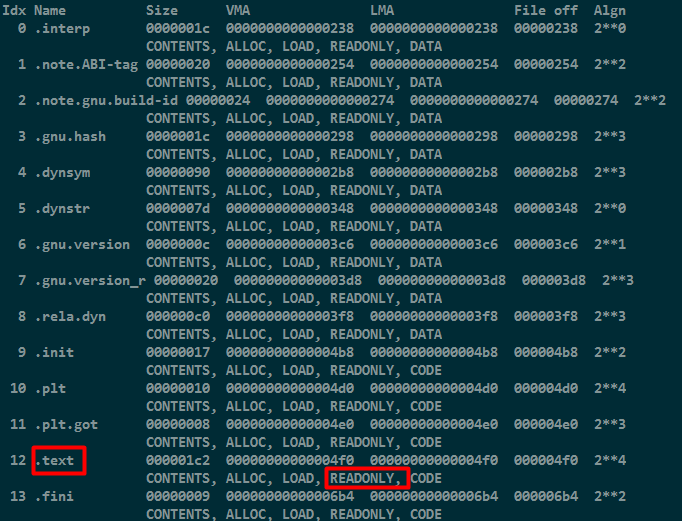
通过objdump -h test,读取text段的信息,可见text段是READONLY的,这也防止其他程序恶意修改程序。
二、数据段
数据段(data):用来存放显式初始化的全局变量或者静态(全局)变量。例如以下反汇编代码片段
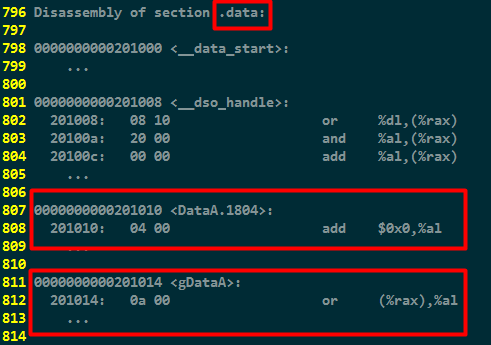
其中DataA.1804可以理解为DataA的一个别名,与编译器有关,在此不再深入分析。
可见gDataA和DataA两个显式初始化的全局变量都存储在data段中。其值分别是0x000a和0x0004。(x86_64小端处理器)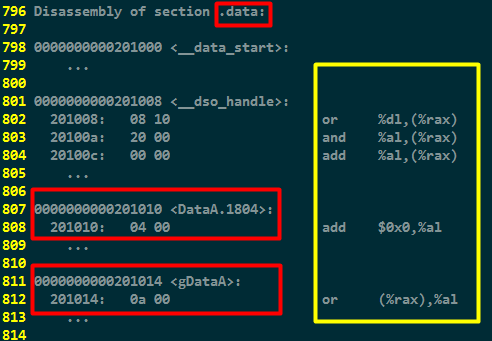
上图红框中的内容是在二进制文件中实际存储的内容,而黄框中的内容是对应二进制解析出来的,对于数据段中内容解析出来后是没有意义的,因为它们是数据,不是指令。可以理解为objdump工具的“过度解析”(下同,不再累述)。
三、BSS段
BSS段(Block Started by Symbol):存储未初始化的全局变量或者静态(全局)变量。例如以下反汇编代码片段:
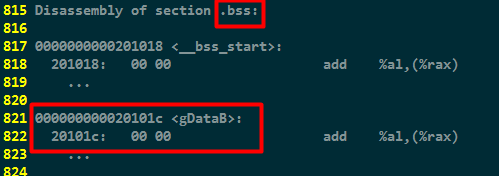
gData是未被初始化的全局变量,因此存放在bss段,其值默认是0。
四、栈段(stack)
我们很多时候习惯统一来说“堆栈”,但是堆和栈是两个不同的区域,对于我们程序员来说还是要搞清楚的。
栈段(stack):存放函数调用相关的参数、局部变量的值,以及在任务切换的上下文信息。为了更便于说明问题,使用下面的示例代码(本代码仅仅是为了说明问题,风格不值得借鉴):
int func(int a1,int a2,int a3,int a4,int a5,int a6,int a7,int a8,int a9) { return (a1 + a2 + a3 + a4 + a5 + a6 + a7 + a8 + a9); } int main(void) { int a1,a2,a3,a4,a5,a6,a7,a8,a9; int sum; a1 = 0x11; a2 = 0x22; a3 = 0x33; a4 = 0x44; a5 = 0x55; a6 = 0x66; a7 = 0x77; a8 = 0x88; a9 = 0x99; sum = func(a1,a2,a3,a4,a5,a6,a7,a8,a9); return sum; }
编译并objdump:
# gcc stack.c -o stack -O2 -fno-inline // 使用-fno-inline的目的是为了禁止内联,便于展现函数调用及参数传递过程。感兴趣的同学可以不加该参数编译下。
# objdump -M intel -D stack > stack.hex
查看main函数和func函数的反汇编代码:
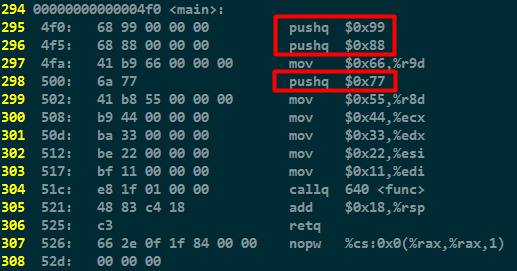
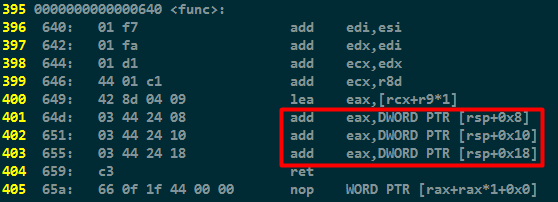
对于main函数中,为何有的使用mov,有的使用push可以参考函数调用过程中的参数传递规则(简言之就是x86_64可以使用6个寄存器(分别是edi,esi,edx,ecx,r8d,r9d)直接传递参数,而不用压栈和出栈,提高性能)。
后面的参数都使用压栈的方式传递给被调用函数func。
从这里也可以知道,在我们自己写函数的情况的时候,参数个数最好控制在6个以内,否则就需要用堆栈,而堆栈的访问速度是没有寄存器快的,性能就会下降。这是x86_64架构的情况,其它的如x86、ARM、ARM64、MIPS传参的规则是不一样的,就需要根据实际情况考虑了。
对于func函数,直接使用edi、esi、edx、ecx、r8d和r9d获得前6个参数值,后面的参数就需要从stack上获取。
栈区是由操作系统分配和管理的区域。
五、堆段(heap)
动态内存分配的区域,也就是malloc申请的内存区。注意malloc申请的内存不用的时候必须free,并指向NULL。
堆区是由程序员显示分配与管理的。
六、小结
下面来自经典书籍《UNIX环境高级编程》中对此有如下描述:
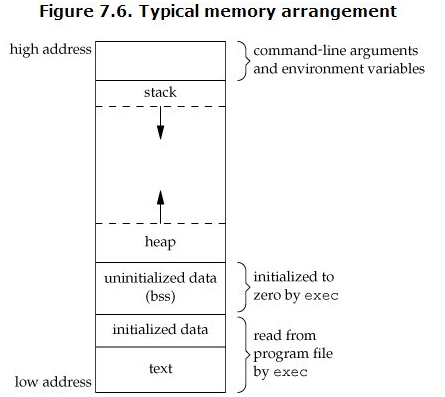
对于C代码编译出来的二进制,代码段(text)、数据段(data)和BSS段是代码编译后就确定了,但是编译后的程序存储在硬盘中,当要执行的的时候,操作系统负责将该程序load到内存中。
在程序运行的之后,就会涉及到堆区和栈区的操作。一般情况下,堆区是向上生长的,栈区是向下生长的,当然不同的处理器架构是不同的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号